 机器人操作模仿学习的数据缩放规律研究
机器人操作模仿学习的数据缩放规律研究




点击下方卡片,关注“具身智能之心”公众号
想象一下,你正在火锅店涮肉,一位“人美声靓”的服务员悄然从你身边走过,不仅及时地为你把菜送到身边,还帮你把菜端到桌子上并摆放整齐。正在酣畅淋漓涮肉的你正想夸一下这家店的服务真不错,猛一抬头发现,居然是个机器人!

咨询了店长才知道,这是昨天刚到的一批“服务员”。内心更加震惊:居然这么快就上岗工作了!都不用培训?即插即用?!
这大概就是Scaling law的魔力了吧。
现如今大模型已发展得如火如荼,然而为什么还没有实现真正的落地?也就是说,为了让AI渗透到生活的每个角落,实现边缘化部署,还需要做什么?有一点亟需研究清楚,即模型性如何能随数据集、模型大小和训练计算量的增加而提升?这就是Data Scaling Law,也可称为数据缩放定律。如何在保留数据集关键信息的同时,尽可能减少数据量,而不牺牲模型的性能?如何在不增加计算资源的情况下,尽量降低模型的错误率?
早在2020年,OpenAI就提出了对Neural Language Models的Scaling law(Kaplan et al.,https://arxiv.org/pdf/2001.08361),说明了模型性能随着模型参数量、数据量和用于训练的计算量的指数级增加而平稳提高。对于计算量(C),模型参数量(P)和数据大小(D),当不受其他两个因素制约时,模型性能与每个因素都呈现幂律关系。2022年DeepMind团队(Hoffmann et al., https://arxiv.org/pdf/2203.15556)发现不应该将大模型训练至最低的可能loss来获得计算最优,模型规模和训练tokens的数量应按相同比例扩展。2023年Hugging Face团队(Colin Raffel et al., https://arxiv.org/pdf/2305.16264)发现在量化在数据受限的情况下,通过增加训练epoch和增加模型参数可以以次优计算利用率为代价提取更多的信息。
本期具身智能之心介绍的这篇文章发现,通过适当的数据缩放,单任务策略可以很好地泛化到任何新环境以及同一类别中的任何新对象。值得注意的是,机器人甚至可以在火锅店中进行零样本部署!
视频来源:https://data-scaling-laws.github.io/
文章表明,当前机器人策略缺乏零样本泛化能力,文章旨在研究机器人操作中数据缩放规律,为构建大规模机器人数据集提供指导。文章探讨了机器人操作模仿学习中的数据缩放规律,通过实验揭示了策略泛化性能与训练环境、对象及演示数量的关系,提出了高效的数据收集策略。
DATA SCALING LAWS IN IMITATION LEARNING FOR ROBOTIC MANIPULATION
https://data-scaling-laws.github.io/
https://data-scaling-laws.github.io/paper.pdf
论文通过 Pour Water(倒水)和 Mouse Arrangement(鼠标放置)两项任务进行大量实验以得出数据缩放规律,并在 Fold Towels(叠毛巾)和 Unplug Charger(拔充电器)等其他任务上进一步验证这些发现。文章的发现如下:
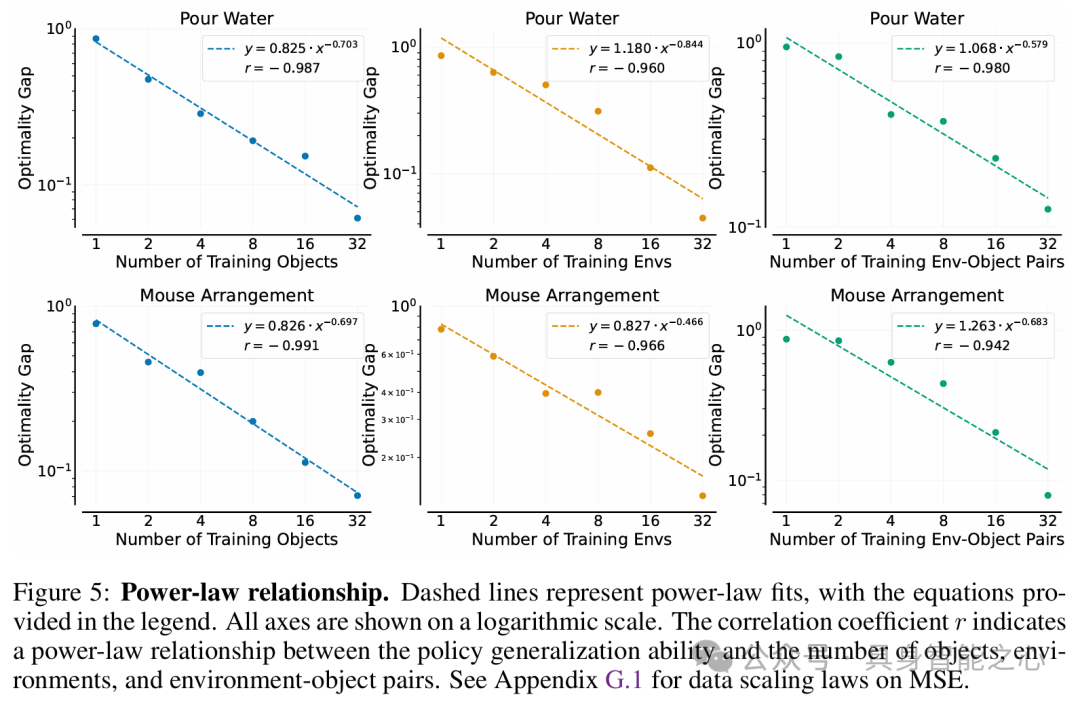
简单幂律:策略对新对象、新环境或两者的泛化能力分别大致与训练对象、训练环境或训练环境 - 对象对的数量呈幂律关系。
多样性就是关键:增加环境和对象的多样性远比增加每个环境或对象的演示绝对数量更有效。
泛化比预期更容易:在尽可能多的环境(例如 32 个环境)中收集数据,每个环境有一个独特的操作对象和 50 次演示,就能够训练出一个对任何新环境和新对象都能很好泛化(90% 成功率)的策略。

相关工作
那么,有哪些已有研究工作与机器人操作数据缩放定律相关呢?
缩放规律:缩放规律最初在神经语言模型中被发现,揭示了数据集大小(或模型大小、计算量)与交叉熵损失之间的幂律关系。
机器人操作中的数据缩放:机器人操作领域也有数据规模扩大的趋势,但部署仍需微调。本文关注训练可直接在新环境和未见对象中部署的策略,同时也有研究探索提高数据缩放效率以增强泛化能力。
机器人操作中的泛化:包括对新对象实例、新环境的泛化以及遵循新任务指令的泛化。本文专注于前两个维度,即创建能在任何环境中操作同一类别内几乎任何对象的单任务策略。
研究方法
概括维度:考虑环境(对未见环境的泛化)和对象(对同一类别新对象的泛化)两个维度,通过收集不同环境和对象的人类演示数据,使用行为克隆(BC)训练单任务策略。
数据缩放规律公式化:在M个环境和N个同一类别的操作对象中收集演示数据,每个环境 - 对象对收集K个演示,评估策略在未见环境和对象上的性能,以揭示泛化能力与变量M、N、K的关系。
评估:通过在未见环境或对象中测试评估策略泛化性能,使用测试者分配的分数作为主要评估指标(计算归一化分数),同时最小化测试者主观偏差,确保结果可靠。
实验结果与分析
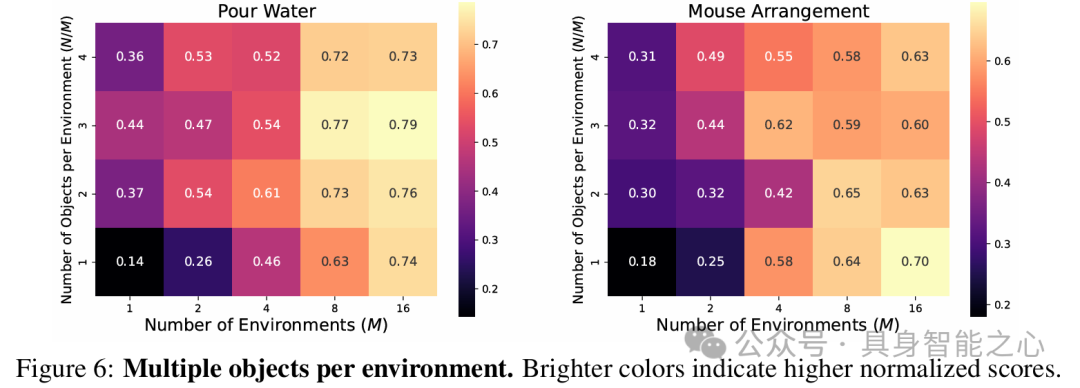
实验结果如下。以Pour Water和Mouse Arrangement任务为例,增加训练对象数量可提高策略对未见对象的性能,对象泛化相对容易实现,且训练对象增多时,每个对象所需演示减少。
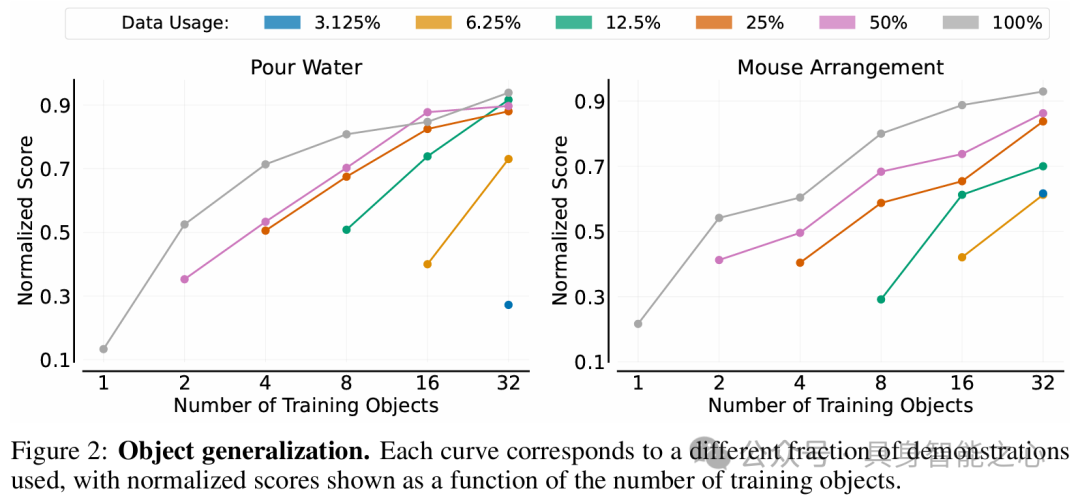
用相同操作对象在不同环境收集数据,增加训练环境数量可提升策略在未见环境的泛化性能,但每个环境中演示数量增加对性能提升的作用会快速减弱,且环境泛化比对象泛化更具挑战性。
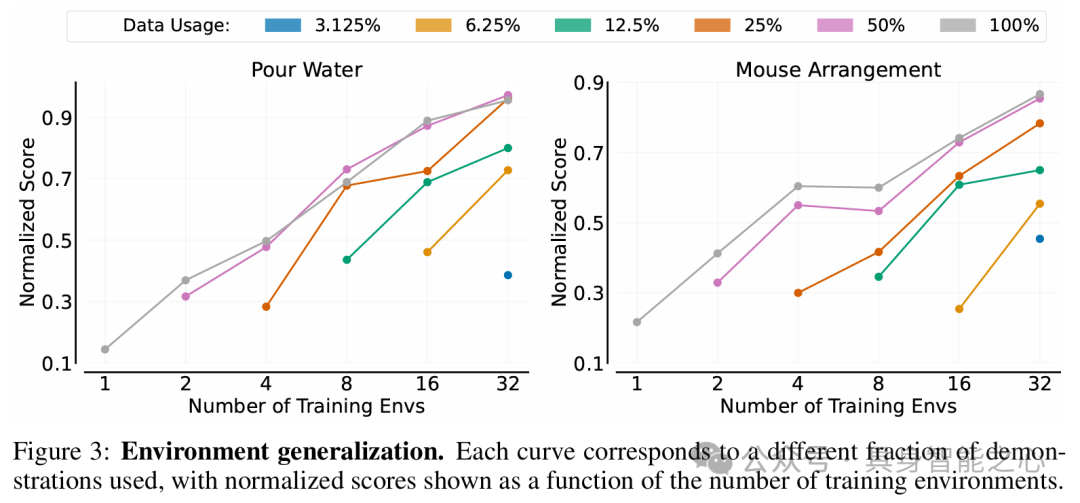
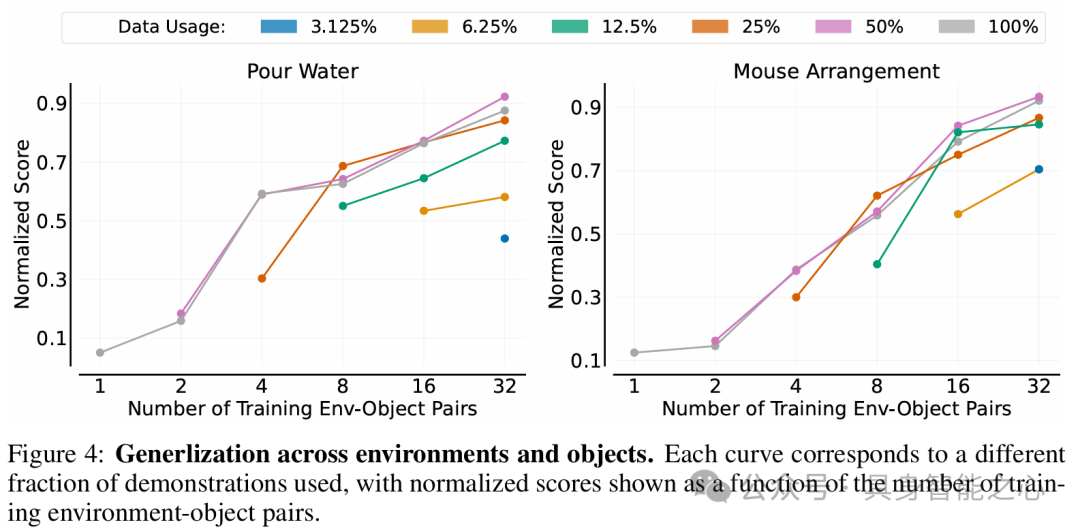
在环境和对象同时变化的设置中,增加训练环境 - 对象对数量可增强策略泛化性能,且同时改变环境和对象比单独改变更能增加数据多样性,使策略学习更高效。
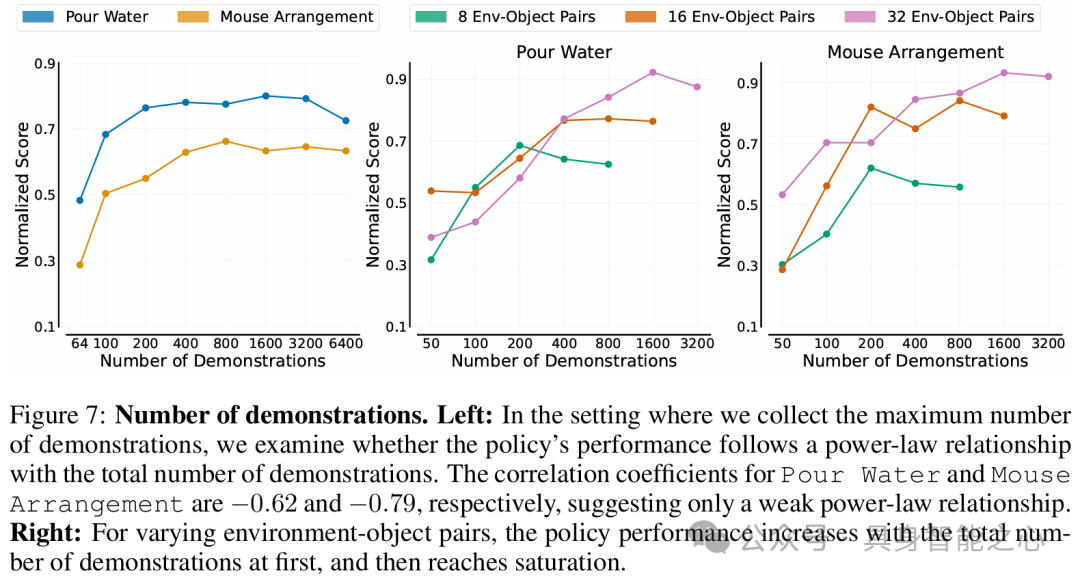
实验结果遵循幂律缩放规律,策略对新对象、新环境或两者的泛化能力分别与训练对象、环境或环境 - 对象对数量呈幂律关系;当环境和对象数量固定时,演示数量与策略泛化性能无明显幂律关系。
为了实现高效的数据收集策略,文章建议在尽可能多的不同环境中收集数据,每个环境使用一个独特对象;当环境 - 对象对总数达到32时,通常足以训练出在新环境中操作未见对象的策略。
实验表明,超过一定数量的演示收益甚微,对于类似难度任务,建议每个环境 - 对象对收集50个演示,更具挑战性的灵巧操作任务可能需要更多演示。
为了验证上述策略的合理性,将数据收集策略应用于Fold Towels和Unplug Charger新任务,四个任务(包括之前的Pour Water和Mouse Arrangement)的策略成功率约达90%,凸显了数据收集策略的高效性。

模型大小和训练策略:研究Diffusion Policy中视觉编码器的训练策略和参数缩放影响,发现预训练和全量微调对视觉编码器至关重要,增加其大小可提升性能,但缩放动作扩散U - Net未带来性能提升。
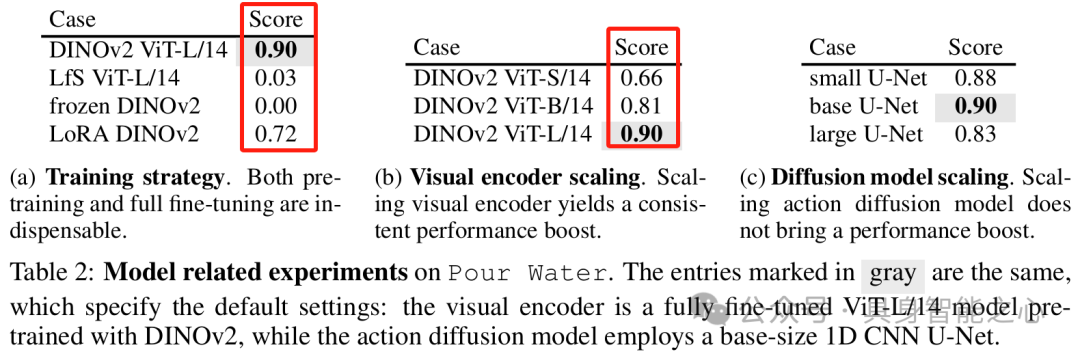
文章还强调数据缩放应注重数据质量,本文揭示了环境和对象多样性在模仿学习中的重要价值。但本文仍存在一些局限性,比如当前工作专注于单任务策略的数据缩放,未探索任务级泛化;仅研究了模仿学习中的数据缩放,强化学习或可进一步增强策略能力;UMI收集数据存在小误差且仅用Diffusion Policy算法建模,未来可研究数据质量和算法对数据缩放规律的影响;资源限制下仅在四个任务上探索和验证数据缩放规律,期望未来在更多复杂任务上验证结论。
“具身智能之心”公众号持续推送具身智能领域热点:
往期 · 推荐
(1)具身多模态基础模型
NVIDIA最新!NVLM:开放级别的多模态大语言模型(视觉语言任务SOTA)
全面梳理视觉语言模型对齐方法:对比学习、自回归、注意力机制、强化学习等
CLIP怎么“魔改”?盘点CLIP系列模型泛化能力提升方面的研究
揭秘CNN与Transformer决策机制:设计原则是关键?
VILA:视觉推理能力如何up up?多模态预训练设计有妙招
(2)3D场景理解、分割与交互
PoliFormer: 使用Transformer扩展On-Policy强化学习,卓越的导航器
大模型继续发力!SAM2Point联合SAM2,首次实现任意3D场景,任意Prompt的分割
更丝滑更逼真!模型自主发现与模式自动识别新升级助力三维场景构建与形状合成
进一步向开放识别迈进!3D场景理解与视觉语言模型的融合创新可以这样玩
(3)具身机器人与环境交互
TPAMI 2024 | OoD-Control:泛化未见环境中的鲁棒控制(一览无人机上的效果)
纽约大学最新!SeeDo:通过视觉语言模型将人类演示视频转化为机器人行动计划
CMU最新!SplatSim: 基于3DGS的RGB操作策略零样本Sim2Real迁移
伯克利最新!CrossFormer:一个模型同时控制单臂/双臂/轮式/四足等多类机器人
斯坦福大学最新!Helpful DoggyBot:四足机器人和VLM在开放世界中取回任意物体
港大最新!RoboTwin:结合现实与合成数据的双臂机器人基准
Robust Robot Walker:跨越微小陷阱,行动更加稳健!
波士顿动力最新SOTA!ThinkGrasp:通过GPT-4o完成杂乱环境中的抓取工作
基础模型如何更好应用在具身智能中?美的集团最新研究成果揭秘!
(4)具身仿真×自动驾驶
麻省理工学院!GENSIM: 通过大型语言模型生成机器人仿真任务
EmbodiedCity:清华发布首个真实开放环境具身智能平台与测试集!
华盛顿大学 | Manipulate-Anything:操控一切! 使用VLM实现真实世界机器人自动化
东京大学最新!CoVLA:用于自动驾驶的综合视觉-语言-动作数据集
ECCV 2024 Oral | DVLO:具有双向结构对齐功能的融合网络,助力视觉/激光雷达里程计新突破
(5)权威赛事结果速递
模型与场景的交互性再升级!感知、行为预测以及运动规划在Waymo2024挑战赛中有哪些亮点
效率和精度齐飞!CVPR2024 AIS workshop亮点大盘点
(6)具身智能工具深度测评
巨好用的工具安利!胜过WPS?MinerU 帮你扫清PDF提取
UCLA出品!用于城市空间的具身人工智能模拟平台:MetaUrban
(7)具身智能时事速递
端到端、多模态、LLM如何与具身智能融合?看完这50家公司就明白了
见证历史?高通准备收购英特尔!
万张A100“堆”出来的勇气:一个更极致的中国技术理想主义故事
即将截止!ECCV'24自动驾驶难例场景多模态理解与视频生成挑战赛


















 4125
4125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









