



点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
编辑 | 自动驾驶之心
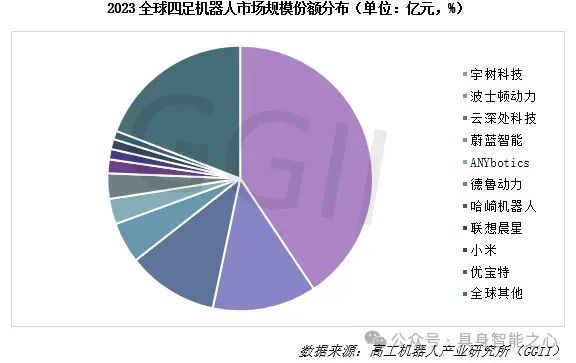
目前四足机器人的全球市场上,市场份额最大的是哪个国家的企业?A.美国 B.中国 C.其他

波士顿动力四足机器人

🎉答案选B,是中国!各位具身人选对了么?
冷知识:中国的宇树科技以一己之力,已经占到全球四足机器人市场的销量份额约69%,已超过美国的波士顿动力!此外,而另一家以四足机器人见长的企业--云深处科技在四足机器人的全球市场上规模仅次于宇树机器人和波士顿动力,位列第三。
四足机器人,也常被称为四足机器人或四足行走机器人,是一种模仿动物四足行走方式的机器人。它们通常具有四个可移动的腿,能够在多种地形上行走,包括不平坦的地面、楼梯、斜坡等,能够执行复杂的动态动作,如跳跃、奔跑和快速转向。这使得它们在搜索救援、探索未知环境、以及在人类难以到达的地方执行任务时非常有用。同时,四足机器人也会搭载传感器和智能算法,能够实现一定程度的自主导航和决策。

宇树科技 Go2 四足机器人 图源:https://www.xiaohongshu.com/discovery/item/66e5cfbf00000000270071ca?source=webshare&xsec_token=ABhXNEtdRFD8RjMgqyf-_pu-0WhKu5XUccd64ANGQ_A1M=&xsec_source=pc_share
四足机器人日渐成熟的今天,仍有一些场景有待突破。来自清华大学交叉信息研究院赵行老师团队的新成果,一作是Shaoting Zhu。研究的内容很有趣:四足机器人如何越过微小障碍?文章信息如下:
Robust Robot Walker: Learning Agile Locomotion over Tiny Traps https://arxiv.org/html/2409.07409v2 Corresponding author. E-mail: zhaohang0124@gmail.com
人类和动物能在复杂环境中稳健行走,依靠本体感觉来避开各种障碍物,如绳子、杆子和地面坑洞。然而,这些挑战对机器人来说却极为困难。在现实场景中,看似微小的陷阱也会对机器人的移动性产生严重影响。如图2所示,许多这样的障碍物都很小或位于机器人下方或后方,使得它们很难被深度摄像头等外部传感设备探测到。窄条或杆子之类的小物体在深度图像中往往会产生不可靠的数据,表现为间歇性的噪声或零距离处的密集区域,使其与其他障碍物的边缘噪声难以区分。
此外,由于真实RGB图像无法在模拟中准确呈现,因此在实际应用中会受到仿真到现实差距的限制。这引发了开发控制策略的需求,使机器人能够不依赖额外的传感设备就能克服此类陷阱型障碍物。

为了解决使用本体感觉在微小陷阱上学习敏捷运动的挑战,文章提出了一种具有几个关键贡献的新颖解决方案。
首先,文章引入了一个完全依赖于本体感觉的两阶段训练框架,可以在模拟和真实世界环境中成功通过微小的陷阱。
其次,文章开发了一种显式-隐式双态估计范式,利用接触编码器来估计不同机器人链接上的接触力,并利用分类头来增强接触表示的学习。
第三,文章将任务重新定义为目标跟踪,而不是速度跟踪,并纳入了精心设计的密集奖励函数和假目标命令。这种方法无需在现实世界中使用动作捕捉或其他定位技术即可实现近似的全向运动,显著提高了训练的稳定性和跨环境的适应性。
最后,文章为微小的陷阱任务引入了一个新的基准,并在模拟和真实场景中进行了广泛的实验,证明了文章方法的稳健性和有效性。
任务定义
该任务被定义为穿过一系列微小的陷阱,机载摄像头通常无法检测到此类陷阱。这些陷阱主要分为三种类型:横杆、坑洞和立杆,如图4所示。横杆是指位于四足机器人头部高度以下的平面上的水平细杆。坑洞是两个平面之间的小凹陷,可能导致机器人腿部打滑,并且从正常的前视图看不到。立杆是直立在平面上的细杆。在遇到这些陷阱时,机器人会接收到恒定的控制命令,并必须自主调整速度以通过它们。

奖励函数
该奖励函数由三个主要部分组成:任务奖励(Task Reward)、正则化奖励(Regularization Reward)和风格奖励(Style Reward)。总奖励是三项之和。
任务奖励:包括目标奖励(鼓励机器人朝向目标移动,随机器人当前位置与目标位置之间的距离减小而增大)、朝向奖励(确保机器人在接近目标时能够正确地对准目标方向,目的是确保机器人在水平或向后方向上遇到陷阱时,以直线或小角度偏移通过陷阱)、完成奖励(当机器人接近目标时,鼓励机器人保持静止)。
正则化奖励:用于优化机器人的性能,防止训练过程中出现的各种问题(如抖动、不稳定等),包括惩罚不必要的停止、速度限制、保持平衡等。
风格奖励:使用对抗性运动先验 (AMP) 风格的奖励,旨在使机器人的运动更加自然和高效。
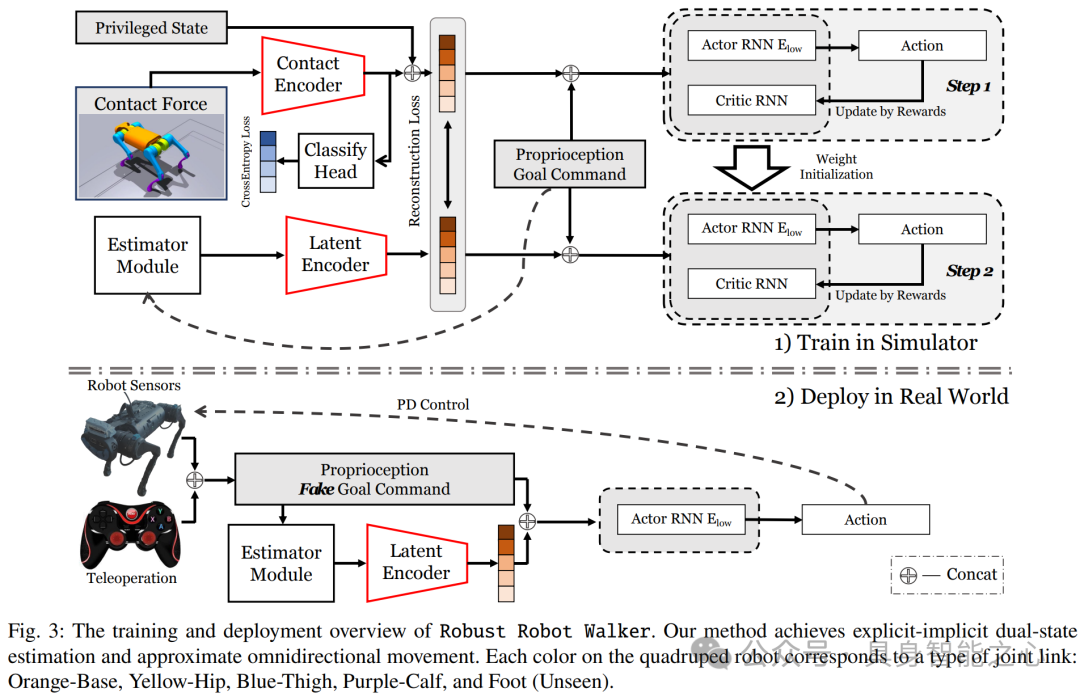
如何训练和部署
训练:采用了两阶段概率退火选择 (PAS) 框架,而不是传统的师生模仿学习方法。第一阶段学习并优化在完全信息下的控制策略,第二阶段使策略适应在部分信息下的工作情况,并减少因信息缺失导致的性能下降。
第一阶段使用显式-隐式双态学习机制,通过接触编码器将接触力编码为隐式潜变量,并与显式特权状态一起构成双态。引入分类头来指导策略学习接触力分布与陷阱类别之间的联系,这有助于策略理解不同陷阱的特性。目标是训练一个高性能的“Oracle”策略,该策略在完全信息下能够有效处理各种陷阱。
第二阶段通过概率退火选择(PAS)机制,逐步减少策略对特权状态信息的依赖,同时保持策略性能。
部署:
生成假目标命令:通过遥操作生成假的目标命令,包括恒定的 ΔG 和 Δt 值。这些命令用于指导机器人在环境中的运动方向。
使用估计器和低层Actor RNN:利用在第一阶段和第二阶段训练好的估计器模块和低层Actor RNN,结合来自机器人传感器的proprioception信息,预测双态并生成控制动作。
实现近似全向移动:由于精心设计的任务奖励函数及其比例,策略学会了基于距离到目标的不同移动策略(如大距离时先原地旋转面向目标,中等距离时同时转向和前进,小距离时直接移动)。这种能力使得机器人能够在没有运动捕捉或其他辅助定位技术的情况下,实现近似全向移动。
执行任务:机器人开始从左侧出发,通过小型陷阱(如Bar、Pit、Pole),最终到达右侧的目标位置,完成任务。
让四足机器人跨越小型陷阱的实验开展
模拟实验
文章首先进行了一个模拟实验,设计了一个 Tiny Trap Benchmark:有一个 5m ×60m 的跑道,三种类型的陷阱沿路径均匀分布。陷阱包括 10 个高度从 0.05 米到 0.2 米不等的杆子、50 个随机放置的杆子和 10 个宽度从 0.05 米到 0.2 米不等的坑。对于每个实验,都会部署 1000 个机器人,从跑道左侧开始,穿过所有陷阱到达右侧。文章将其称为 “Mix” 基准测试(包括 “Bar”、“Pit” 和 “Pole” 三种陷阱)。此外,还有单独的 “Bar”、“Pit” 和 “Pole” 基准测试,每个基准测试都专注于一种特定类型的 Trap,但 Trap 的数量增加了三倍。


该基准测试使用三个指标:Success Rate(成功率)、Average Pass Time(平均通过时间)和 Average Travel Distance(平均行驶距离)。如果机器人在 300 秒内到达目标点的 0.2m 范围内,则认为机器人成功,此时文章记录其通过时间。故障情况包括从跑道上掉下来、卡住或翻车。对于失败的情况,通过时间设置为最长 300 秒。然后,文章计算总体成功率和平均通过时间。在评估结束时,文章平均所有机器人的横向移动距离。在评估过程中,文章使用与实际部署中相同的假目标命令来指导机器人保持在中心。
各种训练方法如下:
• Ours(w/o goal command):使用传统的速度指令,但仅训练向陷阱前进的动作。
• Ours w/ Boolean:不使用编码器,直接将布尔值的碰撞状态输入到低级RNN中。其他设置与我们的方法相同。
其余为参考文献中的其他方法:
• RMA:在师生训练框架中,一维卷积神经网络(1D-CNN)作为异步适应模块。
• MoB:“学习一种单一策略,该策略编码一系列结构化的运动策略,以不同的方式解决训练任务。”
• HIMLoco:“HIM仅通过对比学习明确估计速度,并隐式地将系统响应模拟为隐式潜在嵌入。
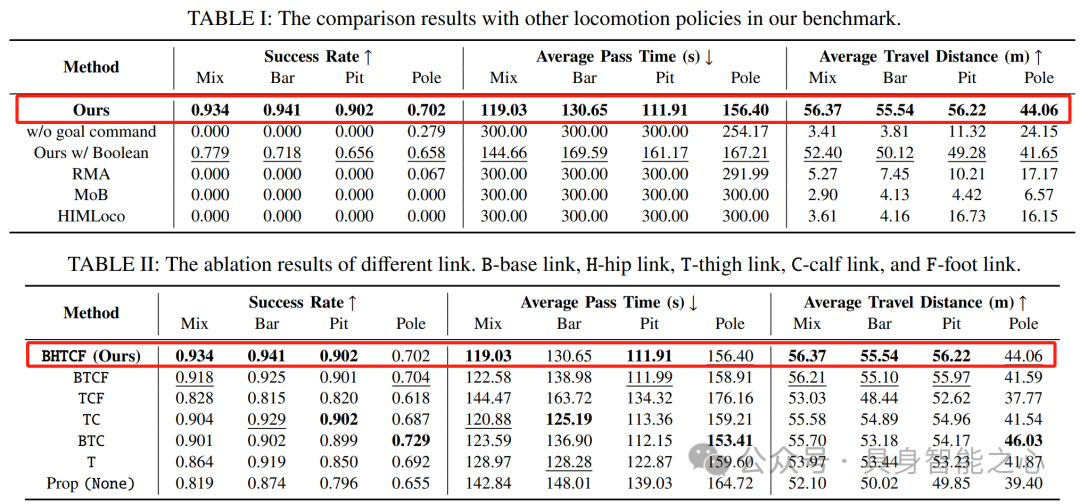
如表1所示,文章的方法在所有指标上都优于其他方法。如表2所示,在消融实验中,利用所有关节链接的策略在 “Mix” 上表现最好,在其他基准测试中表现相对较好。这证明了每个关节的接触力有助于提高策略性能。
真实实验
可视化结果如图 7 所示。1) 杠铃:机器人在接触杠铃后学会了前腿后退。即使后腿被故意困住,机器人仍然可以检测到碰撞并将其后腿抬过横杆。2) 坑:当一条腿踏入虚空时,机器人学会用其他三条腿支撑自己的身体,将悬空的腿抬出坑。此外,机器人还学会了在多条腿卡在坑中时用力踢腿爬出。3) 杆:机器人在与杆子碰撞后学会向左或向右回避,避开杆子一定距离后再向前移动。

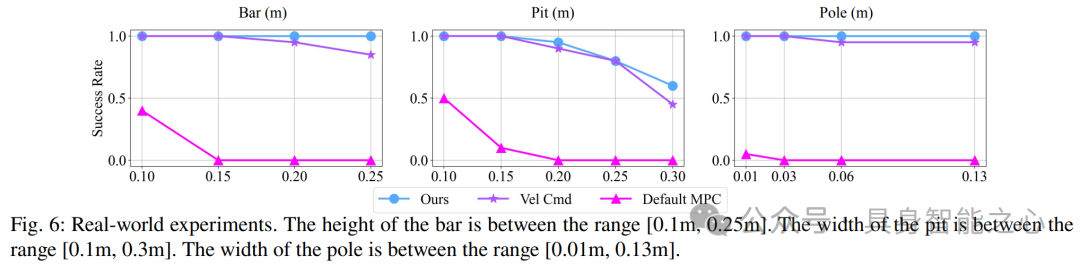
对于每项测试,重复进行 20 次试验并计算成功率。图6显示了成功率随着各种尺度的陷阱的变化。与其他基线相比,文章的方法获得了最佳性能。使用 velocity 命令的方法也很好。这是因为在训练中只采用前向速度命令,而不是传统的全向速度,这大大提高了性能。
我们还表明,当布尔值碰撞状态直接被发送到低级Actor RNN时(Ours w/ Boolean),机器人在部署时会面临严重的模拟到现实的差距(sim-to-real gap),如摩擦和电机阻尼。当差距出现时,潜在空间将产生一些噪声。布尔值状态的潜在空间非常稀疏,如图11所示,这将导致策略更容易误判当前状态并操作不规则。如图9所示,当机器人在平面上向前移动并突然停止一小段时间时,差距出现,估计的碰撞状态上升到较大值。如果我们此时让机器人后退,机器人会认为它撞到了陷阱。由于实际上没有陷阱,机器人可能会碰到地面甚至摔倒。在引入接触力和接触编码器后,模拟到现实的差距得到缓解。机器人可以更好地识别陷阱并更稳定地操作。

其他实验
此外,作者还做了其他模拟实验,证明了作者提出的方法在不同方面的有效性,包括假目标命令对性能的影响、不同运动模式的生成、策略对障碍的识别和响应能力,以及状态空间中不同输入的重要性。
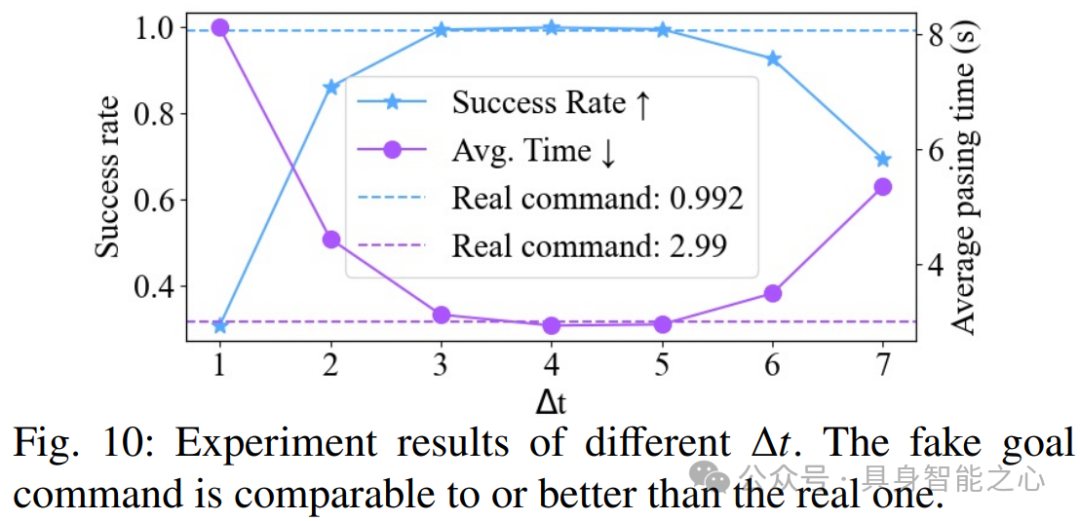
(1) 不同Δt(完成任务所需的剩余时间)的假目标命令对性能的影响:实验测试了通过一个0.2米高的障碍时,恒定的Δt在[3,5]范围内可以获得最佳性能。过大或过小的Δt值会降低性能,可能是由于在中间范围内的样本较少。
(2) 不同ΔG(ΔG=(Δx,Δy,Δz)=(dis⋅cosθ,dis⋅sinθ,0),目标位置相对于当前位置的距离)的假目标命令如何导致不同的运动模式:θ为表示目标位置相对于当前位置的方位的角度。

(3) 使用t-SNE方法可视化了通过每个障碍时估计的双状态。如图11,结果显示,作者发现使用分类头和接触力的方法能够在可视化中清晰地区分不同类型的陷阱和接触状态(不同颜色的点区分为不同区域),具有更可分和连续的编码,这表明了该方法能够有效地编码和区分不同的环境特征。

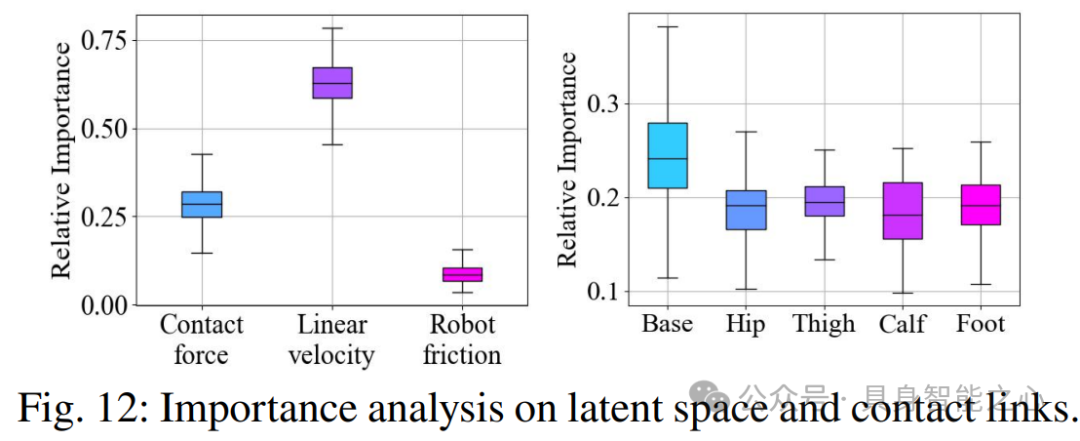
(4) 通过计算雅可比矩阵并归一化结果,分析了状态空间中每个输入的重要性。结果显示,接触力估计和每个关节链接的重要性被突出显示,其中基座链接最为关键,而其他链接显示出相似的重要性。这些结果强调了接触力估计的关键作用以及每个关节链接的重要性。
可以看到,文章通过将机器人链接上的接触力引入模型架构,并将学习任务定义为目标跟踪,已经很大程度上使机器人跨越微小陷阱时行动更为稳健。目前对于四组机器人,开发能够适应各种复杂地形和动态环境的高效运动控制算法、处理机器人的多体动力学和平衡问题仍然是一个挑战。此外,提高机器人的感知、认知和自主决策能力、在复杂环境中进行更精确的自主导航和避障、提高能源效率、以及改善人机交互也是四足机器人的未来发展方向。
『自动驾驶之心知识星球』欢迎加入交流!重磅,自动驾驶之心科研论文辅导来啦,申博、CCF系列、SCI、EI、毕业论文、比赛辅导等多个方向,欢迎联系我们!

① 全网独家视频课程
端到端自动驾驶、仿真测试、自动驾驶C++、BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、CUDA与TensorRT模型部署、大模型与自动驾驶、NeRF、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内外最大最专业,近4000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(端到端自动驾驶、世界模型、仿真闭环、2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









