



作者 | 一介书生 编辑 | 自动驾驶之星
点击下方卡片,关注“自动驾驶之心”公众号
戳我-> 领取自动驾驶近15个方向学习路线
本文只做学术分享,如有侵权,联系删文
车端感知算法变迁
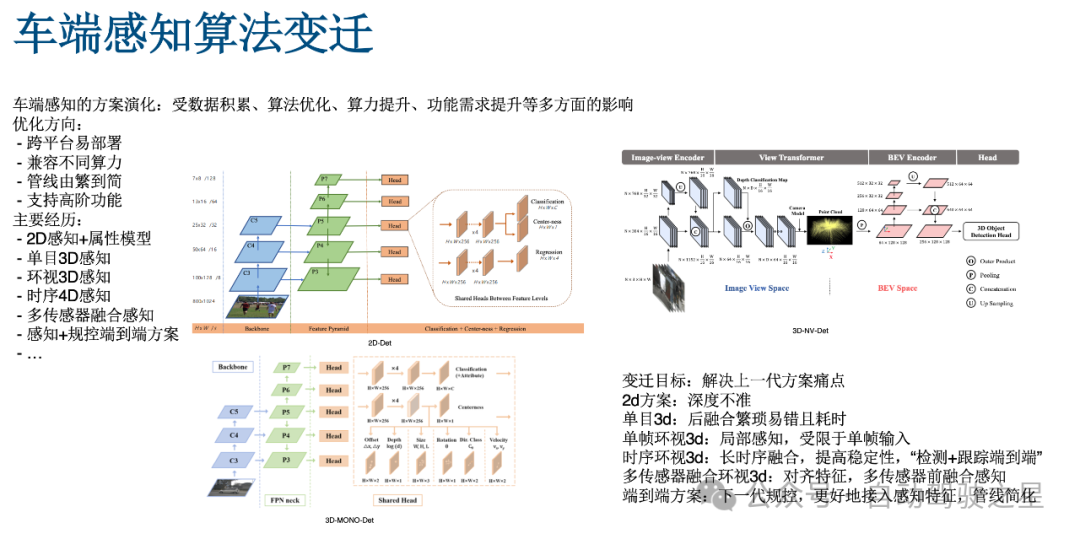
图1: 车端感知算法的变迁
FastBEV的目标是面向于实时的车端的一个BEV环视的感知芯片。它的一个特点是一个中低算力友好的实现方案。如图1所示自动驾驶感知算法的变迁,它可能不同阶段不同方案是受到不同的数据积累不同的算法优化的一个成熟度,还有一个车端算力的芯片提升以及说我们对不同的功能需求的多样性之类的都是相关的,那他可能目前可能这段时间内的一些优化方向的话,一方面可能会考虑到说跨平台,以及部署的问题,要兼容到一些不同的算力平台。
这两年自动驾驶感知发展比较快的几年,技术的变迁目标都是为了解决上一代方案痛点,2D方案的缺点在于深度不准,单目3D方案的缺点在于后融合繁琐易错且耗时。单帧环视3D的方案的缺点在于局部感知的能力,受限于单帧输入。时序环视3D的方案的优点在于长时序融合,提高稳定性,可以理解为“检测+跟踪的端到端”。多传感器融合环视3D方案:对齐特征融合了多传感器的特征,感知能力更强。而大家所期待的端到端的放哪:下一代规控,更好地接入感知特征,管线更加简化,或者换句话说更加丝滑了。
视频1: 关于车端感知算法的迁移解读
BEV versus Occupancy
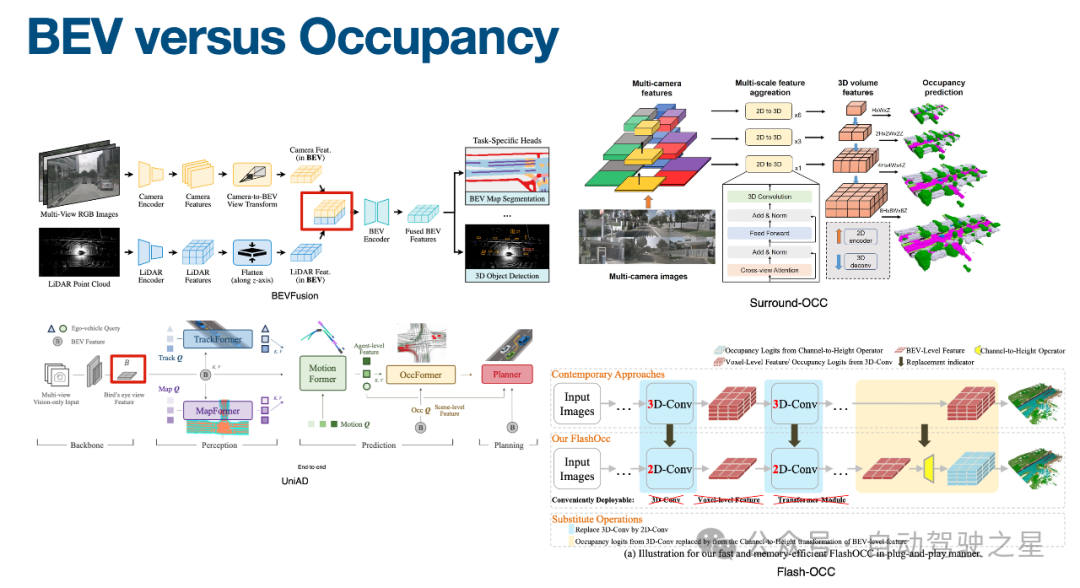
图2: BEV versus Occupany
如图2所示,对于环视前融合这样方案,初步阶段是一个基于BEV future的融合,只有一层BEV的特征,换一个思维理解,就是在纯鸟瞰图下的一个2D BEV特征。它可能同时有传统维和深度维,跟着这个一个思路,比如说把BEV给它拉伸到一个三维的空间去做。基于三维的空间去预测相关的占据,那这就是占据网络相关的思路,最大的一个问题是这个东西会非常的重。如图2中的所表示的 Surround-OCC 网络结构所示。那么是否有轻量化的Occ 表示呢,Flash-OCC 网络就是这样设计,核心点是2D 转3D,会发现是一个比较慢的东西,因为刚刚提到这个特征,又要有深度,又要有一个特征为本身的维度,还涉及到要有六个camera的话,那可能六个camera先各自要做一份。图2中这几篇工作,都是先会把它放到一个好的BEV特征上,然后再去做后续任务,基于这个也能看到一个点,BEV特征融合后的特征,对于各个任务首先都是一个比较好的初始。融合一个统一特征本身,它的任务本身还是比较能够泛化的。
Dense 2D to 3D project
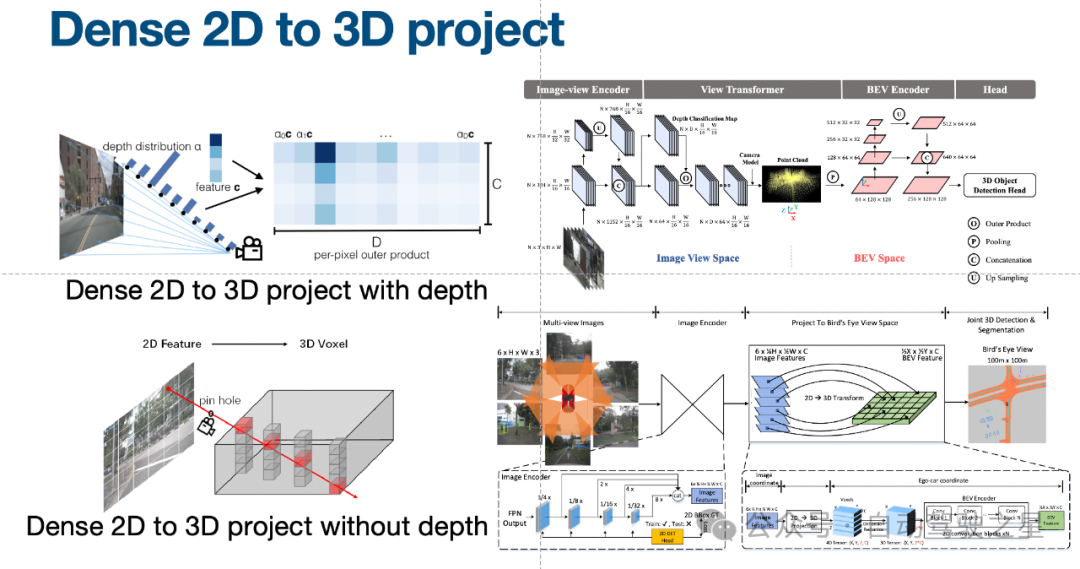
图3: Dense 2D to 3D project
图3 所示主要是说明了显示和隐式的2D转3D,隐式就没有显示的去构建这样一个2D转3D(它的一个类似于索引和融合这样一个过程),隐的方式是从原始的构建2D特征,同时构建出一系列初始的3D点的一些散点。把它作为一个3D的坐标点序列,作为一个位置编码去编码2D特征里面,然后再去接一些position,Encoder和一些结构直接去3D结构,核心用的还是那样一些对应关系,但是它可能就不用显示的先构建出一个BEV特征。
BEVPool V2 versus FastBEV
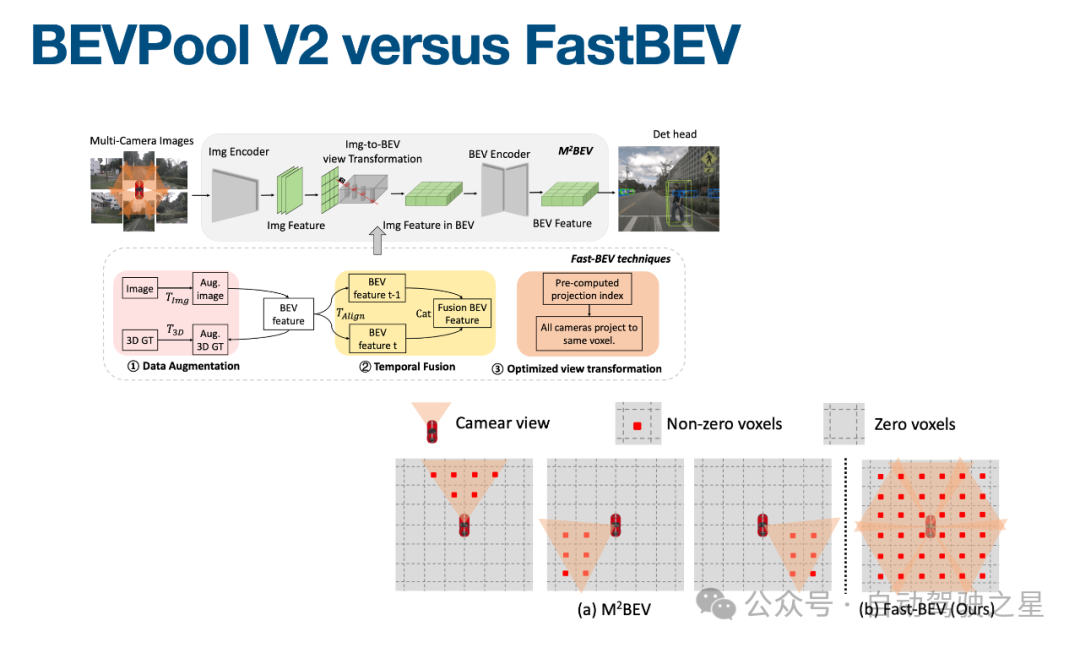
图4: BEVPool V2 versus FastBEV
如图4所示,首选Fast BEV 设计的本身吸收了很多新的Trick 比如时序的融合,2D,3D的引入,深度上不去做过进一步的深度预测,这样的一个隐式深度假设我们就直接均匀的给它铺开。基于这个思想核心的实现,就它是这个东西是可以做的非常快的点是什么?如图4中比如说如果这是一个车子,自车是红色的,可能每个camera只拍到了各自的一部分特征。原来M2BEV 的实现,是每一部分特征各自放一份,然后第二个也各自放一份,完了之后再把六份这样的结果,但是核心点会发现说,因为放就是每个camera之间它的重叠区域会非常小。也就是说,只有涉及到一些重叠区域的时候,它可能才涉及到说这部分的特征是来自不同camera的。然后在每个camera各自拍到的那部分特征之下,它各自特征基本上都是沿着射线等价的。
我们觉得说我两个设计都相机都拍到了,那我也不用考虑那么多了,我就只留一份,这个会造成一个什么样的结果?那这样的就变成了说我们每一个voxels 这个格子应该填每一个camera下的哪个位置的特。它就是一个固定的东西了。那这样的话,只需要通过最终的一个voxels的大小的volume的每一个索引值,就去只需要建立一遍索引。比如说零零这个位置的特征。只需要拿,比如说第一个camera的,比如说第33某个位置的特征,我只要通过建立这样的索引关系,我就直接这样循环做一遍去填充,然后这样就填完了,这样可以做的非常快,其实整个过程是一个静态的参数对应的一个东西,它本身就可以建立一个叉表,其次还完全省去了六个camera各自要构建一遍再同步去做融合这个事.
视频2: FastBEV 核心思路讲解
Fast BEV 的主要贡献
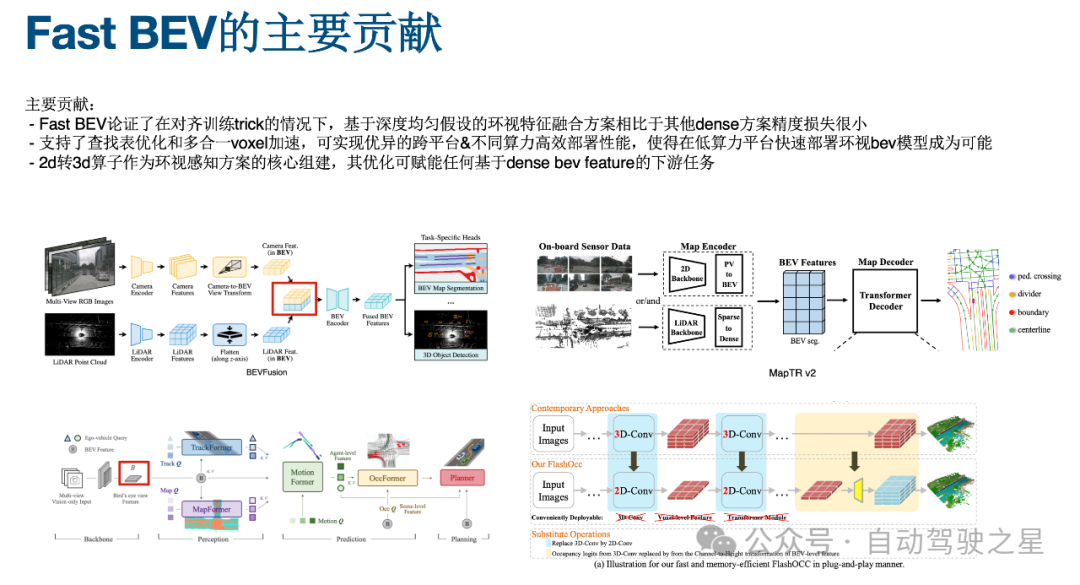
图5: Fast BEV 的主要贡献
如图5 所示 Fast BEV 的主要贡献
1) FastBEV 论证了在对齐训练Trick 的情况下, 基于深度均匀假设的环视特征融合方案相比于其他dense 方案进度损失很小
2) 支持了查找表优化和多合一voxel 加速,可实现优异的跨平台&不同算力高效部署性能,使得在低算力平台快速部署环视BEV 模型成为可能
3) 2D 转3D 算子作为环视感知方案的核心组建,其优化可赋能任何基于Dense BEV feature的下游任务
最后的彩蛋
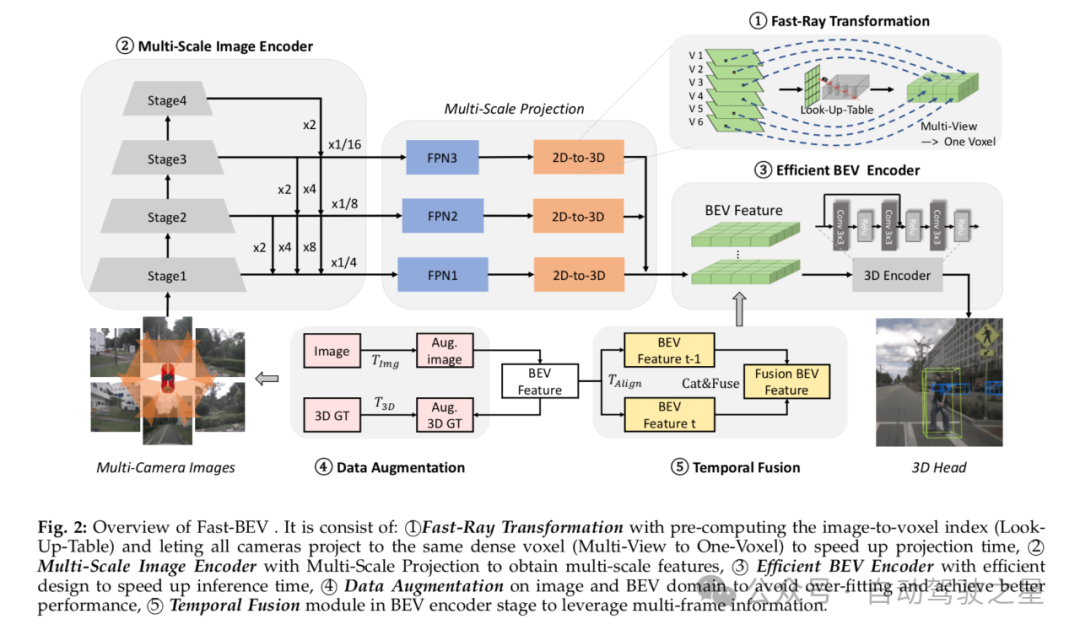
图6: Fast BEV 经典 pipeline
如图6 所示为Fast BEV 经典的pipeline, 在此致敬一下这种查找表的创新之作,最后关于完整的视频分享,后续会整理出更加详细的内容和视频
投稿作者为『自动驾驶之心知识星球』特邀嘉宾,欢迎加入交流!
① 全网独家视频课程
BEV感知、毫米波雷达视觉融合、多传感器标定、多传感器融合、多模态3D目标检测、车道线检测、轨迹预测、在线高精地图、世界模型、点云3D目标检测、目标跟踪、Occupancy、cuda与TensorRT模型部署、大模型与自动驾驶、Nerf、语义分割、自动驾驶仿真、传感器部署、决策规划、轨迹预测等多个方向学习视频(扫码即可学习)

② 国内首个自动驾驶学习社区
国内最大最专业,近2700人的交流社区,已得到大多数自动驾驶公司的认可!涉及30+自动驾驶技术栈学习路线,从0到一带你入门自动驾驶感知(2D/3D检测、语义分割、车道线、BEV感知、Occupancy、多传感器融合、多传感器标定、目标跟踪)、自动驾驶定位建图(SLAM、高精地图、局部在线地图)、自动驾驶规划控制/轨迹预测等领域技术方案、大模型、端到端等,更有行业动态和岗位发布!欢迎扫描下方二维码,加入自动驾驶之心知识星球,这是一个真正有干货的地方,与领域大佬交流入门、学习、工作、跳槽上的各类难题,日常分享论文+代码+视频

③【自动驾驶之心】技术交流群
自动驾驶之心是首个自动驾驶开发者社区,聚焦2D/3D目标检测、语义分割、车道线检测、目标跟踪、BEV感知、多模态感知、Occupancy、多传感器融合、transformer、大模型、在线地图、点云处理、端到端自动驾驶、SLAM与高精地图、深度估计、轨迹预测、NeRF、Gaussian Splatting、规划控制、模型部署落地、cuda加速、自动驾驶仿真测试、产品经理、硬件配置、AI求职交流等方向。扫码添加汽车人助理微信邀请入群,备注:学校/公司+方向+昵称(快速入群方式)

④【自动驾驶之心】平台矩阵,欢迎联系我们!


















 137
137

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









