




引言
在协助众多传统制造业公司进行了一系列的 IOT 方案升级改造和落地实施后,还是总结了不少这方面的经验,今天我们一起来看看, Apache Doris 在 IOT 场景从技术实现角度和业务场景提效方面应该如何正确的设计架构方案及开发实现。
选型理由
在 IOT 场景中,最常听的存储数据库有 IotDB、TDengine 等工业时序数据库,但在随着日志这类"数据三等公民"的地位上升,更多的制造业企业希望通过这类数据挖掘出更多业务相关的有价值场景。这类数据已不是独立于主数据体系外的"无用"数据,而是需要和主数据进行联合查询的重要资产,所以以 Doris 作为主数仓的企业,更希望数据不再割裂和多份存储,以此保证数据时效性、一致性,故此我们来看看如何在 IOT 场景中正确使用 Doris,Doris 又能满足哪些实际应用场景。
常见场景
预警告警
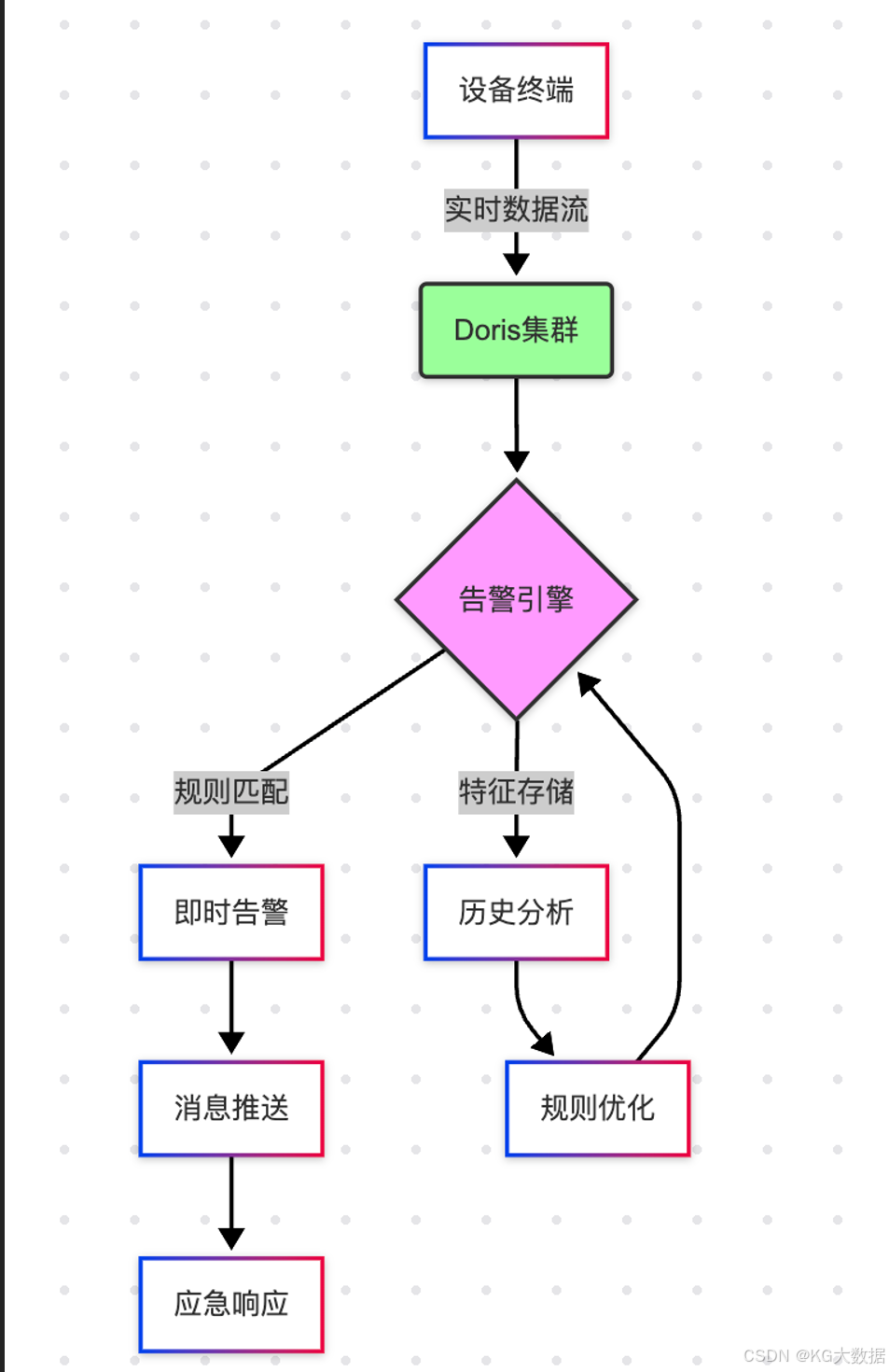
在工业终端(工业机器人、工业流水链等)或者设备终端(汽车、摩托、手机等),往往会产生大量的终端即时日志实时发送到服务端,这类日志里面包含了机械和电子元器件的运行状态、数值、异常等信息,而智能化的预警告警场景中,对实时监听这些日志并即时的触发对应策略机制,如停止终端运行、设备中心告警等各类场景,对日志内的信息检索速度和导入时效性就有了非常高的要求。
以车机为例,这类数据往往可以采取两种解决方案来设计:
- 即时上报当前运行状态的所有有效信息
- 边缘计算一部分区间值定时上报
方案一中,车机终端只负责采集当前 CAN 总线的即时数据,然后封装为 JSON 或者 XML 格式通过物联网通讯卡发送至服务端,这类数据不包含任何边缘侧的计算结果值数据,所以所有计算压力都会堆积到服务端完成,如果服务端需要监听的状态变化值指标过多,那服务端的压力将会非常大。
这类方案好处是可以尽可能的获取到最细粒度的数据,比如一辆车发生碰撞,如果发送的间隔时间是1s,那就可以获取最后一刻状态下的所有完整数据,这个对第二块:分析查询场景中,作用是非常大的。
方案二中,车机终端需要自行定时完成状态变化值的计算,比如过往1min内的电池升温量、过去3s的车辆加速度等,这类数据的计算也可分为两种上报机制,第一种是拉大整体上报时间,将边缘计算的变化值连同瞬时状态一起按时间间隔计算上报,如5s计算上报一次,这种会出现的问题是可能会丢失(服务端未接收,车机端有留存)间隔时间内的明细数据,第二种是瞬时状态明细值按1s发送,每5s再将计算好的状态变化值添加到下一秒上报的报文中。
这类方案就是边缘计算的一种类型,可以大幅度分摊服务中心的计算压力,交由车机部分拆解完成然后结果上报,两种都有各自的优劣,如第一种对车机端的采集和报文生成系统要求较低,第二种可能还要进一步升级物理硬件和车机系统才能完成,而且会消耗一定的车机算力,所以两种方案是不同阶段下的处理方案。
分析查询
日志信息有很大一部分应用场景就是:溯源。
溯源是说,如果出现了问题或者隐患,可以通过日志信息回放来推测出当时的设备终端是什么状态,遭遇了什么,整个运行过程中又发生了什么。我们还是拿车机来举例。
假设一辆新能源具备"智能座舱",在正常行驶过程中,遇到了突发意外情况,比如被追尾、侧滑、失速等情况,车辆实时发送至车企中心和国家数据中心的传感器信息,将成为时候确定事故因素、判定责任划分、改善故障问题的重要依据,比如经常上媒体热搜的"新能源车刹车失灵"事件,通过溯源分析事故发生前若干分钟的传感器数据信息,可得知是车辆故障问题还是用户误踩导致的交通事故。
在分析查询的场景中,数据往往不追求时效性,但是追求数据完整性,同时需要从庞大的车辆行驶数据中筛选出指定车辆在某一时间段按时间进行排序的日志数据。这对数据写入的完整性、存储的可靠性、百亿级数据的查询筛选能力,都有比较高的要求。
同时在电子围栏、行车轨迹、防盗告警等方面,也需要这类能力。虽然在不同的业务场景,对时效性要求并不一致,但是普遍在业务方的应用过程中,都希望数据时效性越高越好。
比如车企配合执法部门调取车辆行驶记录,追溯被盗车辆行车轨迹和当前位置,这类场景时效性较低,查询频次也较低,再比如用户自行设置电子围栏四至,车辆在非可行驶时间段驶出电子围栏,实时给用户告警,这类场景就要求时效性非常高,最大延迟允许分钟内完成。
模型训练
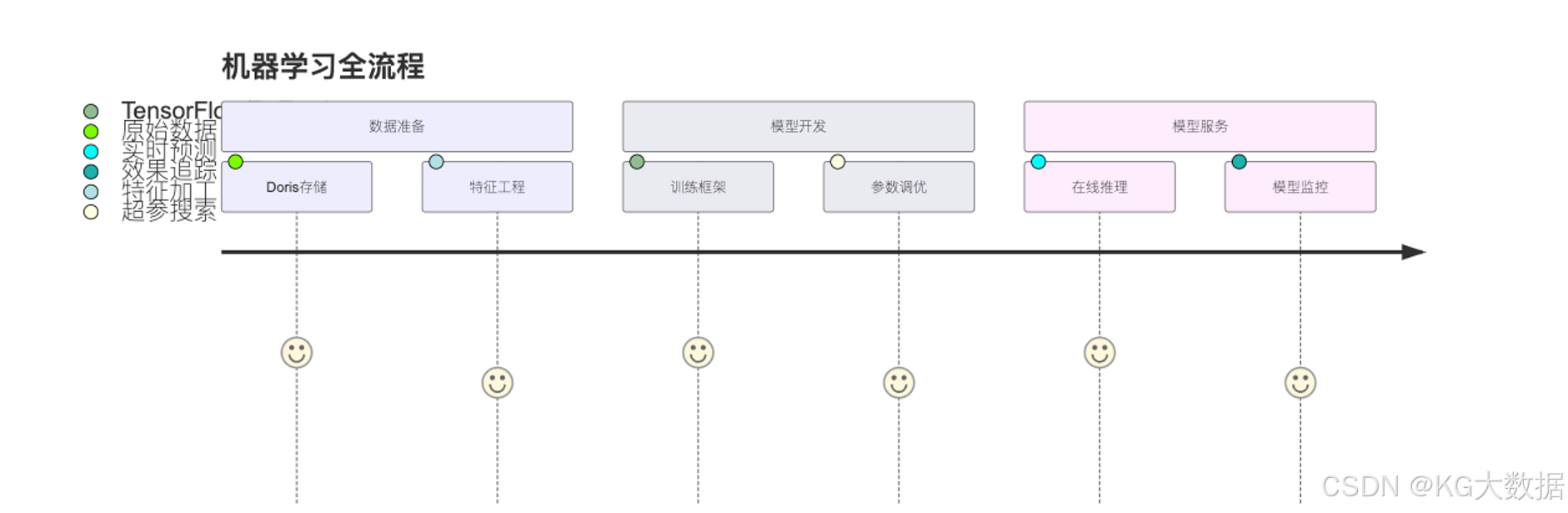
大规模的日志数据接入后,除去做分析和实时告警及异常监控处理外,还有一个重要的用处:预测。
在当下主流的技术栈中,想要完成预测,往往需要大量的历史数据作为蓝本进行模型特征训练,日志数据恰好就是模型训练的最重要的素材,无论是使用 Pandas 等库做模型训练,还是使用一些 SQL 实现回归算法等简单拟合计算,模型训练都需要一个数据存储的基座来完成整体数据吞吐的功能。
在过往的解决方案中,一般是将数据存储于 HDFS 文件系统或者 S3 对象存储内,然后再通过 HDFS-API 和 S3-API 直接读取文件加载至内存完成分析。但随着基于 HDFS 的即席分析能力逐渐无法满足业务方的增长速度后,越来越多的企业更希望能基于 OLAP 数据库来做大规模数据的吞吐加工操作,这样一方面数据不需要再额外基于 HDFS 等系统额外存储一份,另一方面将计算好的标签数据回写入 OLAP 中,数据的一致性和时效性都可以得到保障。
在这类场景中,使用数据库做基座,数据的吞吐是整个处理链路中耗时最长、优化最难的问题,若使用 JDBC 协议进行数据传输,受限于行列转换等性能消耗,单次查询千万以上数据做返回值时,整体耗时会非常明显,一方面会拖慢整个数据库的查询效率,另一方面数据加工和处理的时效性很难满足业务的要求。
Doris 解决方案
预警告警
在预警告警场景中,Doris 可以通过以下几个方面来满足需求:
- 实时性保障
• 通过 Stream Load 实现毫秒级数据写入
• 借助 Routine Load 持续消费 Kafka 数据
• 利用物化视图预计算常用指标 - 告警策略支持
• 使用 Unique 表存储告警规则
• 通过 Materialized View 实现规则预计算
• 结合 Flink 实现复杂的实时计算告警 - 高并发查询
• 分区分桶设计保证查询性能
• 合理的索引设计加速查询
• 通过副本机制保证高可用
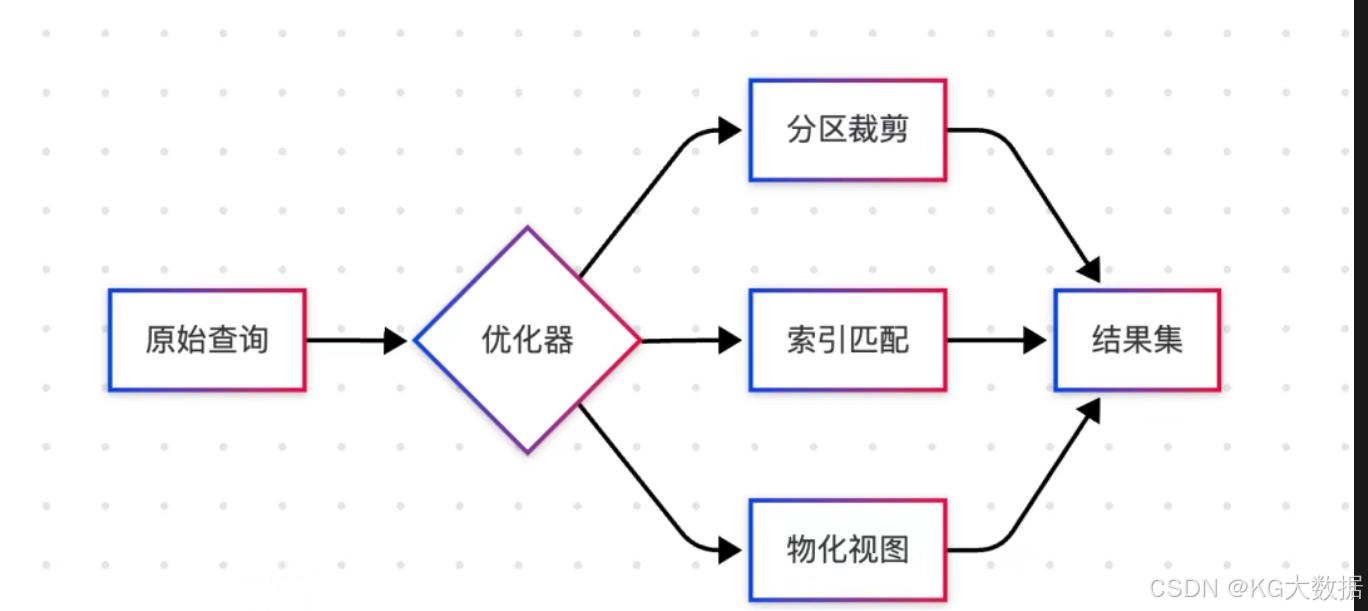
分析查询
在分析查询场景下,Doris 具备以下优势:
- 存储设计
• 按时间+设备ID分区,提升查询效率
• 合理设置副本数保证数据可靠性
• 通过冷热分离降低存储成本 - 查询优化
• 使用 Bitmap 索引加速过滤
• 通过AGG表计算常用简单指标
• 支持多维度分析的异步物化视图 - 数据完整性
• 通过事务保证数据一致性
• 支持数据的更新和删除
• 提供数据版本控制机制
模型训练
在 Doris 中,为解决数据传输的种种难点,社区在这方面提供了 Arrow Flight 数据传输链路来处理该问题。
Arrow Flight 是一个由 Apache Arrow 社区开发的与数据库系统交互的协议,用于 ADBC 客户端使用 Arrow 数据格式与实现了 Arrow Flight SQL 协议的数据库交互,具有 Arrow Flight 的速度优势以及 JDBC/ODBC 的易用性。
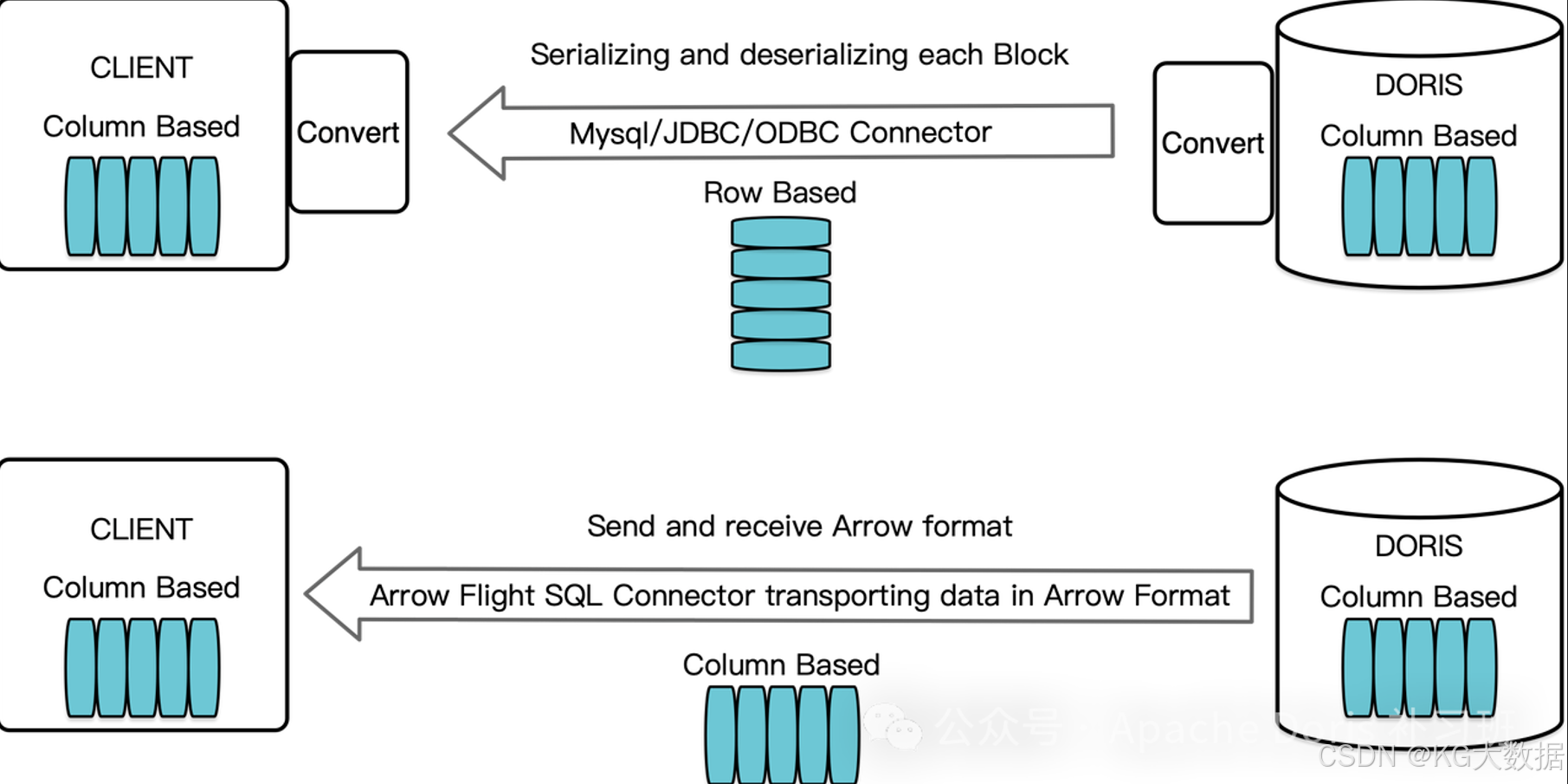
同时 Arrow Flight 还同时支持 ADBC 和 JDBC 两种传输协议,如果要实现满速抽取,那可使用 ADBC 协议来连通数据库,该协议可通过列加载的方式大批量的拿取数据,而不用做行列转化消耗时间。若在代码中已使用 JDBC 协议完成大部分的功能开发,希望能延续整个项目的开发习惯,那也可使用 Arrow Flight 的 JDBC 传输方案,同比使用 MySQL 的 JDBC Driver 进行数据传输,Arrow Flight 的 JDBC 数据传输速度虽然没有 ADBC 快,但也比 MySQL JDBC Driver 快 2-10 倍。
通过 GitHub 这个 Feature 的性能对比可知:
- 只需将连接字符串从 jdbc:mysql:// 替换成 jdbc:arrow-flight-sql://,在不同数据类型上可获得 2 到 10 倍的读取性能提升。
- 对所有连接方式而言,JDK 17 都比 JDK 1.8 的读取性能最少提升提升 10%,最多提升100%。
- 当读取数据量非常大时,使用 Arrow Flight SQL 将比 jdbc:mysql:// 使用更少的内存,在上面的测试中读取 6 亿行 Decimal Column,Arrow Flight SQL 只用了不到十分之一的内存。
技术部分
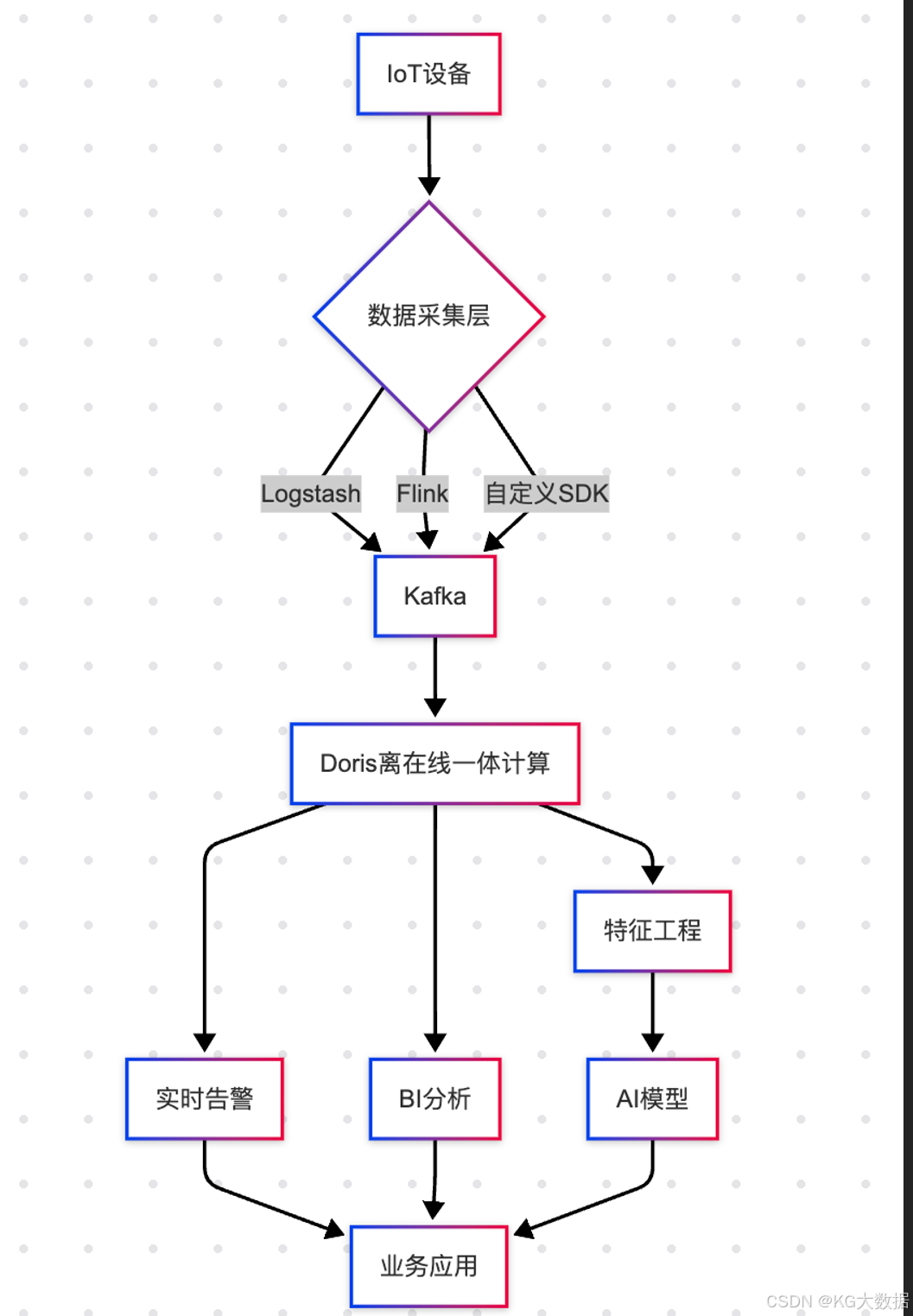
数据接入
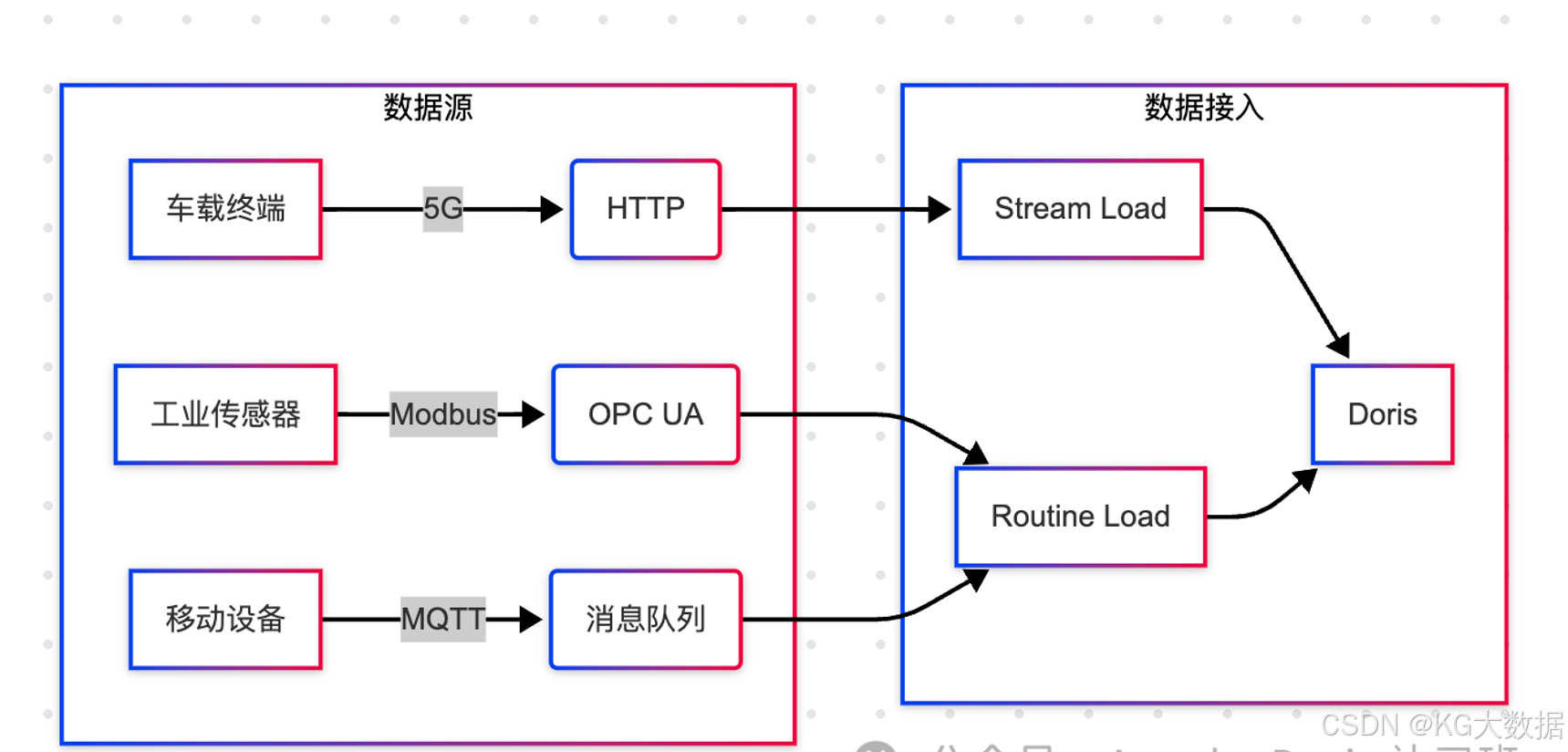
一般而言,除一些特殊的行业(如军工、政府单位等)物联网采集的数据会以二进制加密的方式进行传输,在终端通过相应的解密操作来拿到正确的报文以外,大部分的IOT场景,以非加密场景居多,这类报文会以 Json 字符串或者 Xml 半结构化数据进行传输,通过 Logstash、Fluentd、Logtail 之类的日志采集工具进行采集,然后再转存至下游消息中间件或数据处理引擎中。
可想而知在数据采集阶段,很可能面临的情况是不同项目、不同物理硬件、不同厂商提供的采集工具、采集报文格式、数据加解密方案等,都可能是完全不一样的,如果处理的数据源过多的话,还需构建一个统一的数据处理平台来完成数据接入。
若只有1-2种数据源,可直接对接接入即可。
Logstash
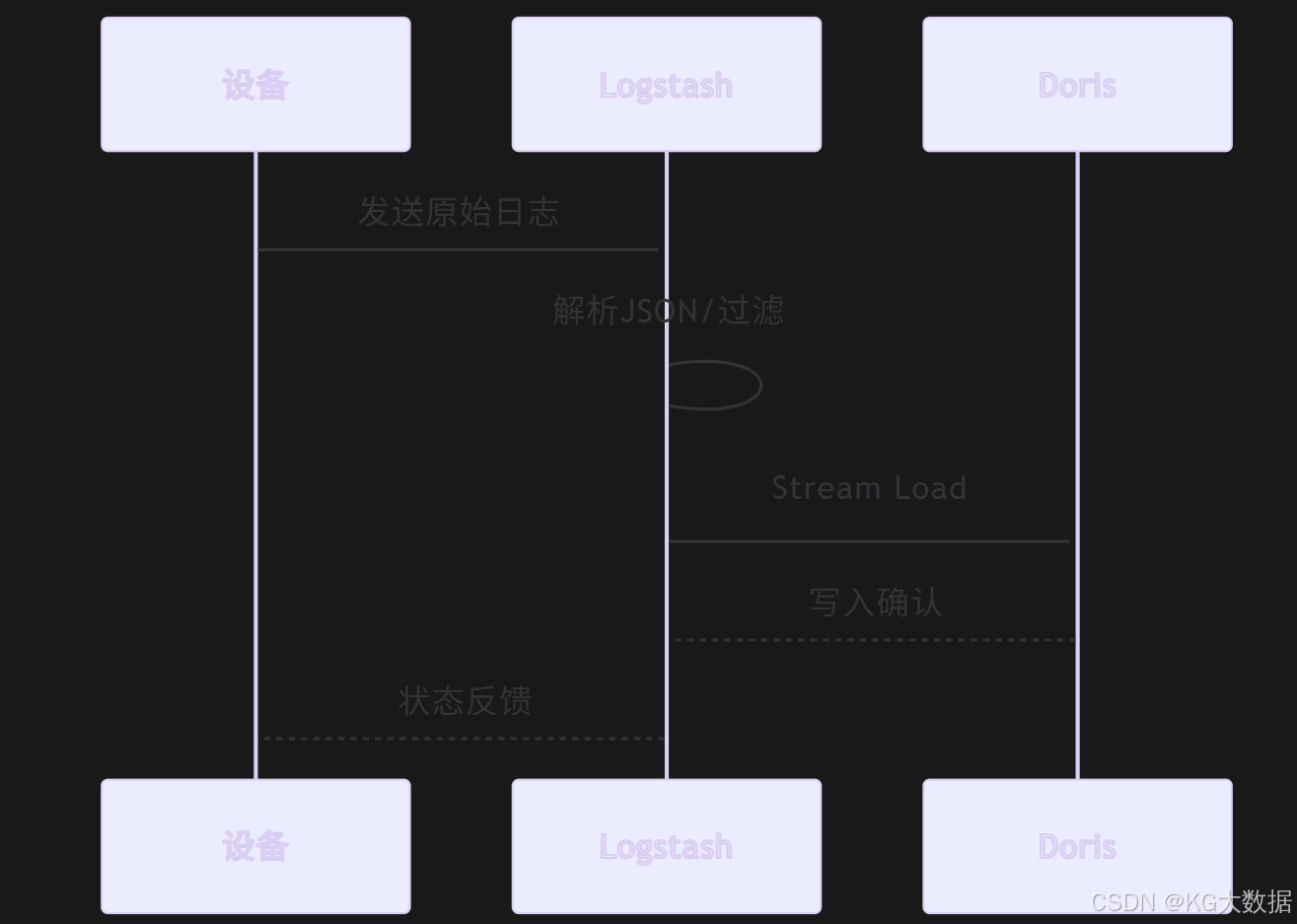
Logstash 作为最常用的日志采集工具之一,可以通过以下配置方式接入 Doris:
- 输入配置
input {
file {
path => "/path/to/log/*.log"
type => "iot_log"
}
}
- 过滤处理
filter {
json {
source => "message"
}
date {
match => ["timestamp", "yyyy-MM-dd HH:mm:ss"]
target => "@timestamp"
}
}
- 输出到 Doris
output {
http {
url => "http://doris_host:8030/api/db/table/_stream_load"
http_method => "PUT"
format => "json"
}
}
Voter
Voter 作为轻量级数据采集工具,可通过以下方式实现端到端数据采集:
- 采集端配置
sensors:
-name:temperature
type:analog
pin:23
interval:100ms
-name:vibration
type:digital
pin:7
trigger:edge
output:
type:doris
endpoint:doris-gateway:8030
batch_size:1000
flush_interval: 1s
- 数据转换规则
def transform(payload):
return {
"ts": datetime.now().isoformat(),
"device_id": payload['device_id'],
"metrics": {
"temp": round(payload['temperature'], 1),
"vib": payload['vibration'] * 0.1
}
}
kafka
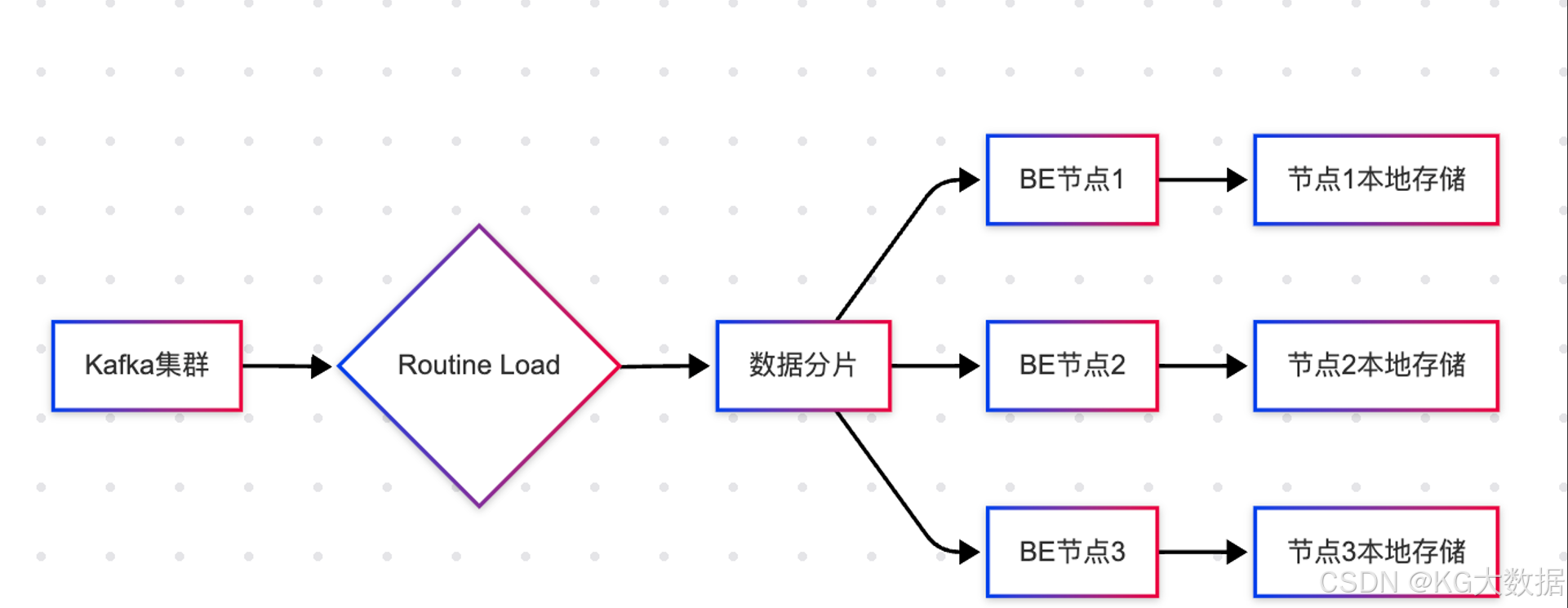
Kafka 作为消息中间件接入 Doris 的最佳实践:
- 多消费者组并行消费
CREATE ROUTINE LOAD db.iot_kafka_load ON iot_metrics
PROPERTIES
(
"desired_concurrent_number" = "4", -- 并行度
"max_batch_interval" = "20", -- 最大消费间隔
"max_batch_rows" = "200000", -- 单批最大行数
"strict_mode" = "false"
)
FROM KAFKA
(
"kafka_broker_list" = "broker1:9092,broker2:9092",
"kafka_topic" = "iot-raw-data",
"property.security.protocol" = "sasl_ssl",
"property.sasl.mechanism" = "PLAIN",
"property.sasl.username" = "doris",
"property.sasl.password" = "encrypted_password"
);
- 复杂JSON处理
"jsonpaths" = "['$.device.id', '$.ts', '$.data.temperature', '$.data.vibration']",
"json_root" = "$.payload",
"strip_outer_array" = "true"
- 错误处理机制
"max_error_number" = "1000", -- 最大容错数
"load_to_single_tablet" = "false", -- 分散写入压力
"format" = "json",
"num_as_string" = "true" -- 处理大整数
性能优化建议:
- 单个Routine Load处理能力:约50MB/s
- 推荐每个BE节点配置2-3个消费线程
- 使用Snappy压缩降低网络传输开销
StreamLoad
对于自定义协议数据接入,Stream Load 提供灵活接入方式:
def stream_load(data):
headers = {
"Authorization": "Basic " + base64.b64encode(f"{username}:{password}".encode()).decode(),
"format": "json",
"strip_outer_array": "true"
}
response = requests.put(
url='http://fe_host:8030/api/db/table/_stream_load',
headers=headers,
data=json.dumps(data)
)
if response.json()['Status'] != 'Success':
raise Exception("Load failed: " + response.text)
flink
Flink 实时处理管道配置示例:
DorisSink<DeviceData> sink = DorisSink.<DeviceData>builder()
.setFenodes("fe_host:8030")
.setUsername("user")
.setPassword("pass")
.setTableIdentifier("db.table")
.setSerializer(new DeviceDataSerializer())
.build();
env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(), "Kafka Source")
.process(new MetricParser())
.sinkTo(sink);
数据存储
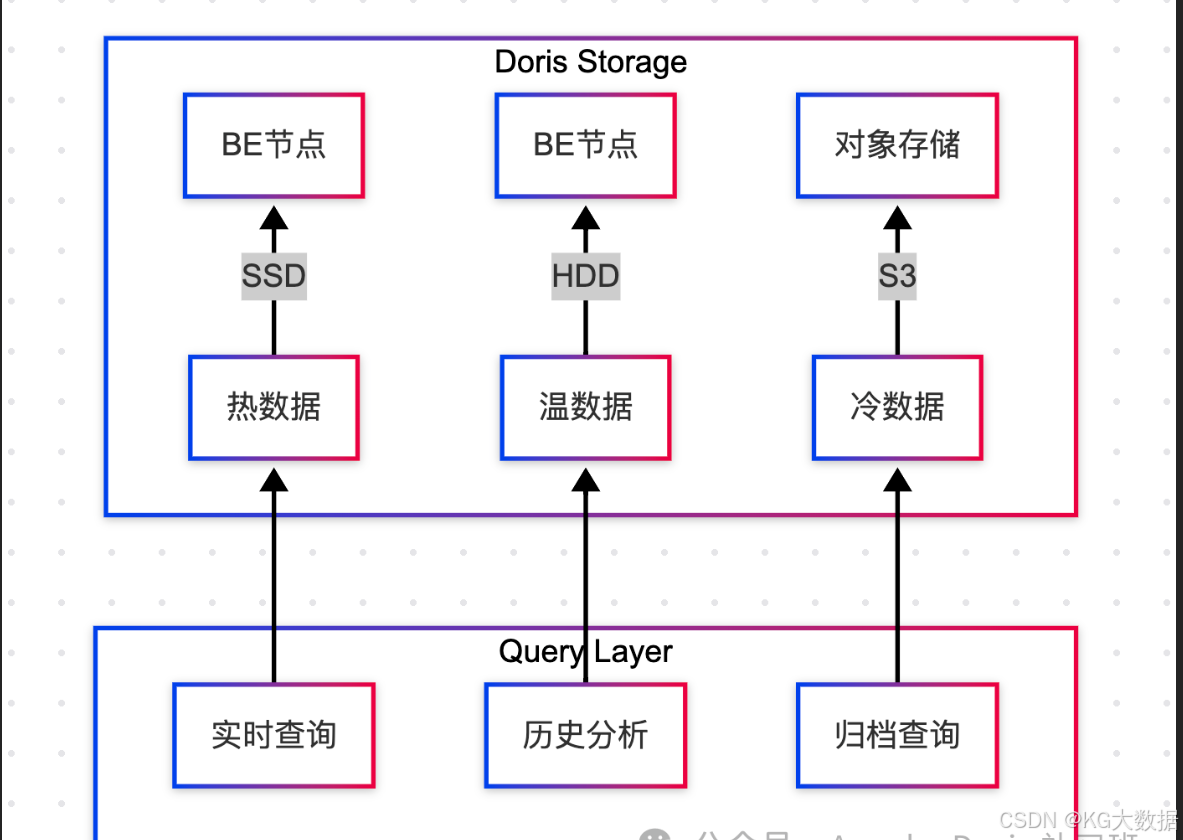
在 Doris 中针对 IOT 场景的存储设计建议:
- 表结构设计
CREATE TABLE iot_metrics
(
`timestamp` DATETIME,
`device_id` VARCHAR(32),
`metrics` JSON,
`tags` BITMAP
)
PARTITION BY RANGE(`timestamp`)
(
PARTITION p1 VALUES LESS THAN ('2024-01-01'),
PARTITION p2 VALUES LESS THAN ('2024-02-01')
)
DISTRIBUTED BY HASH(`device_id`) BUCKETS 32;
- 物化视图设计
CREATE MATERIALIZED VIEW mv_hourly_agg
REFRESH ASYNC
AS SELECT
device_id,
DATE_TRUNC(timestamp, 'HOUR') as hour,
COUNT(*) as count,
AVG(metrics.temperature) as avg_temp
FROM iot_metrics
GROUP BY device_id, DATE_TRUNC(timestamp, 'HOUR');
数据加工
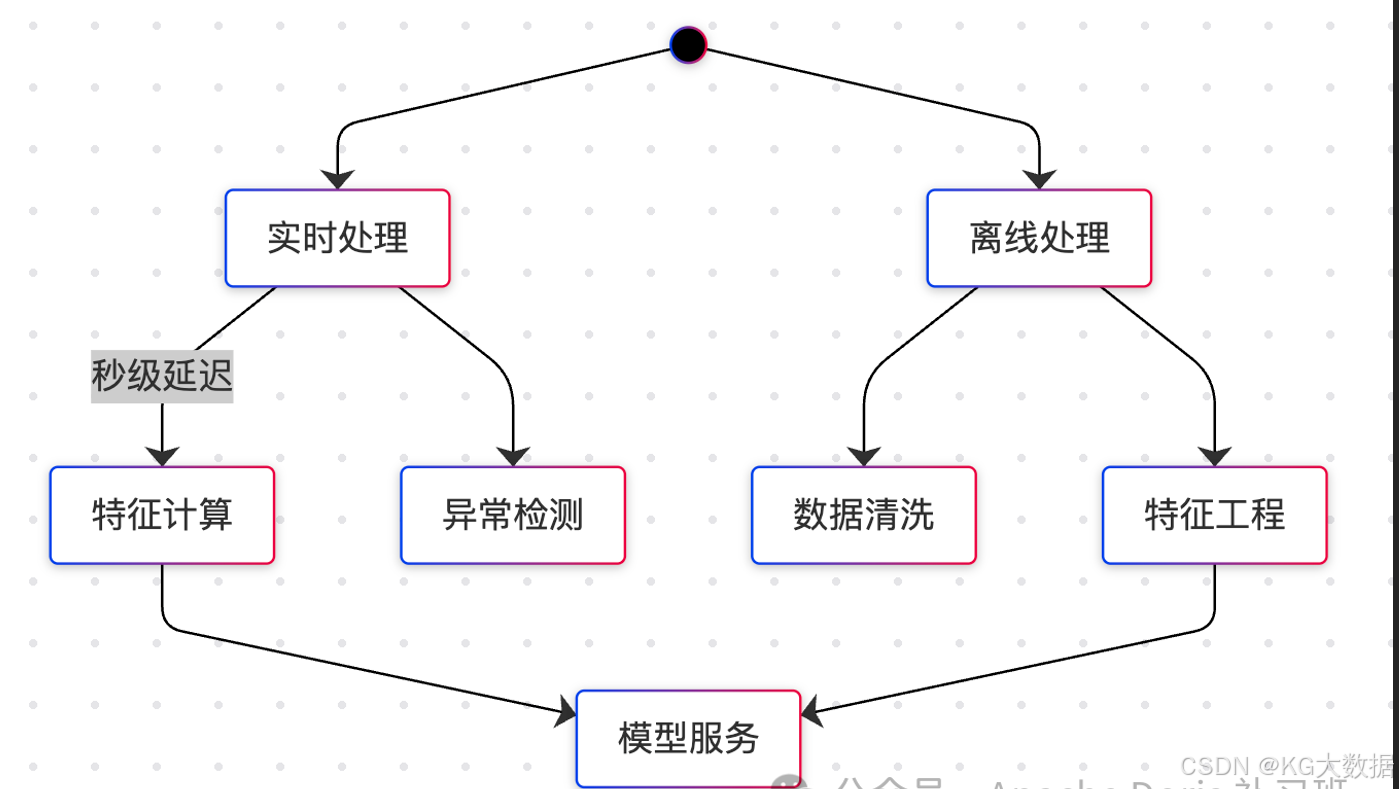
针对 IOT 数据的常见加工场景:
- 实时计算
• 使用 Flink 进行实时流计算
• 通过 UDF 实现复杂业务逻辑
• 结合 Doris 物化视图做微批增量计算 - 离线计算
• 通过 SQL 进行数据清洗转换
• 使用 INSERT INTO SELECT 进行大规模数据处理
• 定期运行 ETL 任务更新数据
数据查询
实时轨迹追踪
-- 实时车辆位置追踪
SELECT
device_id,
metrics.longitude,
metrics.latitude,
metrics.speed,
NOW() -timestampAS latency
FROM iot_metrics
WHERE
device_id ='VIN_1001'
AND timestamp >= NOW() - INTERVAL 30 SECOND
ORDERBY timestamp DESC
LIMIT 10;
历史数据回溯
-- 事故前后5分钟数据回溯
WITH accident_time AS (
SELECT MIN(timestamp) AS accident_ts
FROM iot_metrics
WHERE device_id ='VIN_2002'AND metrics.collision =true
)
SELECT *
FROM iot_metrics
WHERE device_id ='VIN_2002'
AND timestamp BETWEEN
(SELECT accident_ts - INTERVAL 5 MINUTEFROM accident_time)
AND
(SELECT accident_ts + INTERVAL 5 MINUTEFROM accident_time);
模型训练
特征工程
-- 设备健康特征提取
CREATE MATERIALIZED VIEW device_health_features
REFRESH ASYNC EVERY 1 HOUR
AS
SELECT
device_id,
DATE_TRUNC('hour', timestamp) AS time_window,
AVG(metrics.temperature) AS avg_temp,
STDDEV(metrics.vibration) AS vib_stddev,
COUNT_IF(metrics.error_code ISNOT NULL) AS error_count,
MAX(metrics.pressure) -MIN(metrics.pressure) AS pressure_range
FROM iot_metrics
GROUPBY device_id, time_window;
模型服务
from doris.flight import connect
# 建立Arrow Flight连接
conn = connect(host='doris-fe', port=9030, user='ml', password='ml@2024')
# 批量获取训练数据
reader = conn.execute("SELECT * FROM device_health_features")
batch = reader.read_all()
# 转换为Pandas DataFrame
df = batch.to_pandas()
# 训练XGBoost模型
model = xgb.train(params, xgb.DMatrix(df[features], label=df['label']))
# 将模型特征回写Doris
model_features = pd.DataFrame({
'model_version': ['v1.2'],
'features': [','.join(features)],
'importance': [model.feature_importances_.tolist()]
})
conn.upload("model_features", model_features)
业务部分
在实际业务落地过程中,Doris 需要与具体行业场景深度结合。我们选取车联网和工业互联网两个典型领域,通过具体场景说明技术实现方案。
车联网
行业背景
现代智能汽车每天产生约20MB的传感器数据,包含定位、车况、驾驶行为等200+种指标。车企需要实时处理这些数据来实现安全监控、用户体验优化等核心业务。
某新能源车企面临以下挑战:
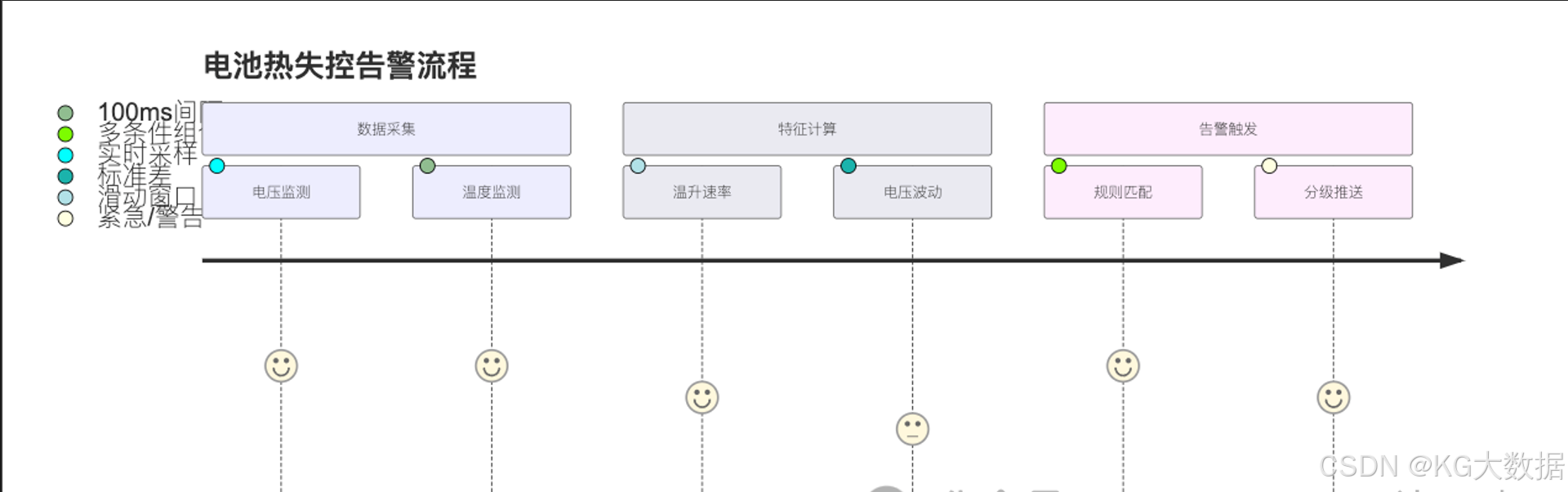
- 电池热失控预警延迟需从分钟级优化至秒级
- 误报率高达15%导致用户投诉增多
- 传统架构无法支撑百万级车辆并发接入
业务演进

架构突破
城市交通治理新需求
- 突发拥堵识别:识别因事故导致的异常拥堵(如5分钟内区域车辆数激增300%)
- 潮汐车道优化:根据历史车流自动调整车道方向
- 应急车辆调度:为救护车规划最优避堵路线
数据挑战
- 千亿级位置点实时处理
- 复杂空间计算(如道路网格化)
- 多时间维度分析(实时/小时/日)
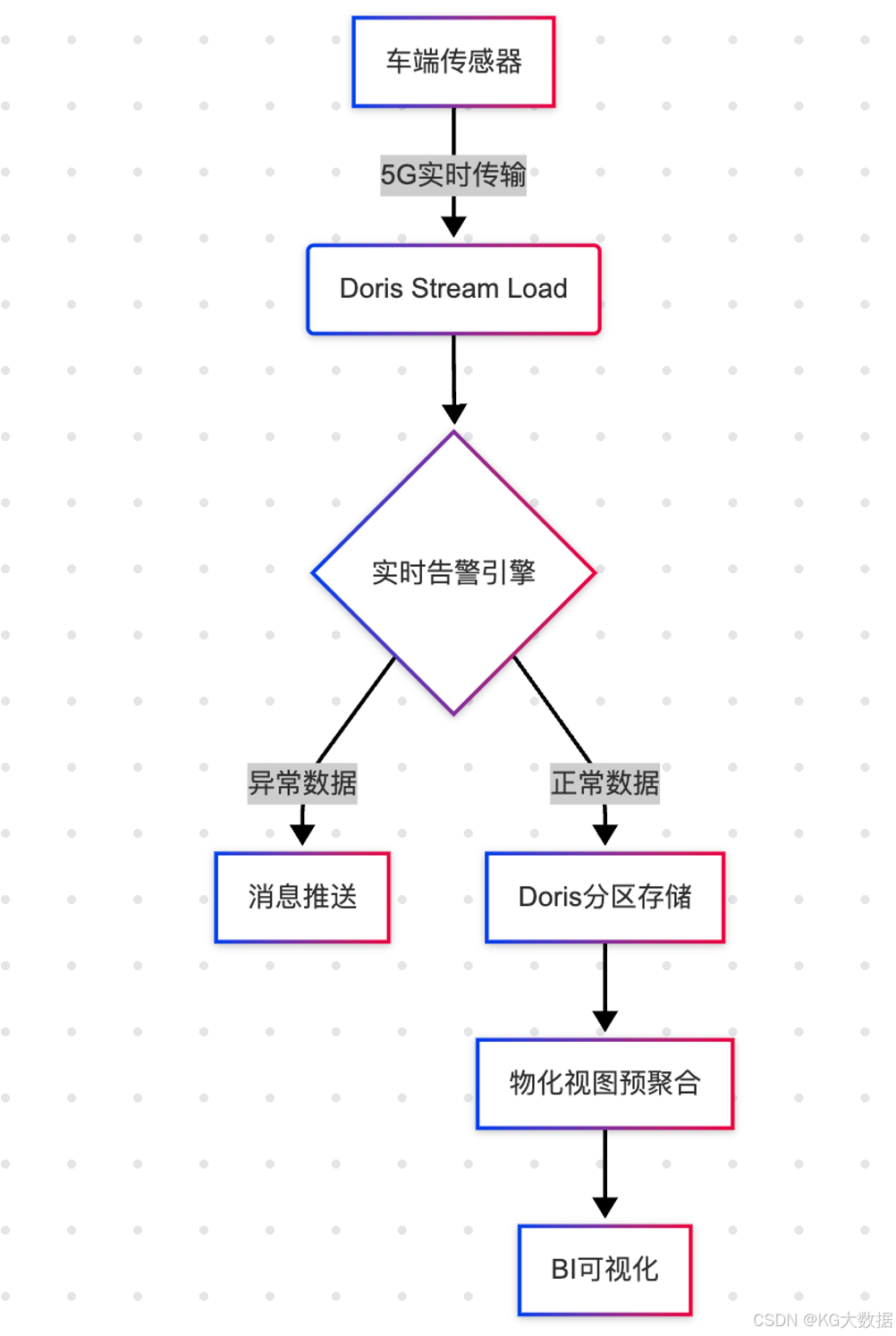
Doris解决方案
-- 动态拥堵指数计算
WITH grid_traffic AS (
SELECT
FLOOR(lng*100) AS grid_x,
FLOOR(lat*100) AS grid_y,
COUNT(*) AS vehicle_count,
AVG(speed) AS avg_speed
FROM realtime_location
WHERE ts >= NOW() -INTERVAL5MINUTE
GROUPBY 1,2
)
SELECT
grid_x, grid_y,
vehicle_count * (1- avg_speed/120) AS congestion_index
FROM grid_traffic
WHERE congestion_index >0.7;
落地效果
某省会城市部署后,早高峰通行效率提升18%
行车轨迹
典型需求
车辆失窃后,警方需要调取过去72小时的行车轨迹,还原车辆移动路径
数据特点
• 时间跨度大(3天)
• 数据密度高(每秒1条)
• 需要空间可视化
优化方案
- 按天分区+设备ID分桶
- 使用GEOMETRY类型存储坐标点
- 建立轨迹压缩物化视图
查询性能
72小时轨迹数据(约30万条)检索耗时<800ms
业务价值
基于驾驶行为分析实现UBI保险定价、智能座舱场景推荐等增值服务
特征计算
-- 急加速行为识别
SELECT
device_id,
COUNT_IF(accel>0.3) AS rapid_accel_count
FROM driving_behavior
WHERE time BETWEEN '2024-03-01' AND '2024-03-31'
GROUP BY 1;
应用效果
某保险公司理赔成本降低18%,用户风险分级准确率提升至89%
工业互联网
行业痛点:
工业设备数据具有高维度(2000+传感器)、强时序、多状态等特点,传统SCADA系统面临:
- 数据存储成本高(年增长PB级)
- 实时分析能力不足
- 厂级数据孤岛严重
制造业痛点分析
- 设备停机损失:单台CNC机床停机1小时损失≈$2000
- 维护成本高:传统定期维护造成30%以上资源浪费
- 工艺优化难:2000+参数组合难以人工调优
某汽车零部件工厂实践
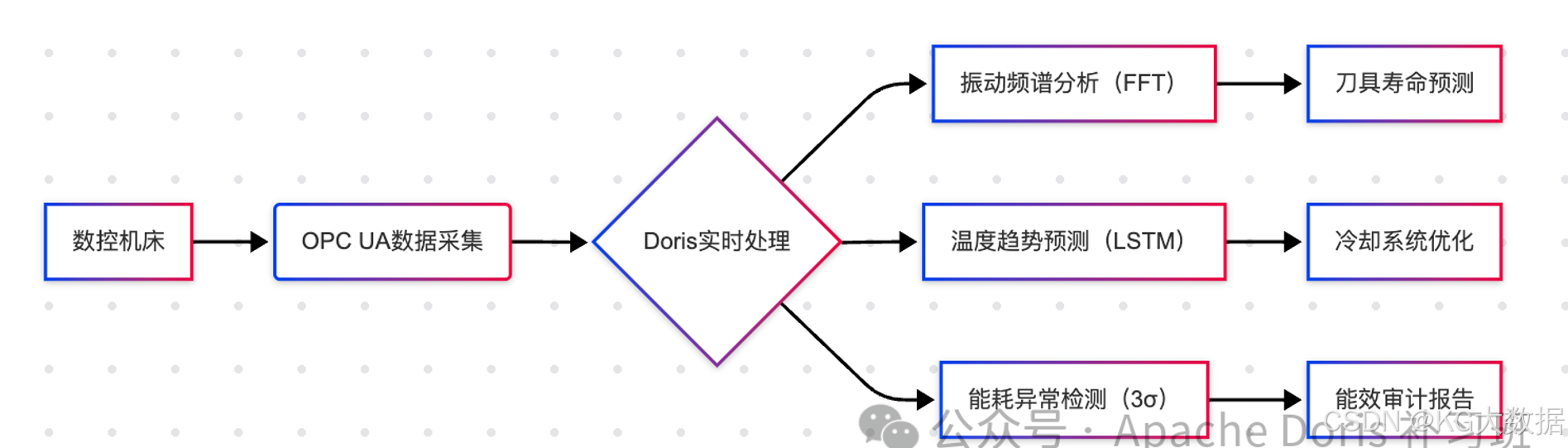
风电行业特殊需求
- 极端环境:海上风机需承受盐雾、高湿度等腐蚀
- 长周期检测:齿轮箱检测周期从3个月延长至1年
- 复合故障:同时存在齿轮磨损和轴承偏心等耦合故障
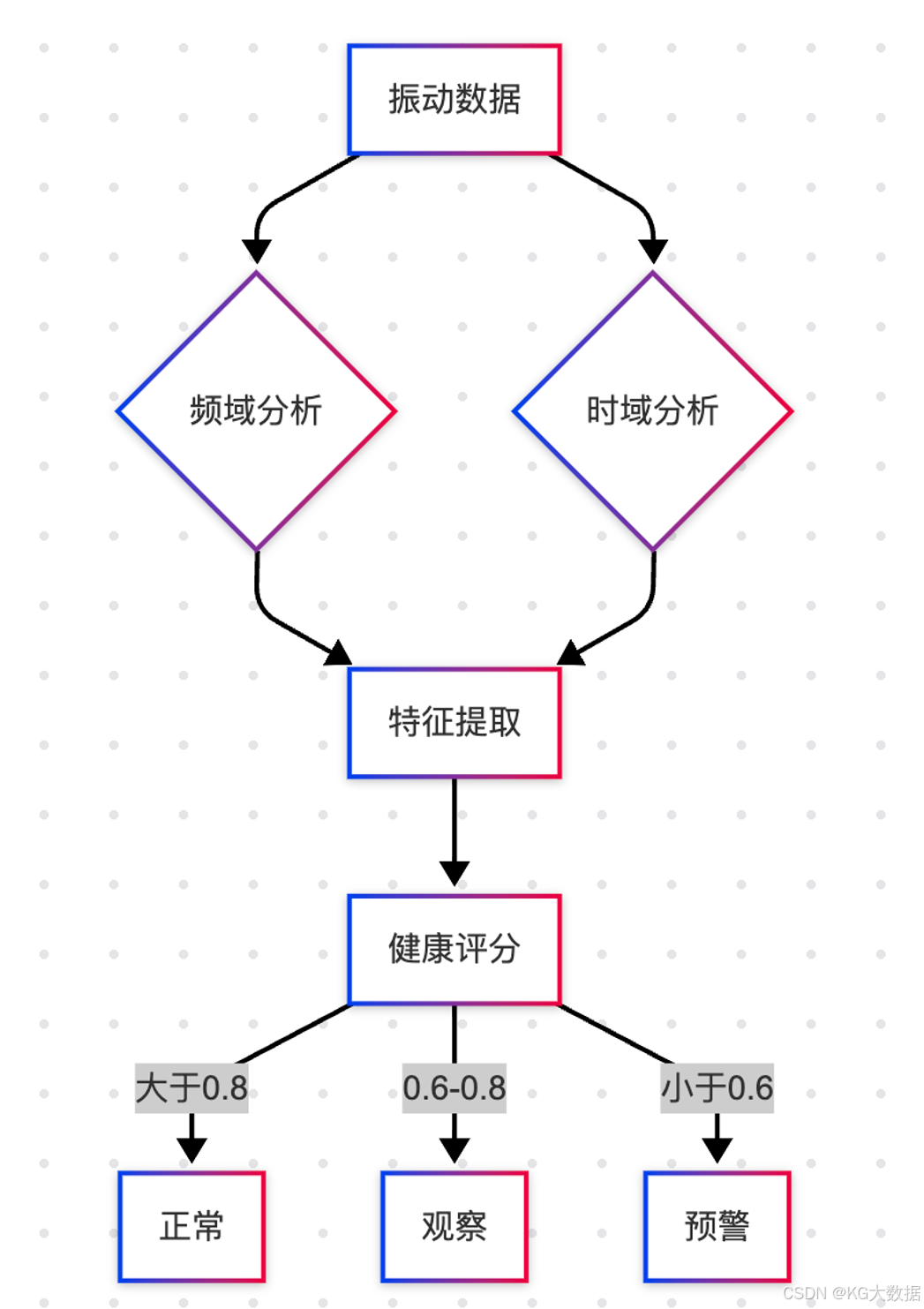
特征工程创新:
-- 多源传感器特征融合
CREATE MATERIALIZED VIEW gearbox_health REFRESH COMPLETE ON SCHEDULE EVERY 1 hour AS
SELECT
device_id,
time_bucket('10 minutes', ts) AS time_window,
AVG(vibration_x) +0.3*AVG(vibration_y) AS composite_vib,
WAVELET(vibration, 5) AS wavelet_coeff,
FFT(vibration, 2048)->'harmonics'AS freq_domain
FROM turbine_sensors
GROUP BY 1,2;
实施成果:某风场运维成本降低42%,故障识别准确率达95.3%
生产优化
案例背景:某半导体厂通过分析蚀刻机台数据,优化工艺参数提升良品率
实施步骤:
- 采集200+设备参数(温度、气压、RF功率等)
- 建立生产批次与设备参数的关联分析
- 通过回归分析找到最优参数组合
SQL实现:
-- 参数相关性分析
SELECT
CORR(chamber_pressure, defect_rate) AS pressure_corr,
CORR(plasma_power, defect_rate) AS power_corr
FROM production_batches
WHERE process_step = 'etching';
成果:关键工序良品率从92.4%提升至95.7%
能耗管理
企业需求:某钢铁集团需实现分厂、工序、设备三级能耗监控,目标降低综合能耗5%
方案设计:
- 建立层次化能耗模型
- 实时监测异常能耗
- 同比环比分析
核心逻辑:
-- 工序能耗异常检测
WITH current_energy AS (
SELECT process_line, SUM(power) AS total
FROM energy_stream
WHERE ts >= NOW() -INTERVAL15MINUTE
GROUP BY 1
),
historical_avg AS (
SELECT process_line, AVG(power) AS avg_power
FROM energy_history
WHERE time_range ='same_day_last_week'
GROUP BY 1
)
SELECT a.process_line, a.total, b.avg_power
FROM current_energy a
JOIN historical_avg b ON a.process_line = b.process_line
WHERE a.total > b.avg_power *1.2;
成效:年节约电费超数百万元
行业趋势与展望
技术融合方向
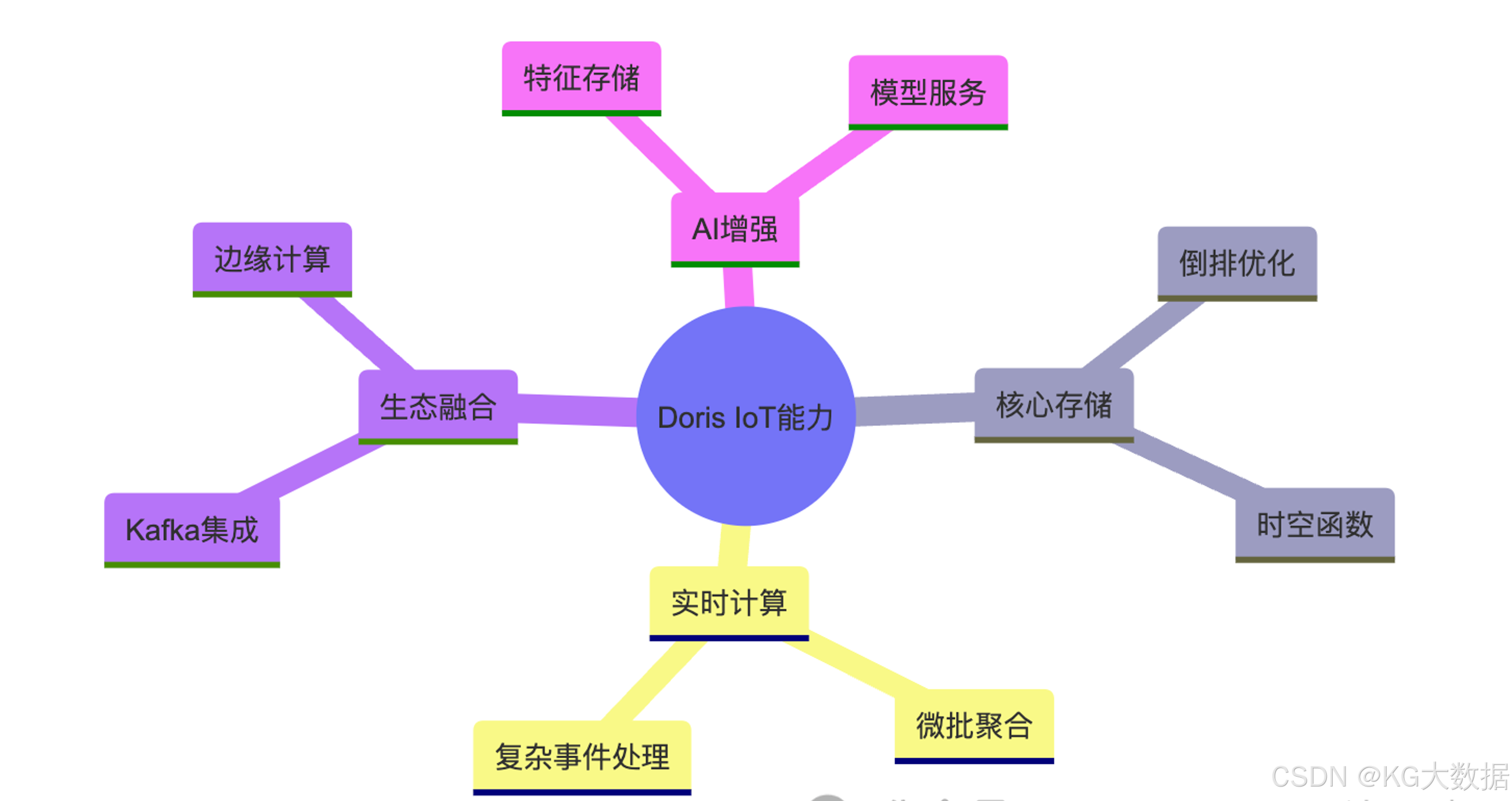
- 边缘智能:Doris与边缘计算框架(如KubeEdge)协同
- 数字孪生:实时数据驱动3D设备建模
- 因果推断:基于时序数据的根因分析
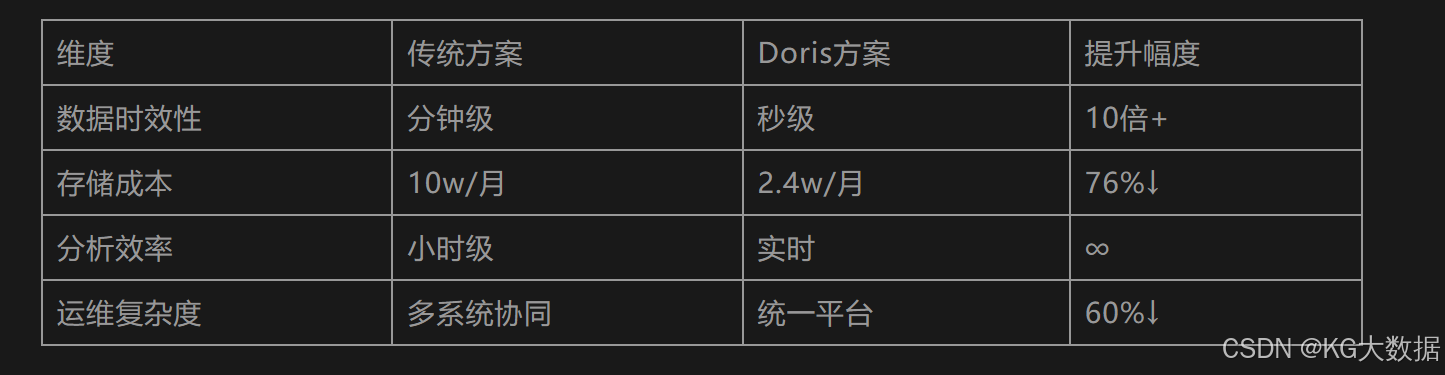
商业价值矩阵
小结
Apache Doris 在 IOT 场景中具有以下优势:
- 高性能的数据写入和查询能力
- 灵活的存储结构和计算能力
- 完善的生态系统集成能力
- 丰富的数据处理和分析功能
通过合理的架构设计和优化配置,Apache Doris 凭借其高性能、易扩展的特性,已成为 IoT 数据平台的核心组件,统一的存储与计算架构,企业可显著降低运维复杂度,同时满足实时告警、复杂分析与模型训练的全场景需求。未来,随着 Doris 生态的持续完善(如边缘计算协同和 AI 协同),其在 IoT 领域的实践将更加深入。

















 974
974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









