




 本文介绍了作者通过爬虫获取51job数据分析岗位数据,进行数据清洗的过程,包括删除无关信息,处理重复值,转换salary单位,整理城市信息,处理异常值和低频数据。清洗后数据量从1.9w条降至1214条,作者对此过程进行了反思,并提出关于处理低频数据的疑问。
本文介绍了作者通过爬虫获取51job数据分析岗位数据,进行数据清洗的过程,包括删除无关信息,处理重复值,转换salary单位,整理城市信息,处理异常值和低频数据。清洗后数据量从1.9w条降至1214条,作者对此过程进行了反思,并提出关于处理低频数据的疑问。
数据分析岗位
数据分析是当下每个互联网人不可或缺的技能,我是去年才开始入坑的大四计算机专业学生,现在面临春招,我现在还是有点楞逼的,继续做点项目充实一下自己空闲的心吧!爬虫分析一波51job有关数据分析的岗位吧。(个人学习项目,思维不严谨的地方,望和大家交流交流。)
需求分析
1.应届毕业生找数据分析岗位的薪资如何?不同城市的薪资的影响?学历对薪资的影响?
2.哪些城市对数据分析岗位的需求大?哪些行业对数据分析岗位的需求量大?
3.初级的数据分析都该掌握哪些技能?
数据获取
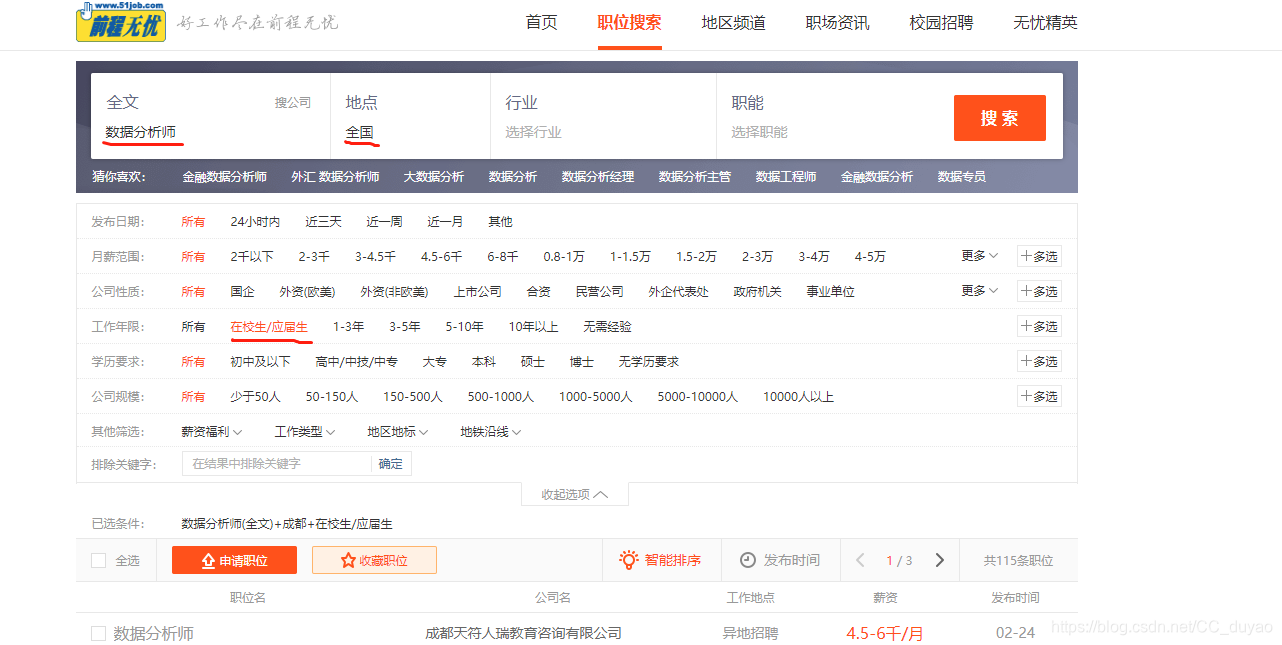
1.先来看看我的搜索条件吧,只是对于应届生而言的数据分析师岗位。
2.爬虫部分这里就自动跳过了,重点是数据分析。这里直接把爬下来的csv文件分析给大家:
链接:https://pan.baidu.com/s/1SSW9sOn_u3_oC-9IJ4ksnA
提取码:5oxg
用Pandas打开如下,一共有1.9w条数据

数据清洗
1.删除职业名称与数据分析无关的信息。
import pandas as pd
import re
data = pd.read_csv('shujufenxi.csv')
b = u'数据'
a = u'分析'
number = 1
li = data['title']
for i in range(0,len(li)):
try:
if a in li[i] or b in li[i]:
#print(number,li[i])
number+=1
else:
data = data.drop(i,axis=0)
except:
pass
代码我是用Jupyter Notebook 写的,这一步直接删除了1.7w条数据。(这一刻感觉爬虫都白爬了,需求这么少的吗?没事,下次爬大数据的)
2.查看重复值,并删除
#查看重复值,这里每个数据没有唯一标识,所以用全查重。
print((data.duplicated()).sum())
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2438
2438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









