



作者 | 钱岚请讲 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/12088531309
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
Q:端到端模型通常大致分为几种?
分为两种,一种是完全黑盒OneNet,模型直接优化Planner;另一种是模块化端到端,即模块级联或者并联,通过感知模块,预测模块以及规划模块之间feat-level/query-level的交互,减少分段式自动驾驶模型的误差累积。
Q:[UniAD]
整个框架分为4部分,输入multi-view camera imgs,Backbone模块提取BEV feat,Perception模块完成对于scene-level的感知包括对于agents+ego以及map,Prediction模块基于时序交互以及agents-scene的交互完成对于agents+ego的multi-mode轨迹预测,Planner模块基于预测的轨迹以及BEV feat完成路径的规划。各模块均采用Query+Transformer形式进行构建,方便各模块间信息的交互。
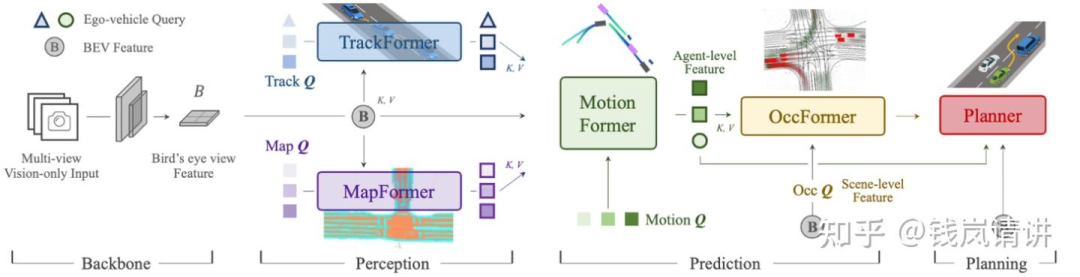
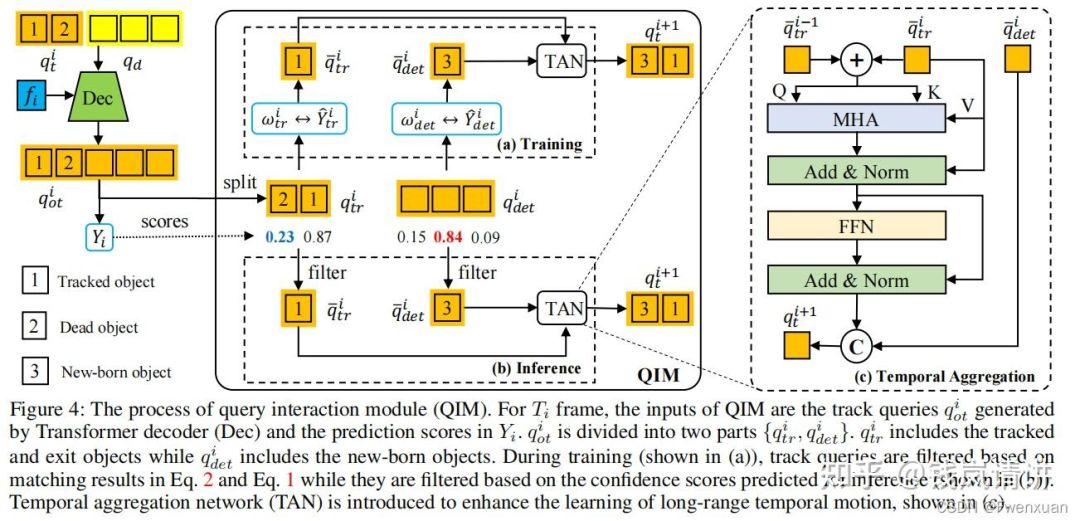
TrackFormer:query由3部分组成,检测query,跟踪query以及ego query。对于检测部分,对于当前时刻t,定义当前时刻的det query ,采用DETR检测模型,用来检测未跟踪到的新目标newborn;对于跟踪部分,每一个query对应其跟踪的对应object,track query的集合长度随着部分object消失而动态变化。推理过程:following MOTR,训练时对于初始时刻det query采用BEVFormer检测newborn,track query集合为空,后续时刻将当前时刻的det query合并到下一时刻的track query集合中。合并后的query集合即cat(,)与BEV feat送入decoder作交互,输出的query经过QIM与上一时刻的track query作MHA获取时序信息,最终输出更新后的。根据预测score用thre来决定newborn加入以及跟踪目标的消失。
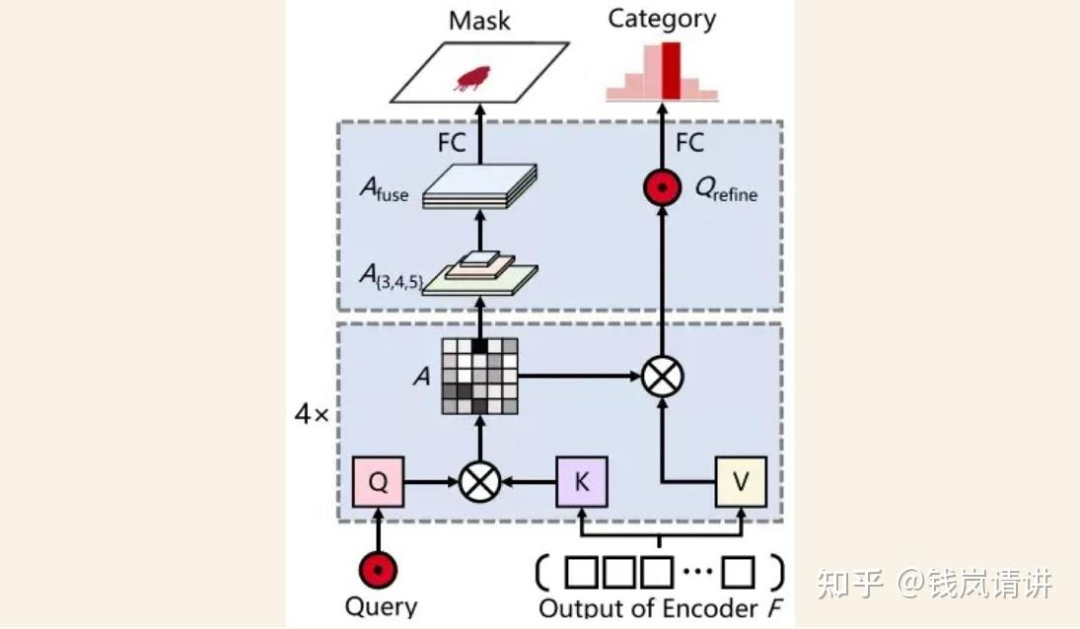
MapFormer:基于Panoptic Segformer(Q2中作详细介绍),对环境进行全景分割,包含两类things和stuff,things表示可记数的实例比如行人或者车辆,每个实例有唯一独立的id区别于其他实例,而stuff表示不可数或者不定形的实例比如天空或者草原,没有实例id。
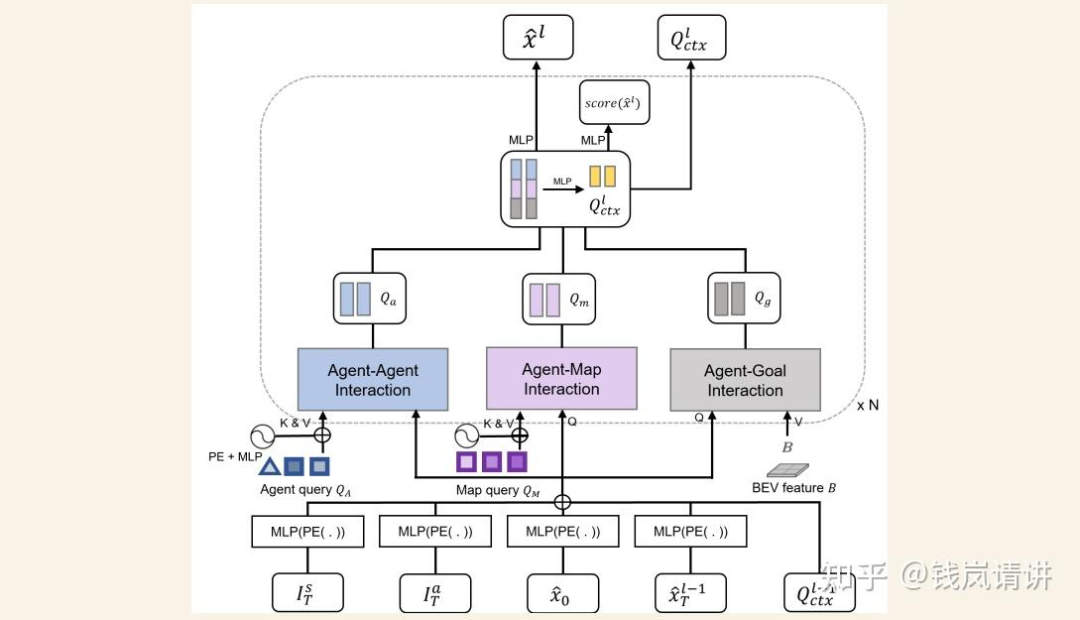
MotionFormer:agent表示交通参与者包括车辆行人等,goal表示交通参与者的目标位置后者轨迹的终点。MotionFormer共有3种交互:agent-agent(与表示动态agent的query交互),agent-map(与表示静态map的query交互),agent-goal。agent-agent输入track query和motion query,agent-map输入map query和motion query,agent-goal输入BEV feat和motion query(类似于BEVFormer中通过dcn完成query从BEV feat中extract motion context)。motion query由5部分组成:当前同一时刻的上一层decoder输出的goal point位置pos信息和query context上下文信息,agent当前位置,以及位置pos先验信息scene全局坐标系下的anchor end point和agent自车坐标系下clustered anchor end point(先验pos即从gt中利用kmeans对所有agents聚类)。decoder最终输出每个时刻所有可能轨迹点组成的multi-mode轨迹即多种可能性的轨迹,training中pre与gt的cost包含3部分,pre轨迹与gt轨迹之间点和点的距离,轨迹运动的物理约束。
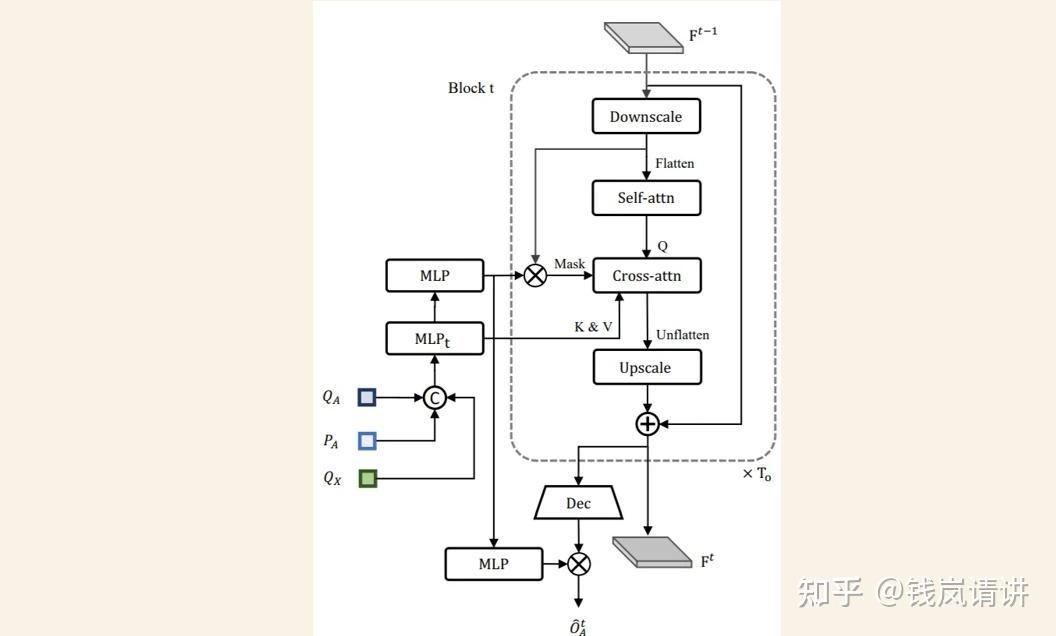
OccFormer:类似于RNN结构,逻辑也类似于NLP中顺序预测下一时刻词元。由个序列block顺序级联,第t个block对应时刻t。上一时刻block输出的scene feat以及sparse agent feat作为此时刻的输入,其中sparse agent feat包括TrackFormer输出的track query和agent position,以及MotionFormer输出的motion query(每个agent只取多mode轨迹中score最大值对应的query),表示未来场景中agent-level的知识。虚线框中pixel-agent interaction采用mask cross-attention使得 dense scene feat 只专注此时刻的agent,专注聚焦局部的相关agent信息。Instance-level occupancy将refined 与coarse mask agent-instance feat 矩阵相乘,得到包含每个agent的id表示的Occ。
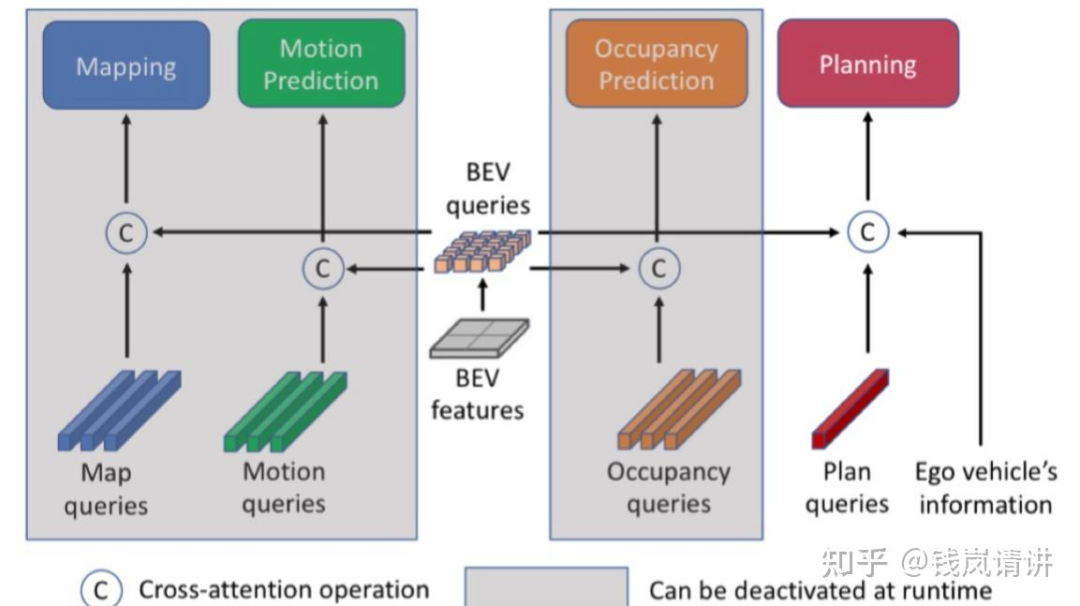
Q:[PARA-Drive]
基于UniAD的各模块,重新调整了感知预测以及规划各模块的连接方式。PARA-Drive中各子模块都采用并行同步协同训练的方式,各模块之间的联系只有updated BEV query(同BEVFormer)。测试推理时可去除Map/Motion/Occ模块,推理速度boost。

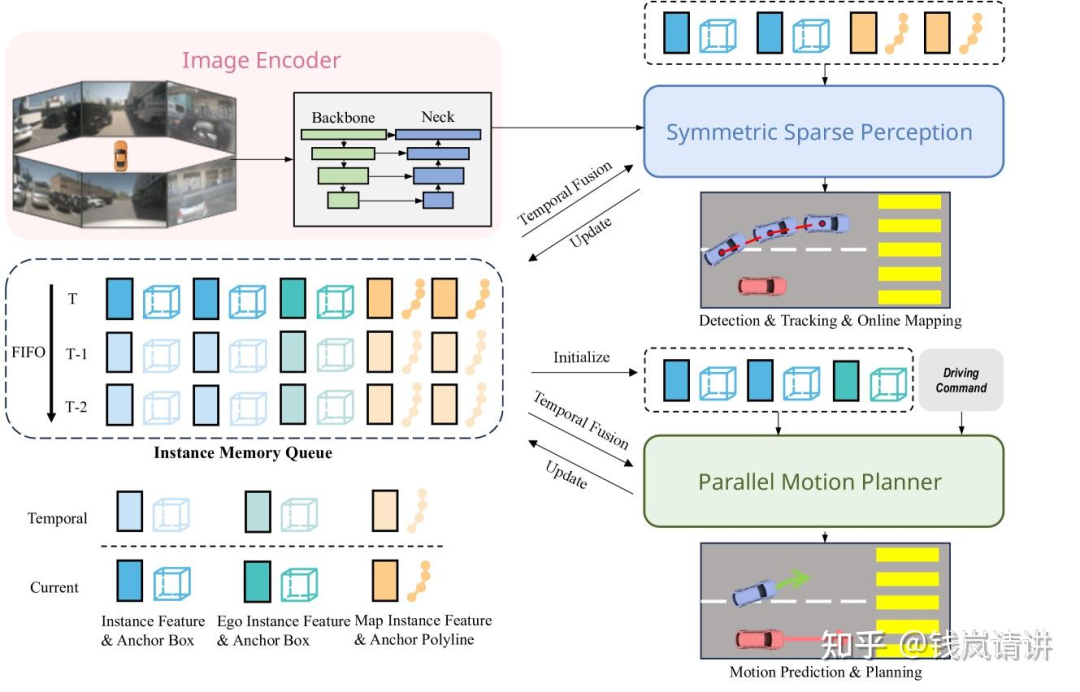
Q:[SpareDrive]
由3部分组成:image encoder提取多尺度多视角2D特征,symmetric sparse perception进行agents和map的感知以及motion planner预测agents和ego的轨迹。


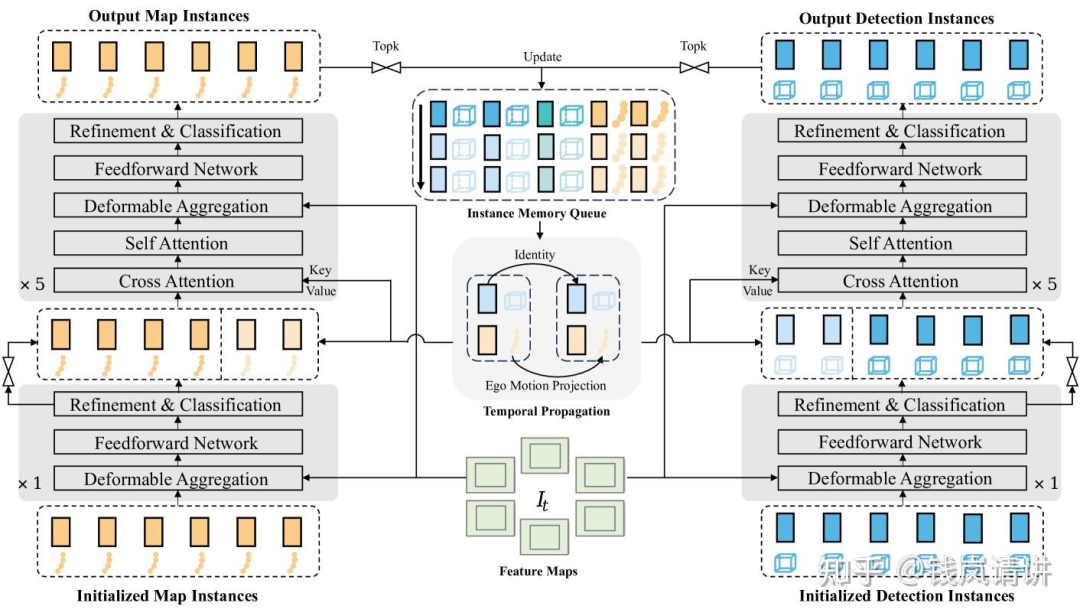

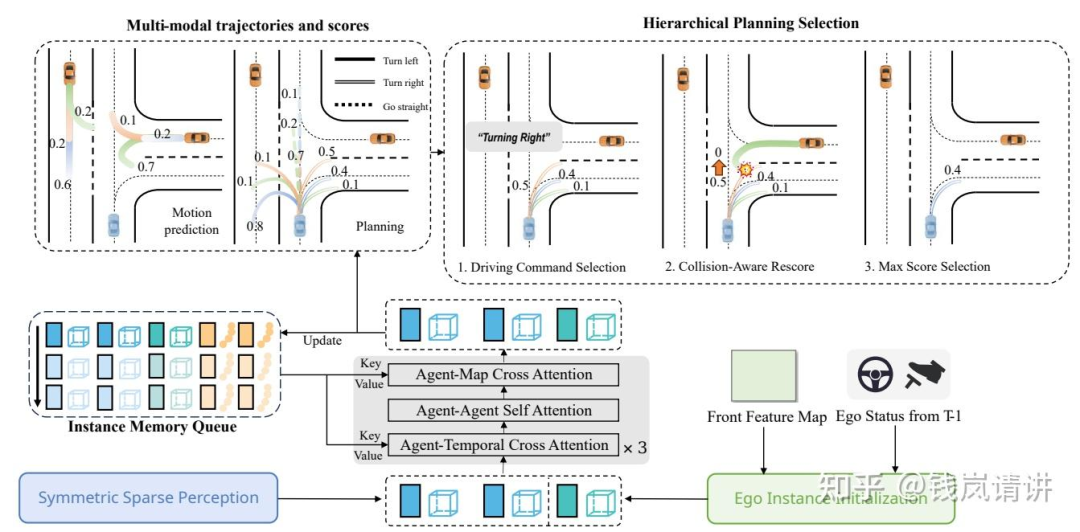
spatial-temporal interactions:逻辑类似于稀疏感知中的时序融合,但有所不同,之前稀疏感知中的cross-attention是当前帧instance与历史帧所有instance的交互,是scene-level,现在的agent-temporal是instance-level,聚焦的是某个instance与自己的历史instance的交互。query依然包括feat和anchor =concat(,),=concat(,)memory queue共有H个历史帧时刻,每个时刻包含个agents的feat+anchor以及1个ego的feat+anchor。最后预测输出周围agents的 X 条轨迹和 X 种planning,T表示多个timestamp,此外还预测相应的轨迹得分对应条轨迹和种planning
hierarchical planning selection:首先,根据驾驶命令cmd选择对应的轨迹集合;接着,结合周围agents的预测的轨迹和自车的planning轨迹,计算碰撞风险,碰撞风险高的轨迹,得分低;最后,选择最高分数的轨迹输出。
Q:[VADv2]
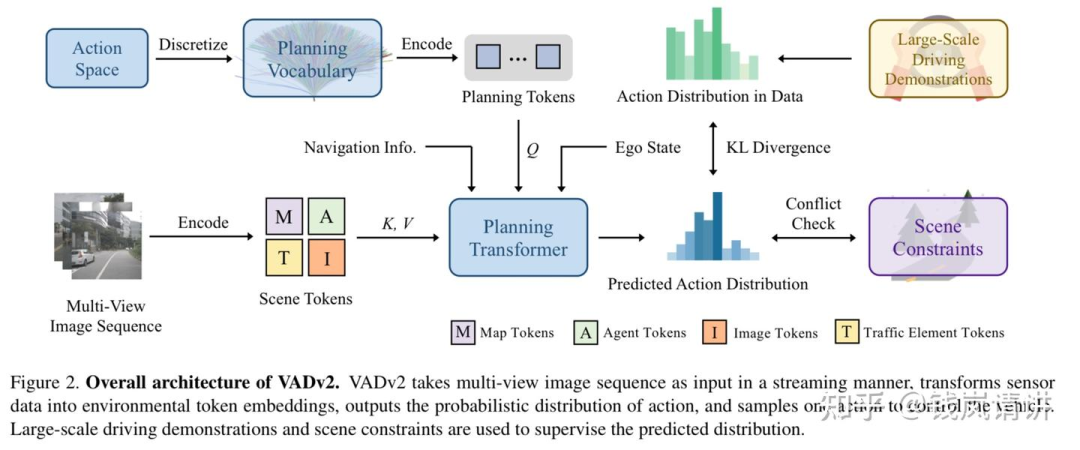
planning transformer输入包括planning token,scene token以及navi token导航/ego status token,通过planning token与scene的交互,最终输出每个action相应的概率,通过概率选出一条action。通过真实人类轨迹数据集当中action的概率来约束预测action概率,同时保留常见的轨迹冲突代价loss。
planning token:通过在真实人类驾驶规划action数据集中通过最远距离轨迹采样得到N条具有代表性的action,具体每个轨迹用点表示,然后作MLP得到planning token。
scene token:输入multi view图片,计算map/agents/traffic element token即提取静态动态不同环境要素pre,同时输入image token补充稀疏pre没有的信息。
navi/ego token:导航信息和ego status通过MLP也提取相应token。
① 2025中国国际新能源技术展会
自动驾驶之心联合主办中国国际新能源汽车技术、零部件及服务展会。展会将于2025年2月21日至24日在北京新国展二期举行,展览面积达到2万平方米,预计吸引来自世界各地的400多家参展商和2万名专业观众。作为新能源汽车领域的专业展,它将全面展示新能源汽车行业的最新成果和发展趋势,同期围绕个各关键板块举办论坛,欢迎报名参加。

② 国内首个自动驾驶学习社区
『自动驾驶之心知识星球』近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描加入

③全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

④【自动驾驶之心】全平台矩阵


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









