 LLM的SFT常见面试问题解答
LLM的SFT常见面试问题解答




作者 | 技术微佬 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/714687583
点击下方卡片,关注“自动驾驶之心”公众号
>>点击进入→自动驾驶之心『大模型』技术交流群
本文只做学术分享,如有侵权,联系删文
1.整体可以参考这篇文章。
技术微佬:LLM的SFT
https://zhuanlan.zhihu.com/p/711825077
2.1 常用的轻量级微调方法有什么,异同点,与传统的fine-tuning的区别?
部分参数微调策略仅选择性地更新模型中的某些权重,尤其是在需要保留大部分预训练知识的情况下。这包括:
prefix/prompt-tuning: 在模型的输入或隐层添加k个额外可训练的前缀 tokens(这些前缀是连续的伪 tokens,不对应真实的 tokens),只训练这些前缀参数;
P-tuning: P-Tuning 利用少量连续的 embedding 参数作为 prompt使 GPT 更好的应用于 NLU 任务,而 Prefix-Tuning 是针对 NLG 任务设计,同时,P-Tuning 只在 embedding 层增加参数,而 Prefix-Tuning 在每一层都添加可训练参数
P-tuning v2:V2更接近于prefix- tuning,微调了每一层transformer的输入embedding,v2在大小模型都有效;
Adapter-Tuning:将较小的神经网络层或模块插入预训练模型的每一层,这些新插入的神经模块称为 adapter(适配器),下游任务微调时也只训练这些适配器参数;
LoRA(Low-Rank Adaptation):通过向模型权重矩阵添加低秩矩阵来进行微调,既允许模型学习新的任务特定模式,又能够保留大部分预训练知识,从而降低过拟合风险并提高训练效率。
AdaLoRA:是对LoRA的一种改进,它根据重要性评分动态分配参数预算给权重矩阵;
QLoRA:使用一种新颖的高精度技术将预训练模型量化为 4 bit,然后添加一小组可学习的低秩适配器权重,这些权重通过量化权重的反向传播梯度进行微调。
与传统的fine-tuning的区别:
参数量:fine-tuning是全参数微调,PEFT是部分参数微调;
训练效率:fine-tuning训练效率慢,PEFT是快;
适用场景:fine-tuning需要更多的资源和数据,相应的上限可能也会更高,PEFT适用于资源较少的场景。
2.2为什么SFT后模型变傻了(灾难性遗忘),如何降低这种现象?
SFT数据比较多或者epoch比较大时,可能会导致SFT后大模型的通用能力下降,导致灾难性遗忘,这要根据实际场景判断,如果你只关注特殊领域的性能,通用能力下降你也不需要过度关注,如果想要不失去通用的生成能力,可以考虑以下几点:
多任务微调:如果希望模型保持多任务泛化能力,可以一次性对多个任务执行微调。良好的多任务微调可能需要包含许多任务的50-100,000个示例。
考虑PEFT的方法:也就是保留了原始LLM的权重,不采用全参数微调的方法。通过训练少量特定于任务的适配器层和参数。PEFT对灾难性遗忘表现出更大的鲁棒性,因为大多数预训练的权重保持不变。
数据配比:在SFT数据中,增加一些通用生成的数据,避免SFT过度学习单一训练集内容。
2.3 SFT指令微调数据如何构建?
SFT的重点是学习样式,而非知识注入,所以SFT的样本在于其质量而非数量,少量但精良的样本往往胜过大批中低品质的样本,实现同样甚至更优的微调效果。通常情况下,2-10k数据就会有一个不错的效果。这一理念在Meta发布的《LIMA: Less Is More for Alignment》论文中得到了有力阐述,该文献强调了在指令微调过程中,高品质微调数据的决定性作用。据此,我们应当将重心放在提升样本质量的打磨上,而非单纯追求数量的增长。
如何评估样本的效果,在评估微调样本质量的过程中,通常需要关注以下几个核心维度:
样本多样性(Sample Diversity):
指令多样性:考察样本中指令的覆盖范围是否广泛,是否包含了各类任务类型、不同难度级别以及多样化的指令结构和表达方式,确保模型在微调后能应对多种复杂情境。
内容多样性:检查样本中提供的文本内容是否涵盖了不同主题、文体、长度以及语境,以避免模型在特定领域或文本类型上过拟合,确保其具备良好的泛化能力。
答案质量(Answer Quality):
准确性(Accuracy):评估答案是否准确无误地响应了给定指令和内容,是否忠实反映了任务要求,且不包含事实性错误、逻辑矛盾或语义模糊。
完备性(Completeness):考察答案是否全面覆盖了指令所要求的所有任务点,尤其对于多步骤或复合任务,答案应完整体现所有必要的操作结果。
简洁性与清晰度(Conciseness & Clarity):衡量答案是否言简意赅、表达清晰,避免冗余信息或含糊表述,确保模型在微调后生成的输出易于理解和使用。
一致性(Consistency):
内部一致性:检查同一指令对不同内容的处理结果是否保持一致,即模型在相似情境下应给出相似的答案。
外部一致性:对比样本答案与已知的知识库、专家判断或公认的基准结果,确保答案符合领域共识和常识。
难度适配(Difficulty Calibration):
难易程度分布:分析样本集中简单、中等、复杂任务的比例,确保微调数据集包含不同难度级别的样本,有助于模型逐步提升处理复杂指令的能力。
噪声控制(Noise Reduction):
标签错误检查:识别并剔除标注错误或不一致的样本,确保答案与指令、内容间的映射关系正确无误。
数据清洗:去除重复样本、无关内容或低质量文本,提升数据集的整体纯净度。
可以看出评估微调样本质量属于一项涉及多方面考量的综合性工作,旨在确保用于指令微调的数据既能有效驱动模型学习指令理解与执行的核心技能,又能促进模型在实际应用中展现卓越的性能和广泛的适应性。通过严谨的质量评估与持续优化,可以最大限度地利用有限的高质量样本资源,实现大模型指令微调的高效与精准。
2.4 如何缓解SFT后模型通用能力的下降?
多任务微调:如果希望模型保持多任务泛化能力,可以一次性对多个任务执行微调,在训练数据中增加一些通用数据;
数据回放:在SFT数据后,再做一下通用能力的SFT,但是这样做的一个风险是之前微调的专业能力会受到影响(死锁了 );
2.5 进行SFT时,基座模型选用Chat还是Base模型?
选Base还是Chat模型,首先先熟悉Base和Chat是两种不同的大模型,它们在训练数据、应用场景和模型特性上有所区别。
在训练数据方面,Base模型是基于海量语料库进行的无监督学习。它从大量文本中学习语言模式和知识,而不需要人工标注或监督。相比之下,Chat模型则是在指令微调的有监督学习下进行训练的。这意味着它使用人工标注的数据集进行训练,以便更好地理解和响应特定指令。
在应用场景上,Base模型主要用于无监督学习任务,如文本分类、情感分析、摘要生成等。这些任务主要关注文本内容的理解和处理,而不需要对特定指令做出响应。相反,Chat模型则主要用于指令学习任务,如问答系统、对话生成、智能客服等。在这些任务中,模型需要理解和响应人类的指令,以提供准确和有用的信息。
在模型特性上,Base模型预训练之后没有做任何调整。它提供了基本的语言理解和生成能力,但可能需要针对特定任务进行微调或优化。而Chat模型则是在Base模型上进行微调的版本,它通过指令微调和人工反馈强化学习等方法,使模型更加符合人类的价值观和指令要求。
总之,Base和Chat是两种不同的大模型,它们在训练数据、应用场景和模型特性上有所区别。Base主要用于无监督学习任务,而Chat则专注于指令学习任务。在模型特性上,Chat通常在Base上进行微调,以更好地适应特定任务的需求。
根据以上区别,在选择基座模型时也要考虑数据量和任务差别难度,对于训练数据量少的,任务和基座大模型比较优秀能力接近的选chat模型。对于训练数据量比较大,或任务与chat版本的相似的能力比较差,选择base版本。
另一种说法是base模型可以更方便做知识注入,而chat版本是做过对其的,不好做知识注入。所以基于base的SFT可以做的上限更高,更方便做知识的注入,而基于chat模型的SFT是做的样式学习或者指令学习。但是base也存在没有对其的风险,输出可能和希望有差距,需要更多的调优和对齐。
2.6 SFT需要多少条数据?
这个没有一个明确的答案,但是根据大家的经验和一些开源的技术报告来看,SFT的数据一般在2k-10k之间,epoch可以根据SFT数据设定为2-10个epoch,epoch和数据量成反比,SFT的数据在准确,不在量大,所以在数据比较精确的情况下,一般5k的数据5个epoch,就能得到一个不错的效果。
另外,对于一般的人类阅读和生成能力,仅在1000个样本上就可以有不错的效果,但是对于数学推理、代码生成等复杂任务,需要较大的数据量。
2.7 SFT的数据配比?
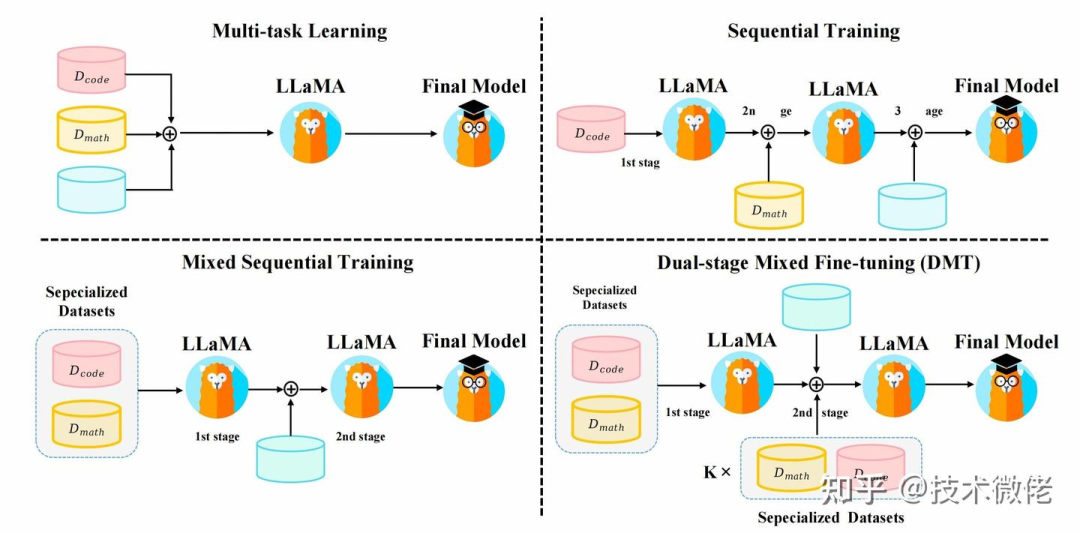
大模型混合多种能力项数据进行微调时,会呈现高资源冲突,低资源增益的现象。提出的DMT策略通过在第一阶段微调特定能力数据,在第二阶段微调通用数据+少量的特定能力数据,可以在保留通用能力的同时,极大程度地挽救大模型对特定能力的灾难性遗忘,这为SFT的数据组成问题提供了一个简单易行的训练策略。值得注意的是,第二阶段微调时混合的特定能力数据量需要根据需求而定。
2.8 大模型在进行SFT的时候是在学习什么?
指令追随和样式学习:并没有学习到世界知识;
领域适用性:特定领域的语言、术语、上下文内容,优化其在特定领域的表现;
激发大模型能力:通过SFT激发大模型在特定领域的能力;
安全性:在SFT中增加一些对抗数据,提高模型的鲁棒性和安全意识。
2.9 预训练和SFT的区别?
目的:预训练是通过大量无标注数据学习知识,SFT是在少量标注数据上学习指令;
数据类型:预训练大量无标注数据,SFT少量标注数据;
模型类型上:预训练是一般学习模式,SFT是在特定任务服务;
2.10 微调模型需要多大的显存?
这块要分两类,分SFT和PEFT,他们两个的显存差距比较大;
SFT:全参数微调,包括参数的梯度、优化器都要激活,如果一个1B(fp32)的模型需要显存如下:
模型需要显存:1B* 4byte = 4GB
梯度显存(每个参数都需要有一个梯度):4GB
优化器显存:以adamw优化器为例,他需要一阶动量+二阶动量=4GB+4GB=8GB;
PEFT:需要的显存与模型没有大的区别,主要看PEFT部分,大概是几M到几GB。
2.11 多轮对话任务如何微调模型?
多轮对话的核心是指令追随。
① 自动驾驶论文辅导来啦

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









