



点击下方卡片,关注“具身智能之心”公众号
作者 | 具身智能之心 编辑 | 具身智能之心
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
写在前面&出发点
现代机器人在形状、尺寸以及用于感知和与环境交互的传感器配置上差异显著。然而,大多数导航策略都是针对特定机器人实体的;在一个机器人配置上学习的策略通常无法优雅地泛化到另一个机器人上。即使机器人实体的尺寸或摄像头视角发生微小变化,也可能导致导航失败。随着近年来定制硬件开发的激增,有必要学习一种可以迁移到其他机器人实体的单一策略,从而消除为每个特定机器人(重新)训练的需求。我们这里介绍了RING(Robotic Indoor Navigation Generalist,机器人室内导航通用系统),这是一种与机器人实体无关的策略,仅通过在大量具有不同随机初始化实体的模拟环境中进行训练而得出。这里增强了AI2-THOR模拟器的能力,使其能够实例化具有可控配置的机器人实体,这些配置在机器人尺寸、旋转中心点以及摄像头配置上各不相同。在视觉对象目标导航任务中,RING在真实环境中未见过的机器人平台(Stretch RE-1、LoCoBot、Unitree的Go1)上表现稳健,在模拟环境中的5个实体和真实世界中的4个机器人平台上分别实现了72.1%和78.9%的平均成功率。
行业介绍
机器人实体形态多样且不断进化,以更好地适应新环境和新任务。这种身体配置的多样性:包括尺寸、形状、轮式或腿式移动方式以及传感器配置的差异。这不仅决定了机器人如何感知世界,还决定了它们如何在世界中行动。具有宽视场(FoV)或多个相机的机器人可以快速扫描周围环境,而视野较窄的机器人可能需要更积极地探索房间。小型机器人可以穿过狭窄的空间,低矮的机器人可以躲在家具下方,而大型机器人可能需要遵循更保守的路线。实体对行为的影响意味着,针对一种甚至多种设计训练的策略,在领域外往往表现不佳。
当下在可扩展的跨实体训练和通用导航策略开发方面已取得了一些进展,虽然这些方法在某些未见过的实体上表现出一定的迁移能力,但它们需要构建拓扑地图或图,并且在实体发生相对较小变化(例如,同一机器人的摄像头位置调整)时性能会下降。这可能是由于这些方法依赖于公共数据集中可用的少量现实世界数据,总数仅约20个实体。这凸显了需要一种更全面的解决方案,该方案能够可靠地覆盖各种可能的实体,而无需重新训练或额外的适应。
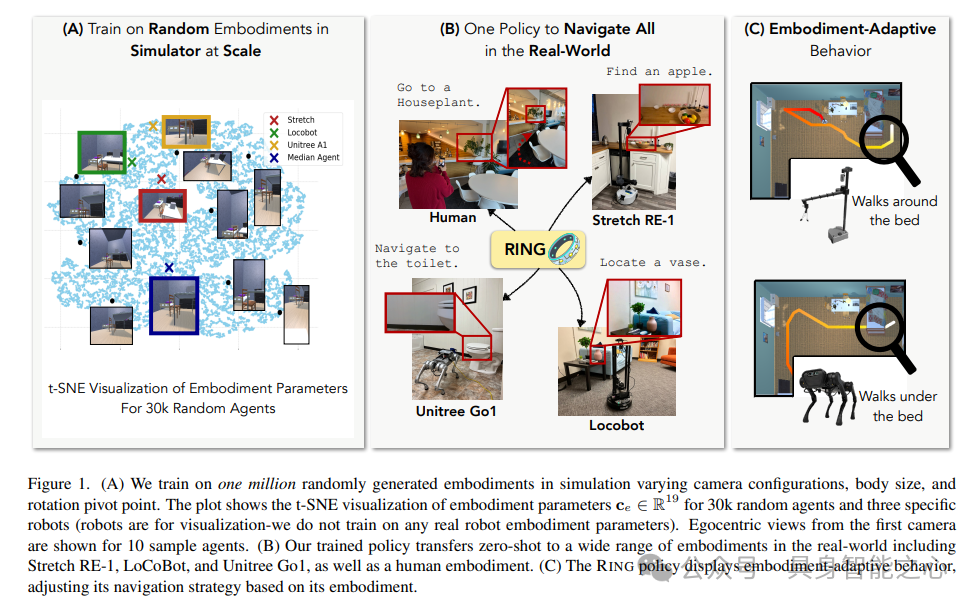
这里介绍了RING,一个机器人室内导航通用系统。RING完全在模拟环境中进行训练,没有使用任何真实的机器人实体。换句话说,在评估时所使用的所有机器人平台(即Stretch RE-1、LoCoBot、Unitree的A1)在RING的训练过程中都是未见过的。利用模拟环境随机采样了100万个智能体身体配置,这些配置在机器人的摄像头参数、碰撞体大小和旋转中心上有所不同。每个实体由一个尺寸不同的碰撞盒以及随机视野和尺寸的摄像头组成,这些摄像头被随机放置在碰撞盒内。图1-A展示了我们在生成数据中3万个随机智能体的身体参数的t-SNE 可视化图。
我们的方法受到了最近在仅在大规模模拟环境中训练就能在真实世界实验中取得成功的启发。模拟训练能够充分利用AI2-THOR模拟器中庞大的场景(150,000个ProcTHOR房屋)和物体(来自Objaverse的40,000多个标注的3D物体)。通过对视觉观测进行广泛的域随机化并使用预训练的视觉编码器,使得在模拟环境中训练的策略能够弥合模拟与现实的差距。遵循FLaRe 中概述的训练程序,首先在从100万个随机实体中收集的专家轨迹上训练我们的策略,然后在模拟器内通过基于策略的强化学习(RL)对其进行微调。
结果表明,RING能够泛化到真正未见过的实体形态。尽管RING仅在模拟环境中进行训练,且无法访问真实的机器人配置,但它能够泛化到多种真实的机器人实体形态,而无需任何适应。在多种实体形态下,包括Stretch RE1、LoCoBot、Unitree的A1,甚至是“导航助手”(其中人类用户通过手机捕捉以ego为中心的观测,并提示RING策略预测导航动作)的零样本设置下评估了策略。RING在模拟环境和真实环境中均取得了平均72.1%和78.9%的成功率,显著优于最佳基线。
这里强调了RING的三个关键特性:1)它能够在未见过的实体形态上实现零样本泛化,并保持一致的高性能;2)它能够无需任何适应或针对真实世界的微调,即可实现零样本迁移到真实世界;3)通过极少的微调,它可以适应特定实体的策略,并获得更好的性能;4)在推理时,它能够根据实体形态动态调整其行为。RING可以直接部署到任何机器人平台上进行导航,安装简便,社区内的研究人员即可直接使用。后续将发布预训练模型、生成的数据和训练代码。
相关工作汇总
跨具身性。跨具身性训练已经引起了研究界的大量关注。可以说,Open-X-Embodiment(OXE)是近期大量研究工作中最具代表性的成果之一。OXE是多方合作努力的结晶,旨在涵盖多种机器人任务,特别是操作任务。与RT-2[5]相比,OXE在RT-X中的使用在突发技能评估中带来了显著的性能提升。尽管其数据集包含了22种具身形态中的150万条轨迹,但现实世界中数据收集的巨大成本使得进一步扩展变得具有挑战性。
CrossFormer在30个机器人的90万条轨迹上训练了一个基于Transformer的策略,其中包括OXE的一个子集、来自GNM的导航数据、来自DROID的操作数据以及其他收集的数据。由于训练期间观察到的具身形态数量相对较少,且目标为低级控制,因此它无法泛化到未见过的具身形态。GET-zero专注于灵巧操作,并提议通过连接图将具身形态的结构告知策略,以引导注意力。相比之下,我们为训练策略生成了任意数量的具身形态,使得能够在不访问具身形态结构的情况下,实现向新具身形态的零样本部署。
基础导航策略。随着近期在点目标导航、运动、敏捷控制、探索和social导航等领域取得的进展,由于在有效探索和语义理解能力方面的欠缺,在语义或目标物体导航(ObjectNav)等更细致的任务中取得可比结果仍然难以实现。最近,借助强大的预训练基础视觉模型和大规模程序生成的虚拟环境,通过从最短路径轨迹进行模仿学习(IL)、强化学习(RL)或其组合,在特定具身形态上的端到端ObjectNav策略学习方面取得了显著进展。在图像目标导航方面,NoMaD扩展了ViNT,使用扩散策略来控制单一具身形态。本着同样的目标,GNM使用模仿学习在6种具身形态上训练导航策略。相比之下,我们的策略通过强化学习的微调而受益,提高了对累积错误的抵抗力。此外,由于在模拟中使用了大规模随机化的具身形态进行训练,RING学会了一个能够导航任何具身形态的单一策略,并能够泛化到现实世界中真正未见过的机器人平台。此外,NoMaD、ViNT、GNM和Mobility VLA都需要进行拓扑地图或图重构以进行高级规划,而我们的策略是完全端到端的,能够在没有显式地图的情况下探索新场景。虽然有几项研究致力于使用大型语言模型(LLMs)或视觉语言模型(VLMs)来学习与具身形态无关的策略,但它们仅解决短期导航任务并进行单步预测。相比之下,RING通过Transformer解码器对时间信息进行建模。
RING方法介绍
随着研究实验室和现实世界应用中使用的机器人日益多样化,仍然需要一种能够操作各种具身形态并以零次或少数几次学习的方式迁移到未见过的机器人的策略。这里介绍了RING,一种用于室内视觉导航的通用策略,它能够从广泛的具身形态中学习,并且完全在模拟环境中进行训练,无需直接使用实际的机器人具身形态。我们证明,在大约100万种随机具身形态上进行训练可以产生稳健的导航策略,从而实现向未见过的现实世界机器人具身形态的零次迁移。为了训练RING,定义了随机具身形态的空间,使模拟环境中能够生成随机具身形态的专家轨迹,并使用最先进的架构设计结合模仿学习(IL)和强化学习(RL)方法进行训练。
问题表述
跨多个具身形态学习导航策略是一个多任务机器人问题。我们将可能的具身形态的空间定义为E,其中每个具身形态e ∈ E由其配置向量表征,该向量包括诸如相机设置、agent碰撞器大小、旋转中心等参数。每个任务都可以建模为部分可观察马尔可夫决策过程(POMDP),表示为γ,其中S和A分别是状态和动作空间。由于相机参数和传感器配置的差异,观察空间在不同的具身形态之间会有所不同。对于具身形态e在时间t的观察,它是状态和具身形态参数的函数。给定动作at,下一个状态遵循转移动态,这取决于具身形态,因为不同的具身形态以不同的方式与环境交互(由于碰撞器大小和旋转中心的差异)。图2显示了从两个不同具身形态开始的示例轨迹,它们从同一位置出发并遵循相同的动作序列。它们具有不同的视觉观察并遵循不同的转移动态:一个agent在桌子下移动,而另一个则与桌子发生碰撞。除非另有说明,我们假设所有具身形态共享相同的离散动作空间{MoveBase(±20cm), RotateBase(±6°, ±30°), Done},并在部署期间使用特定于机器人的低级控制器来执行这些动作。

大规模具身形态随机化
领域随机化是一类方法,其中策略是在广泛的模拟环境参数范围内进行训练的;其目标是使策略对未见过的环境具有鲁棒性。我们的方法是补充性的,但又是正交的;应用具身形态随机化,在多种机器人机体参数上训练策略,从而能够稳健地部署到未见过的真实世界机器人上。
在AI2-THOR模拟器中,将agent的机体建模为一个不可见的碰撞盒。每个agent可以在碰撞盒内以随机姿态放置1个或2个RGB相机。与机体和相机相对应的参数是从表1中指定的范围内随机采样的。我们还修改了生成专家轨迹的过程,以考虑具身形态的多样性。
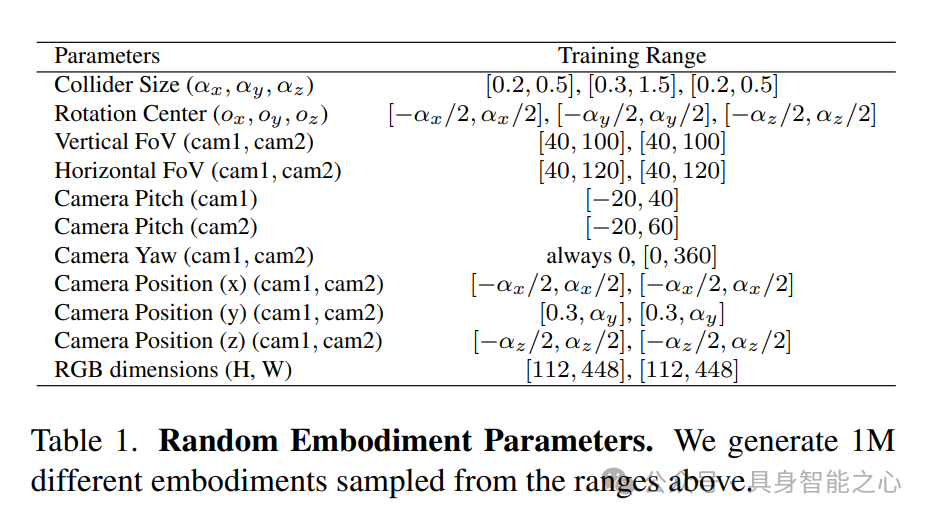
下面详细说明在具身形态随机化中变化的参数。碰撞盒尺寸(αx, αy, αz)。agent的机体被建模为一个碰撞盒。我们使用三个缩放因子(αx, αy, αz)来沿x、y、z轴缩放碰撞盒。从范围[0.2, 0.5]m中均匀采样αx和αy,并从范围[0.3, 1.5]m中采样αz(agent的高度)。这些范围充分捕捉了大多数机器人之间的变异性。
旋转中心(ox, oy, oz)。这些坐标定义了agent的旋转中心点。虽然这个中心通常靠近(0,0),但在不同的机器人上可能会有所不同。从范围[−αx/3, αx/3]中采样ox,从范围[−αy/3, αy/3]中采样oy,采样范围由碰撞盒尺寸决定。
相机参数。每个agent都配备有两个放置在碰撞盒内的RGB相机。随机化了几个相机参数,包括位置、旋转、视野(FoV)和纵横比。这些参数的采样范围如表1所示。虽然第一个相机始终面向前方,但第二个相机可以在z轴上旋转多达360度,使其能够面向前方、侧面或后方。
为了可视化目的,为每个具身形态定义了一个19维的具身形态配置向量,用于表示相机和机体参数。图1-A展示了我们对30,000个随机具身形态的向量进行了t-SNE可视化,同时还展示了Stretch RE-1、LoCoBot和Unitree A1的相应向量。图中还包括了来自第一个相机的10个随机具身形态和这三个机器人的第一人称视角视图。这证明了随机化涵盖了广泛的可能具身形态,涵盖了感兴趣的真实世界机器人平台。总共在50,000栋房屋中收集了100万条轨迹,每栋房屋都有一个随机采样的具身形态。
结构说明
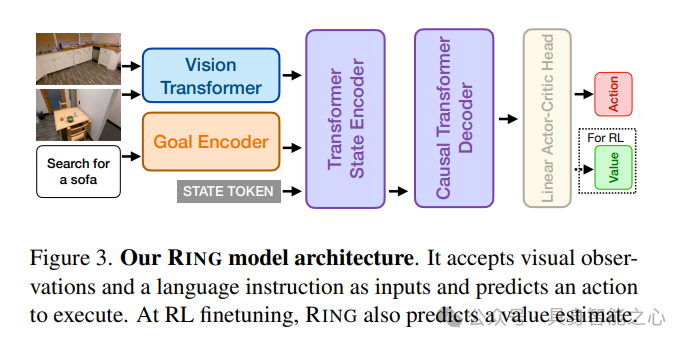
拥有这个丰富的随机具身形态专家轨迹数据集,一个深度且高容量的架构对于学习稳健的策略至关重要。如图3所示,在每个时间步,RING使用N张RGB图像(每个相机一张)和语言指令l来预测离散动作空间上的动作分布。为了考虑不同的维度,在将RGB观测值输入模型之前,会将其填充为正方形并调整为256 × 256的大小。RING的架构受PoliFormer启发,包括一个视觉编码器、一个目标编码器、一个Transformer状态编码器和一个具有线性actor-critic head的因果Transformer解码器。视觉编码器和目标编码器是冻结的预训练模型(分别是ViT和语言模型),它们将RGB观测值和指令l编码为视觉和目标token嵌入。这些嵌入的投影以及一个特殊的STATE token向量沿着token轴堆叠,并通过多层Transformer状态编码器进行处理,该编码器将每个时间步的观测值总结为与STATE token相对应的状态嵌入。最后,因果Transformer解码器在时间上进行显式记忆建模,通过对沿着时间轴堆叠的状态嵌入进行因果注意力操作来生成当前belief。线性actor-critic Head进一步预测动作空间上的动作对数几率以及价值估计。
训练范式
最近,SPOC表明,在模拟中对大规模专家轨迹进行行为克隆(Behavior Cloning)训练得到的策略,能够有效地泛化到真实世界中。FLaRe进一步介绍了一种鲁棒且可扩展的方法,用于通过在线策略强化学习(On-policy Reinforcement Learning)微调这些预训练策略。强化学习微调引入了错误恢复行为,并缓解了模仿学习中通常遇到的累积错误,从而显著提升了性能。我们采用了相同的策略:首先,在从随机具身形态收集的专家轨迹上预训练我们的策略,然后,使用AI2-THOR模拟器中的随机具身形态,通过在线策略强化学习进行微调。
大规模随机具身形态的模仿学习。在每个时间步,因果Transformer解码器中的线性actor-critic Head预测动作对数几率。我们计算对数几率π和专家动作之间的交叉熵损失。在训练时,使用240条轨迹的bs大小,每条轨迹具有100步的时间context window。使用8个H100 GPU(每个GPU 80 GB内存)和AdamW优化器(学习率为)训练模型,迭代80,000次。
随机具身形态的强化学习微调。遵循FLaRe中的训练方案,这里进一步使用AllenAct在模拟中的随机具身形态上进行了大规模的强化学习微调。我们的训练数据集包括100万个随机具身形态和5万个程序生成的PROCTHOR房屋,这些房屋中约有4万个标注的3D object。
强化学习微调对于策略学习通过试错法在各种具身形态中导航尤为重要。特别是,由于RING策略缺乏关于其具身形态的明确信息,因此它必须隐式地推断出这些信息,这需要广泛的探索和试错。使用DD-PPO算法,在4台机器(每台机器配备8个H100 GPU)上运行64个并行环境和128个展开步骤,并使用AdamW优化器(学习率为)进行了4000万步的训练。遵循FLaRe的做法,关闭了PPO损失中的熵项,以避免灾难性遗忘。
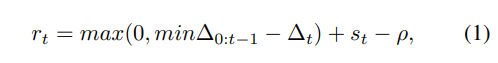
实验分析
实验表明,尽管RING仅在模拟环境中进行训练,且未直接接触任何真实机器人具身形态,但它仍能在包括实际机器人(如Stretch RE-1、LoCoBot和Unitree Go1)以及配备导航助手的真人评估在内的广泛具身形态上有效运行。主要结果如下:
尽管从未在这些具身形态上进行过训练,RING仍能实现零样本泛化至4种真正未见过的具身形态,并在多个基准测试中取得了最先进的性能。
我们的策略仅在模拟环境中对随机具身形态进行训练,便能直接迁移到现实世界,在3种真实机器人和导航助手(真人评估)上表现良好。
RING通过最少的微调即可轻松适应特定具身形态的策略,并在每种特定机器人上实现了更好的性能。
RING展现出具身自适应行为,能够根据智能体的身体调整其策略。
进行了消融研究,并探索了通过碰撞惩罚进行微调,以使策略采取更保守的行动。
RING 实现了对未见具身形态的零样本泛化
针对四种机器人实体(Stretch RE-1(配备1或2个camera)、LoCoBot和Unitree A1)在模拟环境中对所有策略进行了零样本评估。
基线。对于基线,选择了模仿学习(IL)和强化学习(RL)领域的先前工作。每个基线都在一个特定的实体上进行训练,并在四个不同的实体上以零样本设置进行评估。SPOC是一个监督模仿学习基线,它在AI2-THOR中的最短路径专家轨迹上进行训练。PoliFormer是物体目标导航领域最先进的基于Transformer的策略,它使用强化学习从头开始训练。FLaRe 是一种高效策略微调方法,结合了模仿学习和强化学习。SPOC 使用100k条专家轨迹在Stretch RE-1上通过模仿学习进行训练;SPOC-2.3M在更多的专家轨迹上进行训练;PoliFormer 在每个实体上分别进行了3亿步强化学习训练,从头开始;而FLaRe 在Stretch RE-1上对SPOC进行了额外的2000万步强化学习微调。
实验细节。RING首先在模拟中从随机实体收集的100万条专家轨迹上使用模仿学习进行训练,然后在随机实体上进行额外的4000万步强化学习微调(示例见图1-A和图2)。请注意,在训练过程中未见过所有四个目标实体,并且在评估期间不提供有关实体的信息。在CHORES-S 中的导航基准上进行了评估,CHORES-S是一个家用机器人模拟基准,包含200个场景中的200项任务。对于Unitree A1,创建了一个新的类似基准,根据机器人较低的身高调整了200项任务,以确保所有目标都是可行的。
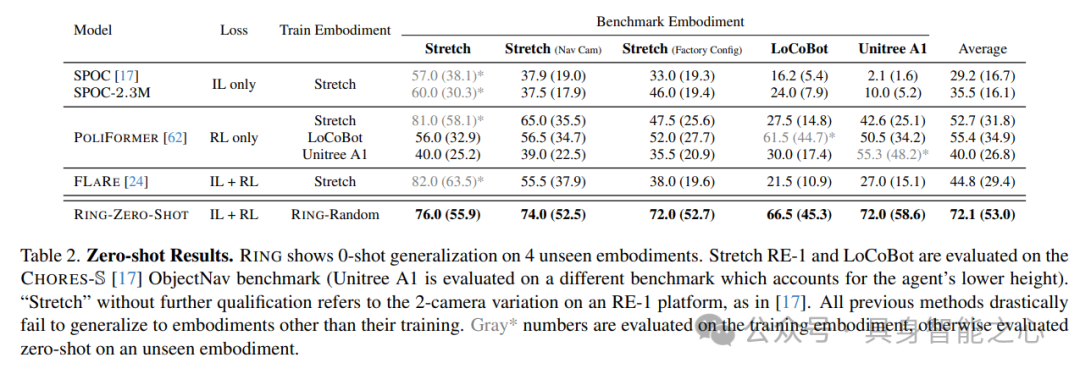
结果。表2展示了四个实体上所有策略的零样本评估结果。我们比较了成功率(Success Rate)和按情节长度加权的成功率(SEL),后者是衡量效率的指标。结果表明,所有单一实体的基线都难以有效地泛化到新的实体,随着实体差异的增加,性能有所下降。例如,在Stretch RE-1上使用两个摄像头训练的SPOC,随着评估实体在表2顶部行从左到右的差异增大,其性能逐渐下降。在高度差异较大的Unitree A1上进行评估时,其表现最差。相比之下,RING在所有实体上都表现出强大的泛化能力,尽管它未在任何一个实体上进行训练,但在成功率上实现了16.7%的平均绝对提升。在某些情况下,它甚至超过了在目标实体上训练的基线:在LoCoBot上训练的PoliFormer(61.5% → 68.5%)和Unitree A1(55.3% → 72.0%)。这表明,RING通过在大规模随机实体上进行训练,获得了更有效的导航策略,甚至优于一些专门针对特定实体的策略。
尽管RING完全在模拟环境中进行训练,但它仍能迁移到现实世界中的实体
机器人评估:在真实公寓中的3个未见过的机器人上对我们的策略进行了零样本评估。所有评估均直接在一个大型公寓(图4)中进行,没有进行任何进一步的适应或针对真实世界的特定微调。分别为LoCoBot 使用了相同的15项任务评估集(3种不同的起始姿势对应5个不同的目标),为Stretch RE-1 使用了18项任务评估集(3种不同的起始姿势对应6种不同的目标规范)。我们为Unitree Go1创建了一个新的评估集,包含3种起始姿势和4个物体(马桶、沙发、电视、垃圾桶),这些物体的位置根据机器人较低的身高进行了调整,以确保从机器人较低的视角可以看到这些物体。
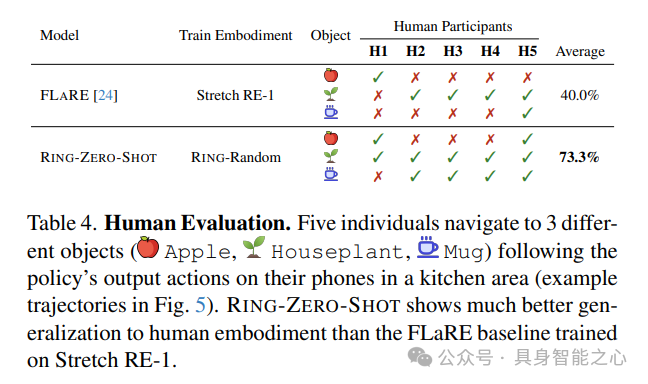
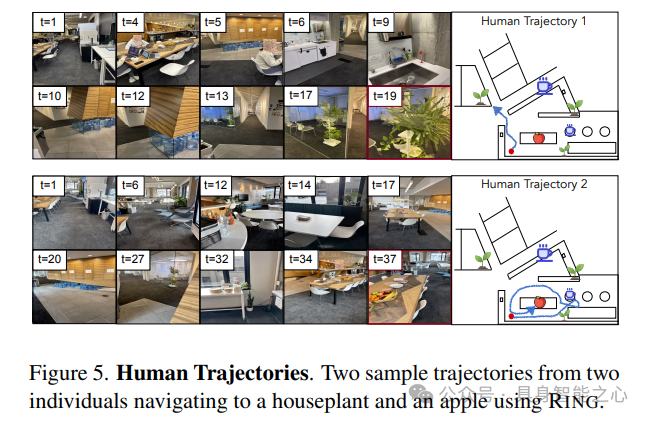
人类评估:为了进一步证明我们的策略在未见过实体上的泛化能力,我们将其作为导航助手与人类(作为新的、未见过的实体)一起进行评估。我们邀请5名参与者按照手机上的策略输出动作在真实厨房区域进行导航。每个人都有独特的特征,包括步长、身高、旋转角度和持相机姿势。每个人导航到三个不同的物体(杯子、苹果、室内植物),总共产生了15条轨迹。我们将RING与仅在Stretch RE-1上训练的FLaRe 进行了比较。表4显示,RING在目标物体和不同参与者上均一致优于FLaRe,图5展示了RING实现的两个定性结果。
RING能够在最小程度的微调下高效地适应特定实体的策略
尽管RING是一种能够在广泛实体上实现零样本迁移的通用策略,但往往在某些情况下,需要针对特定实体制定专门策略以达到最佳性能。这里我们证明了RING可以很容易地通过最小程度的微调适应为针对机器人的专门策略,从而在目标实体上实现更好的性能。
基线。使用FLaRe 作为基线。它已成功适应新任务和实体。该基线在Stretch RE-1上进行预训练,并在三个实体中的每一个上进行最多2000万次强化学习步骤的微调。
实现细节。对在随机实体上预训练的RING进行微调,在每个机器人上最多进行2000万次强化学习步骤的微调,同时保持所有超参数与FLaRe一致,以确保公平比较。遵循FLaRe的做法,我们将两个动作RotateBase(±6°)重新定义为TiltCamera(±30°),以允许LoCoBot的摄像头移动。请注意,在零样本评估期间不允许此移动。
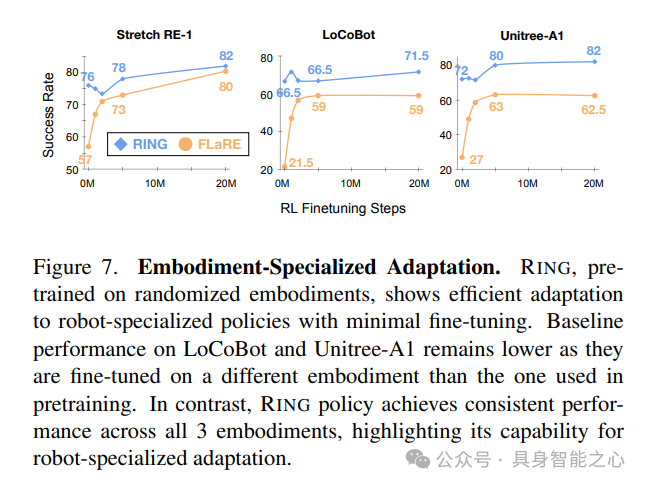
结果。图7显示,RING通过最小程度的微调即可高效地适应特定实体,从而生成性能更佳的特定实体策略。对于LoCoBot和Unitree-A1,FLaRe的性能仍低于Stretch RE-1,这表明在一个实体上进行预训练并在多个实体上进行微调无法取得最佳结果。这凸显了需要一种能够通过轻量级微调持续适应任何实体的策略。
RING具有实体自适应行为
最优导航策略πθ的行为应受到智能体自身形体的强烈影响。例如,与视野更宽的智能体相比,视野较窄的智能体必须探索更多才能有效感知周围环境。较小的智能体可以通过狭窄的过道或在家具下导航,而较大的智能体可能需要采取更保守的路径。一个问题出现了:该策略是否在不同实体上表现出相同的导航行为,还是会相应地调整其策略?
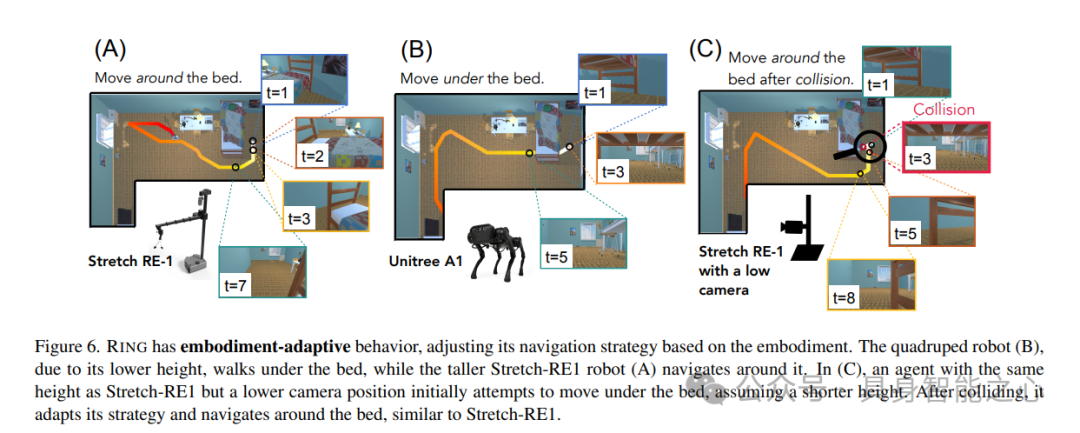
定性结果证实了该策略具有实体自适应行为。在图6-A、B中,Stretch RE-1和Unitree A1都从床后的同一姿势开始。四足机器人由于其高度较低,直接移动到床下,而Stretch RE-1则绕过床。我们观察到,RING能够从视觉观察和转移动态中隐式推断出实体参数,并据此动态调整其导航策略。它无法获取关于当前形体的任何特权信息。
视觉观察可以揭示参数,如摄像头规格,在某些情况下还可以揭示智能体的高度。然而,仅凭视觉信息可能不足以让智能体推断出身形尺寸,导致其依赖碰撞来推断。在图6-C中,智能体的身高与Stretch RE-1相匹配,但摄像头的位置与四足机器人一样低。最初,它假设自己的高度较低,并试图钻到床下,但在发生碰撞后,它调整策略,绕床而行,与Stretch RE-1类似。这种实体自适应导航策略调整是一种有趣的涌现行为,如果不经过在大规模实体空间中进行的全面训练,是不可能实现的。
消融实验
更强大的预训练视觉编码器。策略中使用的默认视觉编码器是预训练的SIGLIP-VIT-B/16。我们研究了使用更强大的视觉编码器对RING性能的影响。使用OpenAI的VITL/14 336PX CLIP模型训练了RING-LARGE。表5比较了结果,显示更强大的视觉编码器在所有四个实体上的零样本性能都有显著提高(平均提高约9%)。在我们的策略中,更大的视觉编码器特别有益,因为随机化的摄像头参数导致视觉观察高度多样化。为确保与基线进行公平比较,并且由于VIT-L/14的计算要求更高,选择了使用VIT-B/16编码器进行我们的主要实验。将为那些对使用更大视觉编码器进行训练感兴趣的人发布训练代码,供社区使用。
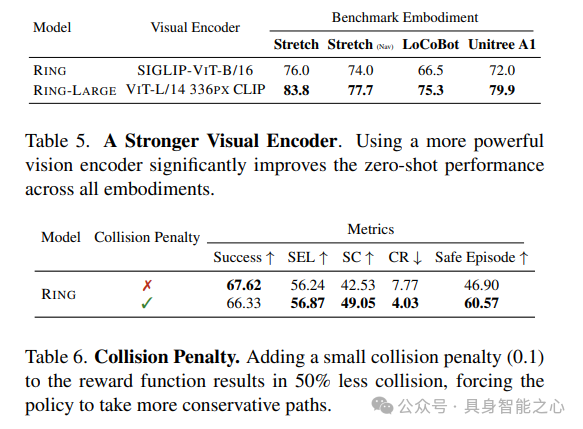
加入碰撞惩罚以选择更安全的路线。由于我们的智能体具有随机的身体尺寸,并且没有明确告知其身体形态,它们可能会在了解自身正确尺寸之前偶尔发生碰撞。我们证明了在奖励函数中加入0.1的小碰撞惩罚可以减少50%的碰撞率(将碰撞率CR从7%降低到4%)。无论身体尺寸大小,由此产生的策略都更加保守。
为了量化这些结果,我们创建了一个类似于CHORES-S的自定义基准测试,该测试由2000个场景中的2000个随机身体形态组成。在这个基准测试上评估了我们策略的两个不同版本,比较了成功率、碰撞加权成功率(SC)、碰撞率(CR)和无碰撞片段百分比(没有任何碰撞的片段所占百分比)等指标。如表6所示,加入碰撞惩罚后,碰撞率(CR)从7.77%降低到4.03%,同时无碰撞轨迹的百分比从46.90%提高到60.57%。
参考
[1] The One RING : a Robotic Indoor Navigation Generalist
【具身智能之心】技术交流群
具身智能之心是国内首个面向具身智能领域的开发者社区,聚焦大模型、视觉语言导航、VLA、机械臂抓取、双足机器人、四足机器人、感知融合、强化学习、模仿学习、规控与端到端、机器人仿真、产品开发、自动标注等多个方向,目前近60+技术交流群,欢迎加入!扫码添加小助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

【具身智能之心】知识星球
具身智能之心知识星球是国内首个具身智能开发者社区,也是最专业最大的交流平台,近1000人。主要关注具身智能相关的数据集、开源项目、具身仿真平台、大模型、视觉语言模型、强化学习、具身智能感知定位、机器臂抓取、姿态估计、策略学习、轮式+机械臂、双足机器人、四足机器人、大模型部署、端到端、规划控制等方向。星球内部为大家汇总了近40+开源项目、近60+具身智能相关数据集、行业主流具身仿真平台、强化学习全栈学习路线、具身智能感知学习路线、具身智能交互学习路线、视觉语言导航学习路线、触觉感知学习路线、多模态大模型学理解学习路线、多模态大模型学生成学习路线、大模型与机器人应用、机械臂抓取位姿估计学习路线、机械臂的策略学习路线、双足与四足机器人开源方案、具身智能与大模型部署等方向,涉及当前具身所有主流方向。
扫码加入星球,享受以下专有服务:
1. 第一时间掌握具身智能相关的学术进展、工业落地应用;
2. 和行业大佬一起交流工作与求职相关的问题;
3. 优良的学习交流环境,能结识更多同行业的伙伴;
4. 具身智能相关工作岗位推荐,第一时间对接企业;
5. 行业机会挖掘,投资与项目对接;



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









