



点击下方卡片,关注“具身智能之心”公众号
机器人能拥有像人类一样灵巧的手吗?比如说,像人类一样接抛球,倒饮料,甚至拉小提琴?
注:特斯拉人形机器人Optimus再进化:换上22自由度灵巧手!来源:https://www.xiaohongshu.com/discovery/item/67497923000000000703ad78?source=webshare&xhsshare=pc_web&xsec_token=CBh2fYcvLoF5sKsO_i6KbkMFsN-BdY96Rjb5wxYVDUO6s=&xsec_source=pc_share
灵巧操作在高级机器人技术中占据着至关重要的地位。传统方法在处理灵巧操作任务时,如轨迹优化和精确动力学模型的运用,会遇到高维动作空间的问题。这意味着在规划机器人动作时,需要考虑众多的变量和参数,使得操作变得极为复杂。在实际操作中,机器人与环境的接触丰富,动力学复杂多变。强化学习虽然被用于处理复杂、高自由度的交互,但它需要大量的在线探索,并且奖励函数的设计至关重要。
内容出自国内首个具身智能全栈学习社区:具身智能之心知识星球,这里包含所有你想要的。
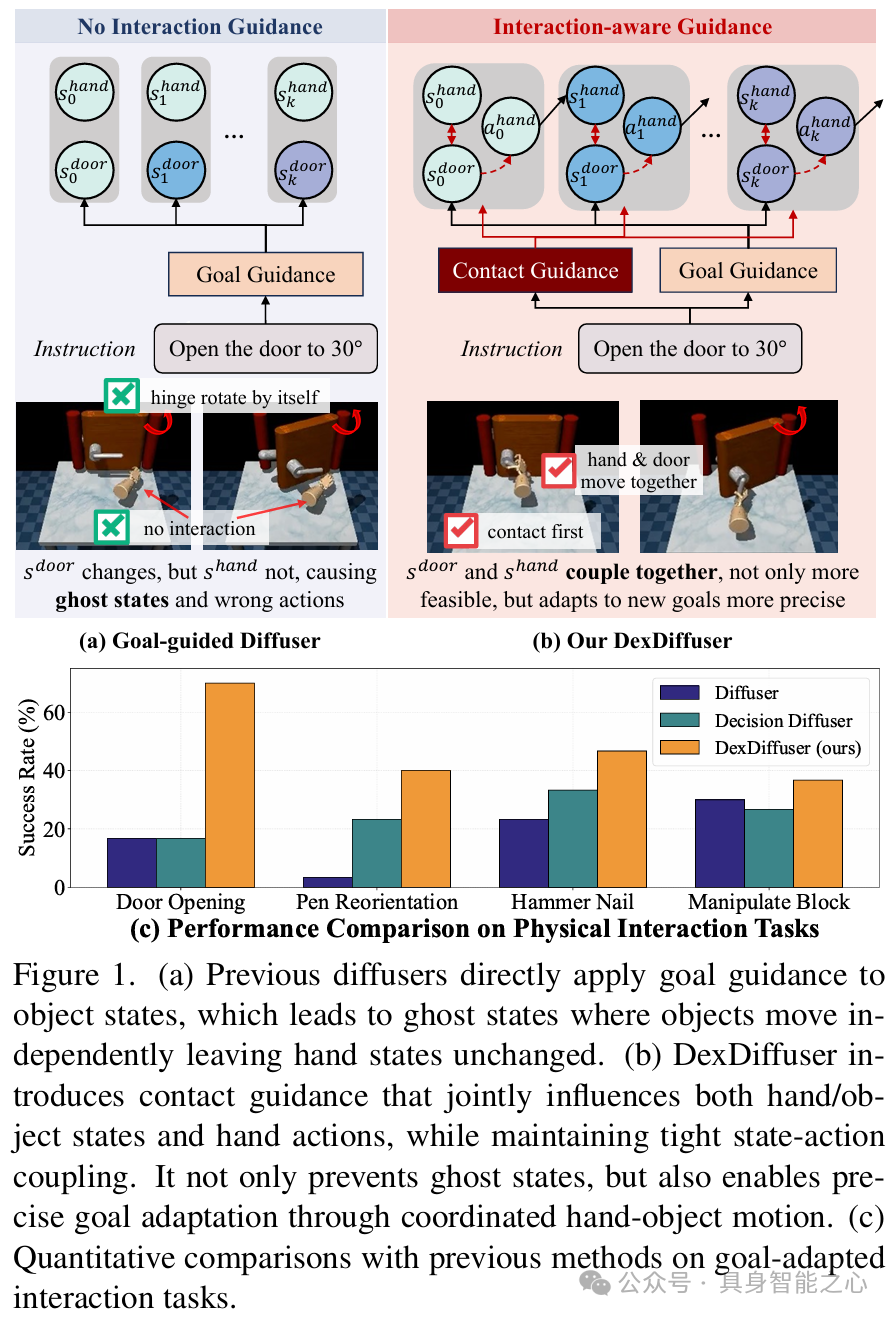
现有扩散方法在复杂任务中存在局限,以 Diffusion Policy 为代表的动作扩散模型(Cheng Chi et al., 2023),在训练数据充足且多样时,能提供精确、一致的动作控制。但对于需要多阶段自适应指导的任务,如开门任务中不同角度的适应,其缺乏在中间阶段进行明确状态指导的灵活性,难以实现手与物体在预抓取和抓取后状态的准确过渡。而状态扩散模型(Michael Janner et al., 2022)在处理灵巧操作任务时,如使用灵巧手用锤子钉钉子这种需要间接控制的任务,由于其对所有关节(包括物体关节)进行扩散,会出现物体在没有接触的情况下自行移动的 “幽灵状态”。这是因为在实际操作中,手的动作需要先影响中间状态,再作用于物体,而状态扩散模型忽略了这一物理过程,导致在依赖自适应、基于接触的控制调整的交互任务中,无法满足现实性要求。

此外,若使用分类器自由扩散模型(Zhixuan Liang et al., 2023),如 Diffusion Policy(Cheng Chi et al., 2023),在处理如推 T 任务或开门实验中,当目标与训练数据中的配置不同时,由于其依赖训练数据中的隐含表示,无法直接修改目标位置或适应新的目标角度,限制了在零样本或新任务场景中的目标适应性。
基于此,香港大学、加州大学伯克利分校等高校的研究人员提出 DexDiffuser 框架,旨在解决上述问题,实现自适应灵巧操作,提高在接触丰富场景下的任务执行能力和目标适应性。DexDiffuser通过以下方式推进了自适应灵巧操作:1)提出了第一个用于灵巧操作的交互感知、目标自适应扩散规划器,对机器人-对象-环境依赖关系进行建模,以处理具有复杂状态转换的顺序任务。2) DexDiffuser通过基于动态的双制导和基于LLM的交互制导联合建模状态-动作行为,为灵巧操作中的自适应规划设定了新标准,并首次将文本-奖励概念扩展到扩散器。3)对不同灵巧操作任务进行了实验验证,验证了该方法的鲁棒性和适应性。在目标导向的任务中,DexDiffuser的平均成功率是次优方法的两倍多(59.2% vs 29.5%)。
相关工作
灵巧操作:传统方法在处理复杂灵巧操作任务时存在困难,强化学习(Yuanpei Chen, 2022)需要大量探索和精心设计奖励函数,基于演示的方法(Bohan Zhou,2024)在泛化方面存在挑战,而 DexDiffuser 通过显式建模手 - 对象 - 环境交互来解决这些问题。
基于扩散的规划方法:规划中使用扩散模型在机器人操作模仿学习中变得重要,但缺乏在中间阶段进行明确状态指导的灵活性、会出现物体在没有接触的情况下自行移动的 “幽灵状态”。DexDiffuser 通过结合状态和动作空间的分类器引导扩散来解决,以实现更精确、交互感知的规划。
基于 LLM 的机器人策略代码生成:LLM 在为机器人任务生成计划或代码方面有潜力,如Eureka(Yecheng Jason Ma, 2023), Text2Reward(Tianbao Xie, 2023), RoboCodeX(Yao Mu,2024)。DexDiffuser 将此文本到代码范式扩展到基于扩散的规划器,通过其显式能量函数公式为 LLM 生成的指导函数提供自然接口。
模型架构
接下来一起看看模型架构。DexDiffuser主要包括交互感知扩散规划和基于 LLM 的指导生成两方面内容。
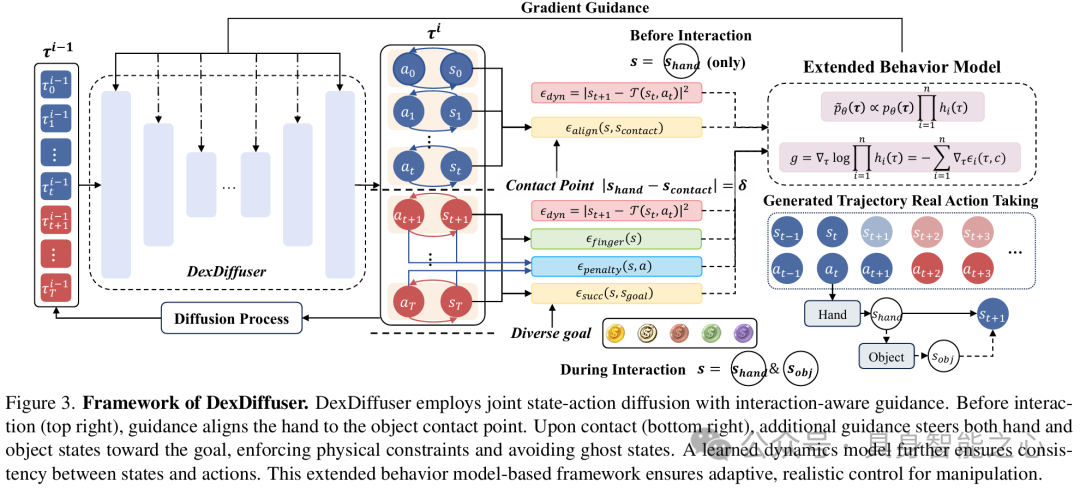
1 交互感知扩散规划
联合状态 - 动作扩散模型:以分类器引导扩散模型为基础,联合扩散状态 - 动作空间。它能够实现明确的状态条件设定,在面对不同任务需求时,可灵活适应目标变化,同时确保物理一致性。
扩展分类器引导扩散策略公式:对基本分类器引导扩散框架进行扩展,借助product of experts framework( Geoffrey E Hinton. 2002)将多个指导相结合。当面对多目标、多约束的复杂任务场景时,该方法可根据不同的任务要求,综合多个指导因素,引导机器人做出准确且适应性强的动作。
基于接触的任务指导:采用双阶段交互方法,依据手与物体接触点距离自动判断阶段转换时机。在不同阶段运用相应的指导组件,在接触前阶段,确保机器人手与物体能稳定对齐;接触后阶段,实现目标导向控制。这种方式有效防止了 “幽灵状态” 的出现,使机器人操作更加真实、可靠,符合物理实际情况。
手中操作指导:针对主要涉及手中操作的任务,采用简化的单阶段指导结构。该结构涵盖目标状态指导、手指运动指导、动力学一致性指导、物理约束指导,通过这些指导的协同作用,提升手中操作任务的执行效果。
动力学感知生成:借助学习的动力学模型,保障生成状态和动作的一致性。当出现违反物理模式的状态 - 动作对时,模型会对其进行惩罚。
2 基于 LLM 的指导生成
环境抽象:采用全面的 Python 环境表示,封装机器人关节配置和对象 - 环境规范,使 LLM 能生成精确指导函数。
指导生成:分类器引导扩散框架使自然语言描述能直接转换为可执行指导函数,无需大量重新训练,提供更大灵活性和可解释性。
集成:集成多个提示组件,使用少样本知识代替传统少样本示例,使模型能访问相关函数和最佳实践,同时对每个指导组件进行归一化,确保目标贡献平衡。
实验
文章接下来对不同灵巧操作任务进行了实验验证,在 Adroit 手和 Shadow 手环境中评估 DexDiffuser,使用专家演示和 TQC + HER 收集的轨迹进行训练,包括开门、锤击、笔和块重新定向等任务,验证了该方法的鲁棒性和适应性。
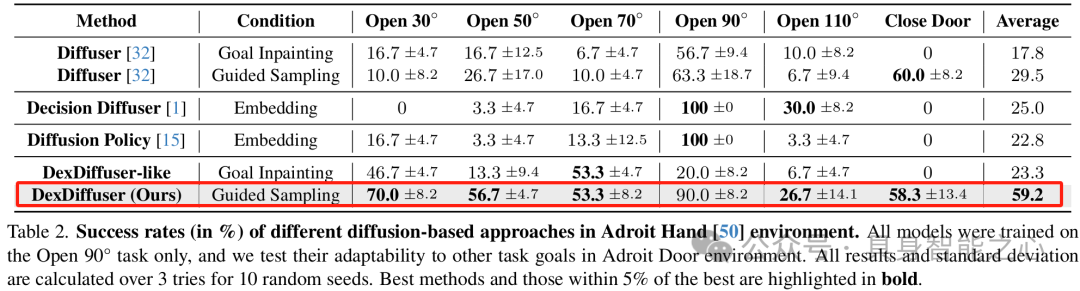
在开门任务中评估 DexDiffuser 的目标适应性,与多个基线方法比较,DexDiffuser 在不同目标角度下表现出色,平均成功率达 59.2%,是其他方法的两倍以上。
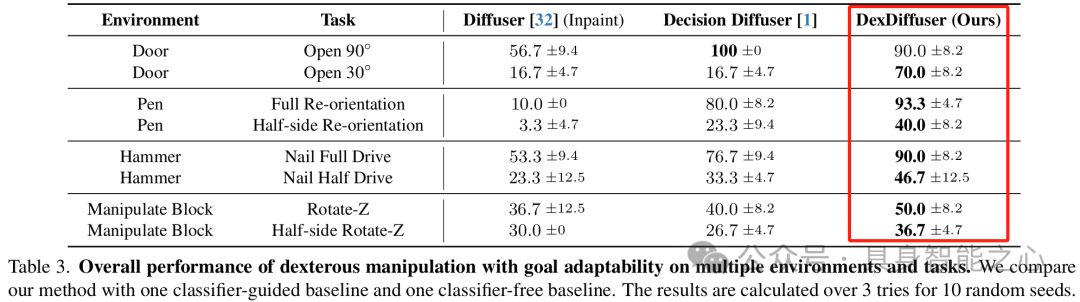
在多个灵巧操作任务中测试 DexDiffuser 的跨任务适应性和目标导向性能,与 Diffuser 和 Decision Diffuser 比较,DexDiffuser 在域内和目标适应任务中均取得优异结果。
LLM 指导生成的消融实验中,比较不同指导方法在目标适应任务中的效果,人工设计和 LLM 生成的指导函数显著优于朴素指导,人工设计的成功率最高。

表5通过消融实验分析 DexDiffuser 各组件的贡献,表明完整设计的有效性。
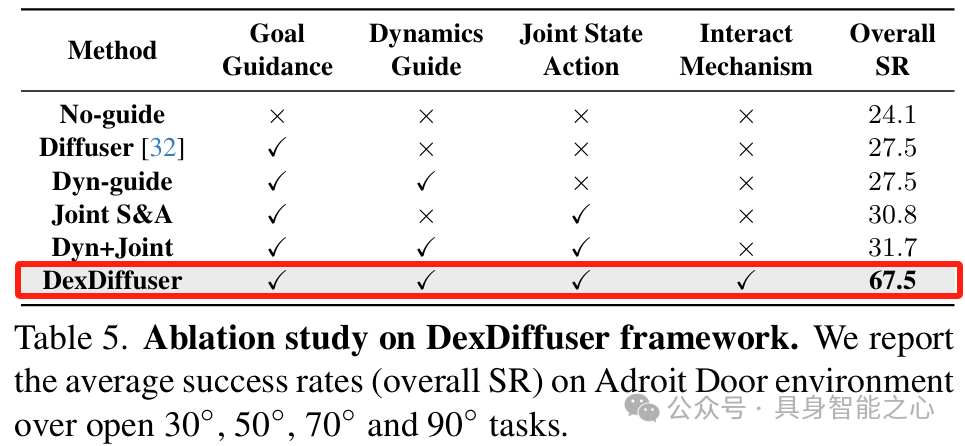
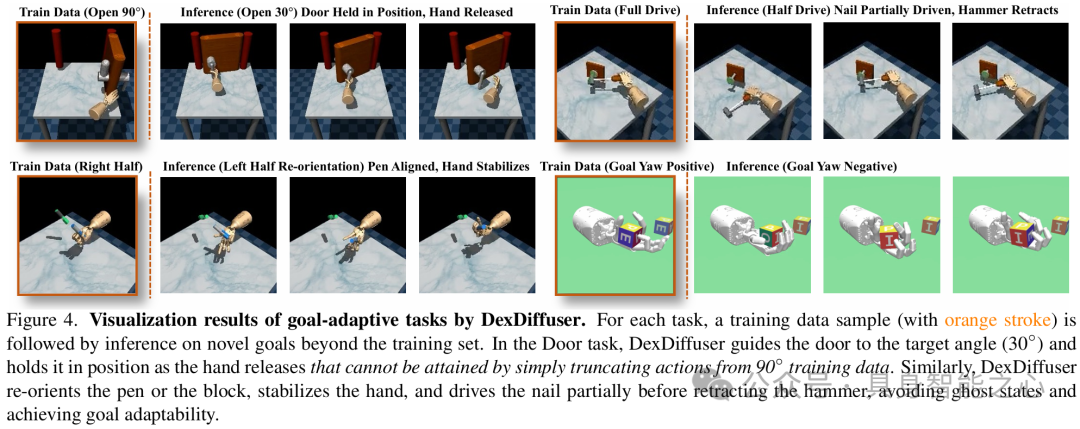
图4展示了 DexDiffuser 在各种目标适应灵巧任务中的交互感知行为,确保与目标对象的真实接触,消除 “幽灵状态”,实现目标适应。
结论
DexDiffuser 是一种用于自适应灵巧操作的交互感知扩散规划框架,通过建模联合状态 - 动作动力学和双阶段扩散机制,解决了现有扩散方法的问题,在复杂操作任务中表现出色,为机器人灵巧操作领域提供了新的方法和思路。
DexDiffuser: Interaction-aware Diffusion Planning for Adaptive Dexterous Manipulation
https://arxiv.org/abs/2411.18562
https://dexdiffuser.github.io/


“具身智能之心”公众号持续推送具身智能领域热点:
往期 · 推荐
(1)具身多模态基础模型
NVIDIA最新!NVLM:开放级别的多模态大语言模型(视觉语言任务SOTA)
全面梳理视觉语言模型对齐方法:对比学习、自回归、注意力机制、强化学习等
CLIP怎么“魔改”?盘点CLIP系列模型泛化能力提升方面的研究
揭秘CNN与Transformer决策机制:设计原则是关键?
VILA:视觉推理能力如何up up?多模态预训练设计有妙招
(2)3D场景理解、分割与交互
PoliFormer: 使用Transformer扩展On-Policy强化学习,卓越的导航器
大模型继续发力!SAM2Point联合SAM2,首次实现任意3D场景,任意Prompt的分割
更丝滑更逼真!模型自主发现与模式自动识别新升级助力三维场景构建与形状合成
进一步向开放识别迈进!3D场景理解与视觉语言模型的融合创新可以这样玩
(3)具身机器人与环境交互
TPAMI 2024 | OoD-Control:泛化未见环境中的鲁棒控制(一览无人机上的效果)
纽约大学最新!SeeDo:通过视觉语言模型将人类演示视频转化为机器人行动计划
CMU最新!SplatSim: 基于3DGS的RGB操作策略零样本Sim2Real迁移
伯克利最新!CrossFormer:一个模型同时控制单臂/双臂/轮式/四足等多类机器人
斯坦福大学最新!Helpful DoggyBot:四足机器人和VLM在开放世界中取回任意物体
港大最新!RoboTwin:结合现实与合成数据的双臂机器人基准
Robust Robot Walker:跨越微小陷阱,行动更加稳健!
波士顿动力最新SOTA!ThinkGrasp:通过GPT-4o完成杂乱环境中的抓取工作
基础模型如何更好应用在具身智能中?美的集团最新研究成果揭秘!
(4)具身仿真×自动驾驶
麻省理工学院!GENSIM: 通过大型语言模型生成机器人仿真任务
EmbodiedCity:清华发布首个真实开放环境具身智能平台与测试集!
华盛顿大学 | Manipulate-Anything:操控一切! 使用VLM实现真实世界机器人自动化
东京大学最新!CoVLA:用于自动驾驶的综合视觉-语言-动作数据集
ECCV 2024 Oral | DVLO:具有双向结构对齐功能的融合网络,助力视觉/激光雷达里程计新突破
(5)权威赛事结果速递
模型与场景的交互性再升级!感知、行为预测以及运动规划在Waymo2024挑战赛中有哪些亮点
效率和精度齐飞!CVPR2024 AIS workshop亮点大盘点
(6)具身智能工具深度测评
巨好用的工具安利!胜过WPS?MinerU 帮你扫清PDF提取
UCLA出品!用于城市空间的具身人工智能模拟平台:MetaUrban
(7)具身智能时事速递
端到端、多模态、LLM如何与具身智能融合?看完这50家公司就明白了
见证历史?高通准备收购英特尔!
万张A100“堆”出来的勇气:一个更极致的中国技术理想主义故事
即将截止!ECCV'24自动驾驶难例场景多模态理解与视频生成挑战赛


















 2555
2555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









