 Dify 解析:RAG 技术揭秘
Dify 解析:RAG 技术揭秘




一、什么是 RAG?
(一)RAG 的基本概念
RAG(Retrieval Augmentation Generation)即检索增强生成。简单来说,RAG 是一种利用外部知识库中的信息来增强大模型生成能力的技术。通过从外部知识库检索相关信息,并将其作为输入提示词的上下文,从而提高大模型生成文本的相关性、准确性和多样性。
(二)RAG 的架构与执行流程
RAG 本质上是一套给大模型提供足够信息的上下文系统。其基本架构如下图所示:
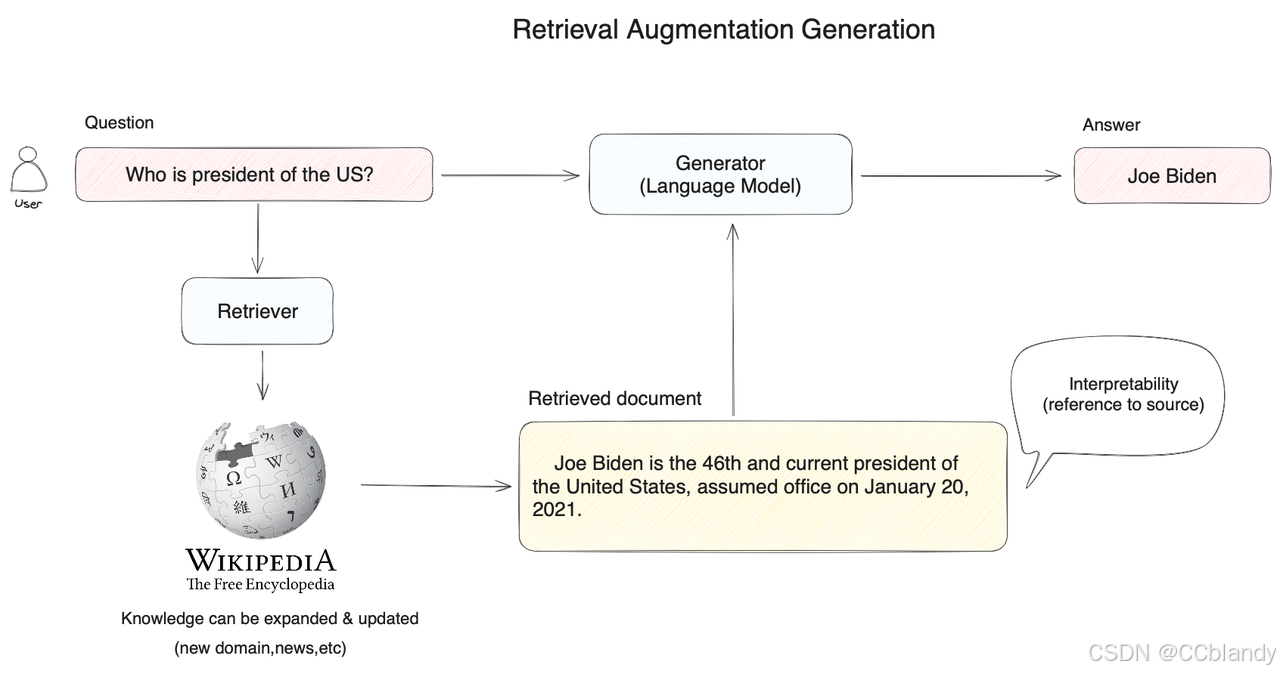
-
知识库管理:负责存储和管理外部知识,包括文本数据、多媒体数据等。
-
检索引擎:用于从知识库中检索与用户查询相关的信息。
-
提示词管理:负责生成和优化提示词。
-
模型推理服务:提供大模型的推理能力。
RAG 的执行流程如下图:
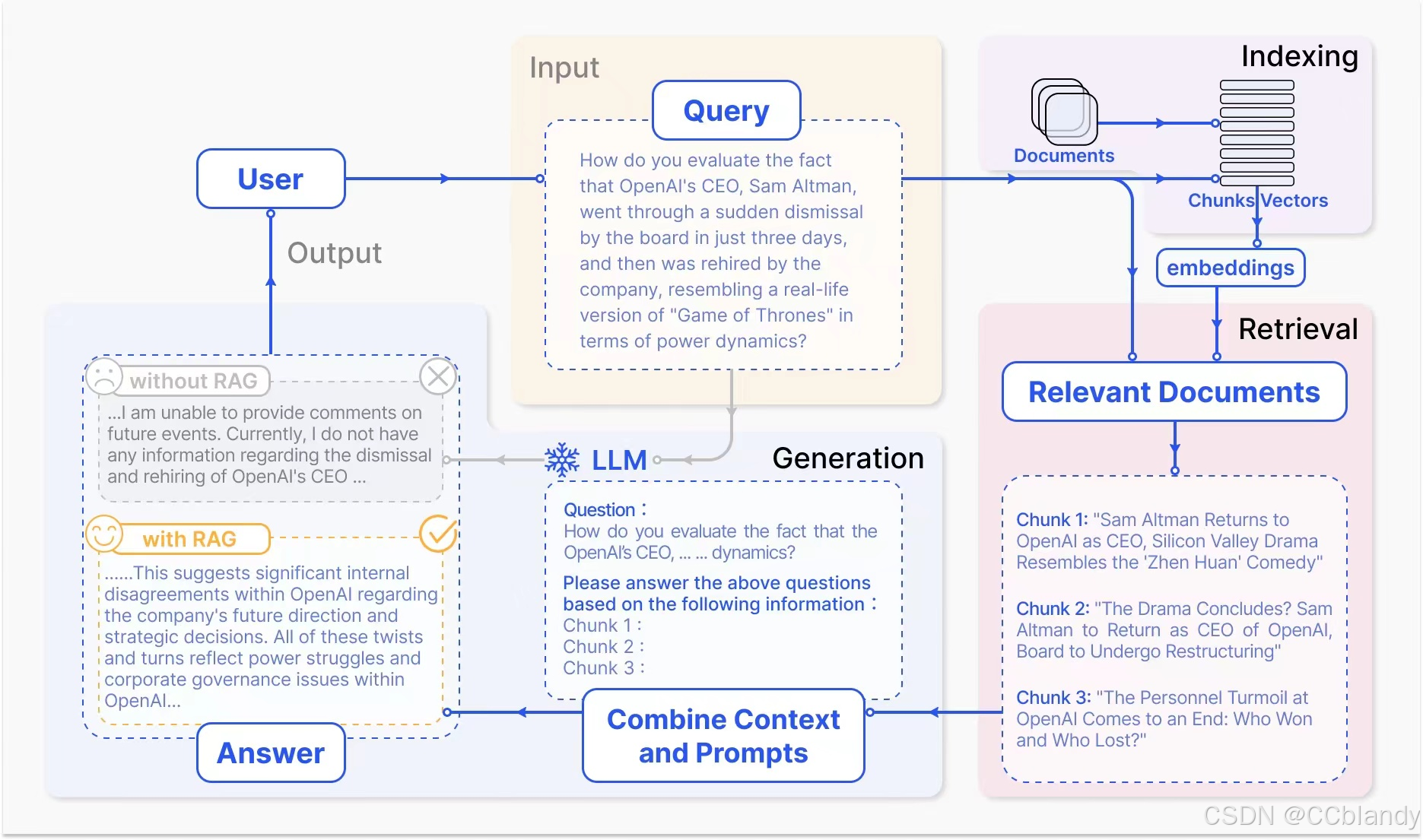
具体步骤如下:
-
用户输入查询请求。
-
检索引擎从知识库中检索相关信息。
-
提示词管理生成合适的提示词。
-
模型推理服务调用大模型进行推理。
-
输出优化生成最终的回答。
(三)RAG 的优势
RAG 的优势在于它只利用大模型的逻辑能力来得到准确的输出,而不使用大模型的任何记忆能力。这种设计方式符合吴恩达课程中的观点,将大模型视作一个逻辑推理引擎。
二、什么是 DIFY?
(一)DIFY 的基本概念
Dify 是一个流行的开源大模型应用开发平台。其核心理念是 "Do It For You"。Dify 内置了构建 LLM 应用所需的关键技术栈,包括插件、代理/反向代理、数据库/缓存、实验训练和可观测(Open Telemetry)。
(二)DIFY 的工作流程
Dify 的工作流程包括以下几个步骤:
-
数据预处理:将原始数据转换为适合模型学习的格式。
-
数据检索:根据用户的查询请求,从预先构建的知识库或数据集中检索相关信息。
-
提示词生成:将检索到的信息与用户的查询意图相结合,生成合适的提示词。
-
内容生成:将提示词输入到大模型中进行推理,生成最终的文本内容。
-
输出优化:对生成的内容进行后处理,以提高其质量和可读性。
三、Dify 的 RAG 架构
在 Dify 中,RAG 的实现主要涉及以下几个核心组件:
(一)知识库管理
知识库管理负责存储和管理外部知识,包括文本数据、多媒体数据等。这些知识可以来自多种来源,如企业内部文档、公开数据集、网络资源等。知识库需要具备高效的存储和检索能力,以支持大规模数据的快速访问。
(二)检索引擎
检索引擎用于从知识库中检索与用户查询相关的信息。常见的检索方法有基于关键词的检索、基于向量相似度的检索以及混合检索方法。
召回模式
当用户构建知识库问答类的 AI 应用时,如果在应用内关联了多个数据集,Dify 在检索时支持两种召回模式:N选1召回模式和多路召回模式。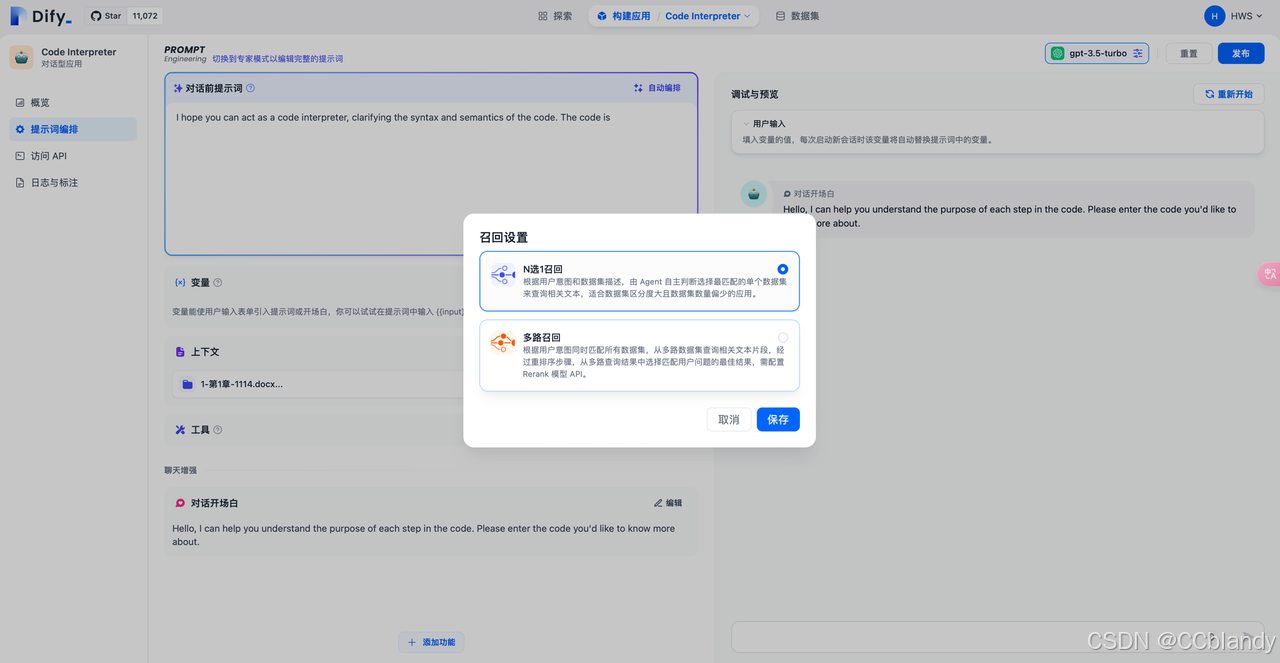
1.N选1召回模式
在用户上传数据集时,系统将自动为数据集创建一个摘要式的描述。为了在该模式下获得最佳的召回效果,可以"数据集->设置->数据集描述"中查看到系统默认创建的摘要描述,并检查该内容是否可以清晰的概括数据集的内容。根据用户意图和数据集描述,由 Agent 自主判断选择最匹配的单个数据集来查询相关文本,适合数据集区分度大且数据集数量偏少的应用。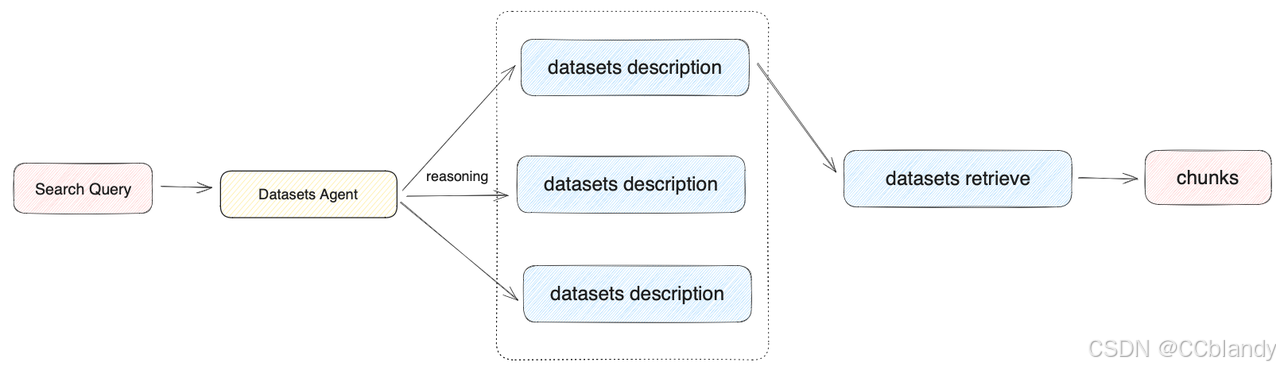
提示:OpenAI Function Call已支持多个工具调用,Dify将在后续版本中升级该模式为"N选M召回"。
2.多路召回模式(推荐)
根据用户意图同时匹配所有数据集,从多路数据集查询相关文本片段,经过重排序步骤,从多路查询结果中选择匹配用户问题的最佳结果,需配置 Rerank 模型 API。在多路召回模式下,检索器会在所有与应用关联的数据集中去检索与用户问题相关的文本内容,并将多路召回的相关文档结果合并,并通过 Rerank 模型对检索召回的文档进行语义重排序。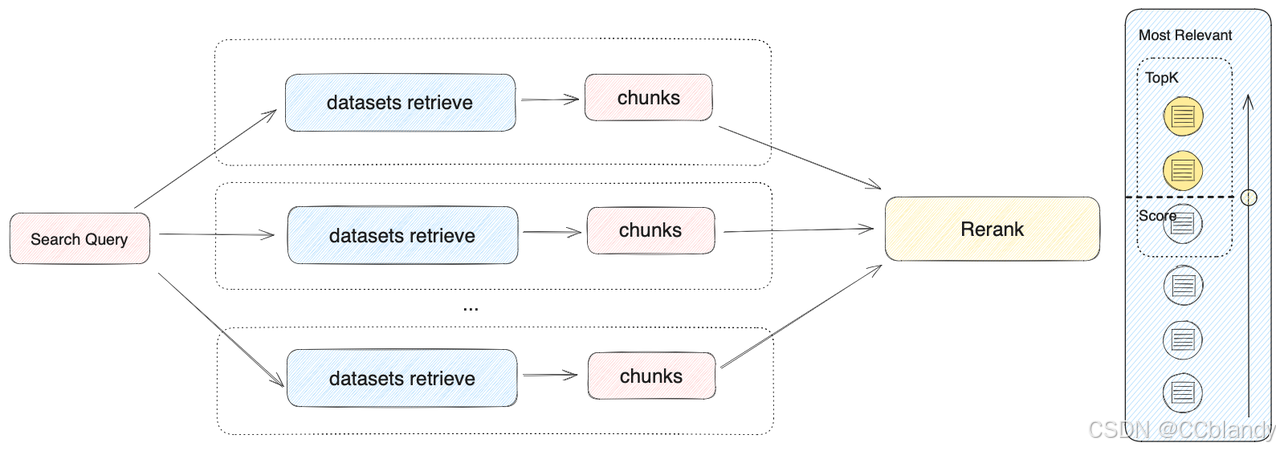
(三)提示词管理
提示词管理负责生成和优化提示词。提示词的生成可以根据用户查询和检索结果自动完成,也可以由用户手动输入。此外,还可以通过模板或动态生成策略来优化提示词。
(四)模型推理服务
模型推理服务提供大模型的推理能力。当接收到提示词后,模型推理服务会调用相应的大模型进行推理,生成最终的回答。
四、总结
Dify 通过 RAG 技术,实现了对外部知识的高效利用,极大地提升了大模型生成内容的质量和相关性。RAG 架构中的知识库管理、检索引擎、提示词管理和模型推理服务等组件相互配合,共同构成了一个完整的 RAG 系统。在实际应用中,企业可以根据自身的需求和数据特点,对这些组件进行定制和优化,以满足特定业务场景下的要求。
参考文献
[1] 检索增强生成(RAG):https://docs.dify.ai/v/zh-hans/learn-more/extended-reading/retrieval-augment
[2] 知识库:https://docs.dify.ai/v/zh-hans/guides/knowledge-base
[3] Unstructured:https://docs.unstructured.io/welcome
[4] dify源码解析-RAG:https://zhuanlan.zhihu.com/p/704341817

















 4331
4331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









