



集群介绍
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起。
HDFS集群负责海量数据的存储,集群中的角色主要有:
NameNode、DataNode、SecondaryNameNode
YARN集群负责海量数据运算时的资源调度,集群中的角色主要有:
ResourceManager、NodeManager
那mapreduce是什么呢?它其实是一个分布式运算编程框架,是应用程序开发包,由用户按照编程规范进行程序开发,后打包运行在HDFS集群上,并且受到YARN集群的资源调度管理。
hadoop架构
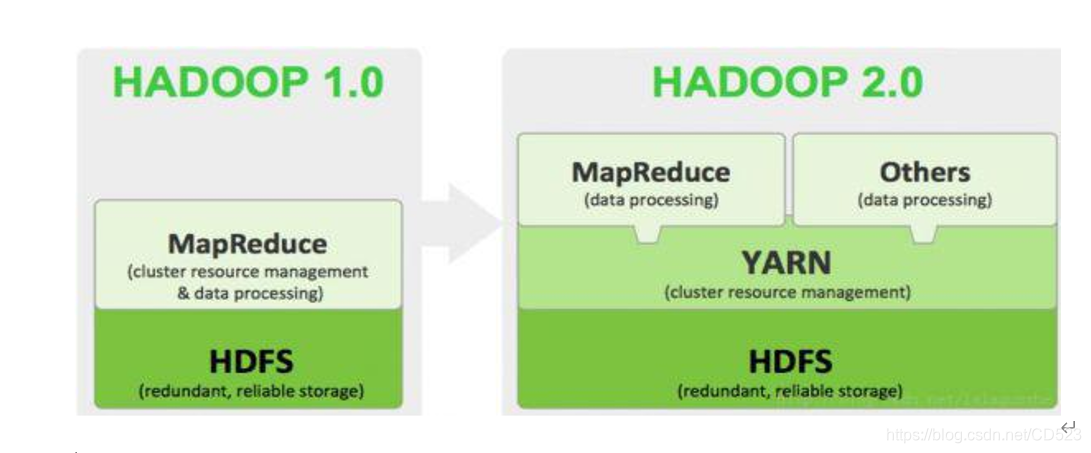
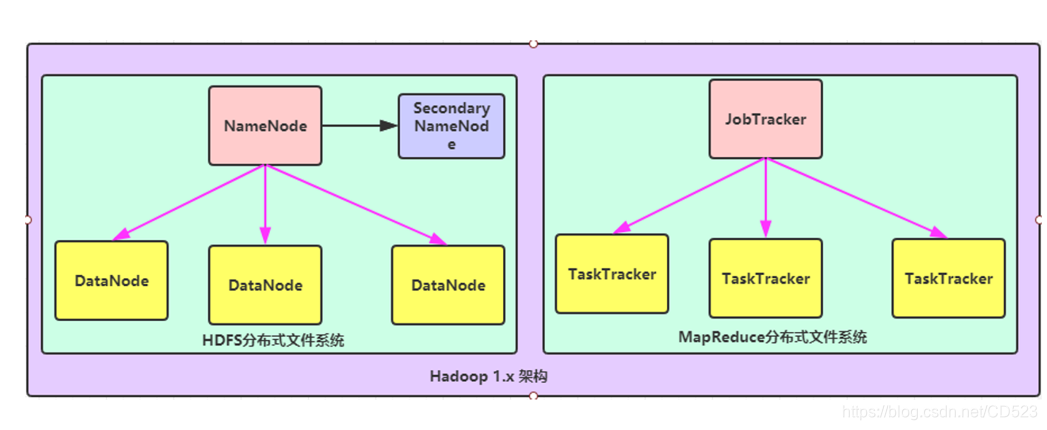
1.x版本
HDFS
文件系统核心模块:
NameNode:集群当中的主节点,管理元数据(文件的大小,文件的位置,文件的权限),主要用于管理集群当中的各种数据
SecondaryNameNode:主要能用于hadoop当中元数据信息的辅助管理
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据
MapReduce
数据计算核心模块:
JobTracker:接收用户的计算请求任务,并分配任务给从节点
TaskTracker:负责执行主节点JobTracker分配的任务
2.x版本
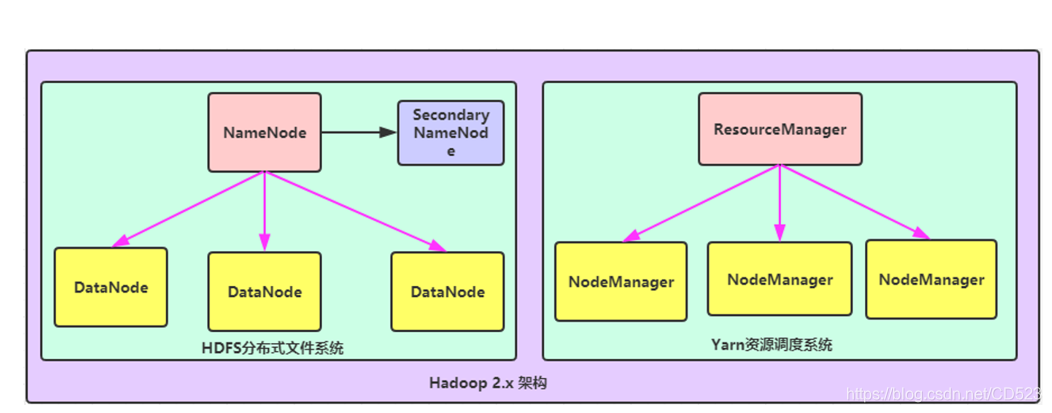
相比于1.x版本加入了yarn资源调度系统
HDFS
文件系统核心模块:
NameNode:集群当中的主节点,主要用于管理集群当中的各种数据
secondaryNameNode:主要能用于hadoop当中元数据信息的辅助管理
DataNode:集群当中的从节点,主要用于存储集群当中的各种数据
yarn
数据计算核心模块:
ResourceManager:接收用户的计算请求任务,并负责集群的资源分配
NodeManager:负责执行主节点APPmaster分配的任务

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









