




1、@OverLoad和@Override的区别。Overloaded的方法是否可以改变返回值的类型
OverLoad是重载。Override是重写。Overloaded 的方法是可以改变返回值的类型。
2、当一个线程进入一个对象的一个synchronized方法后,其他线程是否可以进入此对象的其他方法
1)、其他线程是不能进入这个对象的其他synchronized方法
2)、其他线程是可以进入这个对象的其他非synchronized方法
3)、其他线程是可以进入此这个对象的其他静态synchronized方法
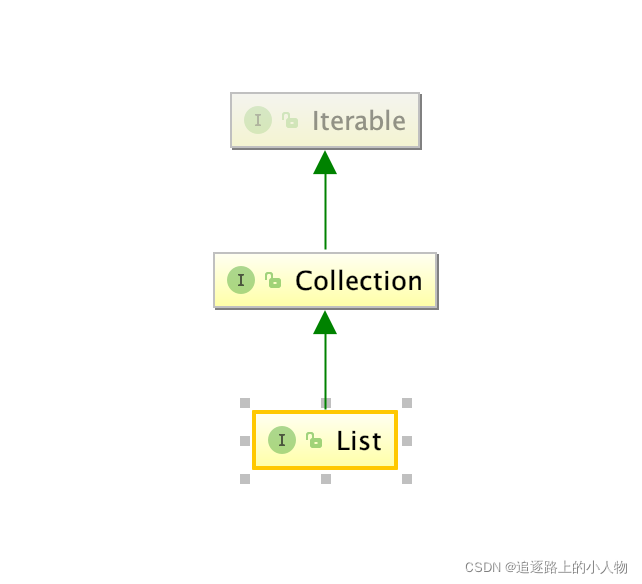
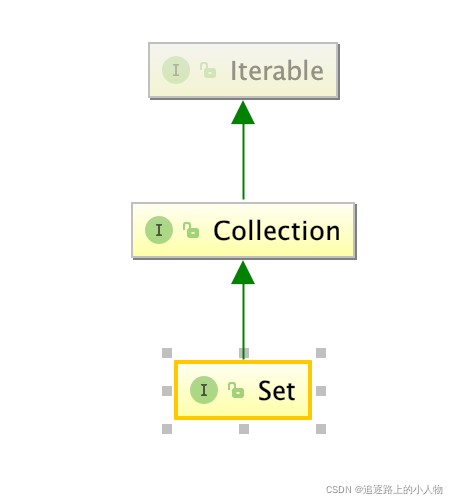
3、List、Set、Map是否继承自Collection接口
List 和Set是的 ,Map不是
4、Spring 中自动装配的方式有哪些
no、byName、byType、constructor、default。
1)、no. 在bean标签里配置autowire="no" 属性。自动装配 property 标签里配置ref属性的值

2)、byName 在bean标签配置autowire="byName" 属性值。使用名字装配,使用的是setter方式注入。所以需要注意被注入的beand的id必须和注入的bean的属性值相同。不然会报依赖注入错误
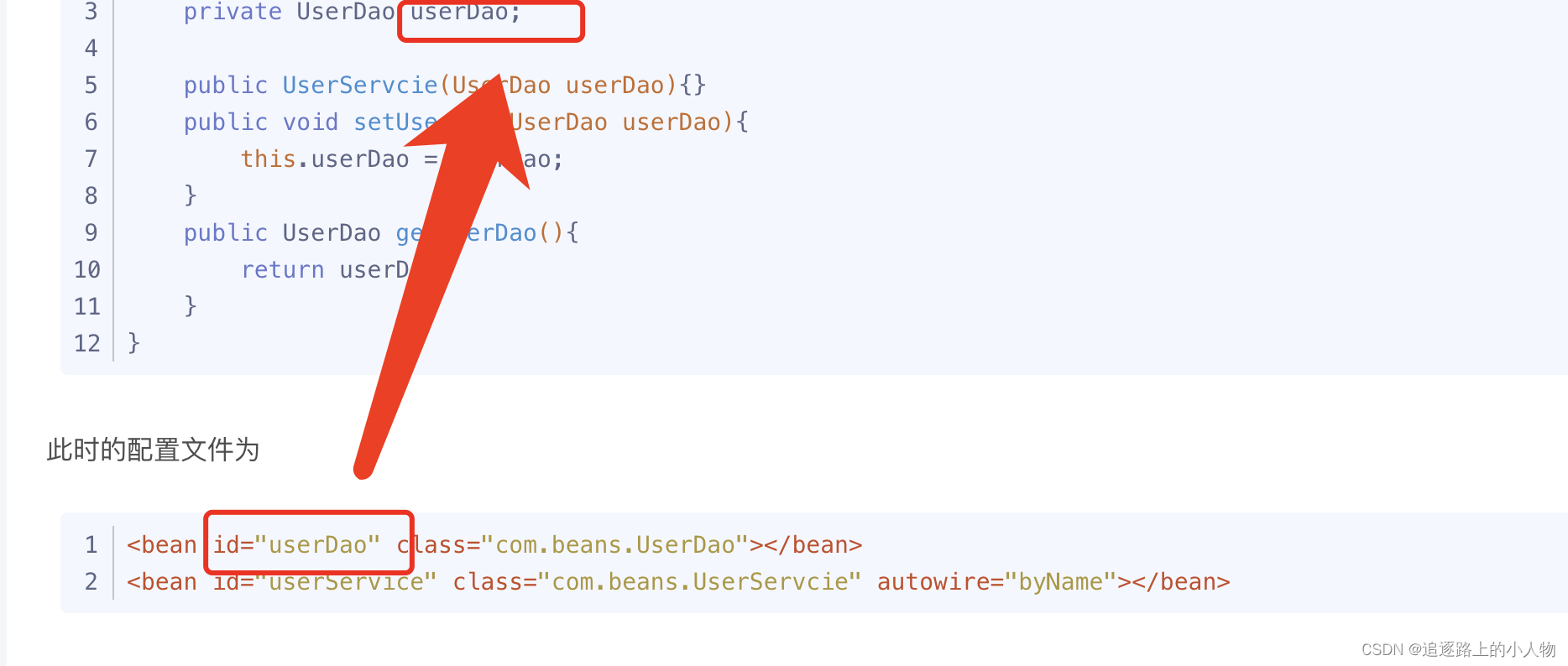 3)、byType,是用类型装配。使用的是setter方式注入。需要注意的是ioc容器不允许出现两个相同类型的Bean
3)、byType,是用类型装配。使用的是setter方式注入。需要注意的是ioc容器不允许出现两个相同类型的Bean

4)、 constructor 构造注入。默认也是使用byType方式装配,只是不同的是按照构造器参数的类型进行装配,构造器方式注入。

5)、default 使用父标签的默认装配方式。即<beans>标签,beans标签使用的是byType方式

5、Spring支持的事务管理类型有哪些?在项目中使用那种方式
支持编程式事务管理和声明式事务管理。声明式事务管理,因为这种方式和应用程序的关联较少,核心类是PlatformTransactionManager
<!-- 配置事务管理器 -->
<bean id="transactionManager"
class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>
<!-- 启用事务注解 -->
<tx:annotation-driven transaction-manager="transactionManager"/>
然后在使用的方法加上@Transactional
事务的传播行为有7中,事务特性有4中。事务的隔离级别有4中。事务出现的问题有3中
6、SpringMVC的工作流程
请求到-->前段控制器()---->路径处理器---->根据处理器找到对应的适配器---->然后调用目标方法----->视图解析器 ----->模型和视图----->前段相应。
7、如何解决POST请求中中午乱码问题。GET的又如何处理呢
在web.xml中配置过滤器。添加
<!-- 配置字符集 -->
<filter>
<filter-name>encodingFilter</filter-name>
<filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class>
<init-param>
<param-name>encoding</param-name>
<param-value>UTF-8</param-value>
</init-param>
<init-param>
<param-name>forceEncoding</param-name>
<param-value>true</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>encodingFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
GET解决:
①修改tomcat配置文件添加编码与工程编码一致,如下:
<ConnectorURIEncoding=“utf-8” connectionTimeout=“20000” port=“8080” protocol=“HTTP/1.1” redirectPort=“8443”/>
②另外一种方法对参数进行重新编码:
String userName = new String(request.getParamter(“userName”).getBytes(“ISO8859-1”),“utf-8”)
ISO8859-1是tomcat默认编码,需要将tomcat编码后的内容按utf-8编码。
8、SpringMVC与Struts2或者Struts的注意区别?讲下SpringMVC和Struts1,Struts2的比较优势
9、SpringMVC的控制器的注解一般用哪个,有没有别的注解可以代替?
@Conntroller 课堂用@RestController
10、@RequestMapping注解用在类上面有什么作用?
是一个用来处理请求地址映射的注解,可用于类或方法上。
用于类上,表示类中的所有响应请求的方法都是以该地址作为父路 径
11、SpingMVC怎么样设定重定向和转发的
在返回值前面加"forward:"
在返回值前面加"redirect:"
12、当一个方法向AJAX返回特殊对象。例如Object,List等。需要做什么处理
@ResponseBody 。做json转换 使用工具类转换 fast
13、MyBatis如何匹配值一对多关联
mapper 表里面 使用 collection标签继续填写其他表的字段列
14、Mybatis里面的动态SQL是怎么设定的?用什么语法?
if.choose,when,otherwise,where
15、讲下MyBaits的缓存
MyBatis 有一级缓存默认开启:就是SqlSession缓存
MyBatis 有二级缓存默认不开启:
16、MyBatis的好处是什么
简化JBDC操作 。让SQL操作数据更简便 ,上手简单
17、MyBatis的xml配置中${} 和#{}有什么区别
${}: 仅仅为一个纯碎的 string 替换,在动态 SQL 解析阶段将会进行变量替换
举例说明:
select id,name,age from student where id =${id},
当前端把id值1,传入到后台的时候,
就相当于 select id,name,age from student where id = 1.
#{}: 解析为一个 JDBC 预编译语句(prepared statement)的参数标记符,一个 #{ } 被解析为一个参数占位符 。
举例说明:
select id,name,age from student where id =#{id},
当前端把id值1,传入到后台的时候,
就相当于 select id,name,age from student where id =‘1’.
使用#可以很大程度上防止sql注入。(语句的拼接),但是如果使用在order by 中就需要使用$.
在大多数情况下还是经常使用#,但在不同情况下必须使用$.
18、什么是XSS攻击?什么是SQL注入攻击?什么是CSRF攻击?如何避免
什么是CSRF攻击?通过构造get 请求去获取已登录浏览器的Cookie信息。提交表单随机带一个uuid
什么是XSS攻击,将一段JavaScript代码注入网页。获取Cookie信息。解决:返回内容时进行转码,转码尖括号采用Unicode编码格式
什么是SQL注入攻击:查询账号信息条件 where 给你注入为1=1 条件永远成功。
解决:最有效的仍然是使用SQL变量进行查询,避免使用字符串来拼接SQL字符串。
19、@autowired 和 @resource的区别
@Resource的作用相当于@Autowired,只不过@Autowired按byType自动注入,而@Resource默认按 byName自动注入罢了。
20、springboot的启动原理
含有三大注解
1、
SpringApplication.run();
一、先初始化
1、保存主配置类-->
2、判断当前是否一个web应用--->
3、从类路径下初始化MEAT-INF/spring.factories里面的所有ApplicationContextInitializer 容器
4、从类路径下加载MEAT-INF/spring.factories里面的所有ApplicationListener 监听器
5、从配置类中找到所有的main方法的主配置类
二、运行run()方法
1、获取运行的监听器
2、调用所有监听器的start()方法
3、准备环境
****会有一个打印spring 的方法printBannner
4、创建容器(ApplicationContext)createApplicationContext();
5、将准备好的环境加入到ioc容器中
6、然后刷新容器。ioc容器初始化 refreshContext() 这里就会打印 Tomcat 启动默认端口8080
7、从容器中获取回调方法的finished方法
8、然后返回启动的容器
方法
1、getRunListeners()
2、listeners.starting();
3、prepareEnvironment()
4、printBanner();
5、createApplicationContext();
6、 new FailureAnalyzers(context);
7、prepareContext()
8、 refreshContext(context);
9、afterRefresh(context, applicationArguments);
10、listeners.finished(context, null);
21、bean的生命周期
1、 实例化(Instantiation)
2、 属性设置(populate)
3、 初始化(Initialization)
4、 销毁(Destruction)
--------------
[1]通过构造器或工厂方法创建bean实例
[2]为bean的属性设置值和对其他bean的引用
[3]调用bean的初始化方法
[4]bean可以使用了
[5]当容器关闭时,调用bean的销毁方法
22、MyBatis 的运行原理
1)、获取sqlSessionFactory对象
SqlSessionFactory sqlSessionFactory=getSqlSessionFactory();
获取getSqlSessionFaction()方法。就是把配置文件的信息解析并保存在Configuration对象中。返回DefaultSqlSession对象
2)获取sqlSession对象
SqlSession openSession=sqlSessionFactory.openSession();
返回一个DefaultSQlSession对象,包含Executor和Configuration
3) 获取接口的实现类对象 (会为接口自动的创建一个代理对象,代理对象去执行增删改查方法)
XXXMapper mapper=openSession.getMapper(XXXMapper.Class)
使用MapperProxyFactory创建一个MapperProxy的代理对象
代理对象里面包含了,DefaultSqlSession(Executor)
4)执行查询
StatementHandler:处理SQL语句预编译,设置参数等相关工作
ParameterHandler:设置预编译参数用的
ResultHandler:处理结果集
TypeHandler:在整个过程中,进行数据库类型和JavaBean类型的映射
代理对象--->DefaultSqlSession----->Executor------>StatementHandler------>ParameterHandler---->ResultSetHandler------->TypeHandler------->JDBC:statement
总结:
1、根据配置文件(全局,sql映射)初始化Configuration对象
2、创建一个DefaultSqlSession对象
他里面包含Configuration对象。以及Executor()
3、DefaultSqlSession.getMapper();拿到Mapper接口对应的MapperProxy
4、MapperProxy里面有(DefaultSqlSession);
5、执行增删改查方法
1)、调用DefaultSqlSession的增删改查(Executor)
2)、会创建一个StatementHandler对象
(同时也会创建出ParameterHandler和ResultSetHandler)
3)、调用StatementHandler预编译参数已经设置参数值;
使用ParameterHandler来给sql设置参数
4)、调用StatementHandler的增删改查方法;
5)、ResultSetHandler封装结果
23、Spring的运行原理
24、SpringMVC的运行原理
25、Spring 中,有两个 id 相同的 bean,会报错吗
在同一个xml里面,有相同的id的bean,在初始话bean的时候会报错。
在使用@Configuration注解类里面,使用@Bean注解 有两个name一样的bean但是类型不同的。在启动时候
使用@Autowired 和@Resource 后
1、如果两个都用了依赖注入,那么会报错。
2、如果第只用了第二个依赖注入也会报错。
3、只有只使用第一个依赖注入不会报错。
26、@Bean注解
1、当一种类型,只有一个Bean,不标注Bean的名字。默认按照类型添加到容器
2、当一种类型,有多个Bean,且不标注Bean的名字。默认按照方法名添加到容器
1.1、使用@Autowired 和@Resource
去注入该类型的类 根据书写的变量名称去容器中找对应的Bean 。当变量和Bean注入容器的方法名一致就返回,否则就报错提示容器中存在的bean的名称。
27、@Autowired 和@Resource区别
@Autowired默认按照类型去匹配
@Resource后面没有任何内容,默认通过name属性去匹配bean,找不到再按type去匹配
如果指定name 按照指定去匹配。不存在就返回错误
如果按照类型去匹配。必须确保容器中只有一个,否则就会报错。提示有容器中存在的类型对应的名字。
28、B数和B+数的区别
磁盘IO的影响,数据库索引是存储在磁盘上。
B数数据存放在整个树种,任何数据在数中只存在一次,在搜索中有可能在非叶子节点结束。搜索数据等价于二分查找
B+数据是B数据的变体,更加稳定的查找,所有记录节点都是按键值大小顺序存放在同一层叶节点中。各叶节点指针相连。
29、mysql数据库的索引
1、什么事索引?
索引是用于快速查找到数据记录的一种数据结构。
2、为什么使用索引(数据都是读取磁盘记录加载到内存中的,这个过程中最耗时的就是磁盘IO)
在没有索引的情况下,数据分布在磁盘不同的位置上,读取数据时。需要多次摆动查询(例如 旧版本的留声机。就是读取磁盘来获取声音)。就进行了多次IO操作。会非常耗时。而建立索引就是减少磁盘IO次数
3、唯一索引:可以保证数据库中每一行数据的唯一性
4、在使用分钟和排序子句进行数据查询时,可以减少查询时间。减低了CPU的消耗
5、索引的缺点:
5.1、创建和维护所以都需要消耗资源和时间。同时提高了查询速度,同时会减低更新表的速度。因为在更新数据的同时,也需要维护新的索引
6、InnoDB中的索引(单数据页 二叉树)
数据放在一个数据页中,因为数据在物流磁盘上存放不是连续的(连续存放极耗时磁盘IO操作)。没条记录之间是通过单列表链接的
6.1、在多个数据页中查找(数据页,目录)
多个数据页,不存在 存放数据顺序。因为没有索引的话,的遍历每个数据页,所以效率极差
举例:就是图书馆的书架记录。每个书架都有标识改书架的类型。便于快速查找。mysql的书架目录维护的更细。
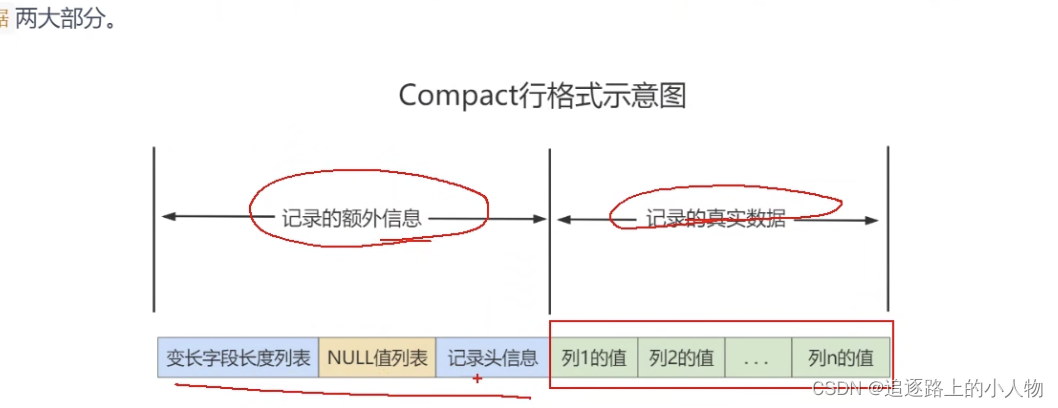
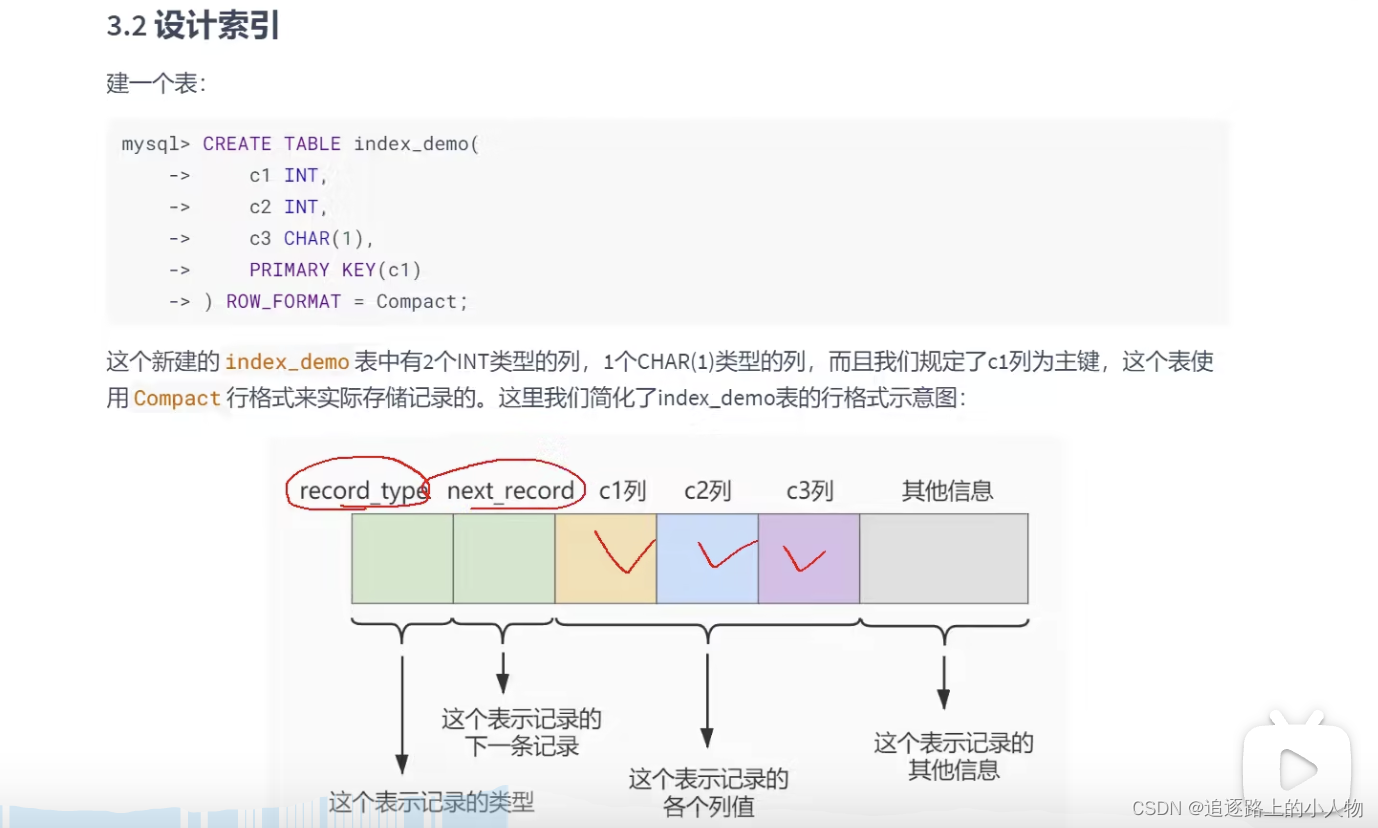

记录数据的重要几个部分:
record_type:记录头信息的一项属性。表示记录的类型
0:表示普通记录。2、表示最小记录。3、表示最大记录
next_record:记录头信息的一项属性。表示下一条地址相对于本条记录的地址偏移量。我们用箭头标明下一条记录是谁。
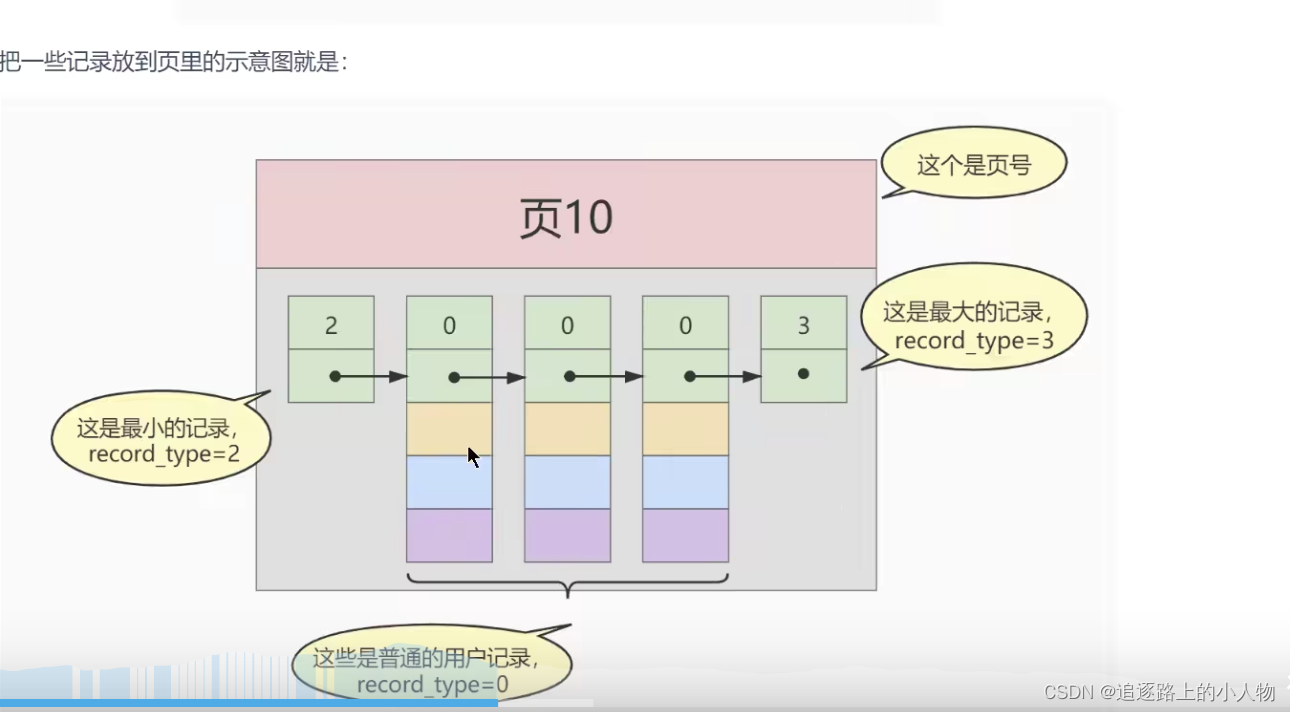
这里record_type记录的是 主键索引值的最大,最小

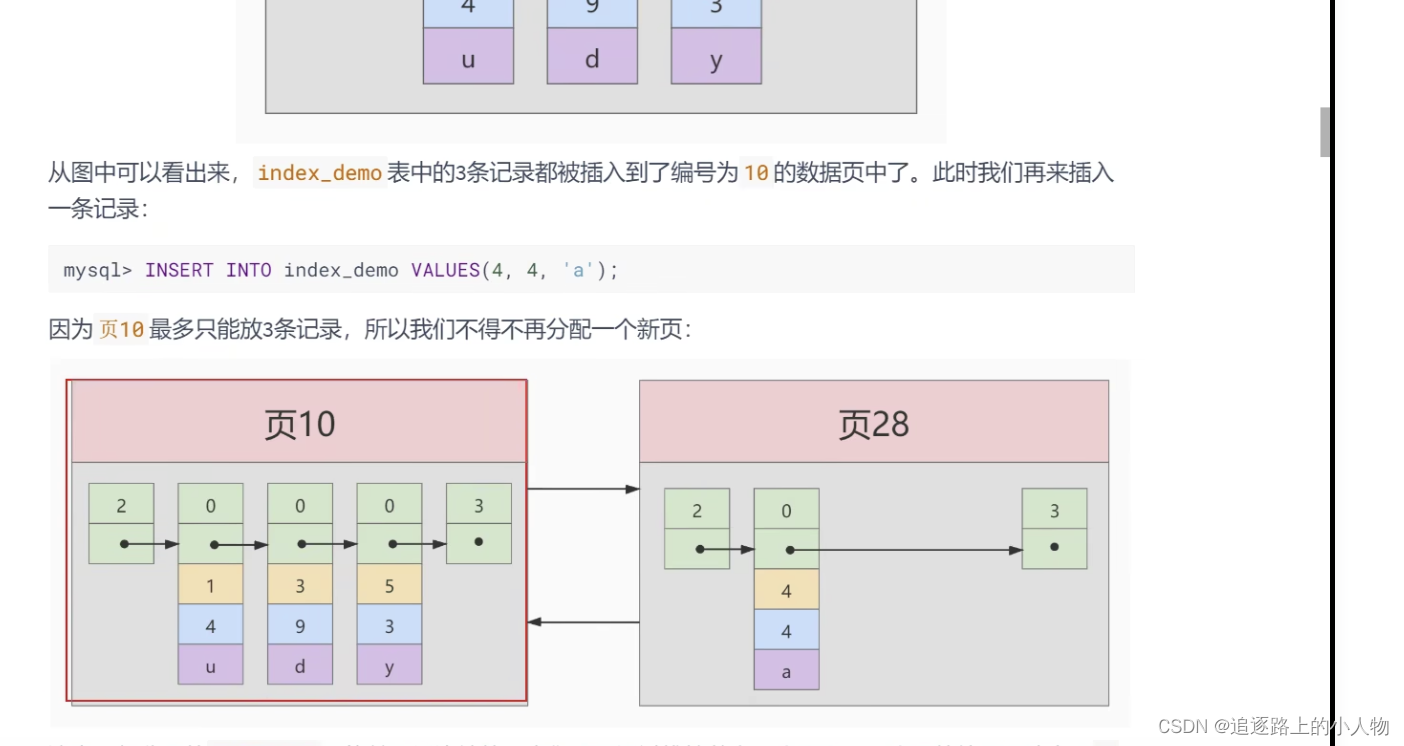 当数据页满时,再添加数据会开辟一个新的数据页。当新页 record_type 小于旧页里面的最大值,那么就得和旧页里的数据进行一次记录移动。以保证数据按顺序存放。也称页的分裂
当数据页满时,再添加数据会开辟一个新的数据页。当新页 record_type 小于旧页里面的最大值,那么就得和旧页里的数据进行一次记录移动。以保证数据按顺序存放。也称页的分裂
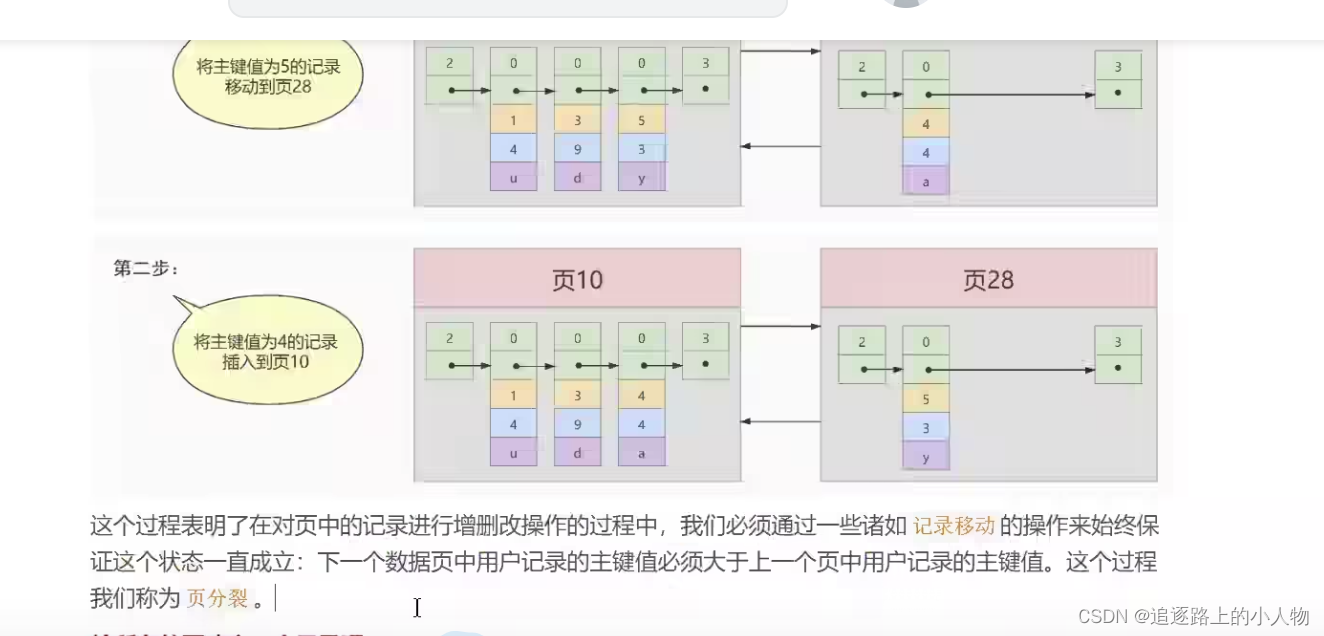
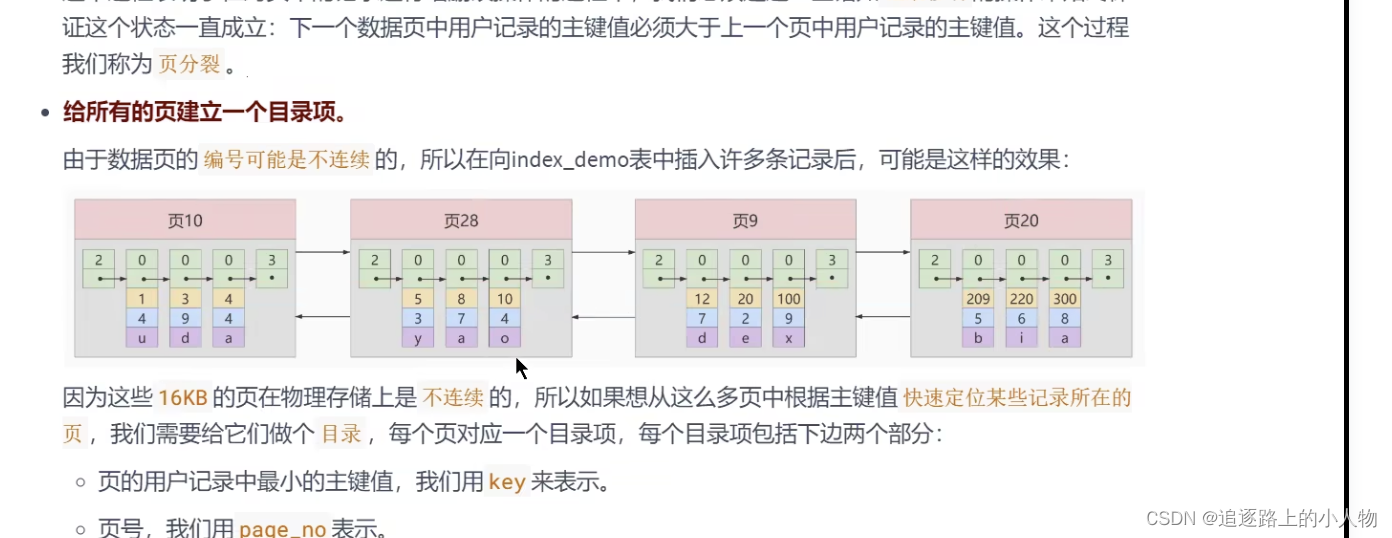
由于数据页,的编号可能不是连续的。所以在表中插入多条记录的时候,可能存在很多数据页。因此需要建立一个目录。没页对应一个目录项。每个目录项包括两个部分
页的用户记录中最小的主键值。用key表示。
页号,用page_no表示。
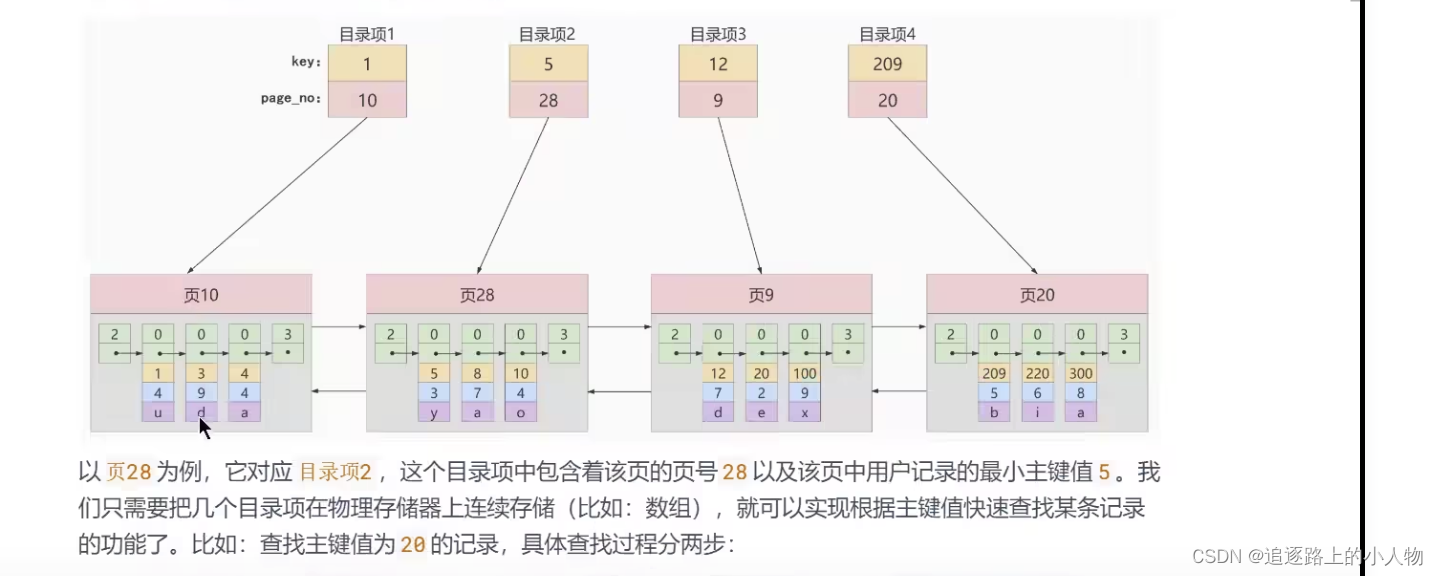
针对主键索引找。通过二分法查找目录项 找记录的主键值。然后再在对应的数据页找对应的值。


















 1129
1129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











