






作者 | 紫彤 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/26904440478
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『具身智能』技术交流群
本文只做学术分享,如有侵权,联系删文
Robotic Control via Embodied Chain-of-Thought Reasoning
背景
机器人控制策略难以训练数据之外进行泛化。最近,关于视觉-语言-动作模型(Vision-Language-Action models,简称VLA)的研究表明,将大型互联网预训练的视觉-语言模型作为学习型机器人策略的核心,可以显著提升其鲁棒性和泛化能力。在其他领域中,大型视觉-语言模型最令人兴奋的能力之一是它们能够通过迭代推理解决复杂问题。这种能力是否可以引入机器人领域,使策略能够在行动之前通过对给定任务的推理来提升性能呢?由于标准VLA可用的训练样本相对简单,因此直接使用“思维链”(Chain-of-Thought,简称CoT)风格的提示效果并不理想。此外,像在常规CoT中常见的那样,仅进行关于子任务的纯语义推理,对于需要将推理建立在感官观察和机器人状态之上的机器人策略来说是不够的。
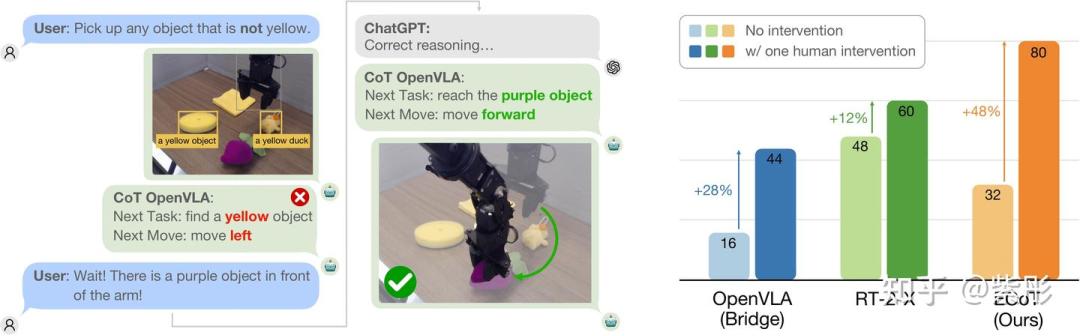
为此,UC Berkeley团队提出了具身思维链推理(Embodied Chain-of-Thought Reasoning,简称ECoT),在预测机器人动作之前,训练VLAs对计划、子任务、运动以及视觉基础特征(如目标边界框和末端执行器位置)进行多步推理。设计了一个用于在大型机器人数据集上生成ECoT合成训练数据的pipeline。实验结果证明,ECoT在具有挑战性的泛化任务中,将当前最强的开源VLA策略OpenVLA的绝对成功率提高了28%,而无需额外的机器人训练数据。此外,ECoT还使人类更容易通过自然语言解释策略的失败并纠正其行为。
方法
ECOT的核心有两部分:具身思维链推理过程分解和训练数据自动标注。此外,文中还提出了两种提高实时性的方法。
具身思维链推理过程
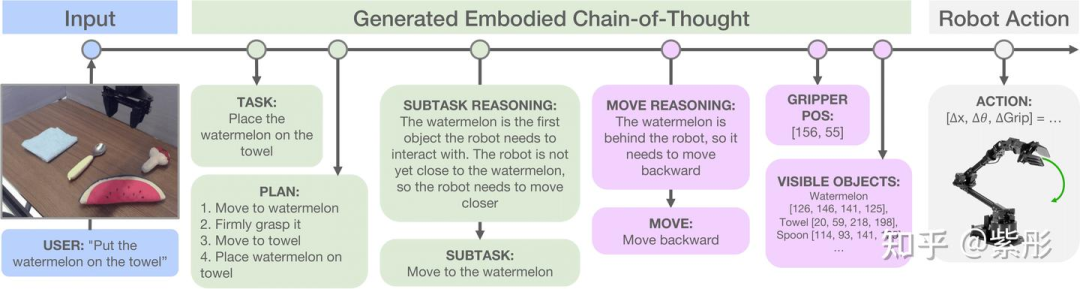
在设计ECoT的推理步骤时,目标有两个:
希望模型能够推理出当前任务所需的子任务,并确定下一步需要执行的内容;
希望模型在预测机器人动作之前,逐步将这种推理与场景和机器人状态的低级特征相结合。
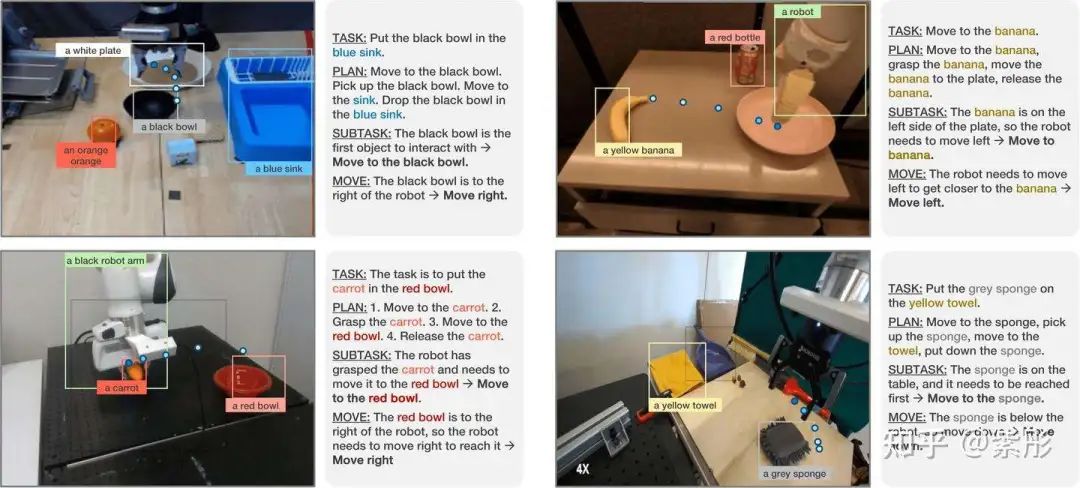
在图1中,展示了训练视觉语言动作模型(VLA)执行的ECoT推理步骤的一个示例。从左到右,模型首先被训练重新表述任务指令(TASK),并预测一个用于完成指令任务的计划(PLAN)。接下来,模型需要推理出当前步骤应执行的子任务(SUBTASK),这需要理解场景和机器人的当前状态。然后,模型预测一个更接近机器人低级动作的语言指令,例如“向左移动”或“向上移动”(MOVE)。最后,要求模型预测精确的、基于空间的特征来描述场景,从而迫使模型仔细关注输入图像的所有元素——具体来说,就是机器人末端执行器的像素位置(GRIPPER)以及场景中所有物体的名称和边界框像素坐标(OBJECTS)。
尽管选择的推理任务及其顺序与我们对任务逐步解决方案的直觉高度一致,但并没有穷尽所有可能的推理任务。测试替代任务及其顺序,并找到自动确定合理推理链的方法,将是未来研究的重要方向。
训练数据自动标注
若想获取高质量推理链,最直接的方式是人工标注数据。然而,这种方法对于包含数百万个单独转换的大型机器人学习数据集来说是不切实际的。因此,提出利用预训练的视觉和/或语言基础模型自动生成ECoT训练数据,类似于自然语言处理中的合成数据生成。
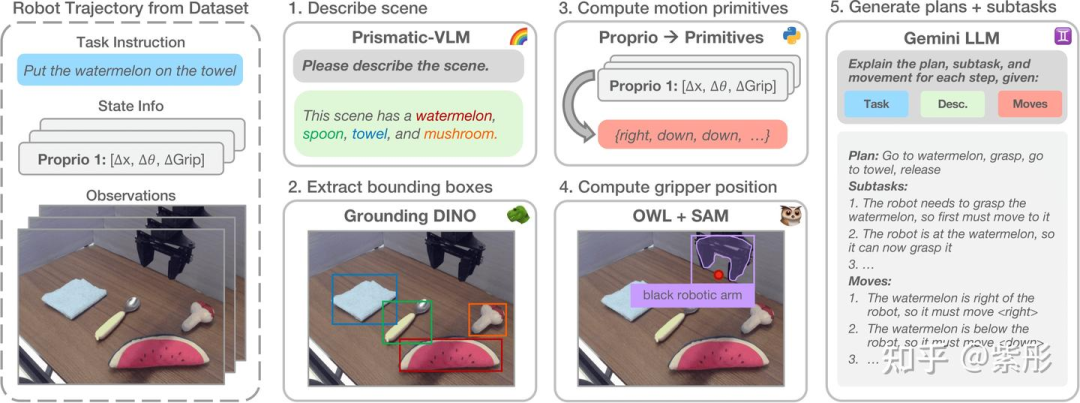
数据生成流程的概述如图2所示。对于给定的图像-指令对,首先提示Prismatic-7B视觉语言模型(VLM)生成场景的详细描述。然后将原始指令与生成的描述拼接,并输入到Grounding DINO中,这是一个开放词汇对象检测器。它会检测所有相关对象实例及其边界框,并将它们与输入文本中的相应语言片段关联起来。根据提供的置信度分数对预测结果进行筛选,仅保留边界框置信度大于0.3且文本置信度大于0.2的检测结果,用于作为OBJECT特征。
接下来,生成MOVE中的每步低级动作原语(例如,“向左移动”“向上移动”)。按照Belkhale等人的方法,利用机器人的本体感知来确定接下来4个时间步的运动方向(假设摄像头固定),并将其转换为729种模板化运动原语之一(所有原语的列表见附录B)。使用OWLv2和SAM检测训练图像中的2D末端执行器位置(GRIPPER),并将其与从机器人状态中提取的3D位置配对,通过RANSAC拟合投影矩阵的稳健估计。然后使用机器人末端执行器位置的2D投影进行训练。该过程独立地对每条轨迹重复进行,无需假设固定的摄像头参数。
为了生成最终的推理链,将每个episode的任务指令、场景描述和每步运动原语输入到Gemini 1.0中,提示其根据任务指令和观察到的运动原语生成子任务的高级计划,以及每步的当前子任务。同时,还要求其简要解释每步中的原始运动和所选子任务,这些内容将包含在ECoT训练数据中。数据生成流程在完整的Bridge v2数据集上运行,该数据集包含超过250万个step,整个过程耗时7天。
实时推理策略
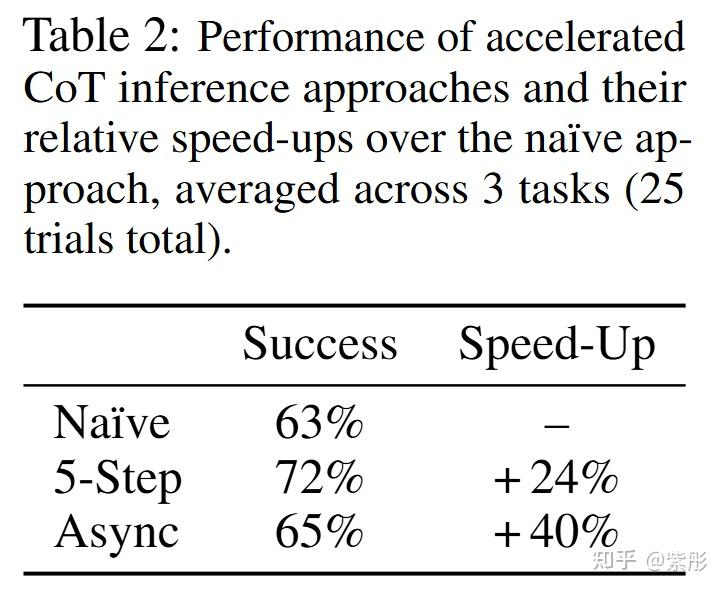
推理速度是ECoT策略面临的一个关键挑战。模型需要预测额外的推理token,显著增加了耗时。每个时间步需要预测的token数量从OpenVLA的7个增加到ECoT的350个。基于LLM的特性,一种加速推理的解决方案是:对于多个步骤,保持推理链的部分内容不变,如高层次的计划或当前子任务。关键是,对于基于Transformer的策略(如OpenVLA)来说,编码之前预测的token比生成新标记要快得多。
进一步给出了两种策略:
(1)同步执行,但每N步预测一次高层次的推理;
(2)异步执行,其中一个ECoT策略实例不断更新高层次的推理链,而第二个策略实例则使用最新的推理链来预测低层次的推理步骤和机器人动作。
此外,可以结合现有的提高大语言模型和视觉-语言模型吞吐量(throughput)的方法,比如优化的计算内核和推测解码。
实验
实验从以下几个角度展开:
(1)具身思维链推理是否提升了VLA策略的表现
(2)具身思维链推理是否更容易解释和纠正策略失败
(3)具身思维链的推理速度优化
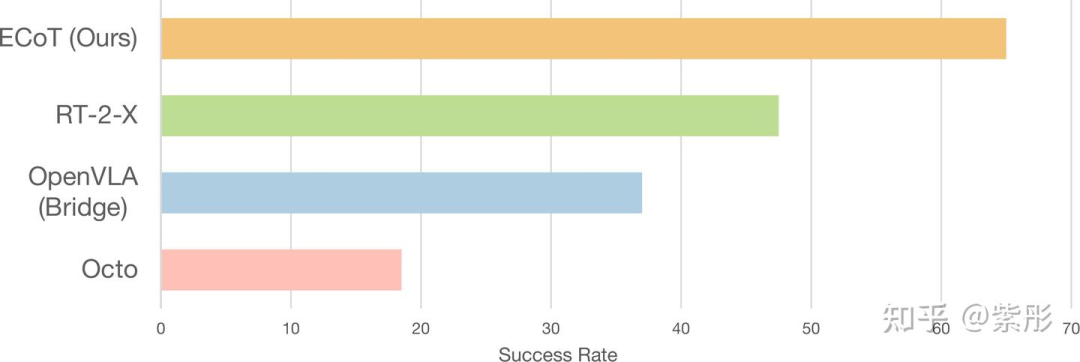
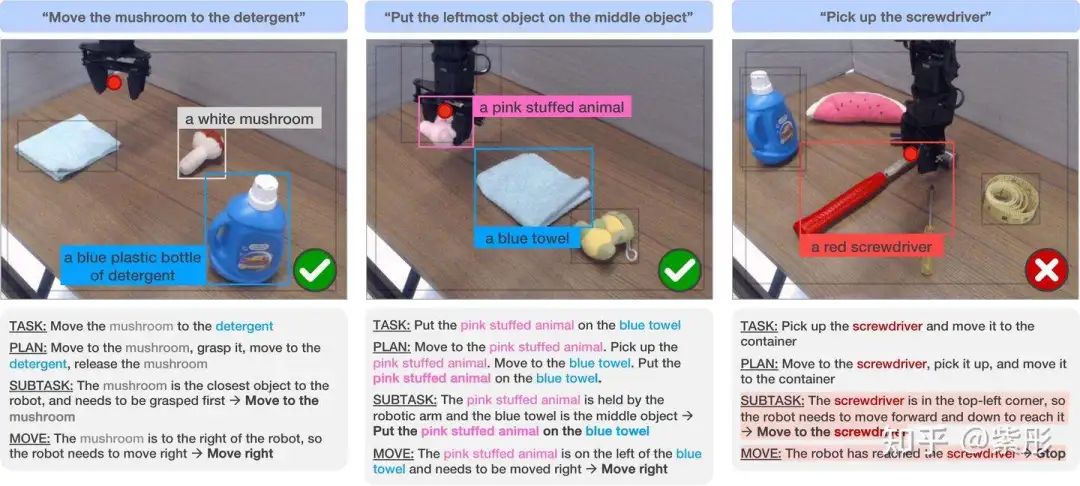
总结
提出了一种训练视觉语言动作(VLA)策略以执行思维链推理的方法,可以在无需收集额外机器人训练数据的情况下显著提升其性能。该方法没有简单照搬语言建模中的思维链(CoT)方法,而是通过添加与场景和机器人状态紧密结合的推理步骤的重要性,例如涉及目标边界框、机器人的末端执行器或低级机器人运动。
该方法仍存在一些局限性。首先,模型没有根据当前的任务调整其推理链的结构;它只能按照预定义的固定顺序执行所有推理步骤。更有效的策略应该是根据机器人和场景状态仅执行部分推理步骤,未来的工作可以探索直接优化模型以选择最佳的推理步骤。此外,将ECoT训练扩展到OXE数据集的更大子集将有助于将ECoT能力迁移到更多机器人上。最后,推理速度仍然是一个关键瓶颈,未来需要进一步优化以实现更高效的推理。
① 自动驾驶论文辅导来啦

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









