



作者 | Fangzh 编辑 | 自动驾驶之心
原文链接:https://zhuanlan.zhihu.com/p/700072002
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
前言
目前的自动驾驶感知算法的输入数据会涉及到诸多采集传感器,比如激光雷达传感器、环视相机传感器以及毫米波雷达传感器等等。
相比于图像数据信息而言,由于激光雷达传感器采集到的点云数据可以更加准确的表示物体的深度和几何结构信息而被广泛应用于当前的智驾感知技术方案当中。并且在学术界也已经涌现出了很多基于BEV空间的3D点云感知算法。
对于当前绝大多数的基于BEV空间的3D感知算法而言,无论是基于单模态的纯视觉输入或者是纯点云输入,又或者是基于多模态的BEV空间3D感知算法,其整体思路均是将传感器采集的原始数据利用主干网络进行特征提取,并将提取到的特征转换到BEV空间下完成BEV特征的构建过程,得到的BEV特征用于后续的不同感知子任务(比如3D障碍物检测、基于BEV空间的语义分割等等)。
本文重点介绍点云3D目标检测任务中的两大基础主干网络:Voxel-Based和Pillar-Based两类主干网络
下面先整体说一下两类主干网络分别是如何处理点云,并得到最终BEV空间特征的整体处理步骤。
【1】Voxel-Based点云提取主干网络
.1 对激光雷达点云进行体素化的处理;
2. 进行体素特征编码(Voxel Feature Encoding,VFE);
3. 利用3D的卷积主干网络(VoxelResBackBone8x)对体素特征编码后的特征进行3D特征提取;
4. 将3D卷积主干网络提取后的特征投影到BEV空间中得到BEV特征;
5. 利用2D的卷积主干网络(ResNet系列等)对BEV特征完成进一步的特征提取;
【2】Pillar-Based点云提取主干网络
对激光雷达点云进行体素化的处理;
进行体素特征编码(Voxel Feature Encoding,VFE);
将体素特征编码后的结果直接投影到BEV空间下得到BEV特征(与Voxel-Based的方法不同,不再使用3D卷积主干网络进行点云特征提取);
利用2D的卷积主干网络(ResNet系列等)对BEV特征完成进一步的特征提取;
通过上述流程可以看出,Voxel-Based和Pillar-Based的点云特征提取方法主要不同点在于是否存在3D卷积提取的过程,Pillar-Based的方法由于不使用3D卷积,具有更快的推理速度,同时方便部署,是目前工业界主流的点云提取主干网络。
接下来,本文将详细介绍每种点云提取主干网络的细节部分~
Voxel-Based点云提取主干网络
该方法最早是在VoxelNet论文中被提出用于提取点云特征,其整体思路是将激光雷达采集到的点云数据转换成3D体素的形式,然后利用3D卷积主干网络进行特征提取,最终得到BEV空间特征,其整体网络结构如下图所示。
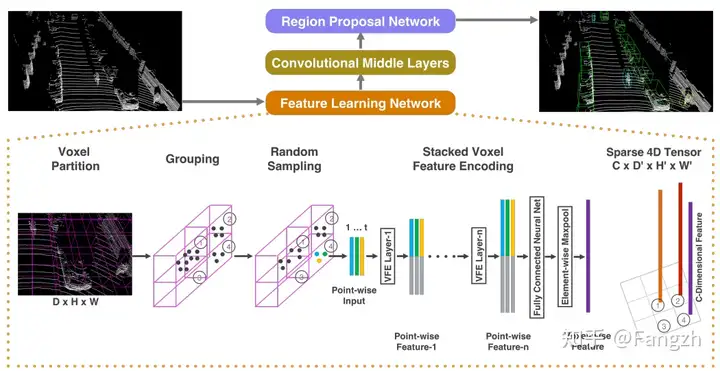
(1)点云数据体素化
点云数据体素化的主要作用就是将输入的点云数据分别划分到设定好的体素网格中,方便进行点云特征提取。具体而言,点云体素化模块的输入是一个张量Tensor([N, 4]),N代表输入点云的个数,4代表点云的3D坐标以及反射强度信息。
在具体处理的过程中需要人为设定当前算法模型的感知范围、每个体素所代表的实际空间大小,这样就可以知道每个体素网格中有多少点云,便于后续进行特征提取了。
点云体素化模块的输出有三项,分别如下
voxels:Tensor([M, max_num_points, 4]),其中M是根据当前点云中包含的所有点计算得到的体素个数,这里的4依旧代表点云的3D坐标以及反射强度;
voxels_coord:Tensor([M, 3]),代表每个体素在体素坐标系下的位置坐标;主要在后续3D卷积的过程中使用;
voxel_num_points:Tensor([M]);代表每个体素内有多少实际有效的点;主要在后续体素特征编码(Voxel Feature Encode,VFE)过程中使用;
(2)体素特征编码
Voxel-Based的体素特征编码主要包含两个部分,如下所示
需要注意的是:这部分输出的Tensor[M, 4])中的4就已经不是xyzr的物理含义了,已经是经过编码后的特征了。
先将每个体素内所有点的值进行求和:Tensor([M, max_points_in_voxel, 4]) → Tensor([M, 4]);
利用每个体素内包含的点云个数对上一步求和后的特征进行归一化;Tensor([M, 4]) / voxel_num_points;
整体的代码实现如下:
class MeanVFE(VFETemplate):
def __init__(self, model_cfg, num_point_features, **kwargs):
super().__init__(model_cfg=model_cfg)
self.num_point_features = num_point_features
def get_output_feature_dim(self):
return self.num_point_features
def forward(self, batch_dict, **kwargs):
"""
Args:
batch_dict:
voxels: (num_voxels, max_points_per_voxel, C)
voxel_num_points: optional (num_voxels)
**kwargs:
Returns:
vfe_features: (num_voxels, C)
"""
voxel_features, voxel_num_points = batch_dict['voxels'], batch_dict['voxel_num_points']
points_mean = voxel_features[:, :, :].sum(dim=1, keepdim=False)
normalizer = torch.clamp_min(voxel_num_points.view(-1, 1), min=1.0).type_as(voxel_features)
points_mean = points_mean / normalizer
batch_dict['voxel_features'] = points_mean.contiguous() # points_mean(12000, 5)
return batch_dict(3)利用3D卷积主干网络进行特征提取
这里采用的是VoxelResBackBone8x(3D Backbone主干网络 —— 8x代表下采样8倍)。具体而言,VoxelResBackBone8x主干网络共采用了两种稀疏卷积形式。
一种是spconv.SparseConv3d(regular output definition),就像普通的卷积一样,只要 kernel 覆盖一个 active input site,就可以计算出 output site,主要用于降采样操作;
另外一种是spconv.SubMConv3d(submanifold output definition),只有当 kernel 的中心覆盖一个 active input site 时,卷积输出才会被计算,主要用于提取点云的特征信息;
其中输入体素不为0的地方称为 active input site;
接下来是VoxelResBackBone8x主干网络的前向过程
def forward(self, voxel_features, voxel_coords, batch_size):
input_sp_tensor = spconv.SparseConvTensor(
features=voxel_features,
indices=voxel_coords.int(),
spatial_shape=self.sparse_shape, #
batch_size=batch_size,
) # 在进行3D卷积前,先进行稀疏化
# SubMConv3d提取特征
# 1) features.shape: Tensor([M = 102604, 16]) --> Tensor([M = 102604, 16])
# 2) spatial_shape: Tensor([grid_z + 1 = 41, grid_x = 1504, grid_y = 448]) -->
# Tensor([grid_z + 1, grid_x, grid_y])
x = self.conv_input(input_sp_tensor)
# SubMConv3d提取特征
# 1) features.shape: Tensor([M = 102604, 16]) --> Tensor([M = 102604, 16])
# 2) spatial_shape: Tensor([grid_z + 1 = 41, grid_x = 448, grid_y = 1504]) -->
# Tensor([grid_z + 1 = 41, grid_x = 448, grid_y = 1504])
x_conv1 = self.conv1(x)
# SubMConv3d提取特征 + SparseConv3d降采样
# 1) features.shape: Tensor([M = 102604, 16] --> Tensor([M = 72218, 32])
# 2) spatial_shape: Tensor([grid_z + 1 = 41, grid_x = 448, grid_y = 1504]) -->
# Tensor([grid_z + 1 = 21, grid_x = 224, grid_y = 752])
x_conv2 = self.conv2(x_conv1)
# SubMConv3d提取特征 + SparseConv3d降采样
# 1) features.shape: Tensor([M = 72218, 32] --> Tensor([M = 26536, 64])
# 2) spatial_shape: Tensor([grid_z + 1 = 21, grid_x = 224, grid_y = 752]) -->
# Tensor([grid_z + 1 = 11, grid_x = 112, grid_y = 376])
x_conv3 = self.conv3(x_conv2)
# SubMConv3d提取特征 + SparseConv3d降采样
# 1) features.shape: Tensor([M = 26536, 64] --> Tensor([M = 8198, 128])
# 2) spatial_shape: Tensor([grid_z + 1 = 11, grid_x = 112, grid_y = 376]) -->
# Tensor([grid_z + 1 = 5, grid_x = 56, grid_y = 188])
x_conv4 = self.conv4(x_conv3)
# SparseConv3d降采样
# 1) features.shape: Tensor([M = 8198, 128] --> Tensor([M = 6534, 128])
# 2) spatial_shape: Tensor([grid_z + 1 = 5, grid_x = 56, grid_y = 188]) -->
# Tensor([grid_z + 1 = 2, grid_x = 56, grid_y = 188])
out = self.conv_out(x_conv4)
encoded_spconv_tensor = out
encoded_spconv_tensor_stride = 8
multi_scale_3d_features = {
"x_conv1": x_conv1,
"x_conv2": x_conv2,
"x_conv3": x_conv3,
"x_conv4": x_conv4,
}
return encoded_spconv_tensor, encoded_spconv_tensor_stride, multi_scale_3d_features(4)3D特征投影到BEV空间
这一步骤的主要目的就是将3D卷积主干网络提取到的3D特征投影到BEV空间得到BEV特征。
def forward(self, encoded_spconv_tensor, encoded_spconv_tensor_stride):
# Tensor([bs, C=128, grid_z=2, grid_x = 56, grid_y = 188])
spatial_features = encoded_spconv_tensor.dense()
N, C, D, H, W = spatial_features.shape
# 通过特征.view()的方式将BEV特征的Z轴拍平
spatial_features = spatial_features.view(N, C * D, H, W) # Tensor([bs, 256, 56, 188])
# 最终的BEV特征 Tensor([bs, 256, 56, 188])
return spatial_features, encoded_spconv_tensor_stride(5)2D主干网络进行BEV特征的进一步提取
这一部分的结构类似ResNet当中的结构,主要是对2D的BEV特征进行进一步的特征提取,其实现代码如下
class BaseBEVBackbone(nn.Module):
def __init__(self, model_cfg, input_channels):
super().__init__()
def forward(self, data_dict):
"""
Args:
data_dict:
spatial_features : (batch, c, W, H)
Returns:
"""
spatial_features = data_dict['spatial_features']
ups = []
ret_dict = {}
x = spatial_features
for i in range(len(self.blocks)):
x = self.blocks[i](x)
stride = int(spatial_features.shape[2] / x.shape[2])
ret_dict['spatial_features_%dx' % stride] = x
if len(self.deblocks) > 0:
ups.append(self.deblocks[i](x))
else:
ups.append(x)
if len(ups) > 1:
x = torch.cat(ups, dim=1)
elif len(ups) == 1:
x = ups[0]
if len(self.deblocks) > len(self.blocks):
x = self.deblocks[-1](x)
data_dict['spatial_features_2d'] = x
return data_dictPillar-Based的点云提取主干网络
该方法最早在PointPillars论文中被提出用于提取点云特征,与VoxelNet算法模型处理点云方式不同,PillarNet在点云数据处理的过程中直接将点云数据处理为BEV特征,取消掉了3D卷积主干网络的特征提取过程,推理速度更快,更方便上车部署,其整体网络结构如下图所示。
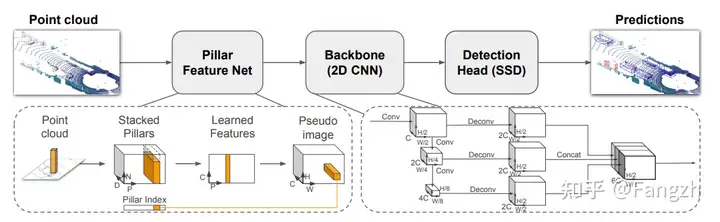
(1)点云数据体素化
该过程与Voxel-Based的方法是相同的,这里就不展开介绍了
(2)体素特征编码
由于Pillar-Based的方法不再使用3D的卷积主干网络对体素化后的点云进行3D特征提取,所以这部分的体素特征编码相对复杂一些。主要包括两部分:点云增强以及点云特征提取。
点云增强部分
原始的激光雷达点云是4维的数据格式(3D坐标以及反射强度),作者对点云数据进行了增强,将其表示为9个维度(x,y,z,r,xc,yc,zc,xp,yp)。其中,xc,yc,zc分别代表划分的Pillar中激光雷达点云相对N个点云中心的偏移量,xp和yp分别表示激光雷达点云相对Pillar坐标的偏移量,r代表反射强度。
点云特征提取部分
这里主要采用了一个全连接网络实现体素特征的编码过程
(3)体素特征投影到BEV空间形成BEV特征
这里的操作主要就根据步骤一中的点云数据体素化后得到的坐标coord以及步骤二体素特征编码后的特征进行按位置填充,从而直接得到BEV空间下的BEV特征。
(4)2D主干网络进行BEV特征的进一步提取
该部分的实现过程与Voxel-Based的实现思路基本一样,这里就不展开介绍了。
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、BEV模型部署、BEV目标跟踪、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】全平台矩阵


















 1018
1018

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









