




目录
- 1- Spark 的运行流程?
- 2- Spark 有哪些组件?
- 3- Spark 中的 RDD 机制理解吗?
- 4- RDD 中 reduceBykey 与 groupByKey 哪个性能好,为什么?
- 5- 介绍一下 cogroup rdd 实现原理,你在什么场景下用过这个 rdd?
- 6- 如何区分 RDD 的宽窄依赖?
- 7- 为什么要设计宽窄依赖?
- 8- DAG 是什么?
- 9- DAG 中为什么要划分 Stage?
- 10- 如何划分 DAG 的 stage?
- 11- DAG 划分为 Stage 的算法了解吗?
- 12- 对于 Spark 中的数据倾斜问题你有什么好的方案?
- 13- Spark 中的 OOM 问题?
- 14- Spark 中数据的位置是被谁管理的?
- 15- Spaek 程序执行,有时候默认为什么会产生很多 task,怎么修改默认 task 执行个数?
- 16- 介绍一下 join 操作优化经验?
- 17- Spark 与 MapReduce 的 Shuffle 的区别?
- 18- Spark SQL 执行的流程?
- 19- Spark SQL 是如何将数据写到 Hive 表的?
- 20- 通常来说,Spark 与 MapReduce 相比,Spark 运行效率更高。请说明效率更高来源于 Spark 内置的哪些机制?
- 21- Hadoop 和 Spark 的相同点和不同点?
- 22- Hadoop 和 Spark 使用场景?
- 23- Spark 如何保证宕机迅速恢复?
- 24- RDD 持久化原理?
- 25- Checkpoint 检查点机制?
- 26- Checkpoint 和持久化机制的区别?
- 27- Spark Streaming 以及基本工作原理?
- 28- DStream 以及基本工作原理?
- 29- Spark Streaming 整合 Kafka 的两种模式?
- 30- Spark 主备切换机制原理知道吗?
- 31- Spark 解决了 Hadoop 的哪些问题?
- 32- 数据倾斜的产生和解决办法?
- 33- 你用 Spark Sql 处理的时候, 处理过程中用的 DataFrame 还是直接写的 Sql?为什么?
- 34- Spark Master HA 主从切换过程不会影响到集群已有作业的运行,为什么?
- 35- Spark Master 使用 Zookeeper 进行 HA,有哪些源数据保存到 Zookeeper 里面?
1- Spark 的运行流程?
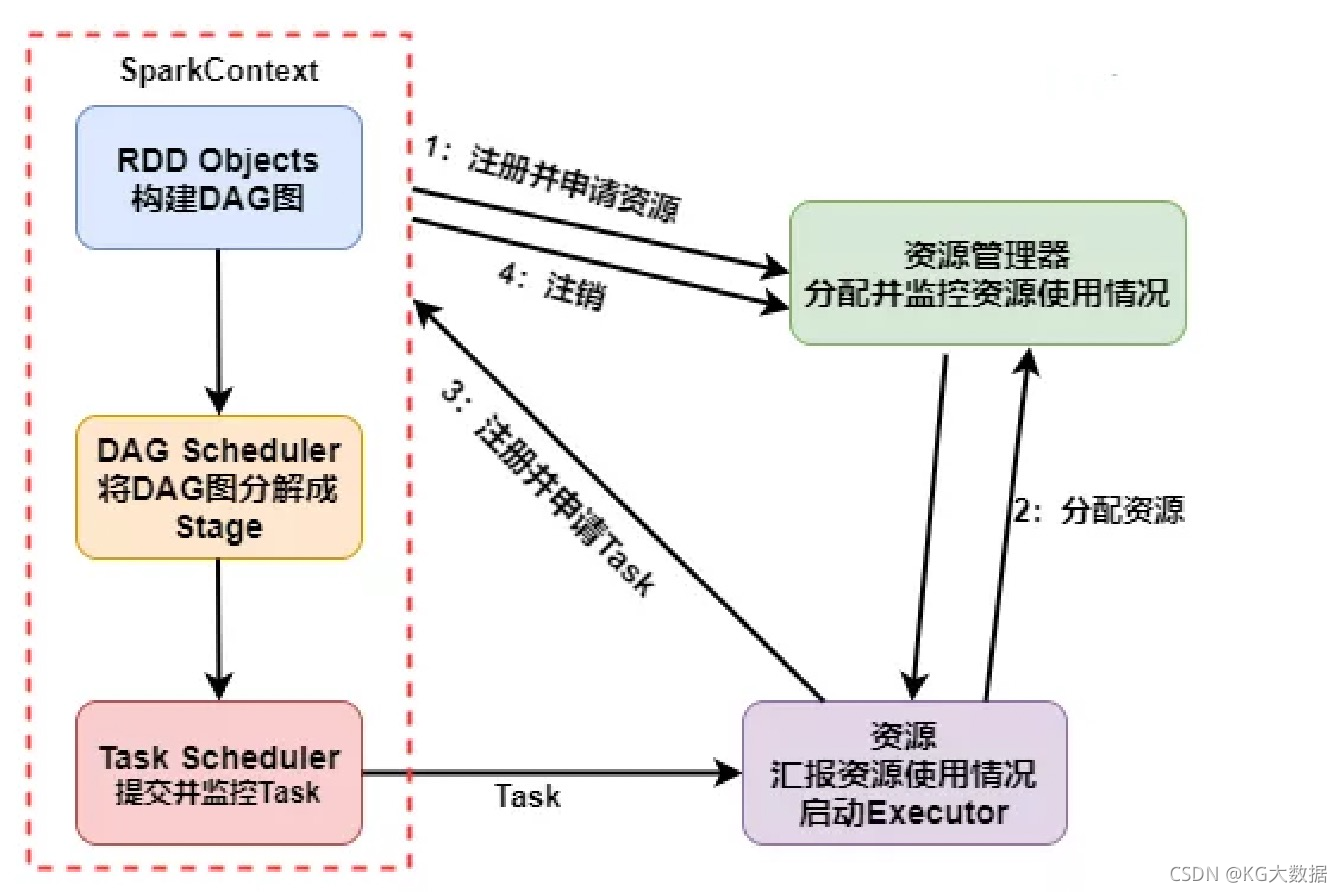
具体运行流程如下:
- SparkContext 向资源管理器注册并向资源管理器申请运行 Executor。
- 资源管理器分配 Executor,然后资源管理器启动 Executor。
- Executor 发送心跳至资源管理器。
- SparkContext 构建 DAG 有向无环图。
- 将 DAG 分解成 Stage(TaskSet)。
- 把 Stage 发送给 TaskScheduler。
- Executor 向 SparkContext 申请 Task。
- TaskScheduler 将 Task 发送给 Executor 运行。
- 同时 SparkContext 将应用程序代码发放给 Executor。
- Task 在 Executor 上运行,运行完毕释放所有资源。
2- Spark 有哪些组件?
- master:管理集群和节点,不参与计算。
- worker:计算节点,进程本身不参与计算,和 master 汇报。
- Driver:运行程序的 main 方法,创建 spark context 对象。
- spark context:控制整个 application 的生命周期,包括 dagsheduler 和 task scheduler 等组件。
- client:用户提交程序的入口。
3- Spark 中的 RDD 机制理解吗?
rdd 分布式弹性数据集,简单的理解成一种数据结构,是 spark 框架上的通用货币。所有算子都是基于 rdd 来执行的,不同的场景会有不同的 rdd 实现类,但是都可以进行互相转换。rdd 执行过程中会形成 dag 图,然后形成 lineage 保证容错性等。从物理的角度来看 rdd 存储的是 block 和 node 之间的映射。
RDD 是 spark 提供的核心抽象,全称为弹性分布式数据集。
RDD 在逻辑上是一个 hdfs 文件,在抽象上是一种元素集合,包含了数据。它是被分区的,分为多个分区,每个分区分布在集群中的不同结点上,从而让 RDD 中的数据可以被并行操作(分布式数据集)
比如有个 RDD 有 90W 数据,3 个 partition,则每个分区上有 30W 数据。RDD 通常通过 Hadoop 上的文件,即 HDFS 或者 HIVE 表来创建,还可以通过应用程序中的集合来创建;RDD 最重要的特性就是容错性,可以自动从节点失败中恢复过来。即如果某个结点上的 RDD partition 因为节点故障,导致数据丢失,那么 RDD 可以通过自己的数据来源重新计算该 partition。这一切对使用者都是透明的。
RDD 的数据默认存放在内存中,但是当内存资源不足时,spark 会自动将 RDD 数据写入磁盘。比如某结点内存只能处理 20W 数据,那么这 20W 数据就会放入内存中计算,剩下 10W 放到磁盘中。RDD 的弹性体现在于 RDD 上自动进行内存和磁盘之间权衡和切换的机制。
4- RDD 中 reduceBykey 与 groupByKey 哪个性能好,为什么?
reduceByKey:reduceByKey 会在结果发送至 reducer 之前会对每个 mapper 在本地进行 merge,有点类似于在 MapReduce 中的 combiner。这样做的好处在于,在 map 端进行一次 reduce 之后,数据量会大幅度减小,从而减小传输,保证 reduce 端能够更快的进行结果计算。
groupByKey:groupByKey 会对每一个 RDD 中的 value 值进行聚合形成一个序列(Iterator),此操作发生在 reduce 端,所以势必会将所有的数据通过网络进行传输,造成不必要的浪费。同时如果数据量十分大,可能还会造成 OutOfMemoryError。
所以在进行大量数据的 reduce 操作时候建议使用 reduceByKey。不仅可以提高速度,还可以防止使用 groupByKey 造成的内存溢出问题。
5- 介绍一下 cogroup rdd 实现原理,你在什么场景下用过这个 rdd?
cogroup:对多个(2~4)RDD 中的 KV 元素,每个 RDD 中相同 key 中的元素分别聚合成一个集合。
与 reduceByKey 不同的是:reduceByKey 针对一个 RDD中相同的 key 进行合并。而 cogroup 针对多个 RDD中相同的 key 的元素进行合并。
cogroup 的函数实现:这个实现根据要进行合并的两个 RDD 操作,生成一个 CoGroupedRDD 的实例,这个 RDD 的返回结果是把相同的 key 中两个 RDD 分别进行合并操作,最后返回的 RDD 的 value 是一个 Pair 的实例,这个实例包含两个 Iterable 的值,第一个值表示的是 RDD1 中相同 KEY 的值,第二个值表示的是 RDD2 中相同 key 的值。
由于做 cogroup 的操作,需要通过 partitioner 进行重新分区的操作,因此,执行这个流程时,需要执行一次 shuffle 的操作(如果要进行合并的两个 RDD 的都已经是 shuffle 后的 rdd,同时他们对应的 partitioner 相同时,就不需要执行 shuffle)。
场景:表关联查询或者处理重复的 key。
6- 如何区分 RDD 的宽窄依赖?
-
窄依赖:父 RDD 的一个分区只会被子 RDD 的一个分区依赖;
-
宽依赖:父 RDD 的一个分区会被子 RDD 的多个分区依赖(涉及到 shuffle)。
7- 为什么要设计宽窄依赖?
-
对于窄依赖:
窄依赖的多个分区可以并行计算;
窄依赖的一个分区的数据如果丢失只需要重新计算对应的分区的数据就可以了。 -
对于宽依赖:
划分 Stage(阶段)的依据:对于宽依赖,必须等到上一阶段计算完成才能计算下一阶段。
8- DAG 是什么?
DAG(Directed Acyclic Graph 有向无环图)指的是数据转换执行的过程,有方向,无闭环(其实就是 RDD 执行的流程);
原始的 RDD 通过一系列的转换操作就形成了 DAG 有向无环图,任务执行时,可以按照 DAG 的描述,执行真正的计算(数据被操作的一个过程)。
9- DAG 中为什么要划分 Stage?
并行计算。
一个复杂的业务逻辑如果有 shuffle,那么就意味着前面阶段产生结果后,才能执行下一个阶段,即下一个阶段的计算要依赖上一个阶段的数据。那么我们按照 shuffle 进行划分(也就是按照宽依赖就行划分),就可以将一个 DAG 划分成多个 Stage/阶段,在同一个 Stage 中,会有多个算子操作,可以形成一个 pipeline 流水线,流水线内的多个平行的分区可以并行执行。
10- 如何划分 DAG 的 stage?
对于窄依赖,partition 的转换处理在 stage 中完成计算,不划分(将窄依赖尽量放在在同一个 stage 中,可以实现流水线计算)。
对于宽依赖,由于有 shuffle 的存在,只能在父 RDD 处理完成后,才能开始接下来的计算,也就是说需要要划分 st
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1496
1496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









