



作者 | ColdM1rr0r 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/5804278465
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
主要参考了wayve发布的视频
www.youtube.com/watch?v=a_q3Efh6-5E&ab_channel=Wayve
Structure
Traditional AV stack 1.0
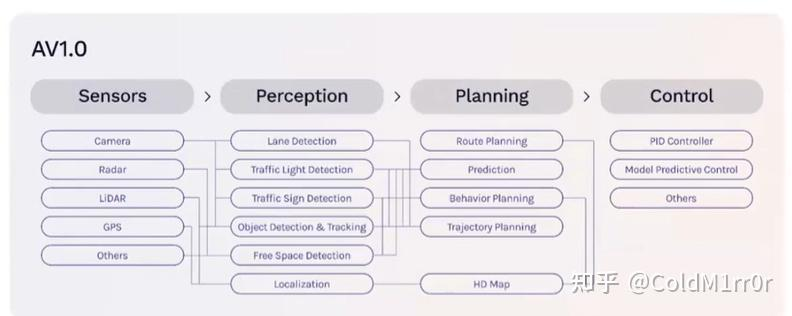
这是一个需要比较大成本的系统,目前也没有一家公司真正做到了。
高精地图(高精地图建图&依赖高精度传感器建图)
数据标记
AV 2.0(Wayve)
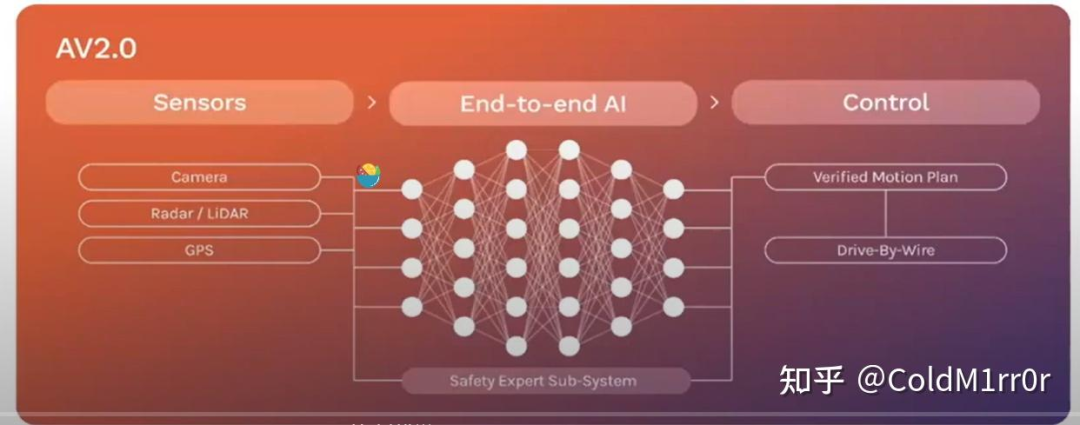
算法易于部署在不同传感器芯片移植(computationally homogeneous)
数据驱动(Generalisation through data)
无图方案成本低,泛化性高(scalable and economic)
安全(outperforms hand-coded solutions)

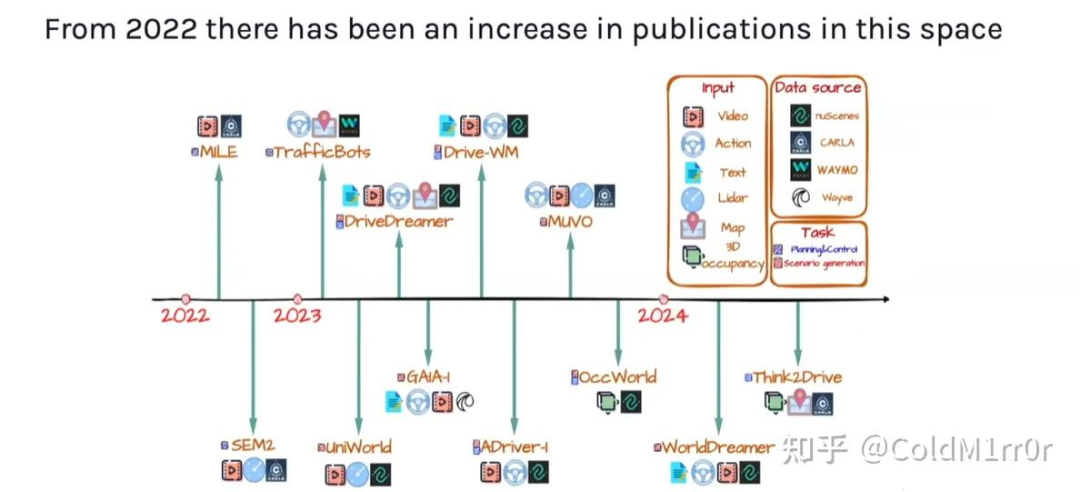
Frontiers in Embodied AI Research
Simulation
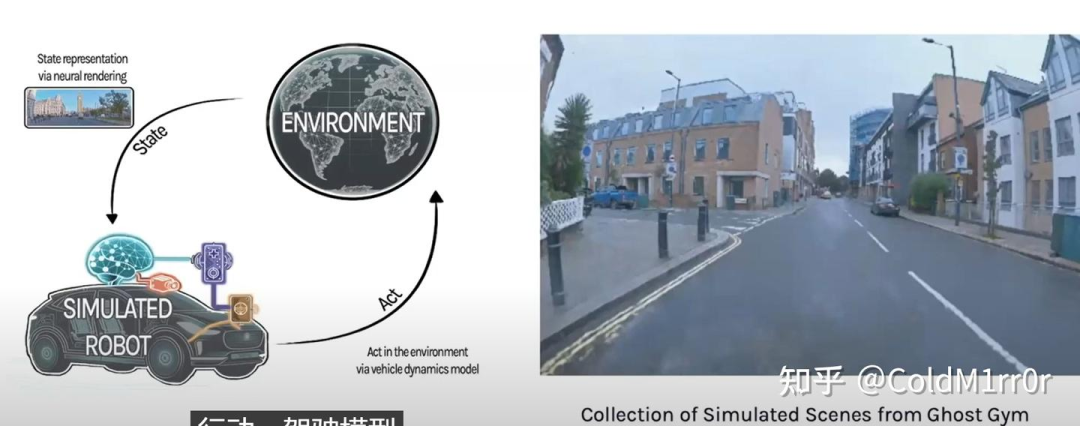
端到端的仿真需要模拟出视觉信息,这是非常困难的,总结一些Wayve的工作:
缩小了预测和行为的gap
动态物体和可形变的物体模拟
模拟出整个环境和平台
数据驱动&可移植
长尾问题
Ghost Gym: A Neural Simulator for AD
https://wayve.ai/thinking/ghost-gym-neural-simulator/

PRISM-1
动态场景重建模型
自监督,4D,Non-parametric scene representation
https://wayve.ai/thinking/prism-1


这个水坑和动态的踩自行车真的牛。。。而且是4d重建,不是一个简单的动画。
而且用正弦曲线去扰乱,也能保证生成的场景很完美,甚至能保证生成的行人也不漂移,甚至还拿着雨伞。
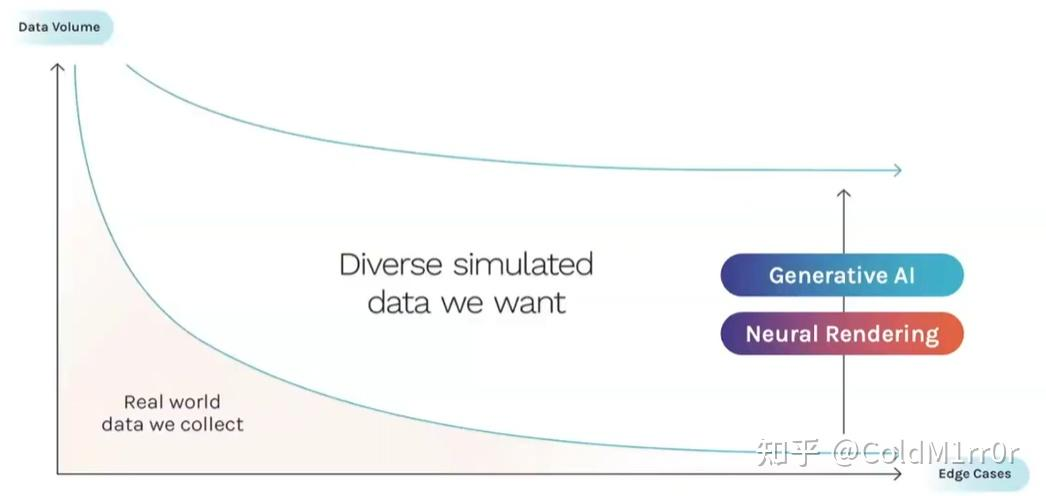
训练场景集:https://wayve.ai/science/wayvescenes101/

不止能重建世界,也能生成一些多样化的场景(所有data driven的优势)
Wayve GAIA(2023)- Generative World Model
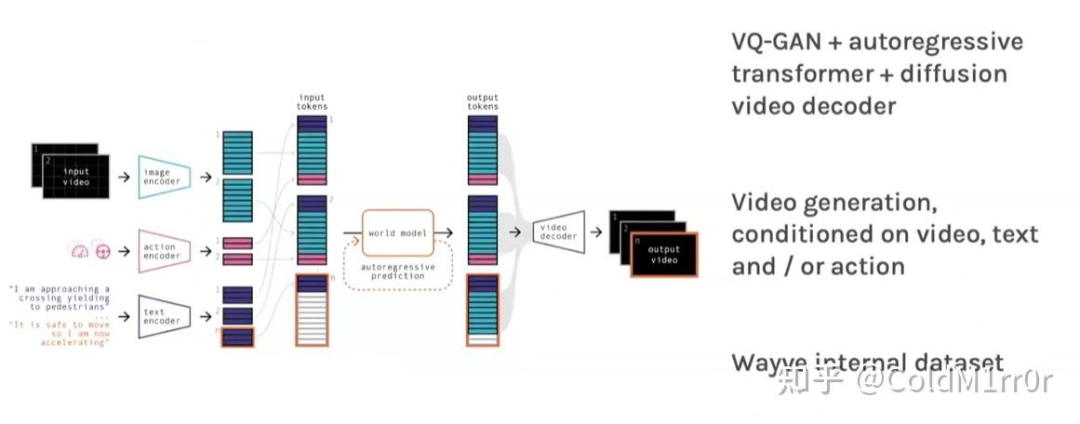
arxiv.org/abs/2403.02622
World Models for Autonomous Driving: An Initial Survey
arxiv.org/abs/2403.02622
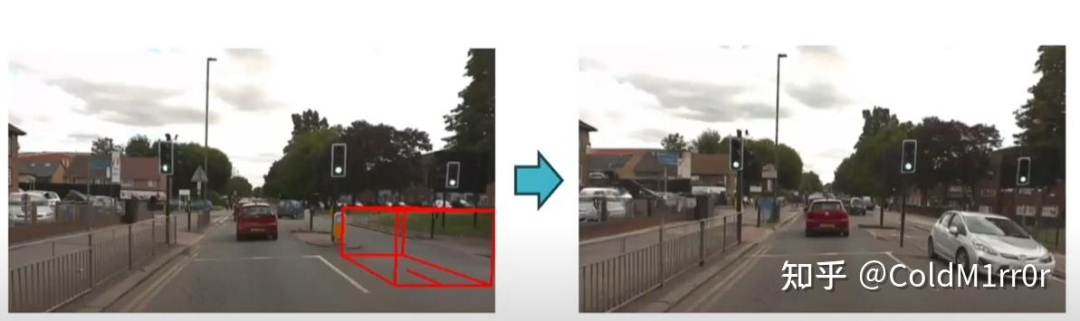
GAIA还可以添加objects,并且做标记(动态的)

Multimodality
LLM4Drive: A Survey of Large Language Models for Autonomous Driving
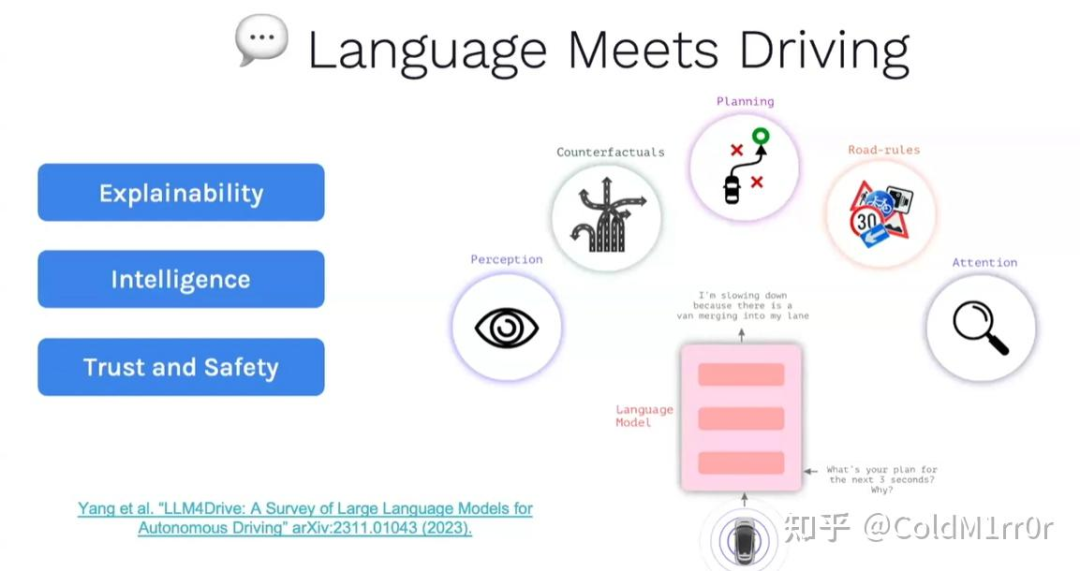
Lingo1: https://wayve.ai/thinking/lingo-natural-language-autonomous-driving/
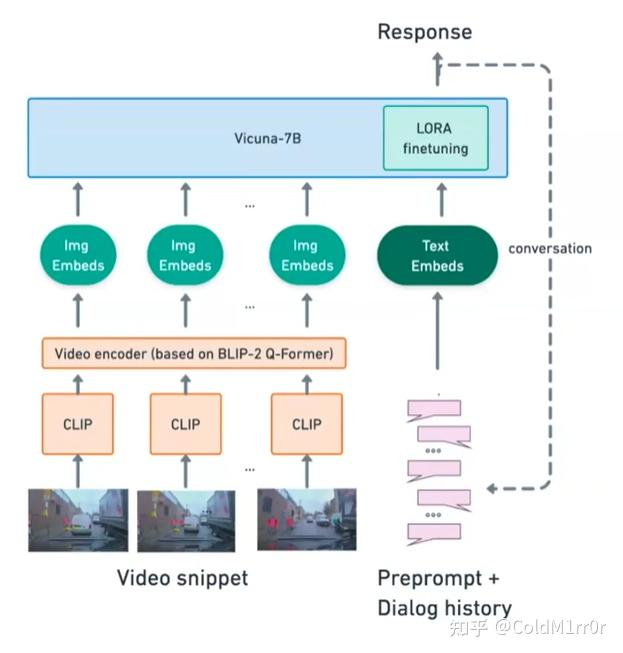
Lingo2: https://wayve.ai/thinking/lingo-2-driving-with-language/
更注重实际驾驶,不仅在驾驶,而且在解释。
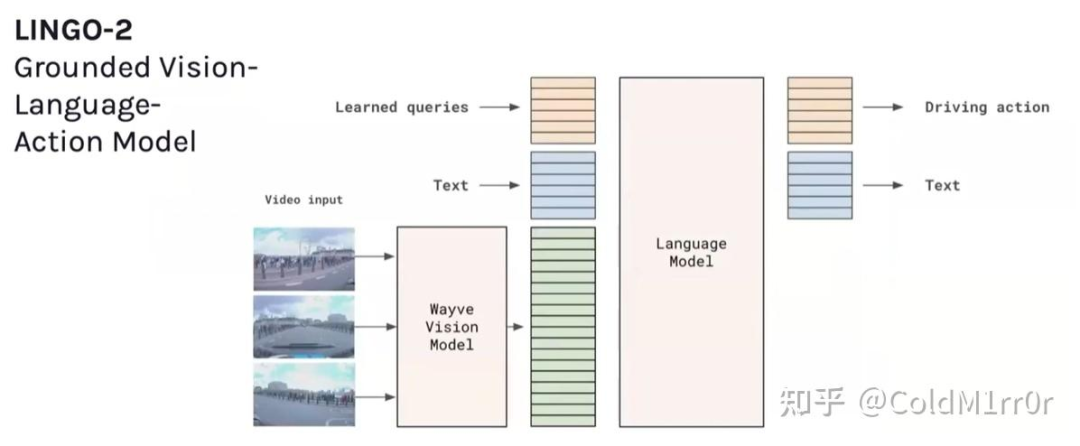
这里的解释行为也比较重要,这里根据不同场景改变了驾驶计划。

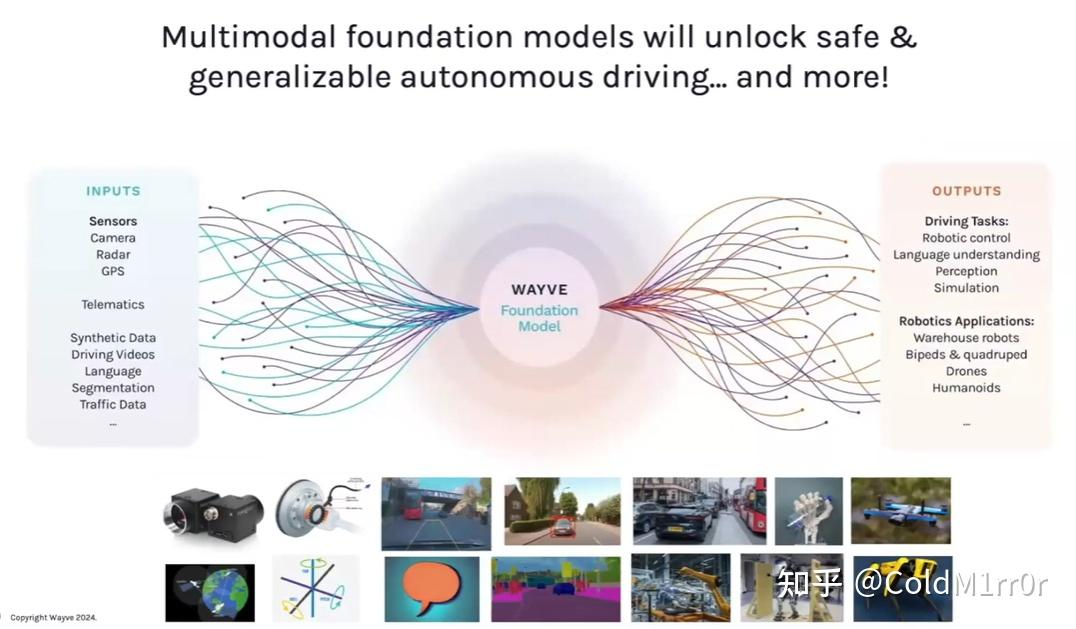
Foundation Models
A Model that is trained on a diverse set of data that can be adaped to a wide range of downstream tasks.
一些挑战

『自动驾驶之心知识星球』欢迎加入交流!重磅,自动驾驶之心科研论文辅导来啦,申博、CCF系列、SCI、EI、毕业论文、比赛辅导等多个方向,欢迎联系我们!

① 全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内外最大最专业,近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵


















 1550
1550

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









