



点击下方卡片,关注“3D视觉之心”公众号
第一时间获取3D视觉干货
>>点击进入→3D视觉之心技术交流群
基于模型的方法如何加速
特征匹配是计算机视觉中多个几何任务的关键组成部分,这些任务涉及在 3D 地图中的图像点之间建立对应关系,例如视觉定位、同步定位与建图(SLAM)、运动结构恢复(SfM)等。通常,这些视觉技术通过匹配图像对中检测到的局部特征来实现,其中描述子向量用于编码其视觉外观。为了实现成功匹配,这些描述子必须既具备可重复性,又具备可靠性。然而,诸如无纹理环境、光照变化和视角变化等挑战使得生成唯一且具备区分度的描述子变得困难。
为了解决不完美特征描述子的不足,研究人员提出了多种基于深度学习的方法。近年来,Transformer 架构已成为视觉应用中的事实标准,包括特征匹配任务。其中,LoFTR作为一种无检测器的稠密局部特征匹配模型,通过在粗到细匹配过程中使用 Transformer,与之前的方法相比,显著提高了匹配精度。然而,该方法在需要低延迟的应用(如 SLAM)中表现较慢。此外,SuperGlue和 LightGlue等稀疏特征匹配方法也被提出,它们同样采用基于 Transformer 的架构来学习图像对之间的匹配,并在室内外环境下展示了鲁棒的特征匹配性能,同时在速度和准确性之间取得了一定的平衡。然而,Transformer 模型的性能仍然伴随着较大的计算资源需求和训练难度。
与此同时,Mamba作为一种高效处理序列数据的新兴架构被提出。由于其能够选择性地关注输入序列中的不同部分,Mamba 已被应用于语言和视觉任务,并在训练和推理速度上表现优异,具有较强的性能优势。

本文介绍一种基于 Mamba 的局部特征匹配模型,称为 MambaGlue[1],它结合了 Mamba 和 Transformer 架构的优点。MambaGlue 通过 Mamba 架构的选择性输入关注能力,改进了整个模型的各层性能。此外,我们提出了一种网络结构,该网络可预测当前层估计的匹配对应关系的可靠性。通过这种方式,该模块允许 MambaGlue 在适应图像对匹配难度的同时,决定是否提前终止迭代,从而减少不必要的计算成本。我们的新颖方法通过精确适应特征匹配的难度,在低延迟的前提下实现了显著的精度提升。
项目链接:https://github.com/url-kaist/MambaGlue
主要贡献:
MambaAttention Mixer:提出了一种新型的 MambaAttention mixer 块,该块利用 Mamba 架构的选择性输入关注能力,并结合注意力机制,以提升各层的性能。
深度置信度分数回归器(Deep Confidence Score Regressor):进一步提出了一种基于多层感知机(MLP)的网络,该网络可以预测置信度分数,从而评估某个特征点是否可以可靠匹配。
优化的匹配性能:在保持低延迟的同时,相较于最新的基准方法,实现了优越的匹配性能。
混合架构的优越性:值得注意的是,MambaGlue 作为一种 Mamba 和 Transformer 结合的简单混合方案,优于当前最先进的稀疏特征匹配方法。
MambaGlue 架构
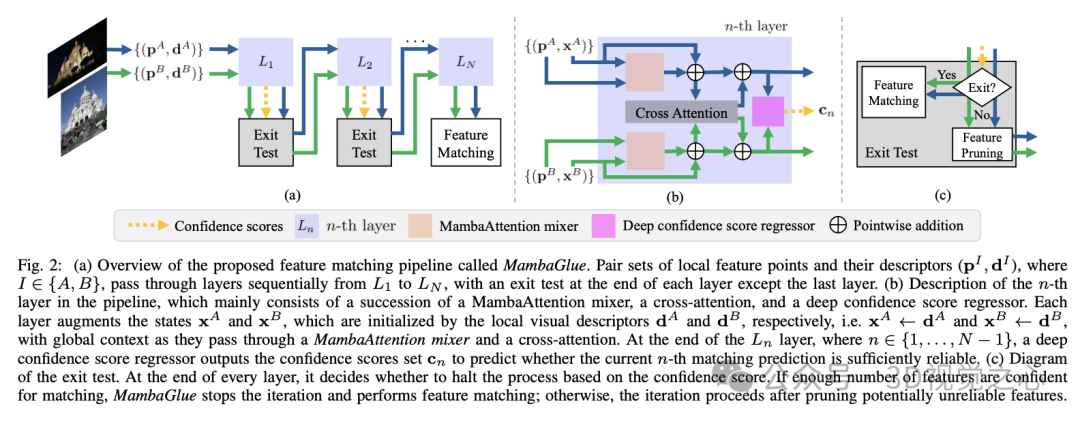
MambaGlue 特征匹配方法的整体框架,如 图 2 所示。MambaGlue 主要由 N 个相同的层级 组成的堆叠层流水线(stacked layer pipeline)构成。输入由 两幅图像 A 和 B 中的局部特征集 组成。我们分别将 A 和 B 的特征集表示为 (F_A) 和 (F_B),其定义如下:
其中,(i) 和 (j) 分别表示图像 A 和 B 的特征索引,(N_A) 和 (N_B) 分别为 A 和 B 中的特征点数量,即 (|A| = N_A) 和 (|B| = N_B)。为了简化表示,我们用 (p^I_q) 和 (d^I_q) 分别表示特征点的位置和 d 维描述子,其中 (I \in {A,B})。
这些局部特征按照以下顺序依次通过流水线的各层:
MambaAttention Mixer(MambaAttention 混合模块)
Cross-Attention(交叉注意力)
Deep Confidence Score Regressor(深度置信度分数回归器)
这三个模块协同工作,以增强特征描述子的表达能力。
在第 n 层((L_n))的末尾,深度置信度分数回归器会输出一个 置信度分数集合 (c_n),用于预测当前层匹配预测的可靠性。具体来说,该置信度分数集合定义如下:
其中,(K_n) 是第 (n) 层中所有特征点的索引集合,即 (|K_n| \leq |N_A| + |N_B|)。
接下来,系统会执行 退出测试(Exit Test),以决定是否终止迭代,从而减少不必要的计算成本:
如果足够多的特征点具有较高的置信度,则 MambaGlue 停止迭代 并执行最终的特征匹配;
否则,进入 特征点剪枝(Feature Pruning),移除可能不可靠的特征点,并进入下一层计算。
当系统确定已经找到足够的匹配点时,迭代终止,并执行最终的匹配步骤,输出最终匹配结果集合:
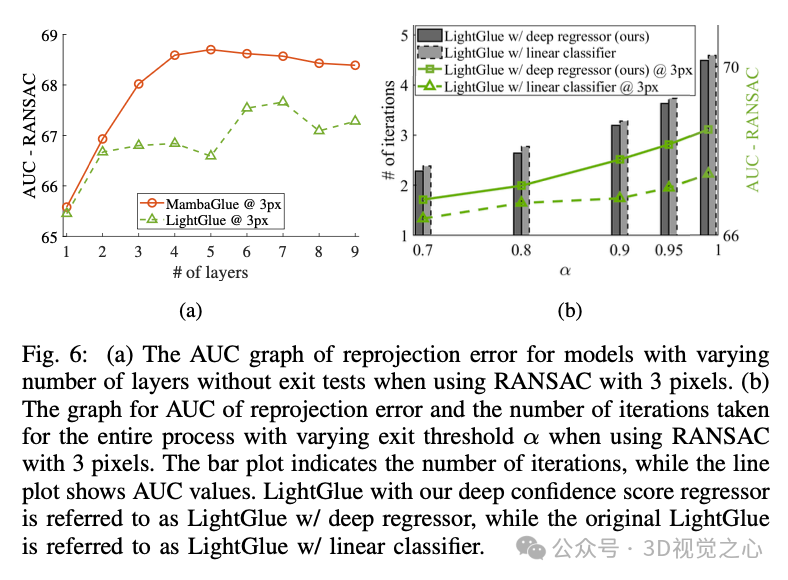
特征剪枝和匹配步骤的退出测试与 LightGlue相同,但 MambaGlue 提供了更高的精度和更强的鲁棒性。
MambaAttention Mixer
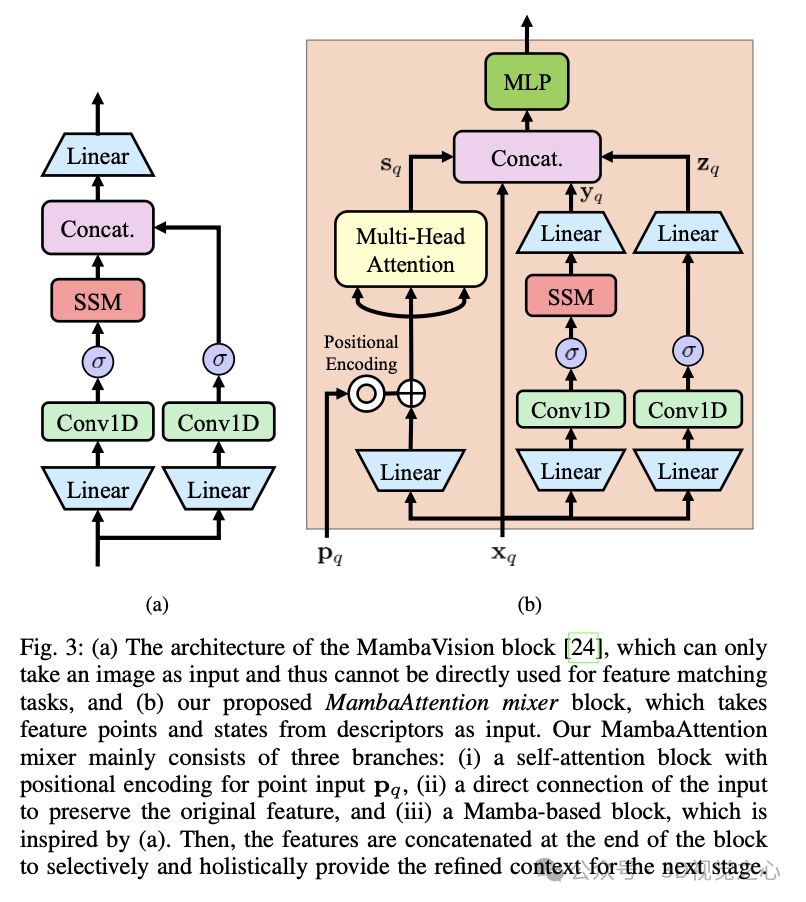
受 MambaVision 的启发,我们提出了一种基于 Mamba 的自注意力块,称为 MambaAttention Mixer。该模块的设计如图 3(b) 所示,主要由三个分支组成:
自注意力(Self-Attention)分支,结合位置编码(Positional Encoding)来处理特征点的位置信息;
直接连接输入的分支,用于保留原始特征信息,避免信息损失;
Mamba 计算路径,借鉴 MambaVision 结构,以增强模型对长距离依赖关系的捕捉能力。
上述三条信息路径的结合,使 MambaAttention Mixer 既能全局感知特征信息,又能选择性地关注最相关的输入,从而提高匹配的准确性和鲁棒性。
在每一层(见图 2(b))中,MambaAttention Mixer 和交叉注意力(Cross-Attention)交替作用。我们为目标图像 I 的每个局部特征点分配一个状态向量 ,并初始化为其对应的描述子:
随后,该状态经过 MambaAttention Mixer 和交叉注意力模块的更新。
在 MambaAttention Mixer 计算过程中,每个点的特征状态 会被更新为:
其中:
([ \cdot \mid \cdot ]) 表示向量拼接;
是 MambaAttention Mixer 提取的信息;
交叉注意力模块(Cross-Attention)用于聚合来自匹配图像的信息,而 MambaAttention Mixer 主要用于从当前图像的局部特征中提取信息。
MambaAttention Mixer 计算的信息 由三部分组成:
其中:
是基于自注意力计算得到的全局特征;
和 来自 Mamba 计算路径,分别用于增强短程和长程特征的表达能力。
具体来说, 通过标准的自注意力机制计算:
´íÎó
其中:
是投影矩阵;
是注意力权重,定义为:
其中 和 分别是通过线性变换得到的键(Key)和查询(Query)向量, 是旋转位置编码(Rotary Position Encoding)。
在 Mamba 计算路径中,我们定义一个特征编码函数 来表示经过卷积和激活函数处理后的特征表示:
其中:
(\text{Linear}(d_{in}, d_{out})) 表示输入维度为 ,输出维度为 的线性变换;
(\text{Conv}(\cdot)) 表示一维卷积操作;
(\sigma) 是 Sigmoid 线性单元(SiLU)激活函数。
利用该编码函数,我们计算 和 :
其中,(\text{Scan}(\cdot)) 是选择性扫描操作(Selective Scan Operation),用于高效提取输入序列中的最相关片段。
通过将 MambaAttention Mixer 与交叉注意力模块结合,MambaGlue 既能全局捕捉特征点之间的长距离依赖关系,又能局部关注匹配点的信息,从而提高特征匹配的精度和计算效率。
退出测试以实现提前终止
我们采用退出测试来进行高效的提前终止,以减少不必要的计算成本。当用户启用该功能时,该模块可以在检测到当前迭代已经产生足够数量的可靠匹配点时提前停止计算,从而降低推理开销。
假设某个点在图像 A 或 B 中的置信度分数为 ,如果其置信度超过某个用户定义的阈值 ,则认为该点是 可信的,即:
退出测试 在每一层的末尾执行,定义如下:
如果否则
其中:
(\alpha) 表示用户定义的最低可信匹配比例。换句话说,退出测试在每一层后都会检查,**如果当前层中可信匹配点的比例超过阈值 **,则停止后续的计算。
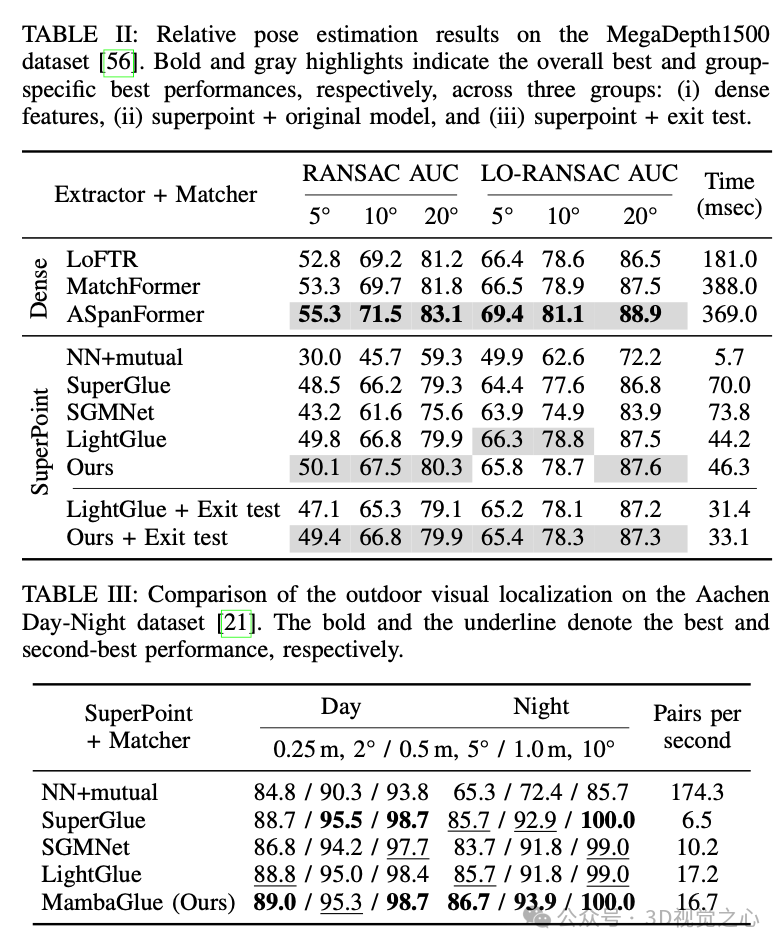
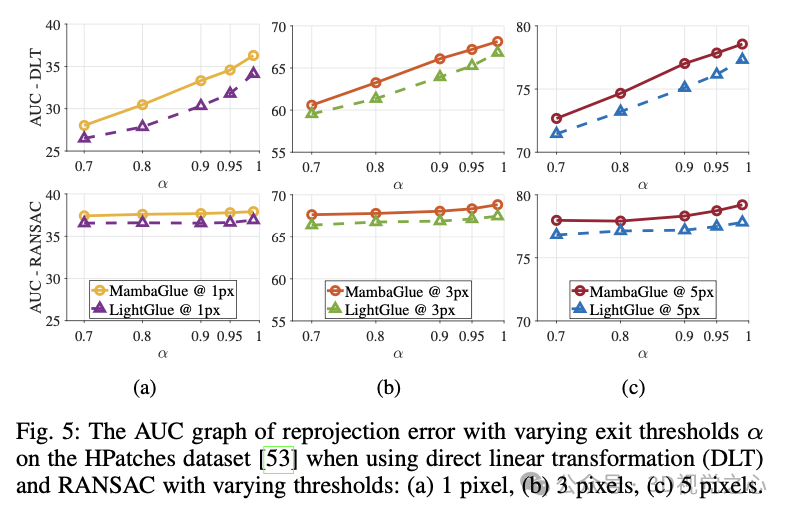
在实验中,我们设置 为 0.95,即当 95% 以上的匹配点达到了置信度要求后,就提前终止迭代,以节省计算资源。该退出机制减少了计算量,同时保持了与不使用提前终止时相似的匹配性能。
在我们的方法中,退出测试可以显著提高推理效率,并且能够根据数据集的不同需求进行调整。对于某些应用场景(如实时视觉任务),可以设定更严格的退出阈值 ,从而进一步加快匹配速度,而在需要高精度的应用中,则可以选择更低的 值,以确保匹配质量。
损失函数
我们在两个阶段训练 MambaGlue,类似于 LightGlue 的训练过程。首先,我们训练网络来预测匹配关系,这时不使用退出测试。我们训练时只关注匹配预测的准确性,而不考虑提前终止。然后,我们单独训练深度置信度分数回归器,以保证退出测试的准确性。第二阶段的训练不会影响第一阶段训练好的匹配预测能力。
我们使用最大似然估计的损失函数来训练匹配预测矩阵 P。匹配预测矩阵 P 通过两幅图像之间的两视图变换获得真实标签,这些标签是基于相机的相对位姿和深度计算得出的。
我们定义的真实匹配记作集合 M,其中包含投影误差低且深度一致的点对。而不可靠的点记作 A 和 B 中的子集 Ã 和 B̃,这些点的投影误差或深度误差较大,因此不能作为可靠的匹配点。
损失函数 L 设计如下:
其中:
Pij 是匹配概率矩阵;
σAi 和 σBj 分别是图像 A 和图像 B 中每个点的匹配置信度。
与 LightGlue 的比较
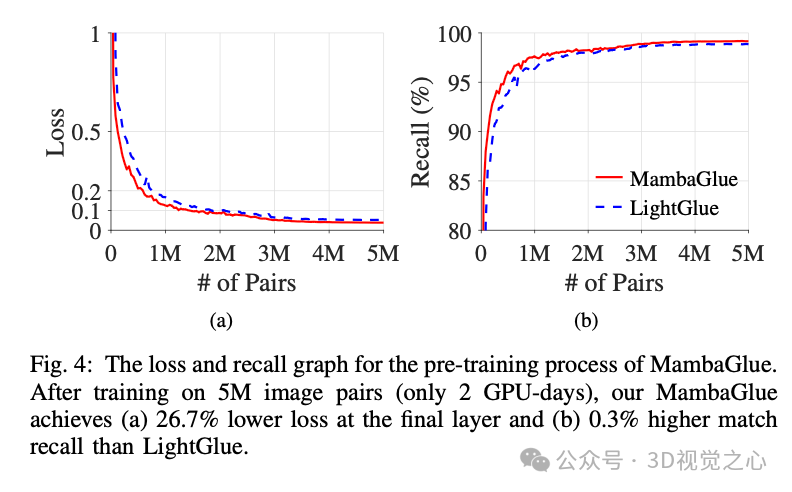
总的来说,我们的 MambaGlue 基于 LightGlue 构建,但在精度和效率上有所提升。MambaGlue 在每一层的精度更高,因此总体上更为准确。通过结合 Mamba 和自注意力,MambaGlue 能够选择性地且全局地处理输入数据,增强了鲁棒性,这超出了仅使用 Transformer 架构的可能性。此外,在每一层的末尾,所提出的深度置信度分数回归器提供了对状态的层次化理解,相比于仅使用单一线性层的结果,生成了更加丰富的上下文输出。尽管做出了这些改进,损失和召回图表显示,MambaGlue 仍然易于训练,甚至比 LightGlue 收敛更快,如图 4 所示。
实验效果
总结一下
MambaGlue是一种快速且鲁棒的匹配方法,该方法结合了 Mamba 和 Transformer 架构,以实现准确且低延迟的局部特征匹配。特别是,我们提出了 MambaAttention mixer 模块,以增强自注意力的能力,并引入深度置信度分数回归器,以预测可靠的特征匹配结果。实验结果表明,MambaGlue 在准确性和速度之间达到了最佳平衡。
局限性:尽管 MambaGlue 在特征匹配方面取得了显著的改进,但该模型仍然依赖于 Transformer 架构,这使得与纯 Mamba 架构相比,其计算资源需求仍然较高。
未来研究:计划构建一个仅基于 Mamba 的模型,以实现更加轻量化和快速的特征匹配。
参考
[1] MambaGlue: Fast and Robust Local Feature Matching With Mamba
本文仅做学术分享,论文汇总于『3D视觉之心知识星球』,欢迎加入交流!
【3D视觉之心】技术交流群
3D视觉之心是面向3D视觉感知方向相关的交流社区,由业内顶尖的3D视觉团队创办!聚焦三维重建、Nerf、点云处理、视觉SLAM、激光SLAM、多传感器标定、多传感器融合、深度估计、摄影几何、求职交流等方向。扫码添加小助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

扫码添加小助理进群
【3D视觉之心】知识星球
3D视觉之心知识星球主打3D感知全技术栈学习,星球内部形成了视觉/激光/多传感器融合SLAM、传感器标定、点云处理与重建、视觉三维重建、NeRF与Gaussian Splatting、结构光、工业视觉、高精地图等近15个全栈学习路线,每天分享干货、代码与论文,星球内嘉宾日常答疑解惑,交流工作与职场问题。


















 1621
1621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









