



点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
论文作者 | 具身智能之心
编辑 | 自动驾驶之心
论文标题:UniGraspTransformer: Simplified Policy Distillation for Scalable Dexterous Robotic Grasping
论文链接:https://arxiv.org/pdf/2412.02699
项目链接:https://dexhand.github.io/UniGraspTransformer/
作者单位:微软亚洲研究院 悉尼大学 新加坡国立大学

UniGraspTransformer的出发点
UniGraspTransformer是一种基于Transformer的通用网络,用于灵巧机器人的抓取任务,具有简化训练流程并提升可扩展性与性能的优势。与需要复杂多步骤训练流程的先前方法(如UniDexGrasp++)不同,UniGraspTransformer采用简化的训练过程:首先,通过强化学习为单个物体训练专用策略网络,以生成成功的抓取轨迹;随后,将这些轨迹蒸馏到一个统一的通用网络中。本文的方法使得UniGraspTransformer能够高效扩展,支持多达12个自注意力模块,用于处理数千种具有不同姿态的物体。此外,该模型在理想化输入和现实世界输入中都表现出了良好的泛化能力,适用于基于状态和基于视觉的环境。值得注意的是,UniGraspTransformer可以为各种形状和方向的物体生成更广泛的抓取姿态,从而实现更加多样化的抓取策略。实验结果表明,在多个物体类别上,UniGraspTransformer相比最先进的方法UniDexGrasp++表现出显著的性能提升。在基于视觉的场景中,其抓取成功率分别在以下任务中实现了提升:对于已见物体提高3.5%,对于已见类别的未见物体提高7.7%,对于完全未见的物体提高10.1%。
内容出自国内首个具身智能全栈学习社区:具身智能之心知识星球,这里包含所有你想要的。
方法设计
灵巧机器人的抓取任务依然是机器人领域的一大挑战,尤其是在处理形状、尺寸及物理属性多样的物体时更为复杂。灵巧机械手由于其多自由度以及复杂的控制需求,在执行操作任务时面临独特的困难。尽管方法如UniDexGrasp++ 在这一领域取得了显著进展,但当单一网络需要处理大量且多样化的物体时,其性能会显著下降。此外,UniDexGrasp++ 采用了多步骤的训练流程,包括策略学习、基于几何的聚类、课程学习以及策略蒸馏等,这种复杂的训练方式限制了方法的可扩展性并降低了训练效率。
在本研究中,本文简化了通用网络的训练流程,使其能够处理数千种物体,同时提升了性能和泛化能力。本文提出的工作流程清晰简洁:
为训练集中每个物体单独训练策略网络:利用强化学习方法,通过精心设计的奖励函数,引导机器人掌握针对特定物体的抓取策略;
生成大量成功抓取轨迹:使用这些经过充分训练的策略网络,生成数百万条成功的抓取轨迹;
训练通用Transformer网络:基于这些丰富的抓取轨迹集,在监督学习框架下训练一个基于Transformer的通用网络,即UniGraspTransformer,使其能够高效泛化到训练中见过的物体以及全新未见的物体。
本文的架构提供了以下四个主要优势:
简洁性:本文直接以离线方式将所有单独的强化学习策略蒸馏到一个通用网络中,无需使用任何额外的技术,例如网络正则化或渐进蒸馏。
可扩展性:较大的抓取网络通常能够处理更广泛的物体,并在形状和尺寸的变化中表现出更强的鲁棒性。本文的方法利用离线蒸馏,使得最终网络——UniGraspTransformer——可以设计为更大规模,支持多达12个自注意力模块。与传统的在线蒸馏方法相比,这种方法提供了显著的灵活性和容量,而后者通常依赖于较小的MLP网络以确保收敛,但限制了可扩展性。此外,本文的专用策略网络设计为轻量级,每个网络仅需要处理单个物体,从而在不牺牲性能的前提下确保效率。
灵活性:每个专用策略网络在一个受控的、理想化的环境中进行训练,在该环境中,系统的全状态(包括物体表示,如完整的点云;灵巧机械手状态,如手指关节角度;以及它们的交互,如手-物体距离)是完全可观测且高度精确的。本文的架构能够将这种理想环境下的知识蒸馏到更实用的真实世界环境中,即使某些观测可能不完整或不可靠。例如,物体的点云可能存在噪声,或者物体姿态的测量可能不够精确。这些专用策略网络的主要作用是为各种物体生成多样化的成功抓取轨迹。在蒸馏过程中,这些抓取轨迹作为标注数据,使本文能够利用现实环境中的输入(如带噪声的物体点云和估计的物体姿态)训练UniGraspTransformer模型,从而预测出与理想环境中的成功抓取轨迹高度一致的动作序列。
多样性:本文的更大规模通用网络结合离线蒸馏策略,不仅能够抓取数千种不同的物体,还展现出为各种方向的物体生成更广泛抓取姿态的能力。这相较于先前的方法(如UniDexGrasp++)有显著提升,后者通常在不同物体间生成重复且单一的抓取姿态。
在本文的实验中,所提出的方法在多个评估环境下相较于现有最先进方法UniDexGrasp++展现了显著的性能提升。具体而言,本文在两种设置下对方法进行了评估:
基于状态的设置:在此设置中,物体的观测信息与灵巧机械手的状态由模拟器提供,具有完全的精确性。
基于视觉的设置:在此设置中,物体的点云由多视图重建生成。
在多种物体类型上,本文的方法始终优于UniDexGrasp++,包括已见物体、已见类别中的未见物体,以及来自未见类别的完全未见物体,如图1所示。例如,在基于视觉的设置下,本文的方法分别在以下任务中实现了性能提升:对已见物体提高3.5%,对已见类别的未见物体提高7.7%,对完全未见类别的物体提高10.1%。

图1. UniDexGrasp、UniDexGrasp++ 和本文提出的 UniGraspTransformer 在基于状态和基于视觉两种设置下的性能比较。对于每种设置,成功率分别在以下三种任务中进行评估:已见物体、已见类别中的未见物体,以及来自未见类别的完全未见物体。
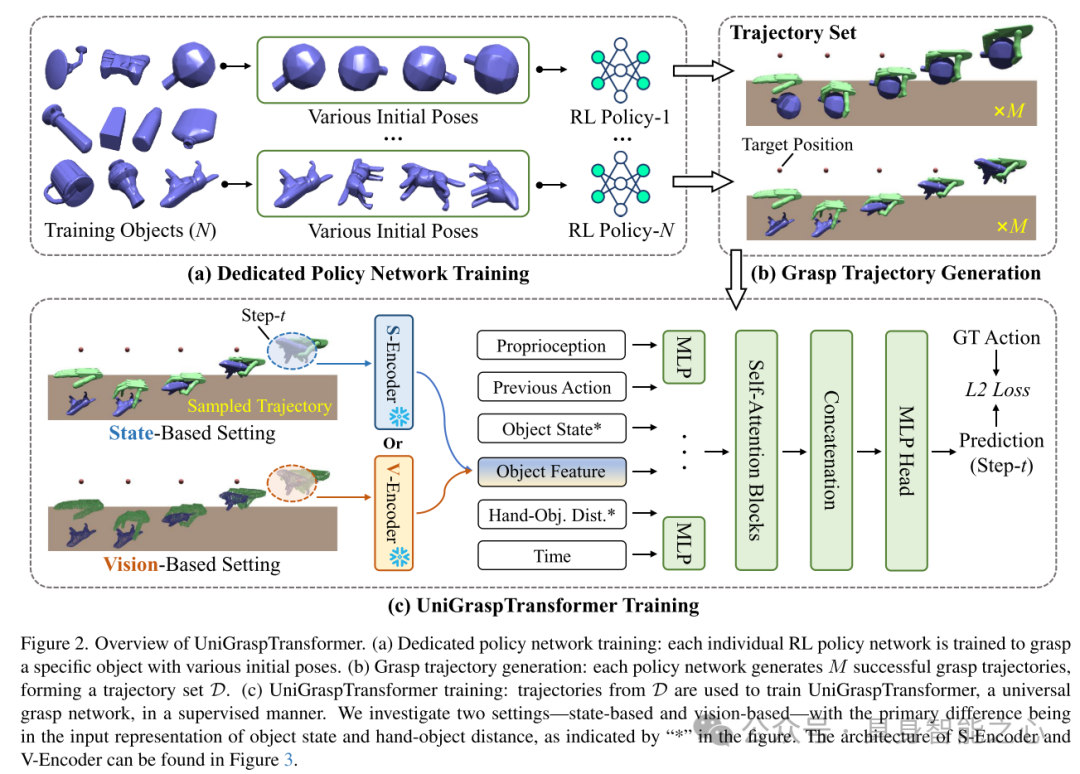
图2. UniGraspTransformer 概览
(a) 专用策略网络训练:每个单独的强化学习策略网络被训练以抓取特定物体,并适应不同的初始姿态。
(b) 抓取轨迹生成:每个策略网络生成 条成功的抓取轨迹,构成轨迹集合 。
(c) UniGraspTransformer 训练:利用轨迹集合 中的轨迹,在监督学习框架下训练 UniGraspTransformer 通用抓取网络。
本文研究了两种设置——基于状态和基于视觉。这两种设置的主要区别体现在物体状态和手-物体距离的输入表示(图中以“*”标注)。S-Encoder 和 V-Encoder 的具体架构请参考图3。
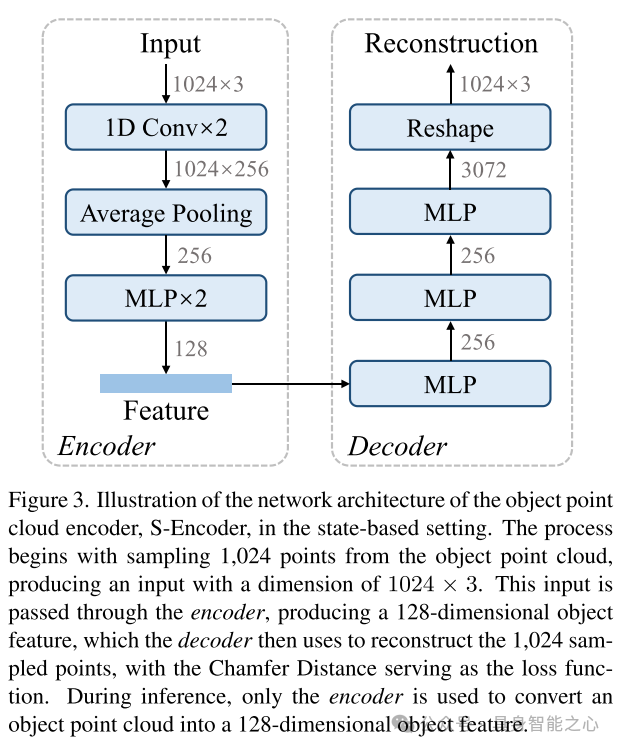
图3. 基于状态的设置中物体点云编码器 S-Encoder 的网络架构示意图
该过程从物体点云中采样 1,024 个点,生成维度为 的输入。该输入通过编码器处理,生成一个 128 维的物体特征。随后,解码器利用该特征重建采样的 1,024 个点,并以 Chamfer 距离作为损失函数进行优化。
在推理阶段,仅使用编码器,将物体点云转换为 128 维的物体特征。
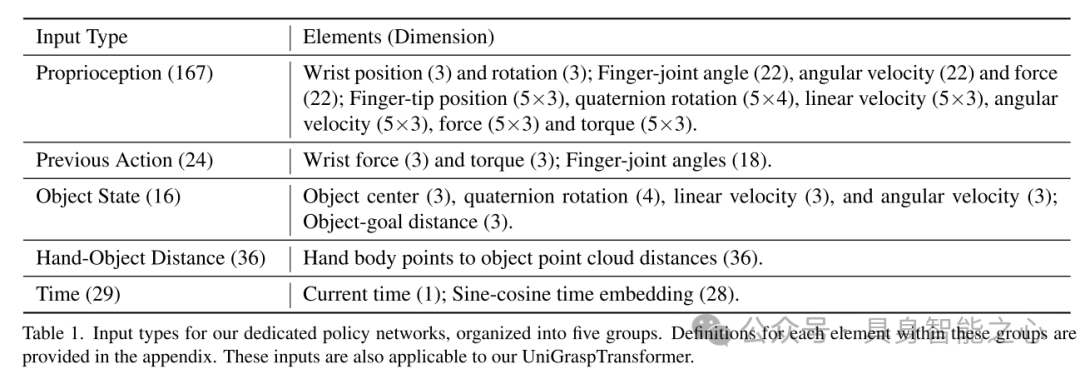
表1. 专用策略网络的输入类型
输入被组织为五个组别,每组的具体元素定义详见附录。这些输入类型同样适用于本文的 UniGraspTransformer。
实验结果
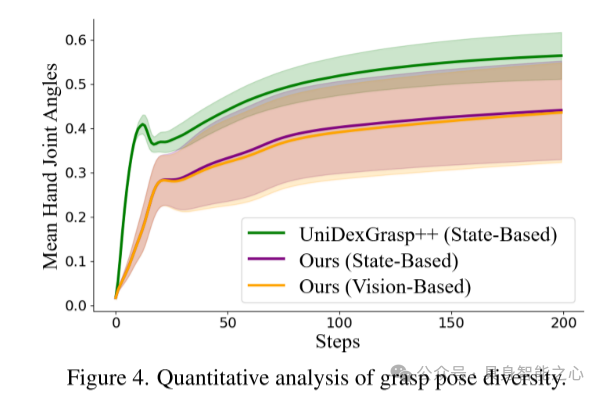
图4. 抓取姿态多样性的定量分析
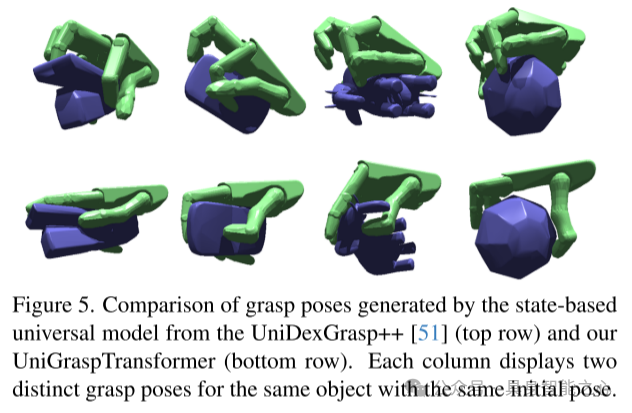
图5. 比较 UniDexGrasp++(上排)和本文提出的 UniGraspTransformer(下排)生成的抓取姿态。每列展示了同一物体在相同初始姿态下的两种不同抓取姿态。
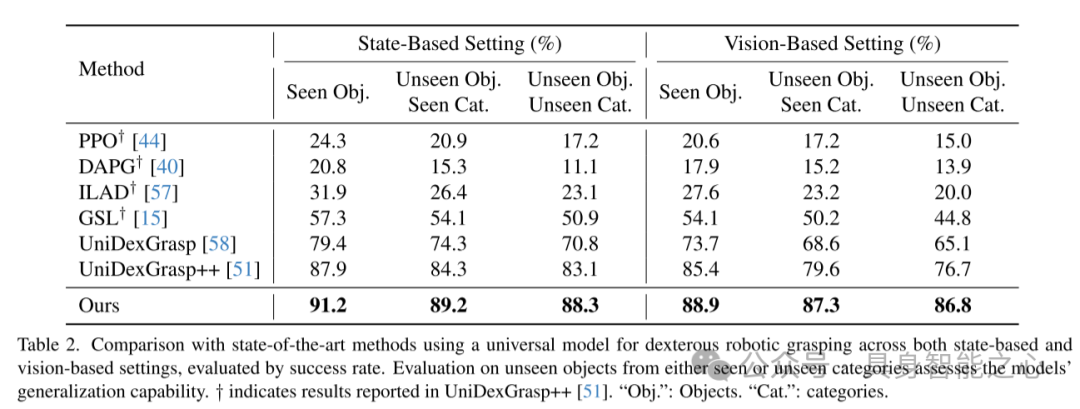
表2. 与现有最先进方法在灵巧机器人抓取任务中的通用模型对比
在基于状态和基于视觉的设置下,通过成功率进行评估。对于已见类别中的未见物体及完全未见类别的物体的评估,反映了模型的泛化能力。标记 † 的结果为 UniDexGrasp++ 中报告的数据。“Obj.” 表示物体,“Cat.” 表示类别。

表3. 不同 值对 UniGraspTransformer 性能的影响分析
针对每个专用策略网络(共 3,200 个),本文生成 条成功的抓取轨迹,并将其蒸馏到 UniGraspTransformer 中。该表分析了随着 值变化对模型性能的影响。

表4. UniGraspTransformer 中自注意力模块数量对性能的影响分析
模型由 个自注意力模块组成,后接一个包含 4 层的 MLP 头。“-” 表示仅使用 MLP 头而不包含任何自注意力模块的配置。

表5. 不同数量专用策略网络蒸馏到 UniGraspTransformer 的影响分析

表6. 不同输入组件对 UniGraspTransformer 训练的影响
“Prev.”:先前状态;“Obj.”:物体;“Feat.”:特征;“Dist.”:距离;“SR”:成功率。
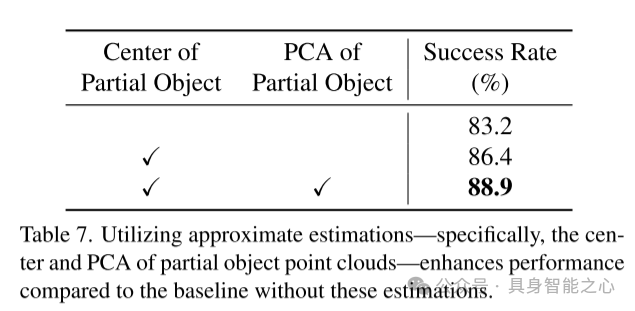
表7. 使用近似估计(特别是局部物体点云的中心和PCA)对性能的提升
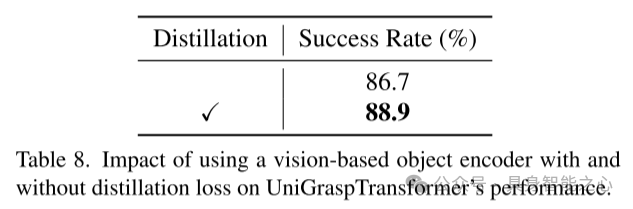
表8. 基于视觉的物体编码器在是否使用蒸馏损失情况下对 UniGraspTransformer 性能的影响
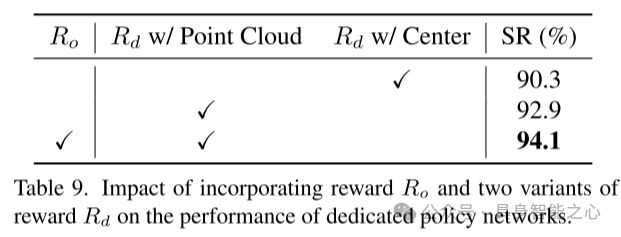
表9. 引入奖励 和两种奖励变体 对专用策略网络性能的影响
总结
本文提出了UniGraspTransformer,一种基于Transformer的通用网络,用于简化灵巧机器人抓取任务的训练流程,同时在抓取策略的可扩展性、灵活性和多样性方面实现显著提升。本文的方法通过专用的强化学习策略网络为单个物体生成抓取轨迹,随后采用高效的离线蒸馏过程,将这些成功的抓取轨迹整合到一个单一的、可扩展的模型中,从而简化了传统复杂的训练管线。UniGraspTransformer 能够处理数千种物体及其多样化的姿态,展现出在基于状态和基于视觉的多种设置中的鲁棒性和适应性。尤其值得注意的是,该模型在已见物体、已见类别的未见物体以及全新类别的未见物体上显著提升了抓取成功率,相较当前最先进方法,在各类评估环境下均实现了大幅性能改进。
引用
@misc{wang2024unigrasptransformersimplifiedpolicydistillation,
title={UniGraspTransformer: Simplified Policy Distillation for Scalable Dexterous Robotic Grasping},
author={Wenbo Wang and Fangyun Wei and Lei Zhou and Xi Chen and Lin Luo and Xiaohan Yi and Yizhong Zhang and Yaobo Liang and Chang Xu and Yan Lu and Jiaolong Yang and Baining Guo},
year={2024},
eprint={2412.02699},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2412.02699},
}① 2025中国国际新能源技术展会
自动驾驶之心联合主办中国国际新能源汽车技术、零部件及服务展会。展会将于2025年2月21日至24日在北京新国展二期举行,展览面积达到2万平方米,预计吸引来自世界各地的400多家参展商和2万名专业观众。作为新能源汽车领域的专业展,它将全面展示新能源汽车行业的最新成果和发展趋势,同期围绕个各关键板块举办论坛,欢迎报名参加。

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









