




 本文详细介绍了SQL中的基本操作,包括创建表、插入数据(单行全列、多行指定列及冲突处理)、查询(全列、指定列、表达式、别名、去重),以及使用where、聚合函数(如COUNT、SUM、AVG等)、groupby、having和更新/删除数据的方法。
本文详细介绍了SQL中的基本操作,包括创建表、插入数据(单行全列、多行指定列及冲突处理)、查询(全列、指定列、表达式、别名、去重),以及使用where、聚合函数(如COUNT、SUM、AVG等)、groupby、having和更新/删除数据的方法。
文章目录
表的增删查改
创建表
create table people(
id int unsigned primary key not null,
name varchar(20) not null,
qq varchar(20),
gender char(1) default '男'
);
一列:列名+类型+约束条件

插入单行全列数据
insert into people values(100, '张三', '12345', '男');

插入多行指定列数据
不指定的列必须能够置为NULL,或者有默认值
insert into people(id, name, gender) values(101, '李四', '男'),
(102, '王五', '女');

插入失败则更新
如果出现了由于 主键 或者 唯一键 对应的值已经存在而导致插入失败,可以选择性的进行同步更新操作。
on duplicate key update XXX = XXX, XXX = XXX;
insert into people(id, name, qq, gender) values(101, '赵六', '123444', '女')
on duplicate key update name = '赵六', qq = '123444', gender = '女';
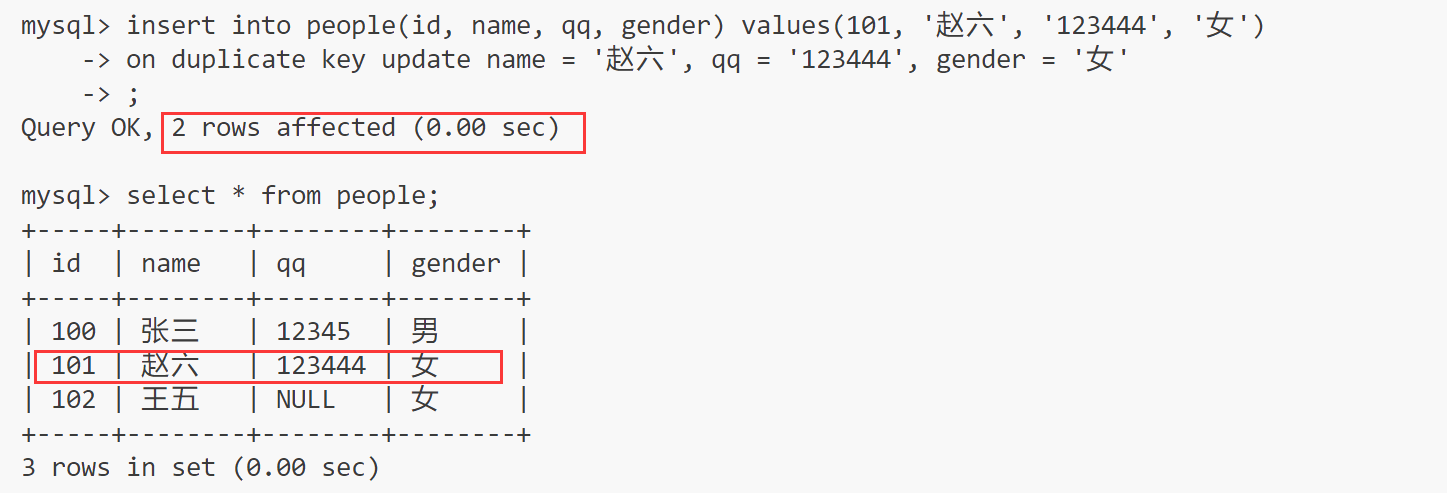
0 row affected: 表中有冲突数据,但冲突数据的值和 update 的值相等
1 row affected: 表中没有冲突数据,数据被插入
2 row affected: 表中有冲突数据,并且数据已经被更新
替换
如果出现了由于 主键 或者 唯一键 对应的值已经存在而导致插入失败,可以删除旧数据插入新数据
不再使用insert 选用 replace
replace into people(id, name, qq, gender) values(100, '赵六', '123444', '女');

1 row affected: 表中没有冲突数据,数据被插入
2 row affected: 表中有冲突数据,删除后重新插入
select
为了下列的演示方便,这里使用一张新的表,具体如图
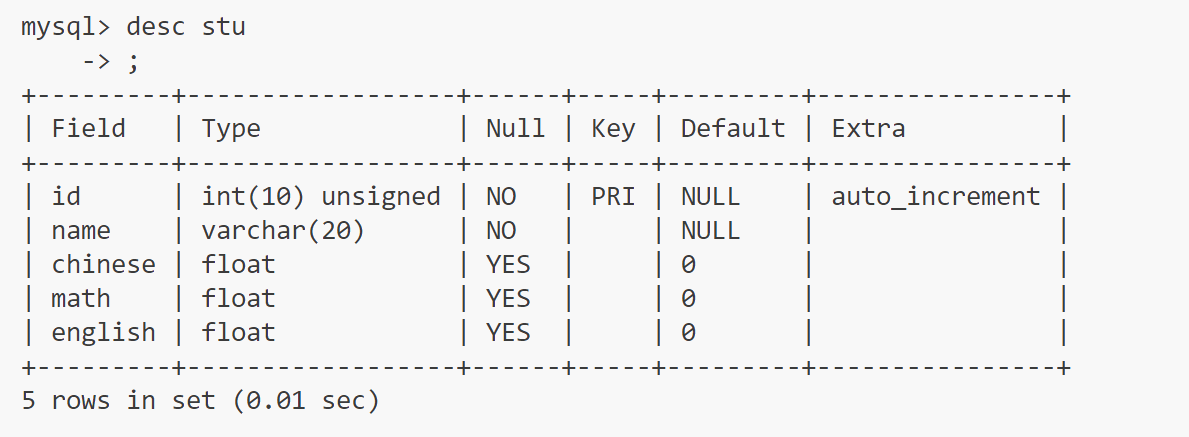
表中的数据可随意插入测试
全列查询
星号代表全部列,from后面跟上需要查询的表名
select * from people;

指定列查询
指定列的顺序不需要按定义表的顺序来
select id, name from people;

查询字段为表达式
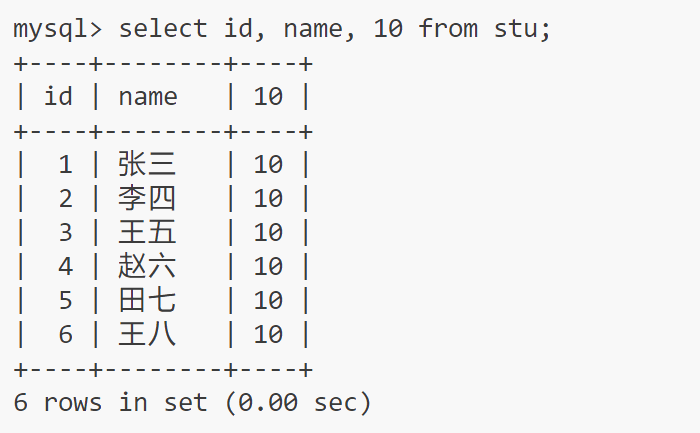
表达式不包含字段 :
select id, name, 10 from stu;
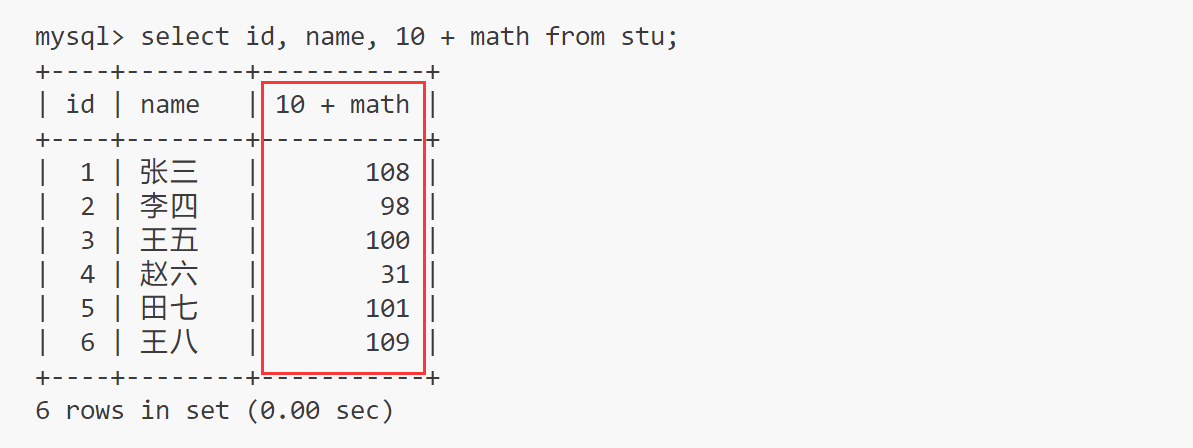
表达式包含一个字段:
select id, name, 10 + math from stu;
表达式包含多个字段:
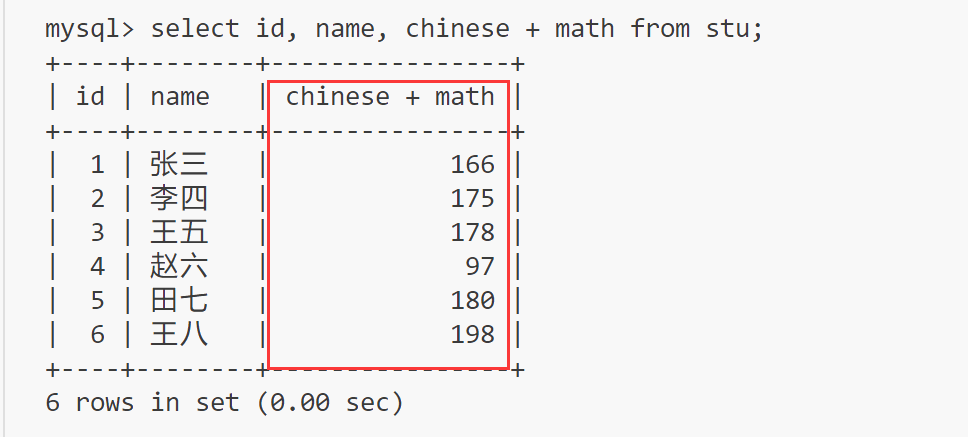
select id, name, chinese + math from stu;
为查询结果指定别名
select id, name, chinese + math + english 总成绩 from stu;

查询结果去重
select distinct math from stu;
where
where 可以指定条件去查询,包括运算符,逻辑运算符等
| 运算符 | 说明 |
|---|---|
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
| !=, <> | 不等于 |
| BETWEEN a0 AND a1 | 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1) |
| IN (option, …) | 如果是 option 中的任意一个,返回 TRUE(1) |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| LIKE | 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符 |
| 运算符 | 说明 |
|---|---|
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| OR | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| NOT | 条件为 TRUE(1),结果为 FALSE(0) |
数学小于60的
select name, math from stu where math < 60;

英语在70到100之间的
select name, english from stu where english >= 70 and english <= 100;

使用其他的逻辑运算符同理
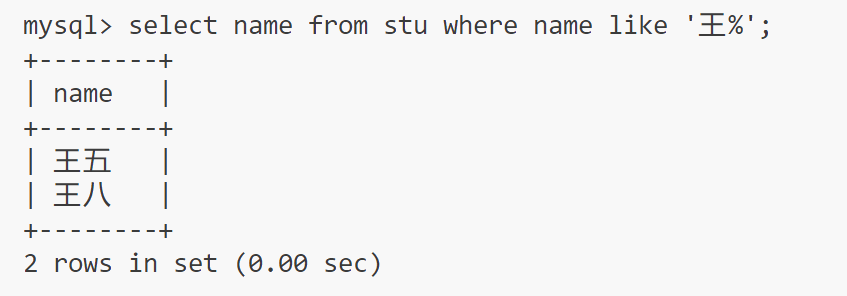
名字为王开头的
% 匹配任意多个(包括 0 个)任意字符
_ 匹配严格的一个任意字符,使用该符号后面只能有一个字符
select name from stu where name like '王%';
总分在 200 分以下的
需要特别注意别名不能用在 WHERE 条件中
select name, math + chinese + english 总分 from stu where math + chinese + english < 200;

语文成绩 > 80 并且不姓王的
select name, chinese from stu where chinese > 80 and name not like '王%';

结果排序
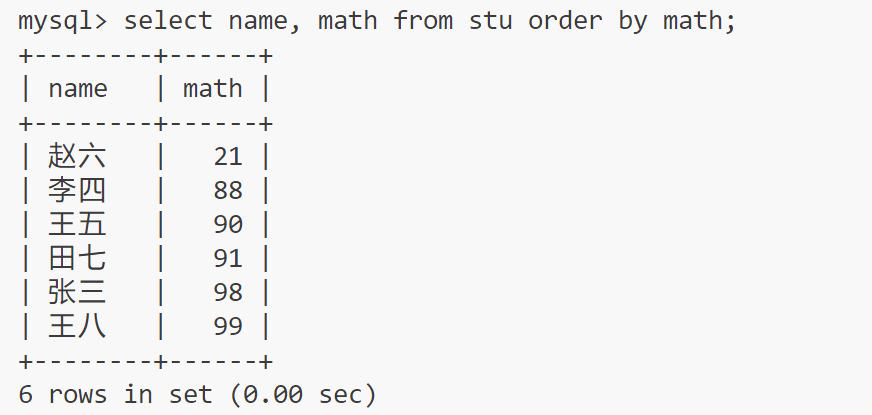
升序
order by XXX — XXX即为需要排序的列
NULL值比任何值都小
select name, math from stu order by math;
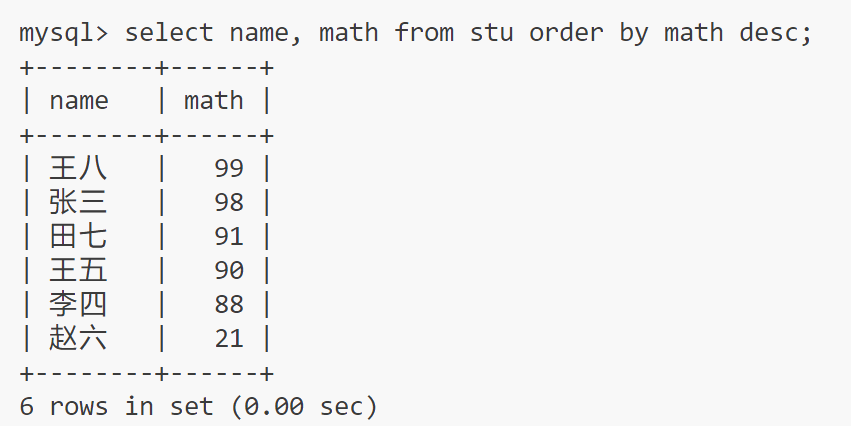
降序
order by XXX desc
select name, math from stu order by math desc;
筛选分页
可以指定从哪一列开始显示几行数据,
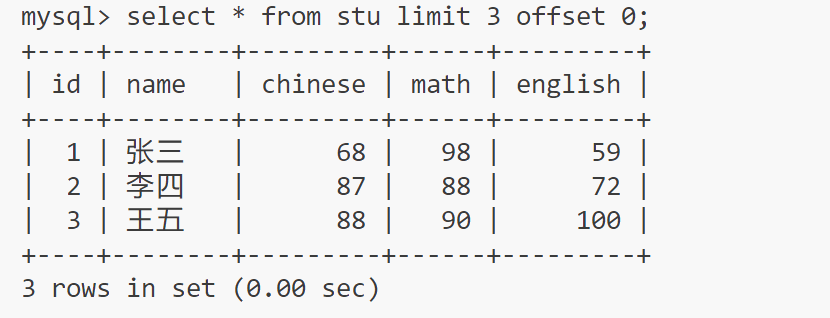
limit 跟上显示几行数据,offset 跟上开始的列
select * from stu limit 3 offset 0;
update
更新指定的数据
注意不支持+=的写法
update stu set math = math + 30;
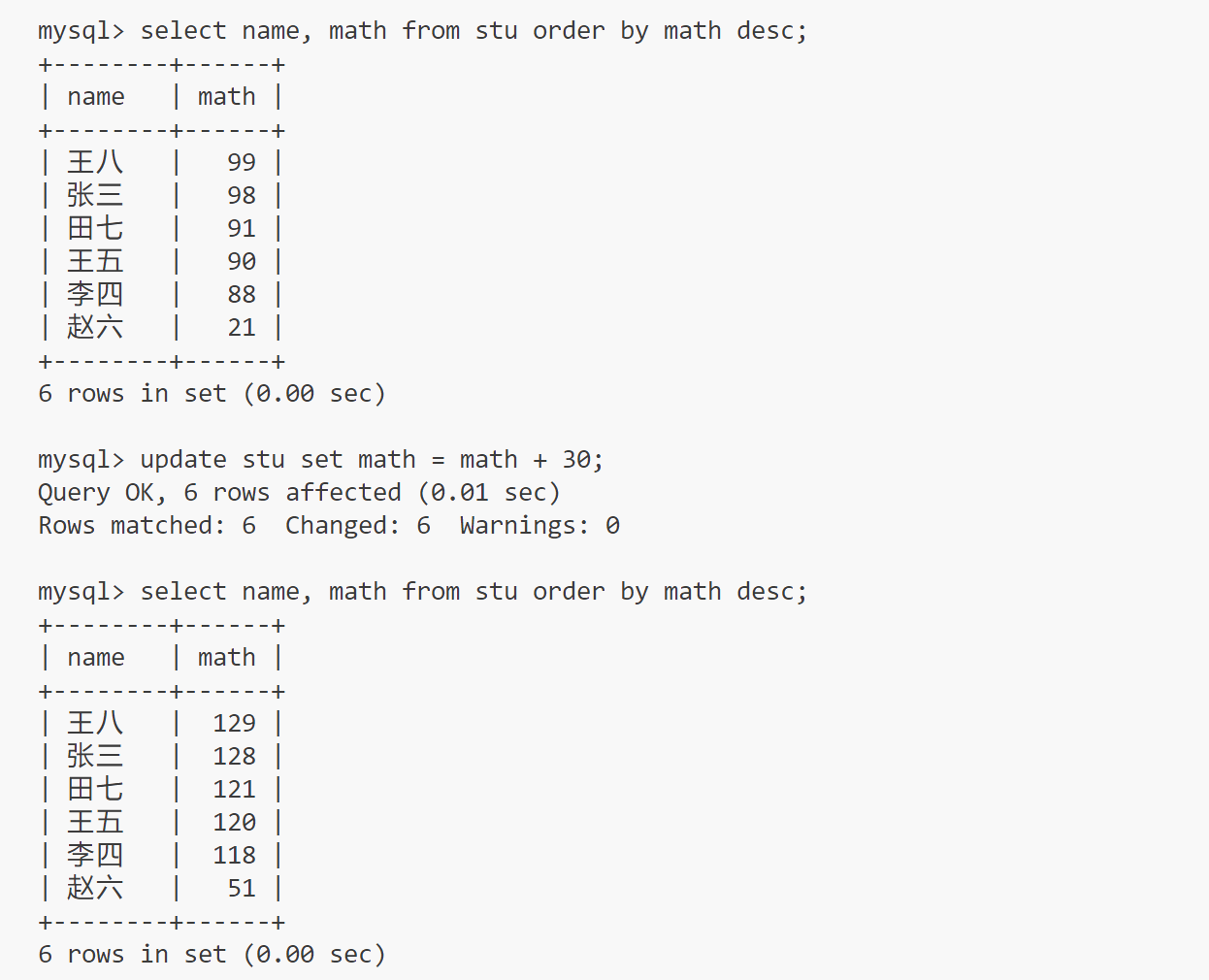
可以搭配where使用
清空表
delete:
使用delete清空表,不会更新自增长值
truncate:
只会清空表,并且不可回滚,更新自增长值
聚合函数
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
|---|---|
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
group by
为了方便体现出效果,新增三张表,分别对应员工信息,部门信息,薪资等级。
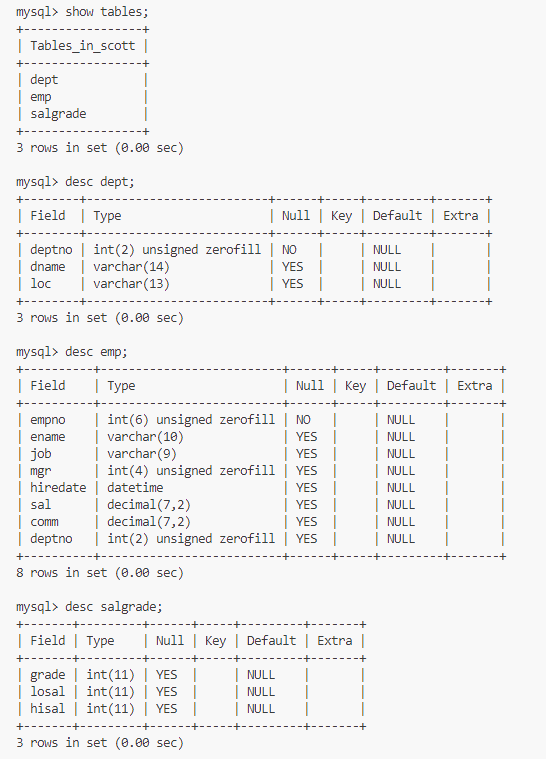
其中员工信息中的部门编号为外键,与部门信息表关联。
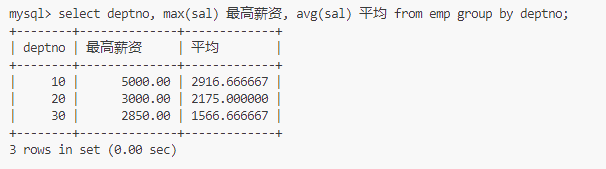
按照组找出薪资最高和平均薪资
select deptno, max(sal) 最高薪资, avg(sal) 平均 from emp group by deptno;
指定列名分组,根据列中不同行的数据进行分组。
分组也可以已多个列作为条件,已多个列作为条件分组时就会出现一个列出现多次的情况
显示平均工资低于2000的部门和它的平均工资
select deptno, avg(sal) 平均 from emp group by deptno having 平均 < 2000;
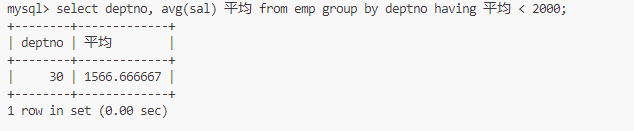
having通常和group by一起用,作用和where类似
having和where的区别
两者都能进行条件筛选。
但是where不能用来做分组后的条件筛选,而having可以充当where使用(不推荐)。因为一张表也可以看作是分组后只有一张表所以having也可以使用。
可以先用where对整体进行筛选之后再分组聚合统计之后再用having进行分组后的条件筛选。二者可以结合使用



















 664
664

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











