



编辑 | 量子位
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
成本不到150元,训练出一个媲美DeepSeek-R1和OpenAI o1的推理模型?!
这不是洋葱新闻,而是AI教母李飞飞、斯坦福大学、华盛顿大学、艾伦人工智能实验室等携手推出的最新杰作:s1。
在数学和编程能力的评测集上,s1的表现比肩DeepSeek-R1和o1。
而训一个这样性能的模型,团队仅仅用了16个英伟达H100,训练耗时26分钟。
据TechCrunch,这个训练过程消耗了不到50美元的云计算成本,约合人民币364.61元;而s1模型作者之一表示,训练s1所需的计算资源,在当下约花20美元(约145.844元)就能租到。
怎么做到的???
s1团队表示,秘诀只有一个:蒸馏。
简单来说,团队以阿里通义团队的Qwen2.5- 32B-Instruct作为基础模型,通过蒸馏谷歌DeepMind的推理模型Gemini 2.0 Flash Thinking实验版,最终得到了s1模型。
为了训练s1,研究团队创建了一个包含1000个问题(精心挑选那种)的数据集,且每个问题都附有答案,以及Gemini 2.0 Flash Thinking实验版的思考过程。
目前,项目论文《s1: Simple test-time scaling》已经挂上arXiv,模型s1也已在GitHub上开源,研究团队提供了训练它的数据和代码。
150元成本,训练26分钟
s1团队搞这个花活,起因是OpenAI o1展现了Test-time Scaling的能力。
即「在推理阶段通过增加计算资源或时间,来提升大模型的性能」,这是原本预训练Scaling Law达到瓶颈后的一种新Scaling。
但OpenAI并未公开是如何实现这一点的。
在复现狂潮之下,s1团队的目标是寻找到Test-time Scaling的简单方法。

过程中,研究人员先构建了一个1000个样本的数据集,名为s1K。
起初,在遵循质量、难度、多样性原则的基础上,这个数据集收集了来自MATH、AGIEval等诸多来源的59029个问题。
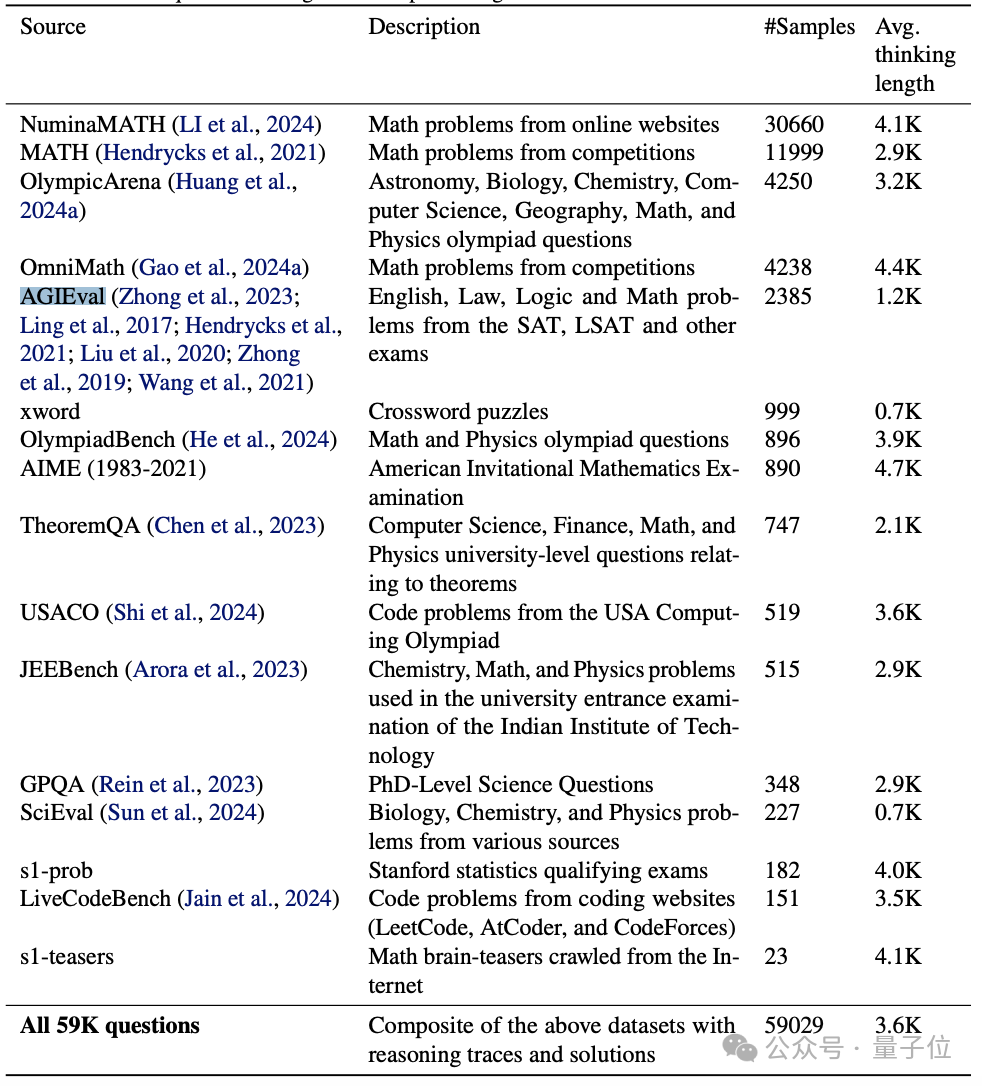
经去重、去噪后,通过质量筛选、基于模型性能和推理痕迹长度的难度筛选,以及基于数学学科分类的多样性筛选,最终留下了一个涵盖1000个精心挑选过的问题的数据集。
且每个问题都附有答案,以及谷歌Gemini 2.0 Flash Thinking实验版的模型思考过程。
这就是最终的s1K。
研究人员表示,Test-time Scaling有2种。
第1种,顺序Scaling,较晚的计算取决于焦躁的计算(如较长的推理轨迹)。
第2种,并行Scaling,be like计算独立运行(如多数投票任务)。
s1团队专注于顺序这部分,原因是团队“从直觉上”认为它可以起到更好的Scaling——因为后面的计算可以以中间结果为基础,从而允许更深入的推理和迭代细化。
基于此,s1团队提出了新的顺序Scaling方法,以及对应的Benchmark。

研究过程中,团队提出了一种简单的解码时间干预方法budget forcing,在测试时强制设定最大和/或最小的思考token数量。
具体来说,研究者使用了一种很简单的办法:
直接添加“end-of-thinking token分隔符”和“Final Answer”,来强制设定思考token数量上限,从而让模型提前结束思考阶段,并促使它提供当前思考过程中的最佳答案。
为了强制设定思考过程的token数量下限,团队又禁止模型生成“end-of-thinking token分隔符”,并可以选择在模型当前推理轨迹中添加“wait”这个词,鼓励它多想想,反思反思当前的思考结果,引导最佳答案。
以下是budget forcing这个办法的一个实操示例:

团队还为budget forcing提供了baseline。
一是条件长度控制方法(Conditional length-control methods),该方法依赖于,在提示中告诉模型它应该花费多长时间来生成输出。
团队按颗粒度将它们分为Token-conditional控制、步骤条件控制和类条件控制。
Token-conditional控制:在提示词中,指定Thinking Tokens的上限;
步骤条件控制:指定一个思考步骤的上限。其中每个步骤约100个tokens;
类条件控制:编写两个通用提示,告诉模型思考短时间或长时间。
二是拒绝抽样(rejection sampling)。
即在抽样过程中,若某一生成内容符合预先设定的计算预算,就停止计算。
该算法通过其长度来捕捉响应的后验分布。

而s1模型的整个训练过程,只用了不到半个小时——
团队在论文中表示,他们使用Qwen2.532B-Instruct模型在s1K数据集上进行SFT,使用16个英伟达H100,训练耗时26分钟。
s1研究团队的Niklas Muennighoff(斯坦福大学研究员)告诉TechCrunch,训练s1所需的计算资源,在当下约花20美元就能租到。
研究新发现:频繁抑制思考会导致死循环
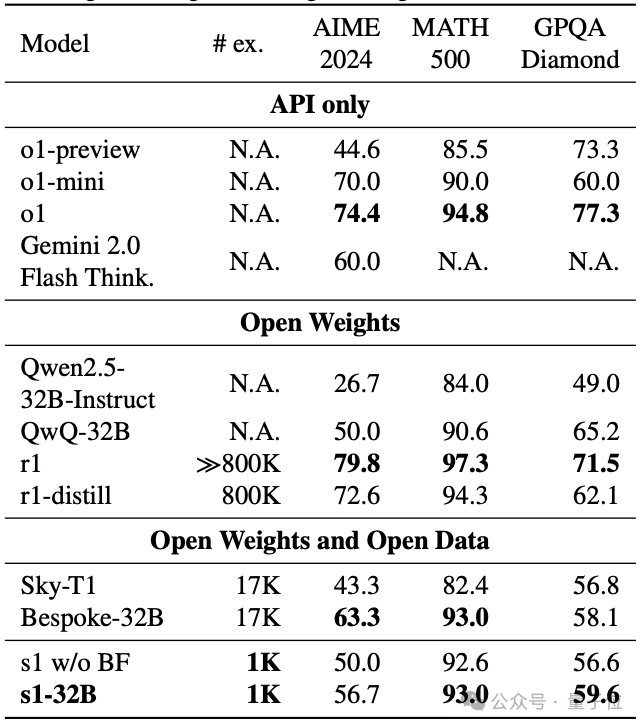
训出模型后,团队选用3个推理基准测试,把s1-32B和OpenAI o1系列、DeepSeek-R1系列、阿里通义Qwen2.5系列/QWQ、昆仑万维Sky系列、Gemini 2.0 Flash Thinking实验版等多个模型进行对比。
3个推理基准测试如下:
AIME24:2024年美国数学邀请考试中使用的30个问题
MATH500:不同难度的竞赛数学问题的基准
GPQA Diamond:生物、化学和物理领域的198个博士级问题
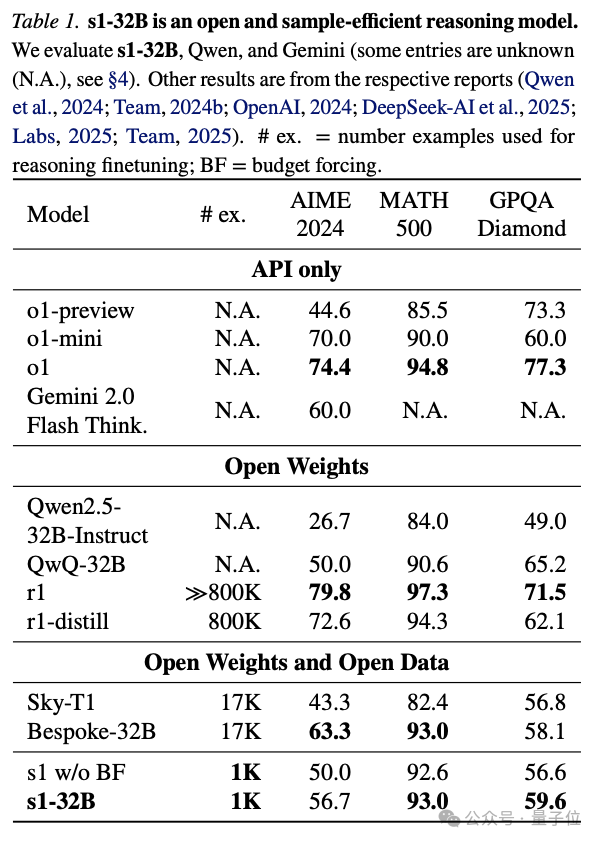
整体来说,采用了budget forcing的s1-32B扩展了更多的test-time compute。
评测数据显示,s1-32B在MATH500上拿到了93.0的成绩,超过o1-mini,媲美o1和DeepSeek-R1。
不过,如下图所示,团队发现,虽然可以用budget forcing和更多的test-time compute来提高s1在AIME24上的性能,在AIME24上比 o1-preview最高提升27%。
但曲线最终在性能提升6倍后趋于平缓。
由此,团队在论文中写道:
过于频繁地抑制思考结束标记分隔符,会导致模型进入重复循环,而不是继续推理。
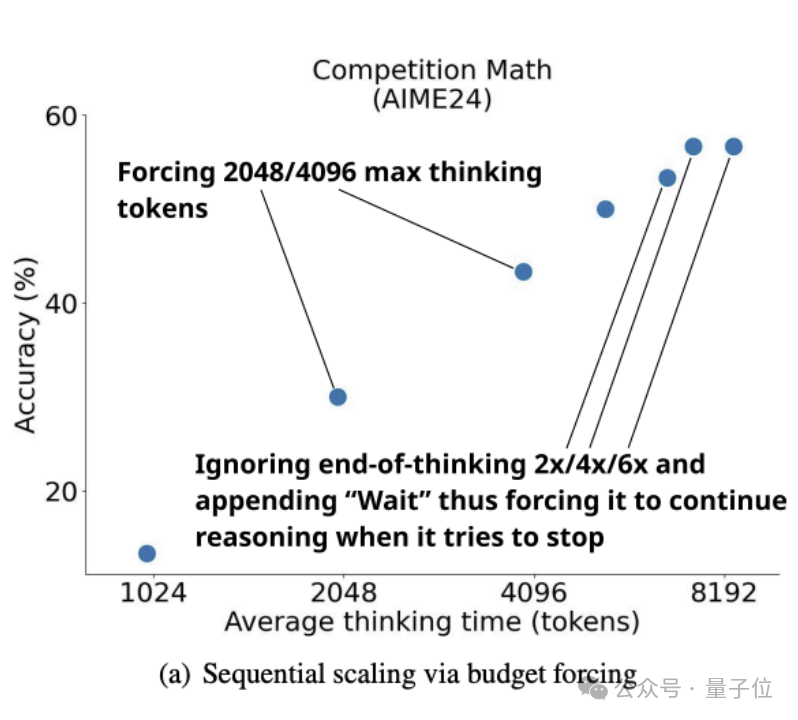
而如下图所示,在s1K上训练Qwen2.5-32B-Instruct来得到s1-32B,并为它配备了简单的budget forcing后,它采用了不同的scaling范式。
具体来说,通过多数投票在基础模型上对test-time compute进行Scale的方法,训出的模型无法赶上s1-32B的性能。
这就验证了团队之前的“直觉”,即顺序Scaling比并行Scaling更有效。
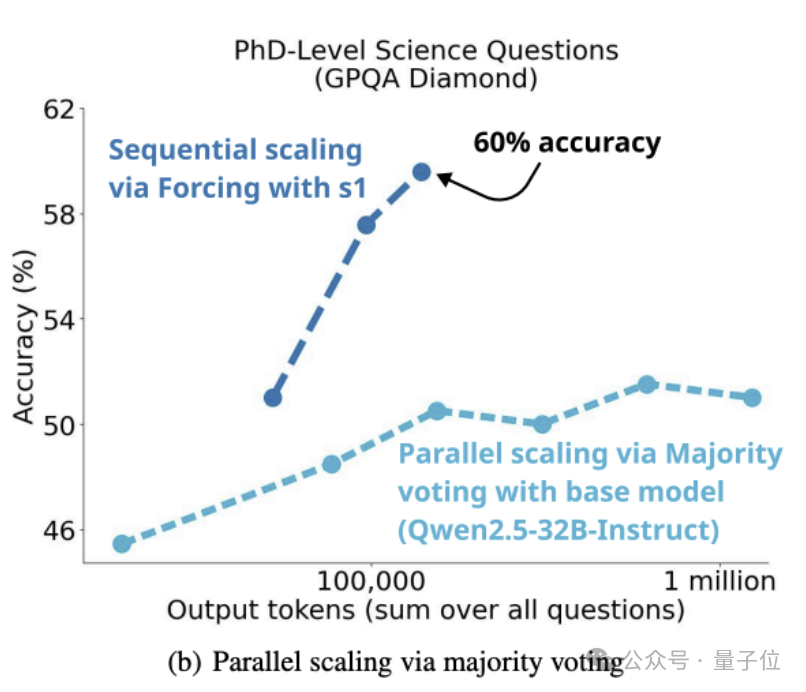
此外,团队提到,s1-32B仅仅使用了1000个样本训练,在AIME24上的成绩就能接近Gemini 2.0 Thinking,是“样本效率最高的开源数据推理模型”。
研究人员还表示,Budget forcing在控制、缩放和性能指标上表现最佳。
而其它方法,如Token-conditional控制、步骤条件控制、类条件控制等,均存在各种问题。
One More Thing
s1模型,是在一个1000个精挑细选的小样本数据集上,通过SFT,让小模型能力在数学等评测集上性能飙升的研究。
但结合近期刷爆全网的DeepSeek-R1——以1/50成本比肩o1性能——背后的故事,可以窥见模型推理技术的更多值得挖掘之处。
模型蒸馏技术加持下,DeepSeek-R1的训练成本震撼硅谷。
现在,AI教母李飞飞等,又一次运用「蒸馏」,花费低到令人咋舌的训练成本,做出了一个能媲美顶尖推理模型的32B推理模型。
一起期待大模型技术更精彩的2025年吧~
arXiv:
https://arxiv.org/pdf/2501.19393
GitHub:
https://github.com/simplescaling/s1
参考链接:
https://techcrunch.com/2025/02/05/researchers-created-an-open-rival-to-openais-o1-reasoning-model-for-under-50/
— 完 —
① 自动驾驶论文辅导来啦

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵


















 121
121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









