



作者 | yoccoy 编辑 | 汽车人
原文链接:https://zhuanlan.zhihu.com/p/690880124
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
Introduction
Hello World
GPU编程涉及到多个设备(CPU,GPU,内存,显存),因此首先明确概念
Host:CPU + 内存
Device:GPU + 显存
A "hello world" example
__global__ void kernel(void) {
}
int main(){
kernel<<<1, 1>>>();
printf("Hello world\n");
return 0;
}和普通C程序的区别
函数
kernel返回值之前的__global__前缀,告诉编译器,这个函数到时候会跑在GPU上函数调用时的
<<<1, 1>>>,在CPU上调用GPU实现的函数,1,1是因为可能会调用若干个GPU”核心“ 同时跑这个函数
"hello world" 例子里,GPU实现的函数并没有接收任何参数,也没有具体的返回值。实际有意义的函数,通常会有输入和输出。看下边这个例子
__global__ void add(int a, int b, int *c){
*c = a + b;
}
int main() {
int c;
int *dev_c;
cudaMalloc((void**)&dev_c, sizeof(int));
add<<<1, 1>>>(2, 7, dev_c);
cudaMemcpy(&c, dev_c, sizeof(int), cudaMemcpyDeviceToHost);
printf("2+7=%d\n", c);
cudaFree(dev_c);
return 0;
}这个示例做的事情很简单,在GPU计算两个整数之和。但是涉及到了一些新的东西
cudaMalloc,在GPU上做实际计算之前,需要先为相关变量分配好显存。和通常的malloc直接返回分配好的内存地址不同,cuda 函数的返回值往往表示执行成功与否。因此实际分配的显存的地址,需要通过传入的参数取到。 由于 C 语言函数调用默认是 by-value,因此为了得到一个int*这样的返回值,实际传入的是指向int*的指针,即int**,然后类似malloc里,分配的内存是没有类型信息的,因此需要转成void **,第二个参数sizeof(int),是说分配的显存大小。最终,执行后,dev_c指向一个位于显存里的地址。add<<<1, 1>>>(2,7,dev_c),这个是调用 GPU 上执行的函数,*c = a + b,将a+b结果写入上一步分配好的显存里cudaMemory,负责 host 和 device 之间的数据拷贝(包括 host2host, device2device)&c:targetdev_c: sourcesizeof(int),拷贝的数据量cudaMemcpyDeviceToHost,方向,这个将 device 数据拷贝到 host,因此&c需要指向 host,dev_c需要指向 devicecudaFree(dev_c),释放之前分配的GPU上的显存
Query Device Information
先查询当前机器上GPU的数量
int count;
cudaGetDeviceCount(&count);然后查询每一个GPU的属性
cudaDeviceProp prop;
for (int i=0; i<count; i++){
cudaGetDeviceProperties(&prop, i);
}这里 cudaDeviceProp 是一个 C-struct,包含设备名,设备显存,单个block可以使用的共享显存,单个block里的寄存器,每个warp里的线程数等等。
当机器上有多个GPU设备时(例如既有集成显卡,又有独立显卡),有时某些操作对GPU有一些要求,比如需要版本号 >= 1.3(major version >1, or major version=1, minor version>3),Cuda提供了两个API用于快速找到当前几种满足要求的设备
cudaDeviceProp prop;
memset(&prop, 0, sizeof(udaDeviceProp));
prop.major = 1;
prop.minor = 3;
int dev;
cudaChooseDevice(&dev, &prop);
printf("ID of CUDA device closest to revision 1.3: %d\n", dev);
cudaSetDevice(dev);Parallel Programming in CUDA C
上一章只是简单介绍了 cuda 程序的大体结构,但是并没有涉及任何并行化。本章会正式介绍 cuda 中实现并行化计算的方式
Vector Addition Example
考虑向量相加的例子
#define N 10
int a[N], b[N], c[N];
// init a, b, memset c to zero
for (int i=0; i<N; i++){
c[i] = a[i] + b[i];
}GPU version
__global__ void add(int *a, int *b, int *c){
int tid = blockIdx.x;
if (tid < N){
c[tid] = a[tid] + b[tid];
}
}
int main()
// Suppose `int a[N], b[N], c[N]` are given
int *dev_a, *dev_b, *dev_c;
cudaMalloc((void**)&dev_a, N*sizeof(int)); cudaMemcpy(dev_a, a, N*sizeof(int), cudaMemcpyHostToDevice);
cudaMalloc((void**)&dev_b, N*sizeof(int)); cudaMemcpy(dev_b, b, N*sizeof(int), cudaMemcpyHostToDevice);
cudaMalloc((void**)&dev_c, N*sizeof(int));
add<<<N, 1>>>(dev_a, dev_b, dev_c);
cudaMemcpy(c, dev_c, N*sizeof(int), cudaMemcpyDeviceToHost);
for (int i=0; i<N; i++) {
printf("%d\n", c[i]);
}
cudaFree(dev_a); cudaFree(dev_b); cudaFree(dev_c);
return 0;
}和之前例子不同的地方
调用GPU上实现的函数时,尖括号里第一个参数是
N,即add<<<N, 1>>>(...),这里第一个参数N表示并行的 ”block“ 数量add函数实现内部,int tid = blockIdx.x, 这里blockIdx是一个cuda内部的变量,blockIdx.x表明当前函数跑在第几个block上。.x 是因为 cuda允许你在多个维度上定义block的划分方式,这个在处理诸如图像,或者矩阵这样的数据结构是会更加的方便。
当调用GPU实现的这个函数时,我们指定了 N 个并行的block,我们将这些并行的block,称为 “grid” NOTICE:cuda函数返回值通常表示其是否执行失败(C里的错误码),因此在每个函数调用时,建议加上CHECK。这里为了简洁,先忽略这个。
Julia Set Example
向量相加这个例子还是比较简单。看下边这个 “Julia Set" 的例子 Julia Set是一类分形,通过每个像素自己的迭代,确定分形的边界。具体迭代规则如下=+C这里 表示某个位置的像素在第 和第 轮的迭代结果。 是一个常数。如果随着迭代 ,则认为这个位置的像素不再 Julia Set 里,否则认为在这个集合里。每个位置下的像素初始值设置为这个像素在图片中的位置(归一化到 ) 先看 CPU 下的实现
int main() {
CPUBitmap bitmap(DIM, DIM);
unsigned char *ptr = bitmap.get_ptr();
kernel(ptr);
bitmap.display_and_exit();
}
void kernel(unsigned char *ptr) {
for (int y=0; y<DIM; y++){
for(int x=0; x<DIM; x++){
int offset = x + y*DIM;
int juliaValue = julia(x, y); // 0 or 1
ptr[offset*4 + 0] = 255 * juliaValue;
ptr[offset*4 + 1] = ptr[offset*4 + 2] = 0;
ptr[offset*4 + 3] = 255;
}
}
}
int julia(int x, int y){
const float scale = 1.5;
float jx = scale * (float)(DIM/2 - x)/(DIM/2);
float jy = scale * (float)(DIM/2 - y)/(DIM/2);
cuComplex c(-0.8, -0.156); // cuComplex defines a complex number class
cuComplex a(jx, jy);
for(int i=0; i<200; i++) { // 迭代200次
a = a * a + c; // 迭代规则
if (a.magnitude2() > 1000) {
return 0;
}
}
return 1;
}接下来,我们看GPU下的实现
int main() {
CPUBitmap bitmap(DIM, DIM);
unsigned char *dev_bitmap;
cudaMalloc((void**)&dev_bitmap, bitmap.image_size());
dim3 grid(DIM, DIM);
kernel<<<grid, 1>>>(dev_bitmap);
cudaMemcpy(bitmap.get_ptr(), dev_bitmap, bitmap.image_size(), cudaMemcpyDeviceToHost);
bitmap.display_and_exit();
cudaFree(dev_bitmap);
}整个过程和CPU下的区别在于
cudaMalloc在GPU上分配和bitmap大小相同的显存调用 kernel 函数时,在block数量的设置上,和之前直接用
N不同, 是dim3 grid(DIM, DIM)形式,这里dim3是 cuda 定义的多维元组(至多3维,没有被初始化的部分默认是 1),用于指定调用GPU函数时,GPU的block数,针对这种多维情形,接下来kernel函数的实现会处理这种多维grid情形cudaMemcpy将GPU上跑出结果拷贝回内存中。cudaFree释放GPU上分配的显存
我们看 kernel 函数的实现
__global__ void kernel(unsigned char *ptr) {
int x = blockIdx.x;
int y = blockIdx.y;
int offset = x + y * gridDim.x;
int juliaValue = julia(x, y);
ptr[offset*4 + 0] = 255 * juliaValue;
ptr[offset*4 + 1] = ptr[offset*4 + 2] = 0;
ptr[offset*4 + 3] = 255;
}注意点
__global__说明,这个函数跑在 GPU 上,但是可以被 host(即CPU)调用blockIdx.x, blockIdx.y表明当前执行这个函数的 block 的 index =(x, y),其中x,y范围都是 [0, DIM-1]gridDim这个是所有 block 共享的常量,里边存放的是调用kernel函数时的grid配置(即dim3 grid(DIM, DIM)),因此这里gridDim.x = DIM, gridDim.y = DIM,根据这个grid配置,以及x,y,可以计算出对应的一维情形下的偏移,即offset = x + y*gridDim.x这个
kernel函数内调用了julia函数,由于调用方也是GPU函数,因此 julia 函数定义如下
__device__ int julia(int x, int y) {
const float scale = 1.5;
float jx = scale * (float)(DIM/2 - x)/(DIM/2);
float jy = scale * (float)(DIM/2 - x)/(DIM/2);
cuComplex c(-0.8, 0.156);
cuComplex a(jx, jy);
for (int i=0; i<200; i++) {
a = a * a + c;
if (a.magnitude2() > 1000){
return 0;
}
}
return 1;
}注意点
__device__表明,这个函数只能被另外一个跑在GPU上的函数调用(即被其他__global__或者__device__函数调用)cuComplex类型内的方法(operator*,operator+,magnitude2需要有GPU下的实现)
struct cuComplex {
float r, i;
cuComplex(float a, float b): r(a), i(b) {}
__device__ float magnitude2(void) { return r*r + i*i; }
__device__ cuComplex operator* (const cuComplex& a) { return cuComplex(r*a.r-i*a.i, i*a.r+r*a.i); }
__device__ cuComplex operator+ (const cuComplex& a) { return cuComplex(r+a.r, i+a.i); }
}Thread Cooperation
上一章介绍了block间的并行,即将一个大的任务分解到若干个block上执行,但block之间,是没有考虑任何通信的。本章介绍另外一种并行方式,称为 threads。和 block 的区别在于,threads 之间是可以通信的。
Splitting Parallel Blocks
在 block 的基础上,对于每个 block,cuda 还允许其包含若干 "threads",其实就是 <<<N, M>>> 里的第二个参数(之前都是 1,即之前默认1个block里只有1个thread),从而之前 N blocks * 1 thread/block = N parallel threads,事实上,我们也完全可以启动 N/2 个block,然后每个block内包含两个threads,或者 N/4 个block,然后每个block内包含 4 个threads
threads 的好处在于,同一个block内的threads可以共享存储,从而方便通信。但我们先忽略这个事情,先看基于threads 的并行(或者block + threads的并行)如何实现。
类似 blockIdx 这个特殊变量,threads 也有一个 threadIdx,使用起来几乎和 blockIdx 完全一致,标志当前这个函数跑在哪个 thread 下。
__global__ void add(int *a, int *b, int *c) {
int tid = threadIdx.x;
if (tid < N) {
c[tid] = a[tid] + b[tid];
}
}
int main() {
int a[N], b[N], c[N];
// init a[N], b[N], memset c[N]
int *dev_a, *dev_b, *dev_c;
cudaMalloc((void**)&dev_a, N*sizeof(int)); cudaMemcpy(dev_a, a, N*sizeof(int), cudaMemcpyHostToDevice);
cudaMalloc((void**)&dev_b, N*sizeof(int)); cudaMemcpy(dev_b, b, N*sizeof(int), cudaMemcpyHostToDevice);
cudaMalloc((void**)&dev_c, N*sizeof(int));
add<<<1, N>>>(dev_a, dev_b, dev_c);
cudaMemcpy(c, dev_c, N*sizeof(int), cudaMemcpyDeviceToHost);
// dispplay c
cudaFree(dev_a); cudaFree(dev_b); cudaFree(dev_c);
return 0;
}可以看到,整个过程和之前基于 block 的并行几乎完全一致
调用时,采用的是
add<<<1, N>>>的方式,即 block数 = 1, thread 数= Nadd函数内部,采用threadIdx.x拿到当前 thread 的下标。
Thread 并行的问题在于,单个block 能并行的thread数量是有限的(maxThreadsPerBlock),通常是 1024 这样。而 block 的数量通常要大的多(例如 )。
接下来,我们讨论如何同时使用 block 和 thread 来做并行。此时涉及到一个新的全局变量 blockDim,类似之前的 gridDim,blockDim 记录的是每个block内,有多少个 thread?
注意类似 gridDim,blockDim 类型也是 dim3,即它也有 x,y,z 成员。事实上,thread 在设置并行数时,也是可以指定多个维度的(上边的例子里只指定了1个维度,即只用了 threadIdx.x)。 当同时使用 block 和 thread 的并行(并且都只有1个维度时)
int tid = threadIdx.x + blockIdx.x * blockDim.x考虑到整除问题,这里有一个常见的trick。
举例,对于包含 个元素的向量加法,如果我们 thread 并行数 = 128,则 block 并行数 = (N+127)/128 即
add<<<(N+127)/128, 128>>>(dev_a, dev_b, dev_c)此时,block 数 * thread 数 是足够的,并且可能比 稍微大点(如果 ),所以,在 add 函数内做避免越界的处理是必须的
// 类似这样
if (tid < N) {
c[tid] = a[tid] + b[tid];
}block 数量虽然可以比 thread 数更多,但毕竟也是有限的。那么对于任意长的向量加法,该怎么并行呢?
通常的做法是这样的
__global__ void add(int *a, int *b, int *c) {
int tid = threadIdx.x + blockIdx.x + blockDim.x;
while (tid < N) {
c[tid] = a[tid] + b[tid];
tid += blockDim.x * gridDim.x; // 所有block下并行的thread总数
}
}
int main(){
// ...
add<<<blockNum, threadNum>>>(dev_a, dev_b, dev_c); // threadNum <= 1024
}接下来,通过下边这个生成波纹图片的例子,进一步熟悉基于 block + thread 的并行化。
先看一些基础代码
struct DataBlock{
unsigned char *dev_bitmap;
CPUAnimBitmap *bitmap;
};
void cleanup(DataBlock *d) {
cudaFree(d->dev_bitmap);
}
int main () {
DataBlock data;
CPUAnimBitmap bitmap(DIM, DIM, &data);
data.bitmap = &bitmap;
cudaMalloc((void**)&data.dev_bitmap, bitmap.image_size());
bitmap.anim_and_exit((void(*)(void*, int))generate_frame, (void(*)(void*))cleanup);
}然后看 generate_frame 的实现
void generate_frame(DataBlock *d, int ticks) {
dim3 blocks(DIM/16, DIM/16);
dim3 threads(16, 16);
kernel<<<blocks, threads>>>(d->dev_bitmap, ticks);
cudaMemcpy(d->bitmap->get_ptr(), d->dev_bitmap, d->bitmap->image_size(), cudaMemcpyDeviceToHost);
}注意点
由于现在处理的是图像,
blocks,threads都是两维,这样方便后边的处理对于 1920 x 1080 这样的图像,
blocks * threads,即总的threads数量大概是200万,我们发现GPU的并行程度往往会远远超过CPU
我们看 kernel 函数的实现
__global__ void kernel(unsigned char *ptr, int ticks) {
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
float fx = x-DIM/2, fy=y-DIM/2;
float d = sqrtf(fx*fx + fy*fy);
unsigned char grey = (unsigned char)(128.0f + 127.0f * cos(d/10.0f - ticks/7.0)/(d/10.0f + 1.0f));
ptr[offset*4+0] = ptr[offset*4+1] = ptr[offset*4+2] = grey;
ptr[offset*4+3] = 255;
}其中,最关键的是前3行
根据
threadIdx.x, blockIdx.x, blockDim.x得到对应 x,以及类似的得到对应 y根据
x, y得到一维情形下的偏移量offset
Shared Memory and Synchronization
引入 thread 并行的好处是,每个block内部,可以有一块该block下所有thread共享的存储空间。采用 __shared__ 关键字来标识。
启动某个运行在 GPU 上的函数(通常叫做 kernel)时,__shared__ 标识的变量会在每一个block内拷贝一份,然后在这个block内的各个threads之间共享。某个block下的thread不能读写其他block下的 __shared__ 区域 同一个block下,多个thread读写一个共享区域,显然会出现竞争问题,cuda提供了 __syncthreads() 方法来处理这个问题。
我们来看一个具体的例子,考虑向量内积的问题
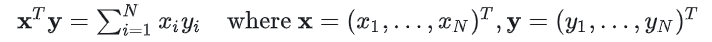
const int N = 33 * 1024;
const int threadsPerBlock = 256;
__global__ void dot(float *a, float *b, float *c) {
__shared__ float cache[threadsPerBlock]; // 每个block内共享这个变量,因此这个长度和block数量无关
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int cacheIndex = threadIdx.x;
float temp = 0;
while(tid < N){
temp += a[tid] * b[tid];
tid += blockDim.x * gridDim.x; // same as vector addition before
}
cache[cacheIndex] = temp;
// to be continued ...
}可以看到,逐项相乘这个过程和之前向量相加是基本一致的。区别在于 1. 引入了 __shared__ 变量,目的是逐项相乘后,汇聚这个block内的部分和。
为了汇聚block内的这个“部分和”,需要这个block内所有thread都完成了计算,这样 cache 中存的值才能准备接下来的 “reduction“,cuda 提供了这个同步函数,称为 __syncthreads(),需要先执行这个函数,确保同一个 block内的所有 threads 都完成了初始的计算,然后开始下一步汇聚部分和(称为”reduction“)
最简单的 reduction 的方式是,选择某一个thread,然后遍历 cache 这个数组,得到最终的加和。但这样的话,是一个和数组长度相关的线性的复杂度,并没有充分利用 cuda 提供的并行能力。事实上,针对这个问题,我们有 的方式。
大概思路就是,对于长度为 的序列,先 reduce 到 ,reduce 到 ,这样经过 次之后,就 reduce 到了最终长度为 的结果。 最后,为了将这个结果返回,这个只需要一个thread做这件事情即可。例如选择 cacheIndex = threadIdx.x = 0 这个thread
__global void dot(float *a, float *b, float *c) {
// continue from before, now we have variable: __shared__ cache[threadsPerBlock]
__syncthreads();
int i = blockDim.x/2; // threadsPerBlock *must* be a power of 2, here we set it to 256, so is OK
while (i!=0) {
if (cacheIndex < i) {
cache[cacheIndex] += cache[cacheIndex + i];
}
__syncthreads();
i /= 2;
}
// we need to return cache[0]
if (cacheIndex == 0) {
c[blockIdx.x] = cache[0]
}
}事实上,截止到这里,也只是完成了每个 block 内的部分和。
float c[] 里的每一项,对应着某个block内的部分和。通常这种reduction问题,越到后边,问题规模会越小。由于并行规模不够大,此时再在GPU上执行就不划算了,可以直接返回到CPU上,然后在CPU上完成最后的计算。
const int blocksperGrid = imin(32, (N+threadsPerBlock-1)/threadsPerBlock);
int main() {
float *a, *b, c, *partial_c;
float *dev_a, *dev_b, *dev_partial_c;
// allocate and init a,b, set partial_c to new float [blocksPerGrid]
cudaMalloc((void**)&dev_a, N*sizeof(float));
cudaMalloc((void**)&dev_b, N*sizeof(float));
cudaMalloc((void**)&dev_partial_c, N*sizeof(float));
cudaMemcpy(dev_a, a, N*sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, N*sizeof(float), cudaMemcpyHostToDevice);
dot<<<blocksPerGrid, threadsPerBlock>>>(dev_a, dev_b, dev_partial_c);
cudaMemcpy(partial_c, dev_partial_c, blocksPerGrid*sizeof(float), cudaMemcpyDeviceToHost);
// final reduction on CPU
c = 0;
for (int i=0; i<blocksPerGrid; i++) {
c += partial_c[i];
}
printf("dot production for a*b=%f\n", c);
cudaFree(dev_a); cudaFree(dev_b); cudaFree(dev_partial_c);
free(a); free(b); free(partial_c);
return 0;
}NOTICE:对于带分支判断的情形,__syncthreads() 需要放到分支之外,保证同步的顺利完成。否则部分线程,由于不会执行分支内的逻辑,导致 __syncthreads() 永远不会被走到,此时根据cuda的设计,所有线程就 hang 住了。
看下边这个bitmap的例子,main 函数部分和之前 Julia Set 类似,只不过在调用GPU函数时,每个block会启动若干个thread
#define DIM 1023
#define PI 3.14159265
int main() {
CPUBitmap bitmap(DIM, DIM);
unsigned char *dev_bitmap;
cudaMalloc((void**)&dev_bitmap, bitmap.image_size());
dim3 grids(DIM/16, DIM/16);
dim3 threads(16, 16);
kernel<<<grids, threads>>>(dev_bitmap);
cudaMemcpy(bitmap.get_ptr(), dev_bitmap, bitmap.image_size(), cudaMemcpyDeviceToHost);
bitmap.display_and_exit()
cudaFree(dev_bitmap);
return 0;
}除了调用GPU函数时,指定的block 数量 和每个block下的thread 数量,都是 dim3 类型,包含两个维度,其他和之前的例子没有区别
然后我们来看 kernel 函数的实现
__global__ void kernel(unsigned char *ptr) {
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
__shared__ float shared[16][16];
const float period = 128.0f;
shared[threadIdx.x][threadIdx.y] = 255 * (sinf(x*2.0f*PI/period) + 1.0f) * (sinf(y*2.0f*PI/period) + 1.0f) / 4.0f;
__syncthreads(); // 这个是必须的。因为后边读的是来自其他线程的计算结果。
ptr[offset*4+0] = 0;
ptr[offset*4+1] = shared[15-threadIdx.x][15-threadIdx.y];
ptr[offset*4+2] = 0;
ptr[offset*4+3] = 255;
}Constant Memory and Events
之前我们已经学会了
怎样让一段代码在GPU上跑,并从CPU上来调用它(
__global__关键字,以及__device__,注意它们的不同)以及<<<M,N>>>这种语法怎样基于cuda实现并行化(block并行,thead并行),注意一些cuda内置的重要的变量,包括
blockIdx, threadIdx, gridDim, blockDim等怎么在并行时,实现一定的”通信“ 和 ”同步“ (
__shared__,__syncthreads)
本周讨论 ”常量显存“(Constant Memory) 和 "cuda 事件"(cuda events),前者用于进一步提升GPU程序的性能,后者用于对 cuda程序的性能评估上,这样我们就能对不同写法的性能有一个量化评估方式。
Constant Memory
常量显存是cuda提供的一块特殊区域,通常64KB,在讨论这个概念之前,我们通过图形学里光线追踪的案例来引入这个概念。 先定义 Sphere ,表示一个球,包含中心(x,y,z),半径(radius),颜色(r,g,b)
#define INF 2e10f
struct Sphere {
float r,g,b;
float radius;
float x,y,z;
__device__ float hit(float ox, float oy, float *n) {
float dx = ox - x, dy = oy - y;
if (dx*dx + dy*dy < radius*radius) { // inside the sphere
float dz = sqrtf(radius*radius - dx*dx - dy*dy);
*n = dz /sqrtf(radius*radius);
return dz + z;
}
return -INF;
}
}这里,Sphere 定义了 hit 方法,大概就是说,给定位置(ox,oy),如果位于球的内部,计算其距离最近的球面。
我们看 main 函数的实现
#efine rnd(x) (x*rand() / RAND_MAX)
#define SPHERES 20
Sphere *s;
int main() {
cudaEvent_t start, stop;
cudaEventCreate(&start); cudaEventCreate(&stop);
cudaEventRecord(start, 0);
CPUBitmap bitmap(DIM, DIM);
unsigned char *dev_bitmap;
cudaMalloc((void**)&dev_bitmap, bitmap.image_size());
cudaMalloc((void**)&s, sizeof(Sphere)*SPHERES);
// create 20 spheres with random color, center and size
Sphere *temp_s = (Sphere*) malloc(sizeof(Sphere)*SPHERES);
for (int i=0; i<SHPERES; i++) {
temp_s[i].r = rnd(1.0f);
temp_s[i].g = rnd(1.0f);
temp_s[i].b = rnd(1.0f);
temp_s[i].x = rnd(1000.0f) - 500;
temp_s[i].y = rnd(1000.0f) - 500;
temp_s[i].z = rnd(1000.0f) - 500;
temp_s[i].radisu = rnd(100.0f) + 20;
}
// copy these spheres to GPU
cudaMemcpy(s, temp_s, sizeof(Sphere)*SPHERES, cudaMemcpyHostToDevice);
free(temp_s);
// render spheres on parallel
dim3 grid(DIM/16, DIM/16);
dim3 threads(16, 16);
kernel<<<grids, threads>>>(dev_bitmap);
// copy back and free resource
cudaMemcopy(bitmap.get_ptr(), dev_bitmap, bitmap.image_size, cudaMemcpyDeviceToHost);
bitmap.display_and_exit();
cudaFree(dev_bitmap); cudaFree(s);
return 0;
}main 函数没什么好说的,随机生成20个颜色不同,中心不同,半径不同的球,然后将生成的球拷贝到显存里。
在GPU上并行跑 kernel 函数(一个类似渲染的过程),最后将结果拷贝回内存并显示结果。
我们来看 kernel 函数的实现
__global__ void kernel(unsigned char *ptr) {
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
float ox = (x-DIM/2), oy = (y-DIM/2);
float r=0, g=0, b=0;
float maxz = -INF;
for (int i=0; i<SPHERES; i++) {
float n;
float t = s[i].hit(ox, oy, &n);
if (t > maxz) {
float fscale = n;
r = s[i].r * fscale;
g = s[i].g * fscale;
b = s[i].b * fscale;
}
}
ptr[offset*4+0] = (int)(r*255);
ptr[offset*4+1] = (int)(g*255);
ptr[offset*4+2] = (int)(b*255);
ptr[offset*4+3] = 255;
}对于每个pixel,遍历所有的 Spheres,调用 hit 方法,找到离位于球面内部,且最接近球面边界的球。然后确定当前 pixel 的颜色 以上计算过程中,我们发现,我们将随机创建的 20 个球(Spheres),拷贝到了每个执行单元里。但事实上,在每个执行单元实际执行时,只会读这个信息,不会对其修改。所以一个很自然的想法就是,将这个信息放到某个”公共区域”,并且GPU的所有执行单元都能访问它。 具体来说,我们定义 s 时,使用__constant__ 标识,然后在 main 函数中,在得到 20个 Spheres,并将其拷贝到 显存里时,我们这样实现
__constant__ Sphere s[SPHERES];
int main(){
...
cudaMemcpyToSymbol(s, temp_s, sizeof(Sphere)*SPHERES); // copy to constant memory
...
}从常量区域读取数据,会比从普通显存里读数据更快(节省带宽),这个主要是两个原因
从常量区域读的结果,会广播到“附近”的其他thread,至多可以节省15次读取
常量区的内容会被缓存。因此同样地址的多次读取,不会带来多次实际的显存的检索
具体来说,我们需要引入 "warp" 的概念。cuda 中 “warp” 是指一组线程(32个线程),这组线程执行时“步调一致”,即处于同一个warp内的线程,总是执行同一个代码指令(当然是在不同数据上)。当读取常量区域的数据时,单个线程读到的数据可以广播给半个warp的其他线程。 从而原本需要16次读取,现在只需要1次读取就可以了。 除此之外,常量区域内的结果读了以后会被缓存,从而进一步加速了读取。 但这个机制有时候也会影响速度,例如处于warp内的半组线程读取的数据各不相同的话,这些线程的读取请求会排队,从而可能会比从普通显存里读数据更慢。
Cuda Event
显然,这个需要对GPU运算时间,有一个更准确的度量方式,这里就引入了 cuda event 的概念。 cuda 中的 ”event“,可以理解为 GPU 的一个”时间戳“,这样可以更准确的衡量 GPU 中的运算耗时。相关的 API 主要包括
cudaEvent_t start;
cudaEventCreate(&start);
cudaEventRecord(start, 0) // 这个第二个参数0,和 "cuda stream" 相关,可以先不用管通常的结构如下
cudaEvent_t start, end;
cudaEventCreate(&start); cudaEventCreate(&end);
cudaEventRecord(start, 0);
// do some actual work on GPU
// like allocate GPU memory,launch kernel...
...
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop); // 这个不能少
float elapsedTime;
cudaEventElapsedTime(&elapsedTime, start, stop);
printf("GPU running time: %3.1f ms\n", elapsedTime);
cudaEventDestroy(start);
cudaEventDestroy(stop);注意点:我们将 cudaEventRecord 视作一条记录GPU时间戳的指令,但是这条指令会放到 GPU 的执行队列里排队等待执行。因此只有当之前的指令都执行完了,此时这个指令才会真正被执行,通过 cudaEventSynchronize 方法确保这个指令在GPU上已经执行完毕。
Texture Memory
纹理存储(Texture Memory)和上一章的常量存储有点类似,也是为了更快速的数据读取。纹理存储适用的场景是不同线程读取的数据具备某种空间上的“局部性”,即邻近的线程读取的数据也是邻近的,此时使用纹理存储会提升速度。
我们来看一个例子,这个例子是模拟物理学中热量的传递。 具体来说,假设我们有一个矩形,分成了m X n个网格,每个网格视作一个房间。其中某些房间里有热源,这些有热源的房间里会维持某个固定的问题(不同热源温度可能不同)。其余房间,热量从温度高的房间往温度低的相邻的房间传递(这里我们只考虑上下左右四个邻居)。传递方式如下 (单步情形)
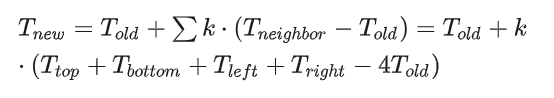
我们使用 GPU 来模拟这个热量传递的过程。 整个过程包含两个比较重要的GPU kernel
copy_const_kernel,给定m X n的房间(网格),每个房间里有一个温度。将有热源的格子的温度设置为初始的热源的问题(因为假设里,热源所在房间的温度是固定的,等于起始热源的问题)blend_kernel,给定某个时刻各个房间的问题,根据扩散公式,计算下一个时刻扩散后的各个房间的温度
我们来看这两个kernel的实现
// iptr 是待更新的数据,cptr是初始热源的情形
__global__ void copy_const_kernel(float *iptr, const float *cptr) {
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
if (cptr[offset] != 0) { // 0 表示没有热源,所以这一步就是只处理有热源的房间
iptr[offset] = cptr[offset];
}
}
__global__ void blend_kernel(float *outSrc, const float *inSrc) {
int x = threadIdx.x + blockIdx.x * blockDim.x;
int y = threadIdx.y + blockIdx.y * blockDim.y;
int offset = x + y * blockDim.x * gridDim.x;
int left=offset-1, right=offset+1;
if (x == 0) left++; // 处理左边界
if (x == DIM-1) right--; // 处理右边界
int top = offset - DIM, bottom = offset + DIM;
if (y == 0) top += DIM; // 处理上边界
if (y == DIM-1) bottom -= DIM; // 处理下边界
outSrc[offset] = inSrc[offset] + SPEED * (inSrc[top] + inSrc[bottom] + inSrc[left] + inSrc[right] = inSrc[offset]*4);
}然后看主要的调度 和 main 函数
#define DIM 1024
#define PI 3.14159265
#define MAX_TEMP 1.0f
#define MIN_TEMP 0.0001f
#define SPEED 0.25f
struct DataBlock {
unsigned char *output_bitmap;
float *dev_inSrc;
float *dev_outSrc;
float *dev_constSrc;
CPUAnimBitmap *bitmap;
cudaEvent_t start, stop;
float totalTime, frames;
};
void anim_gpu(DataBlock *d, int ticks) {
cudaEventRecord(d->start, 0);
dim3 blocks(DIM/16, DIM/16);
dim3 threads(16, 16);
CPUAnimBitmap *bitmap = d->bitmap;
for (int i=0; i<90; i++){
copy_const_kernel<<<blocks, threads>>>(d->dev_inSrc, d->dev_constSrc);
blend_kernel<<<blocks, threads>>>(d->dev_outSrc, d->dev_inSrc);
swap(d->dev_inSrc, d->dev_outSrc);
}
// 感觉最后还应该再执行一次 `copy_const_kernel`,要不然无法满足题设中带热源的房间温度固定这个条件。
float_to_color<<<blocks, threads>>>(d->output_bitmap, d->dev_inSrc);
cudaMemcpy(bitmap->get_ptr(), d->output_bitmap(), bitmap->image_size(), cudaMemcpyDeviceToHost);
cudaEventRecord(d->stop, 0);
cudaEventSynchronize(d->stop);
float elapsedTime;
cudaEventElapsedTime(&elapsedTime, d->start, d->stop);
d->totalTime += elapsedTime;
++d->frames;
printf("Average time per frame: %3.1f ms\n", d->totalTime/d->frames);
}
void anim_exit(DataBlock *d){
cudaFree(d->dev_inSrc);
cudaFree(d->dev_outSrc);
cudaFree(d->dev_constSrc);
cudaEventDestroy(d->start);
cudaEventDestroy(d->stop);
}anim_gpu 里是最主要的执行过程。
先通过 copy_const_kernel ,将带有固定温度的房间(网格)覆盖到 d->dev_inSrc 对应位置,然后在 d->dev_inSrc 上执行扩散过程(blend_kernel),将结果写到 d->dev_outSrc 里,最后通过 swap 操作,再将结果写回到 d->dev_inSrc。
如此执行 90 次,最后将结果转成rgb写到 d->output_bitmap 里,之后就是通过 cudaEvent 得到这个过程的耗时,打印相关耗时结果。
main 函数里就没有太多好说的,主要就是对 DataBlock 的一些初始化,以及 个房间温度的初始化,热源的初始化。
int main() {
DataBlock data;
CPUAnimBitmap bitmap(DIM, DIM, &data);
data.bitmap = &bitmap;
data.totalTime = 0;
data.frames = 0;
cudaEventCreate(&data.start);
cudaEventCreate(&data.stop);
cudaMalloc((void**)&data.output_bitmap, bitmap.image_size());
cudaMalloc((void**)&data.dev_inSrc, bitmap.image_size());
cudaMalloc((void**)&data.dev_outSrc, bitmap.image_size());
cudaMalloc((void**)&data.dev_constSrc, bitmap.image_size());
float *temp = (float*)malloc(bitmap.image_size());
for(int i=0; i<DIM*DIM; i++){
temp[i] = 0;
int x = i%DIM, y = i/DIM;
if ((x>300) && (x<600) && (y>310) && (y<601)) temp[i] = MAX_TEMP;
}
temp[DIM*100+100] = (MAX_TEMP+MIN_TEMP)/2;
temp[DIM*700+100] = temp[DIM*300+300] = temp[DIM*200+700] = MIN_TEMP;
for (int y=800; y<900; y++) {
for(int x=400; x<500; x++) {
temp[x+y*DIM] = MIN_TEMP;
}
}
cudaMemcpy(data.dev_constSrc, temp, bitmap.image_size(), cudaMemcpyHostToDevice);
for(int y=800; y<DIM; y++) {
for (int x=0; x<200; x++) {
temp[x+y*DIM] = MAX_TEMP;
}
}
cudaMemcpy(data.dev_inSrc, temp, bitmap.image_size(), cudaMemcpyHostToDevice);
free(temp);
bitmap.anim_and_exit((void(*)(void*, int))anim_gpu, (void (*)(void*))anim_exit);
return 0;
}main 函数代码较长,但其实没啥太多好说的,主要就是
初始化 DataBlock d 里各个成员,分配内存(显存),初始 cudaEvent
初始化 “热源”,然后同步到显存里 data.dev_constSrc 里
初始化其他房间的初始问题,然后同步到显存 data.dev_inSrc 里
我们来考虑使用纹理存储(Texture memory)来优化上述过程。注意到 blend_kernel 里各个线程的计算是带有很强的“局部性”的
NOTE: "Cuda By Example" 这本书里关于纹理存储API的介绍有点过时,所以以下内容简单看下即可,不做深入讨论。Kepler GPUs 和 Cuda 5.0 之后,Nvidia提供了新的纹理存储的API,See here and here
首先将声明几个纹理内存的对象的引用,这些对象需要定义成全局变量
texture<float> texConstSrc;
texture<float> texIn;
texture<float> texOut;然后通过 cudaBindTexture() 将这些对象“绑定”到已有的显存,其实就是做了两件事情 1. 我们会将某块特定的显存视为“纹理” 2. 我们会使用某个名字作为这个纹理存储的名字
cudaMalloc((void**)&data.dev_inSrc, imageSize);
cudaMalloc((void**)&data.dev_outSrc, imageSize);
cudaMalloc((void**)&data.dev_constSrc, imageSize);
cudaBindTexture(NULL, texConstSrc, data.dev_constSrc, imageSize);
cudaBindTexture(NULL, texIn, data.dev_inSrc, imageSize);
cudaBindTexture(NULL, texOut, data.dev_outSrc, imageSize);为了在 kernel 函数里使用这个纹理存储,还需要使用特定的函数 text1Dfetch(),由于已经定义了纹理对象的引用, blend_kernel 就不再需要传递这些参数了,而是通过一个 flag 来设置现在需要读哪个纹理对象,以及将最后计算的结果写出即可
__global__ void blend_kernel(float *dst, bool dstOut) {
...
if (dstOut) {
t = tex1Dfetch(texIn, top); l = tex1Dfetch(texIn, left);
r = tex1Dfetch(texIn, right); b = tex1Dfetch(texIn, bottom);
c = tex1Dfetch(texIn, offset);
} else {
t = tex1Dfetch(texOut, top); l = tex1Dfetch(texOut, left);
r = tex1Dfetch(texOut, right); b = tex1Dfetch(texOut, bottom);
c = tex1Dfetch(texOut, offset);
}
dst[offset] = c + SPEED * (t+b+r+l-4*c);
}
__global__ void copy_const_kernel(float *iptr) {
...
float c = tex1Dfetch(texConstSrc, offset);
if (c!=0) {
iptr[offset] = c;
}
}最后,在调用上,由于 kernel 函数接口变了,需要适配,以及最后需要解除绑定
void anim_gpu(DataBlock *d, int tick) {
...
volatile bool dstOut = true;
for (int i=0; i<90; i++) {
float *in, *out;
if (dstOut) {
in = d->dev_inSrc;
out = d->dev_outSrc;
} else {
out = d->dev_inSrc;
in = d->dev_outSrc;
}
copy_const_kernel<<<blocks, threads>>>(in);
blend_kernel<<<blocks, threads>>>(out, dstOut);
dstOut = !dstOut;
}
...
}
// 以及退出时,需要解除绑定
void anim_exit(DataBlock *d) {
cudaUnbindTexture(texIn);
cudaUnbindTexture(texOut);
cudaUnbindTexture(texConstSrc);
// 最后再将相关显存和event释放
cudaFree(XX); cudaEventDestroy(YY);
}可以看到,整个过程还是比较冗长的。纹理对象除了1维之外,还可以定义成两维,这样处理图像之类时会更方便一些
texture<float, 2> texConstSrc;
texture<float, 2> texIn;
texture<float, 2> texOut;然后绑定后,使用方式如下
int main() {
...
// treat as 2D texture
cudaChannelFormatDesc desc = cudaCreateChannelDesc<float>();
cudaBindTexture2D(NULL, texConstSrc, data.dev_constSrc, desc, DIM, DIM, sizeof(float)*DIM);
cudaBindTexture2D(...)
cudaBindTexture2D(...)
}
__global__ void blend_kernel(float *dst, bool dstOut) {
...
t = tex2D(texIn, x, y-1);
l = tex2D(texIn, x-1, y);
c = tex2D(texIn, x, y);
r = tex2D(texIn, x+1, y);
b = tex2D(texIn, x, y+1);
}
__global__ void copy_const_kernel(float *iptr) {
...
float c = text2D(texConstSrc, x, y);
...
}最后的解除绑定,和1维情形完全一样,即 cudaUnbindTexture
Graphics Interoperability
这一章主要讲 cuda 程序和 OpenGL 这样图形渲染库的联动,和实际计算关系不大,先跳过吧。 接下来三章讲原子性,cuda stream 和 多 GPU
Atomics
Compute Capability
Nvidia不同的GPU可能会对应不同的 ”计算能力“,通常更高”计算能力“的GPU,会有更多新的特性(例如 MMX, SSE, SSE2 等),之前章节 ([[#Query Device Information]]) 里已经介绍如何获取GPU的各种属性,其中就包括了计算能力(Compute Capability) 这个信息。 本章介绍了原子性操作,适用于计算能力在 1.1 以上的GPU,在 shared memory 上执行的原子性操作,则需要计算能力在 1.2 以上
NOTE: 现在(2024)使用的GPU,通常 Compute Capability(CC) 都是 8.x 了,例如(3080 CC=8.6, 4090 CC= 8.9)
Atomic Operation
cuda 是一种并行化的处理的方式,而在并行化处理中(包括多线程,多进程),数据竞争是常见的问题,例如
x++;这样的操作,实际执行的时候会分成几步 1. 读取 x 里的值 2. 1) 中读到的值加1 3. 将 2) 中的结果写回到 x
当多个线程同时执行 x++ 时,实际执行的操作顺序是不定的,例如线程A,B 都读取了同一个 x 的值,然后执行 +1,最终写回到 x 的结果只是执行一次 +1 的结果。 我们称这样的问题叫 ”read-modified-write" ,为了在多线程中得到正确的结果,需要这个过程是不被打断的,即需要将这个过程限制为一个 "原子操作" (atomic operation)
Computing Histograms
我们来看一个计算直方图的例子 先看 CPU 下的实现
#define SIZE (100*1024*1024)
int main() {
unsigned char *buffer = (unsigned char*)big_random_block(SIZE);
unsigned int histo[256];
memset(histo, 0, sizeof(int)*256);
for(int i=0; i<SIZE; i++){
histo[buffer[i]]++;
}
// we've get histo as our histogram
free(buffer);
return
}然后我们来看在GPU下如何实现,和之前例子的区别在于,直方图的计算中,很容易出现多个线程会更新同一个直方图bin的情况。
int main() {
unsigned char *buffer = (unsigned char*)big_random_block(SIZE);
cudaEvent_t start, stop; // for measuring performance
cudaEventCreate(&start); cudaEventCreate(&stop); cudaEventRecord(start, 0);
unsigned char *dev_buffer;
unsigned int *dev_histo;
cudaMalloc((void**)&dev_buffer, SIZE);
cudaMemcpy(dev_buffer, buffer, SIZE, cudaMemcpyHostToDevice);
cudaMalloc((void**)&dev_histo, 256*sizeof(int));
cudaMemset(dev_histo, 0, 256*sizeof(int)); // like memset, but operates on GPU with error code
// launch GPU kernel, and run it!
...
unsigned int histo[256];
cudaMemcpy(histo, dev_histo, 256*sizeof(int), cudaMemcpyDeviceToHost);
cudaEventRecord(stop, 0); cudaEventSynchronize(stop);
float elapsedTime;
cudaEventElapsedTime(&elapsedTime, start, stop);
print("Time to generate histogram on GPU: %3.1f ms\n", elapsedTime);
cudaEventDestropy(start); cudaEventDestropy(stop);
cudaFree(dev_histo); cudaFree(dev_buffer); free(buffer);
return 0;
}关于launch kernel,这里的推荐做法是 block数量 = 2倍的GPU multiprocessor 数量,因此这块逻辑如下
cudaDeviceProp prop;
cudaGetDeviceProperties(&prop, 0);
int blocks = prop.multiProcessorCount;
histo_kernel<<<blocks*2, 256>>>(dev_buffer, SIZE, dev_histo);最后,我们来看戏 histo_kernel 的实现,特别是多个线程更新同一个 bin 时的原子操作写法
__global__ void histo_kernel(unsigned char *buffer, long size, unsigned int *histo) {
int i = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
while (i<size) {
atomicAdd(&(histo[buffer[i]]), 1); // read-modified-write 的原子实现
i += stride;
}
}atomicAdd(addr, y) 是原子性的读取地址 addr 处的值,增加 y,并将结果写回。
以上方式 GPU 实现是没有问题的,但是实际执行的时候,耗时比 GPU 版本的更多(4倍之多,Under GeForce GTX 285),显然很不合理。这种实现方式慢的原因在于,原子操作太多,几千个线程同时更新一小片的内存,更新过程还是原子的,造成了严重的排队现象,没有很好的发挥GPU并行化的优势。
为了解决这个问题,我们可以将计算直方图这件事情分成两步 1. 每个block,计算单独的直方图信息(这个block内所有thread),虽然也需要原子操作,但1个block内只有256个线程,原子性带来的排队影响会小一些 2. 待这个block内所有线程更新完毕后,一次性的更新到最终结果里 具体来说,实现方式如下
__global__ void histo_kernel(unsigned char *buffer, long size, unsigned int *histo) {
__shared__ unsigned int temp[256]; // block 内的直方图,被各个thread共享
temp[threadIdx.x] = 0;
__syncthreads();
int i = threadIdx.x + blockIdx.x * blockDimx;
int offset = blockDim.x * gridDim.x;
while (i<size) {
atomicAdd(&temp[buffer[i]], 1);
i += offset;
}
__syncthreads();
// 一个block内所有线程更新完毕后,一次性的更新到最终的结果里(by thread)
atomicAdd(&(histo[threadIdx.x]) temp[theadIdx.x]);
}以上几种方式,GTX285 下耗时情况如下

Streams
Page-Locked Host Memory
先介绍什么叫分页内存(pageable memory),什么叫锁页内存(page-locked memory,pinned memory) 通过 malloc 分配的内存叫 分页内存,这样的内存在暂时不用的时候,可能会被CPU 缓冲到硬盘上,然后在需要的时候CPU重新分配,所以这块内存的实际物理地址不是固定的,CPU 会通过页表进行自动的转换,让其”看起来“像是在一个固定的位置上。分页内存的好处是,系统可以分配超过实际物理内存大小的空间。坏处是,对于频繁的大量数据的读写,性能较低。 另外一种内存分配方式叫 “锁页内存”(page-locked memory or pinned memory),和分页内存不同,这个内存空间分配后,会一直在那里,不会被 CPU 缓冲到磁盘上,然后重新分配。这样一旦分配好了,地址不变,就可以通过 DMA 的方式来拷贝数据(to or from)。锁页内存对于大量读写的性能会更高,但也失去了分页内存的好处,系统实际可分配的内存会减少。锁页内存,通过 cudaHostAlloc 来分配。 事实上,即便是在分页内存上拷贝数据,cuda driver也会采用 DMA 的方式,但需要通过两步,首先将分页内存数据拷贝到某个 锁页的 stage buffer,然后再从这个锁页的stage buffer里将数据拷到显存里(或者反过来,显存 -> stage buffer -> pageable memory),显然,这种拷贝方式,会比直接通过 锁页内存 多了一次拷贝,速度上也要慢一倍。
接下来,通过一个例子,来看这两种内存分配方式的使用和对比
先看传统的基于 malloc 的方式,这个就是在CPU 和 GPU上分别分配 size 个元素的内存(显存),然后循环100次,执行内存到显存,或者显存到内存的拷贝(根据输入的参数 up 决定),最终返回总的耗时。
float cuda_malloc_test(int size, bool up) {
// up = True,host => device
// up = False, device => host
cudaEvent_t start, stop;
int *a, *dev_a;
float elapsedTime;
cudaEventCreate(&start); cudaEventCreate(&stop);
a = (int*)malloc(size * sizeof(*a));
cudaMalloc((void**)&dev_a, size * sizeof(*dev_a));
cudaEventRecord(start, 0);
for (int i=0; i<100; i++) {
if (up) cudaMemcpy(dev_a, a, size*sizeof(*dev_a), cudaMemcpyHostToDevice);
else cudaMemcpy(a, dev_a, size*sizeof(*dev_a), cudaMemcpyDeviceToHost);
}
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsedTime, start, stop);
free(a); cudaFree(dev_a); cudaEventDestroy(start); cudaEventDestroy(stop);
return elapsedTime;
}类似的,我们来看基于锁页内存的方式
float cuda_host_alloc_test(int size, bool up) {
cudaEvent_t start, stop;
int *a, *dev_a;
float elapsedTime;
cudaEventCreate(&start); cudaEventCreate(&stop);
cudaHostAlloc((void**)&a, size*sizeof(*a), cudaHostAllocDefault); // 分配锁页内存
cudaMalloc((void**)&dev_a, size*sizeof(*dev_a));
cudaEventRecord(start, 0);
for (int i=0; i<100; i++){
if (up) cudaMemcpy(dev_a, a, size*sizeof(*dev_a), cudaMemcpyHostToDevice);
else cudaMemcpy(a, dev_a, size*sizeof(*dev_a), cudaMemcpyDeviceToHost);
}
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsedTime, start, stop);
cudaFreeHost(a); // 释放锁页内存
cudaFree(dev_a); cudaEventDestroy(start); cudaEventDestroy(stop);
return elapsedTime;
}最后看下 main 函数
#define SIZE (10*1024*1024)
int main() {
float elapsedTime;
float MB = (float)100*SIZE*sizeof(int)/1024/1024; // 执行10次,总的数据量
elapsedTime = cuda_malloc_test(SIZE, true);
printf("\tcuda_malloc_test: MB/s during copy up: %3.1f\n", MB/(elapsedTime/1000)); // malloc, host->dev, 拷贝速度
// 类似的,可以计算 dev->host 拷贝速度,以及 锁页内存(cudaHostAlloc) host->dev 和 dev->host 速度
return 0
}GeForce GTX285下,测试结果如下
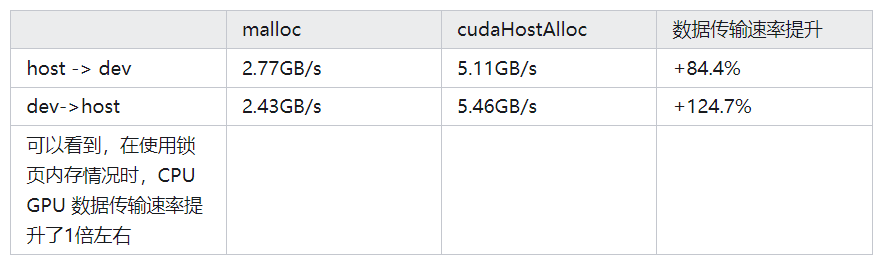
锁页内存除了在数据传输上更快以外,在特定情况下,还是必须使用的。
CUDA Streams
cuda stream 是 GPU 上的一个按顺序执行的队列,其中包括各种待执行的操作,包含加载kernel,内存显存拷贝,事件的开始结束等。操作执行的顺序和将其加入到队列里的顺序是一致的。可以将每一个cuda stream 视为GPU上的一个任务(“task”),同一个task内的操作按顺序执行,不同task之间在执行时可以并行。
我们先看使用单个 cuda stream 的例子,我们考虑给定两个向量,我们分别从其中每个向量取3个元素,然后计算他们的均值
#define N (1024*1024)
#define FULL_DATA_SIZE (N*20)
__global__ void kernel(int *a, int *b, int *c) {
int idx = threadIdx.x + blockIdx.x * blockDim.x;
if (idx < N) {
int idx1 = (idx + 1) % 256;
int idx2 = (idx + 2) % 256;
float as = (a[idx] + a[idx1] + a[idx2]) / 3.0f;
float bs = (b[idx] + b[idx1] + b[idx2]) / 3.0f;
c[idx] = (as + bs)/2;
}
}这个kernel 函数本身不重要,我们主要来看 main 函数
int main() {
// 原本需要检车GPU是否有 `deviceOverlap` 属性,但较新的 GPU 通常都满足,因此先忽略这个检查了
cudaEvent_t start, stop;
float elapsedTime;
cudaEventCreate(&start); cudaEventCreate(&stop); cudaEventRecord(start, 0);
cudaStream_t stream;
cudaStreamCreate(&stream);
int *host_a, *host_b, *host_c;
int *dev_a, *dev_b, *dev_c;
cudaMalloc((void**)&dev_a, N*sizeof(int));
cudaMalloc((void**)&dev_b, N*sizeof(int));
cudaMalloc((void**)&dev_c, N*sizeof(int));
cudaHostAlloc((void**)&host_a, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault);
cudaHostAlloc((void**)&host_b, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault);
cudaHostAlloc((void**)&host_c, FULL_DATA_SIZE * sizeof(int), cudaHostAllocDefault);
for(int i=0; i<FULL_DATA_SIZE; i++) {
host_a[i] = rand(); host_b[i] = rand();
}
...几个注意点 1. GPU有一个属性叫 device overlap,拥有这个属性的GPU,可以同时执行 kernel 函数 和 进行内存显存的数据拷贝,这个通过多个 stream 可以实现 2. 我们使用了 cudaHostAlloc 在host上分配锁页内存,不仅仅因为它在做数据拷贝时更快,而且是因为接下来使用 cudaMemcpyAsync 需要使用锁页内存
接下来,按照以前方式,我们需要将内存数据拷贝至显存,然后加载kernel函数,设置并发数(blocks, threads),最后将结果从显存拷贝回内存,完成计算。但这次,我们会有些改变 1. 我们不会一次性拷贝所有的数据,我们会每次拷贝一个片段的数据到显存,在GPU中完成对这个片段数据的计算,然后将结果拷贝回内存 2. 我们可以将这个过程看做,GPU 的显存比较小,无法一次性把所有数据全部加载进来
for (int i=0; i<FULL_DATA_SIZE; i+=N) {
cudaMemcpyAsync(dev_a, host_a+i, N*sizeof(int), cudaMemcpyHostToDevice, stream);
cudaMemcpyAsync(dev_b, host_b+i, N*sizeof(int), cudaMemcpyHostToDevice, stream);
kernel<<<N/256, 256, 0, stream>>>(dev_a, dev_b, dev_c);
cudaMemcpyAsync(host_c+i, dev_c, N*sizeof(int), cudaMemcpyDeviceToHost, stream);
}注意点 1. 拷贝数据时,使用 cudaMemcpyAsync,这是一个异步执行的函数,和 cudaMemcpy 的区别在于,cudaMemcpy 是同步执行的(这个和 C 里的 memcpy类似),即函数返回时,表示拷贝操作已经完成了。而这个异步执行的函数,只是提交一个操作到 stream 对应的队列,函数返回时,并不能保证拷贝操作已经完成。这个函数要求host内存是 锁页内存(locked memory or pinned memory) 2. kernel函数也是异步调用的,事实上,这个 for 循环结束后,这些 cuda 操作只是提交到了对应的 stream(任务队列),以及它们在任务队列中的实际执行顺序,和任务提交顺序是一致的(即先是 host_to_device ,然后执行 kernel 函数,然后是 device_to_host 的拷贝,然后是下一轮) 3. 接下来需要调用 steam 的同步函数,来确保提交到 stream 的任务已经全部完成了
cudaStreamSynchronize(stream);
cudaEventRecord(stop, 0); cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsedTime, start, stop);
printf("Time taken: %3.1f ms\n", elapsedTime);
// clean up
cudaFreeHost(host_a); cudaFreeHost(host_b); cudaFreeHost(host_c);
cudaFree(dev_a); cudaFree(dev_b); cudaFree(dev_c);
cudaStreamDestroy(stream);
return 0;
}以上,展示的是单个 stream 的情形,实际应用中不多(不过当CPU自身也有一些任务要做时,这个可以让CPU 和 GPU 充分并行,可能会有用)。更常见的是多个 stream 情形。
Using Multiple CUDA Streams
假设 GPU 可以同时执行计算和数据拷贝,那么我们能否通过合理的方式,将 GPU 的这个能力充分利用起来? 例如可以这样,(A-> 表示 memcpy A to GPU,B -> 表示 memcpy B to GPU,-> C 表示 memcpy C from GPU,kernel 表示执行kernel函数),这里假设执行kernel函数耗时和一次数据拷贝耗时差不多。

对于一些更新的GPU,支持同时计算和两次数据拷贝(一次 GPU->CPU,一次 CPU -> GPU),总之对于支持同时计算和数据拷贝的GPU,通过使用多个stream,理论上总能提速。 我们来看使用多个 cuda stream 如何实现之前的计算,这里 kernel 函数和之前完全一样,主要看 main 函数
cudaStream_t stream0, stream1;
cudaStreamCreate(&stream0); cudaStreamCreate(&stream1);
int *host_a, *host_b, *host_c;
int *dev_a0, *dev_b0, *dev_c0; // GPU buffers for stream0
int *dev_a1, *dev_b1, *dev_c1; // GPU buffers for stream1
cudaMalloc((void**)&dev_a0, N*sizeof(int));cudaMalloc((void**)&dev_b0, N*sizeof(int));cudaMalloc((void**)&dev_c0, N*sizeof(int));
cudaMalloc((void**)&dev_a1, N*sizeof(int));cudaMalloc((void**)&dev_b1, N*sizeof(int));cudaMalloc((void**)&dev_c1, N*sizeof(int));
cudaHostAlloc((void**)&host_a, FULL_DATA_SIZE*sizeof(int), cudaHostAllocDefault);
cudaHostAlloc((void**)&host_b, FULL_DATA_SIZE*sizeof(int), cudaHostAllocDefault);
cudaHostAlloc((void**)&host_c, FULL_DATA_SIZE*sizeof(int), cudaHostAllocDefault);
for (int i=0; i<FULL_DATA_SIZE; i++) {
host_a[i] = rand(); host_b[i] = rand();
}
// we've got two streams, so each time 2 chunks
for(int i=0; i<FULL_DATA_SIZE; i+=N*2) {
// first, copy-copy-kernel-copy for stream0
cudaMemcpyAsync(dev_a0, host_a+i, N*sizeof(int), cudaMemcpyHostToDevice, stream0);
cudaMemcpyAsync(dev_b0, host_b+i, N*sizeof(int), cudaMemcpyHostToDevice, stream0);
kernel<<<N/256, 256, 0, stream0>>>(dev_a0, dev_b0, dev_c0);
cudaMemcpyAsync(host_c+i, dev_c0, N*sizeof(int), cudaMemcpyDeviceToHost, stream0);
// then, same for stream1
cudaMemcpyAsync(dev_a1, host_a+i+N, N*sizeof(int), cudaMemcpyHostToDevice, stream1);
cudaMemcpyAsync(dev_b1, host_b+i+N, N*sizeof(int), cudaMemcpyHostToDevice, stream1);
kernel<<<N/256, 256, 0, stream1>>>(dev_a1, dev_b1, dev_c1);
cudaMemcpyAsync(host_c+i+N, dev_c1, N*sizeof(int), cudaMemcpyDeviceToHost, stream1);
}
cudaStreamSynchronize(stream0); cudaStreamSynchronize(stream1);
cudaEventRecord(stop 0); cudaEventSynchronize(stop); cudaEventElapsedTime(&elapsedTIme, start, stop);
printf("Time taken: %3.1f ms\n", elapsedTime);
// clean up all
...在 GeForce GTX285 上对原始单个stream的版本 和使用两个 stream 的版本分别进行计算耗时,发现原始版本(单个stream)耗时 62毫秒,修改后耗时 61毫秒,几乎没啥变化,所以接下来需要具体了解 GPU 上的任务调度的机制,然后再给出一个实现方式。
事实上,GPU 内部分为 "Copy Engine" 和 “Kernel Engine",所谓的 ”device overlap" 是指这个两个 engine 可以同时跑(在没有数据数据依赖的情况下)。所以,按照上边方式实际在 GPU 中会以如下方式调度。 这里 0: copy A 是指 cuda stream 0,执行的 memcpy A 这个操作,0: kernel 是指 cuda stream 0,执行 kernel 函数这个操作。类似的,1: copy A 是指 cuda stream 1,执行 memcpy A 这个操作,以此类推。
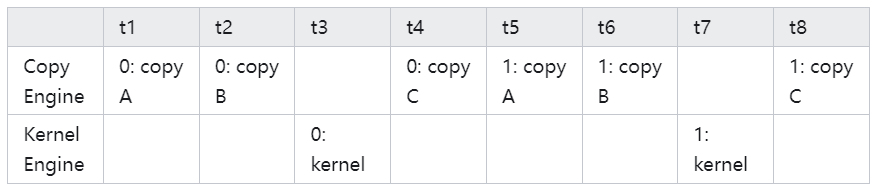
可以看到,在实际调度时,由于数据依赖关系(例如0:copy C 显然需要等待 0: kernel 执行后才能跑),这些操作并没有实现我们预期的那种并行。
那怎么做才能达到我们期望的”并行“呢?看下边这个实现(只看调度部分,其他部分和之前没有区别)
for (int i=0; i<FULL_DATA_SIZE; i+=N*2) {
cudaMemcpyAsync(dev_a0, host_a+i, N*sizeof(int), cudaMemcpyHostToDevice, stream0);
cudaMemcpyAsync(dev_a1, host_a+i+N, N*sizeof(int), cudaMemcpyHostToDevice, stream1);
cudaMemcpyAsync(dev_b0, host_b+i, N*sizeof(int), cudaMemcpyHostToDevice, stream0);
cudaMemcpyAsync(dev_b1, host_b+i+N, N*sizeof(int), cudaMemcpyHostToDevice, stream1);
kernel<<<N/256,256,0,stream0>>>(dev_a0, dev_b0, dev_c0);
kernel<<<N/256,256,0,stream1>>>(dev_a1, dev_b1, dev_c1);
cudaMemcpyAsync(host_c+i, dev_c0, N*sizeof(int), cudaMemcpyDeviceToHost, stream0);
cudaMemcpyAsync(host_c+i+N, dev_c1, N*sizeof(int), cudaMemcpyDeviceToHost, stream1);
}我们将这个实现,对应到实际调度上,大概是下边这个形式
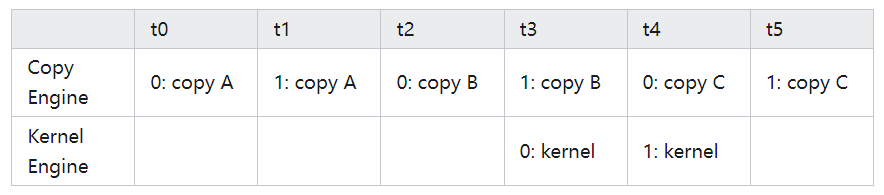
可以看到,这种调度方式,确实实现了我们期望的并行,即数据拷贝 和 kernel 函数能同时进行。实测耗时也会从之前的 61毫秒降低到 48毫秒,显然这个优化才是有效的。
Multiple GPUs
Zero-Copy Host Memory
之前,引入 cudaHostAlloc 时,介绍了 两种不同的内存分配方式 1. 分页内存,通过 malloc 分配的内存,这种内存在需要的时候,会被 CPU 缓冲到磁盘上,然后再在需要的时候重新载入(到另外一个物理地址上),CPU 通过页表来屏蔽这个影响 2. 锁页内存,通过 cudaHostALloc 分配的内存,这个内存物理地址始终不变,不会被 CPU 缓存,在涉及数据拷贝时,速度会更快,但分配过多锁页内存,会让系统可用的物理内存减少,降低系统的整体速度 当我们通过 cudaHostAlloc 分配内存时,有一个参数叫 cudaHostAllocDefault,当时并未对这个参数过多说明。事实上,这里这个参数还可以传入 cudaHostAllocMapped,此时分配的锁页内存,还可以被 GPU 直接访问,我们这个叫 ”零拷贝内存“(zero-copy memory)
我们以之前实现的计算向量内积([[#Shared Memory and Synchronization]])为例,介绍如何使用零拷贝内存来实现这个例子。
float cuda_host_alloc_test(int size) {
cudaEvent_t start, stop;
float *a, *b, c, *partial_c;
float *dev_a, *dev_b, *dev_partial_c;
float elapsedTime;
cudaEventCreate(&start); cudaEventCreate(&stop);
cudaHostAlloc((void**)&a, size*sizeof(float), cudaHostAllocWriteCombined | cudaHostAllocMapped);
cudaHostAlloc((void**)&b, size*sizeof(float), cudaHostAllocWriteCombined | cudaHostAllocMapped);
cudaHostAlloc((void**)&patial_c, blocksPerGrid*sizeof(float), cudaHostAllocMapped);
for (int i=0; i<size; i++) {
a[i]=i; b[i]=i*2;
}
...这里,在分配 a,b,partial_c 的内存时,我们采用了 cudaHostAlloc 分配锁页内存。其中 cudaHostAllocMapped 表示分配的是 零拷贝内存(GPU可以直接访问),对于两个输入,我们还设置 cudaHostAllocWriteCombined 参数,表明分配的是写联合空间,此类内存不使用 L1 和 L2 cache,所以程序其他部分就有更多的L1,L2 缓存可用,由于没有使用 L1,L2 cache,CPU读这段内存会很慢,因此主要适用于 CPU写入,GPU读取的锁页内存。 带有 cudaHostAllocMapped 标识的内存,可以被 GPU 访问,但GPU会有不同的存储映射表,所以需要通过 cudaHostGetDevicePointer() 将其转成 GPU 下的地址,具体使用方式如下
cudaHostGetDevicePointer(&dev_a, a, 0);
cudaHostGetDevicePointer(&dev_b, b, 0);
cudaHostGetDevicePointer(&dev_partial_c, partial_c, 0);有了GPU下的地址,就可以启动计时器,然后加载 kernel 函数 dot
cudaEventRecord(start, 0);
dot<<<blockPerGrid, threadsPerBlock>>>(size, dev_a, dev_b, dev_partial_c);
cudaThreadSynchronize();由于 dev_a, dev_b, dev_partial_c 实际指向的还是 host 侧的内存,因此不需要通过 cudaMemcpy 来做任何内存拷贝。但是注意到加载 dot 之后,会执行 cudaThreadSynchronize(),这个是因为 GPU 执行期间,零拷贝内存里的内容是不确定的,同步以后,我们可以确保此时kernel函数执行完毕,零拷贝内存里的内容已经是最终结,此时停止计时器,得到最终结果
cudaEventRecord(stop, 0); cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsedTime, start, stop);
c = 0;
for (int i=0; i<blockPerGrid; i++) {
c += partial_c[i];
}最后,释放所有分配的资源(包括 cudaEvent)
cudaFreeHost(a); cudaFreeHost(b); cudaFreeHost(partial_c);
cudaEventDestroy(start); cudaEventDestroy(stop);
printf("Value calculated: %f\n", c);
return elapsedTime;
}可以看到,锁页内存的释放方式还是和之前一样,通过 cudaFreeHost 完成
最后,在 main 函数里,需要检查下当前使用的 GPU 是否支持映射host侧的内存,这个通过 cudaGetDeviceProperties() 检查 canMapHostMemory 属性即可。如果GPU支持这个功能,还需要设置一个 flag 来开启之。差不多就像下边这段代码
int main() {
cudaDeviceProp prop;
int whichDevice;
cudaGetDevice(&whichDevice);
cudaGetDeviceProperties(&prop, which);
if (prop.canMapHostMemory != 1) {
printf("Device cannot map memory.\n");
return 0;
}
cudaSetDeviceFlags(cudaDeviceMapHost);
float elapsedTime = cuda_host_alloc_test(N);
printf("Time using cudaHostAlloc: %3.1f ms\n", elapsedTime);
return 0;
}零拷贝内存的性能如何? 这个问题的答案和 GPU 是独立显卡还是集成显卡相关。独立显卡有自己的存储(称为显存),集成显卡则是集成在主板之上,和 CPU 共用内存。 对于集成显卡,采用零拷贝内存,总是会有性能提升,因为显卡本来也是要读内存里数据,通过零拷贝内存,可以减少一次数据拷贝。当然代价也是有的,零拷贝内存也是一种锁页内存,而锁页内存总是会消耗实际物理内存,从而降低系统实际可用的物理内存,影响系统整体表现。 对于独立显卡,情况会复杂一些。当输入输出都只会被用到一次时,零拷贝内存会更快。但由于零拷贝内存在GPU侧没有缓存,如果数据被GPU多次频繁读取,最终可能反而会有更大的整体延迟。
对于上述的计算向量内积的例子,由于数据确实只会被读取写入一次,从而使用零拷贝内存会更快。在 GeForce GTX 285上,在没有使用零拷贝内存的情况下,耗时 98.1 毫秒,而使用了零拷贝内存后,耗时降低到了 52.1 毫秒,可以看到性能提升是很明显的。
Using Multiple GPUS
现代计算机,多GPU情况是常见的(例如集成显卡+独立显卡,或者多个独立显卡)。这里我们还是以向量内积的例子,来讨论如何使用多GPU来处理问题。 首先定义和每个GPU相关的数据结构
struct DataStruct {
int deviceID; // GPU ID
int size; // size of input buffer
float *a, *b; // input buffer
float returnValue; // a^Tb result
};为了确保系统中有多个GPU,先通过 cudaGetDeviceCount() 检查下
int main() {
int deviceCount;
cudaGetDeviceCount(&deviceCount);
if (deviceCount < 2) {
printf("We need at least 2 GPUs, found %d\n", deviceCount);
return 0;
}然后和之前一样,初始输入
float *a = (float*)malloc(sizeof(float) * N);
float *b = (float*)malloc(sizeof(float) * N);
for(int i=0; i<N; i++) {
a[i] = i; b[i] = i*2;
}接下来,准备实现多 GPU 部分的代码。这里的关键在于,每个 GPU 需要由一个单独的 CPU 的线程控制。以下我只考虑两个 GPU 的情形,并且假设 CPU 线程部分的逻辑已经封装好了
DataStruct data[2];
data[0].deviceId = 0; data[0].size = N/2; data[0].a = a; data[0].b = b;
data[1].deviceId = 1; data[1].size = N/2; data[0].a = a+N/2; data[0].b = b+N/2;
CUTThread thread = start_thread(routing, &(data[0])); // additional thread
routing(&(data[1])); // main thread
end_thread(thread);
free(a); free(b);
printf("Value calculated: %f\n", data[0].returnValue + data[1].returnValue);
return 0;
}注意,这里我们其实只是额外创建了一个CPU下的线程,另外一个由当前主线程直接调用 routing 函数
最后,看下 routing 函数的实现
void *routing(void *pvoidData) {
DataStruct *data = (DataStruct*)pvoidData;
cudaSetDevice(data->deviceID);
// 剩下的部分和之前单GPU下的kernel(没有使用零拷贝内存的版本)函数基本没有区别
// 为什么不用零拷贝内存?多线程情形下,锁页内存(当然也是零拷贝内存)会有其他问题
...
}可以看到,核心在于需要为每个 GPU 单独分配一个 CPU 的线程(可以包括当前主线程),然后在 kernel 函数内,通过 cudaSetDevice 绑定到对应 ID 的 GPU 即可。
Portable Pinned Memory
我们讨论多线程情形下的锁页内存问题。通过 cudaHostAlloc 分配的锁页内存,在多线程情形下,只会被分配了该锁页内存的线程,认为是锁页内存,而其他线程依然 认为 这块内存时分页内存(虽然事实上,这块内存 真的是 是锁页内存)。 因此在多线程情况下,这样会导致两个问题 - 其他线程,在试图将这块内存通过 cudaMemcpy 拷贝至显存时,会依然按照分页内存的方式拷贝,可能会降低了 50% 以上的速度 - 其他线程,当对这块内存使用 cudaMemcpyAysnc 时,会直接失败,因为 cudaMemcpyAsync 需要的是锁页内存,而这块内存,会被非创建线程 认为 是分页内存
如何解决这个问题? 分配 pinned memory 时,指定一个新的 flag (cudaHostAllocPortable) 即可,这个 flag 可以和之前的 cudaHostAllocWriteCombined,cudaHostAllocMapped 联合使用。
还是以向量内积的例子为例,为了实现多 GPU 下,零拷贝版本的实现,
int main() {
...
float *a, *b;
cudaSetDevice(0);
cudaSetDeviceFlags(cudaDeviceMapHost); // 打开 GPU0 的这个flag
cudaHostAlloc((void**)&a, N*sizeof(float), cudaHostAllocWriteCombined | cudaHostAllocPortable | cudaHostAllocMapped);
cudaHostAlloc((void**)&b, N*sizeof(float), cudaHostAllocWriteCombined | cudaHostAllocPortable | cudaHostAllocMapped);
// start new thread, attach to `routing`
// main thread call `routing`
// finish newly started thread
// get result, then clear all
...
}routing 函数的实现,和之前也稍微有些区别,注意到分配的 锁页内存 是在 GPU0 下做的,因此还要把这个信息告诉 GPU 1,以及由于使用了零拷贝技术,对于内存中的输入,就不需要拷贝到显存了,只需做个地址映射即可,剩下的其他逻辑和之前一致。
void *routing(void *pvoidData) {
DataStruct *data = (DataStruct*)pvoidData;
if (data->deviceId != 0) { // do not call `cudaSetDevice` twice on single thread
cudaSetDevice(data->deviceID);
cudaSetDeviceFlags(cudaDeviceMapHost);
}
...
// 之前需要用 `cudaMemcpy` 将内存中的输入拷贝至显存,这里只需要重新映射地址即可
// 其他的和之前的实现没有区别
cudaHostGetDevicePointer(&dev_a, a, 0);
cudaHostGetDevicePointer(&dev_b, b, 0);
cudaMalloc((void**)&dev_partial_c, blocksPerGrid*sizeof(float));
...
}投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内最大最专业,近3000人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦感知、定位、融合、规控、标定、端到端、仿真、产品经理、自动驾驶开发、自动标注与数据闭环多个方向,目前近60+技术交流群,欢迎加入!
自动驾驶感知:目标检测、语义分割、BEV感知、毫米波雷达视觉融合、激光视觉融合、车道线检测、目标跟踪、Occupancy、深度估计、transformer、大模型、在线地图、点云处理、模型部署、CUDA加速等技术交流群;
多传感器标定:相机在线/离线标定、Lidar-Camera标定、Camera-Radar标定、Camera-IMU标定、多传感器时空同步等技术交流群;
多传感器融合:多传感器后融合技术交流群;
规划控制与预测:规划控制、轨迹预测、避障等技术交流群;
定位建图:视觉SLAM、激光SLAM、多传感器融合SLAM等技术交流群;
三维视觉:三维重建、NeRF、3D Gaussian Splatting技术交流群;
自动驾驶仿真:Carla仿真、Autoware仿真等技术交流群;
自动驾驶开发:自动驾驶开发、ROS等技术交流群;
其它方向:自动标注与数据闭环、产品经理、硬件选型、求职面试、自动驾驶测试等技术交流群;
扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!



















 192
192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









