 LangExtract:精准文档信息抽取利器
LangExtract:精准文档信息抽取利器







一、背景
在当今这个数据驱动的时代,很多有价值的信息其实都藏在非结构化的文本里——比如临床病历、冗长的法律合同,或者用户反馈的讨论串。在处理海量的非结构化文本时,如何高效且准确地提取结构化信息(如实体、关系、属性)一直是一个棘手的问题。传统方案如正则表达式或基于规则的解析器虽然简单,但往往缺乏灵活性、难以适应复杂语境,且维护成本居高不下。随着大型语言模型的兴起,利用LLM自然语言理解能力进行信息抽取,正在成为主流的新范式。
二、LangExtract 简介
LangExtract 的核心是一个基于指令(Prompt)和示例(Few-Shot)驱动的信息抽取引擎,围绕 “Schema 驱动抽取”思想构建而成,提供了一种精准、可扩展且可验证的方式,从任意文本中提取用户定义的结构化信息。
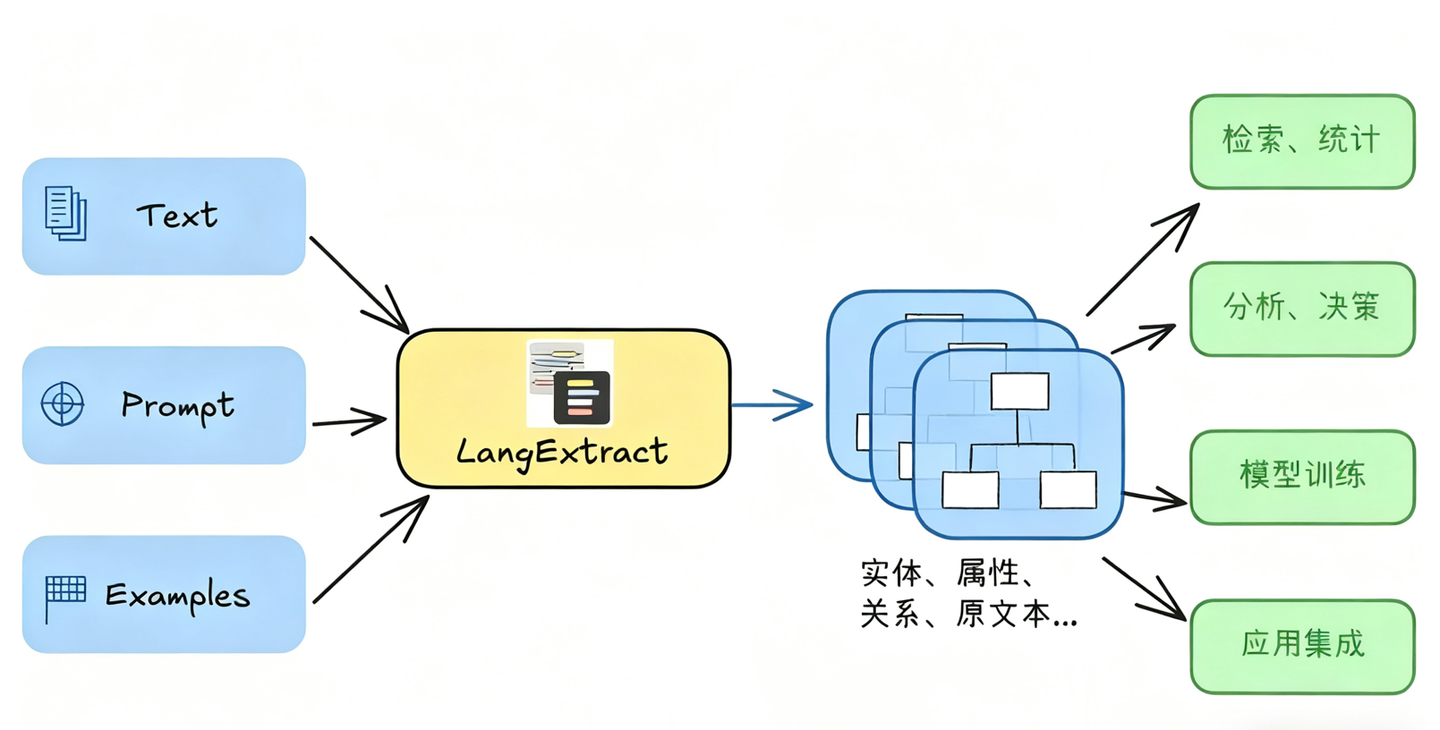
使用 LangExtract 进行信息抽取,遵循以下简单步骤,即可高效完成需求:
清晰界定提取任务:用自然语言明确提取目标即可,比如 “提取新闻中的人物姓名、所属机构及核心观点,严格匹配原文内容,不额外增删信息”。
准备参考示例:提供若干文本片段,并搭配对应的理想提取结果样例,帮助模型精准理解需求。
选择模型执行抽取:从可用模型中选定适配的一款,提交后 LangExtract 会自动处理文本,输出符合要求的结构化数据。
三、特性
1. 精准溯源
这是 LangExtract 的核心功能。它不止于识别文本中是否包含目标信息(如 “高血压”),更能精准标注该信息在原始文本中的具体字符偏移位置。
该功能的核心价值在于提供了极强的可解释性、可追溯性与可验证性。用户或下游系统可轻松回溯至原文上下文,清晰理解模型判断的依据,彻底规避了 AI 模型的 “黑盒问题”,为构建可靠的业务应用筑牢核心基础。
2. 结构化输出
LangExtract 通过精心设计的提示词(Prompt),结合对 Gemini 等支持模型的受控生成(Constrained Decoding)技术,能够强制模型严格按照用户示例定义的预定格式输出结果。
结构化输出打破了传统模型输出松散文本的局限,直接生成 JSON 等高度结构化的数据。这些数据可无缝导入数据库,或直接用于后续的数据分析流程,大幅提升了结果的可用性与一致性。
3. 长文档支持
传统大语言模型通常都会有上下文长度限制,在处理动辄数万、数十万字符的实际业务文档的时候,即使多轮摘要总结,往往也会不确定性地丢失一些可能重要的信息,使得长文档的处理效果没有那么理想。
针对长文档处理瓶颈,LangExtract 集成三大核心优化机制:
- 智能文本分块(Text Chunking):自动将超长文档拆解为适配模型处理能力的合理片段;
- 并行加速处理(Parallel Processing):通过 max_workers 参数配置,多线程并行加速文档处理进程;
- 多轮迭代扫描(Multiple Extraction Passes):支持通过 extraction_passes 参数(默认值为 1)设置多轮扫描,让模型从不同视角反复解析文本,显著提升关键信息的召回率,避免遗漏重要内容,解决传统模型总结效果不佳的问题。
4. 可视化呈现
LangExtract 支持将信息抽取到的结果(存储于.jsonl 文件)一键生成自包含的交互式 HTML 文件。用户可在可视化界面中,直观查看成千上万个提取实体(如人名、药物名称、情绪短语等)在原始文本中的高亮标注,同时支持搜索、筛选等便捷操作。
- 对开发者而言,能够帮助调试提示词、验证抽取效果。
- 对于用户而言,视觉冲击,也能更快得帮助用户理解文章内容。
5. 多模型适配
LangExtract 构建了多维度、可扩展的模型适配体系,用户可以根据性能、成本、隐私、功能需求自由选择最合适的引擎,以满足不同场景需求。
- 云端模型原生支持:适配 Google Gemini 系列模型,gemini-2.5-flash 为性价比首选,gemini-2.5-pro 适用于复杂推理场景;
- 本地模型隐私部署:内置 Ollama 集成能力,可直接运行 gemma2:2b 等开源模型,无需 API 密钥,兼顾隐私安全;
- 第三方模型适配:支持 gpt-4o 等 OpenAI 模型(需安装额外依赖);
- 插件化扩展能力:提供灵活的插件机制,开发者可轻松集成其他第三方模型 API,或接入自定义推理端点。
四、代码结构解析
1. 项目结构
项目主体结构位于langextract/目录下,各模块职责明确。
langextract/
├── core/ # 核心逻辑,包括数据类型定义、数据格式化、文本分词等
├── providers/ # LangExtract所需的大模型服务,可扩展。
├── schema.py # 定义核心数据结构,如 ExtractionInput, ExtractionResult
├── extraction.py # 提取流程的控制器和编排逻辑
├── factory.py # 提供顶层 API 入口
├── prompting.py # 根据 Schema + 文本生成提示词
├── chunking.py # 文本分块逻辑
├── inference.py # 负责调用底层 LLM
├── plugins.py # 插件系统,用于加载扩展
└── registry.py # 注册表,管理可扩展组件
providers主要是为LangExtract提供大模型服务,支持多种大模型,内置的有google 的gemini模型,OpenAI模型以及Ollama部署私域模型等。
User Code LangExtract Provider
───────── ─────────── ────────
| | |
| lx.extract( | |
| model_id="gemini-2.5-flash") |
|─────────────────────────────> |
| | |
| factory.create_model() |
| | |
| registry.resolve("gemini-2.5-flash") |
| Pattern match: ^gemini |
| ↓ |
| GeminiLanguageModel |
| | |
| Instantiate provider |
| |─────────────────────────────>|
| | |
| | Provider API calls |
| |<─────────────────────────────|
| | |
|<──────────────────────────── |
| AnnotatedDocument | |
2. 核心方法介绍
2.1 lx.extract 方法
extract方法是LangExtract的入口,也是最核心最基本的方法,在LangExtract的使用过程中,通过extract调用,就能得到想要的结构化的数据信息以及可视化呈现。
核心参数包括text_or_documents、prompt_description 和examples。
def extract(
text_or_documents: typing.Any, # 信息抽取的源文本或者url
prompt_description: str | None = None, # 提示词描述,告诉模型从文本中提取什么样的内容、实体等
examples: typing.Sequence[typing.Any] | None = None, # 指导提取的示例数据,ExtractData对象列表,没有示例会报错
model_id: str = "gemini-2.5-flash",
api_key: str | None = None,
language_model_type: typing.Type[typing.Any] | None = None, # 模型类型(已弃用)
format_type: typing.Any = None, # 输出格式, JSON或者yaml
max_char_buffer: int = 1000, # 可用于运行推理的最大字符数, 文本将被拆分为不超过此长度的块
temperature: float | None = None,
fence_output: bool | None = None, # 是否期望/生成带分隔符的输出(```json或```yaml)
use_schema_constraints: bool = True, # 是否为模型生成模式约束
batch_length: int = 10, # 每批处理的文本块数量
max_workers: int = 10, # 用于并发处理的最大并行工作线程数
additional_context: str | None = None, # 推理期间要添加到提示词中的额外上下文
resolver_params: dict | None = None, # resolver.Resolver`的参数,该解析器将原始语言模型输出字符串(例如,从```json...```块中提取JSON)解析为结构化的`data.Extraction`对象
language_model_params: dict | None = None,
debug: bool = False,
model_url: str | None = None,
extraction_passes: int = 1,
config: typing.Any = None, # 用于提取的模型配置。优先级高于model_id、api_key和language_model_type参数
model: typing.Any = None, # 用于提取的预配置语言模型。优先级高于所有其他参数,包括config。
*,
fetch_urls: bool = True, # 当输入是URL字符串时,是否自动下载内容
prompt_validation_level: pv.PromptValidationLevel = pv.PromptValidationLevel.WARNING,
prompt_validation_strict: bool = False,
show_progress: bool = True,
) -> typing.Any:
"""从文本中提取结构化的数据信息"""
2.2 factory.create_model方法
def create_model(
config: ModelConfig,
examples: typing.Sequence[typing.Any] | None = None,
use_schema_constraints: bool = False,
fence_output: bool | None = None,
return_fence_output: bool = False,
) -> base_model.BaseLanguageModel | tuple[base_model.BaseLanguageModel, bool]:
"""基于配置信息创建大模型实例"""
2.3 annotator.annotate_text方法
annotator = annotation.Annotator(
language_model=language_model,
prompt_template=prompt_template,
format_handler=format_handler,
)
annotator.annotate_text(
text: str, # 要注释的源文本
resolver: resolver_lib.AbstractResolver | None = None, # 用于从文本中提取信息的解析器
max_char_buffer: int = 200, # 可用于运行推理的最大字符数, 文本将被拆分为不超过此长度的块
batch_length: int = 1, # 单次批处理中要处理的块数
additional_context: str | None = None, # 用于补充提示说明的额外上下文
debug: bool = True,
extraction_passes: int = 1, # 为提高召回率而进行的连续提取次数,以查找更多实体。默认为1,即执行标准的单次提取。大于1的值会对标记进行多次重新处理,可能会增加成本。
show_progress: bool = True, # 是否显示进度条
**kwargs,
) -> data.AnnotatedDocument:
"""为文本输入添加带有自然语言处理提取内容的注释"""
五、应用示例
使用语义检索 + 实体图谱 的Hybird RAG
RAG在工业界的应用已经比较成熟了,除了最基本的语义检索外,还有使用Rerank进行重排序、语义和关键字结合的混合检索,以及Graph RAG等基于知识图谱的方案。使用LangExtract可以在一定程度下替代Graph RAG这种token杀手,相当于一种Hybrid RAG的方案,并且成本相对可控。
# 定义规则
prompt = textwrap.dedent("""\
Extract characters, emotions, and relationships in order of appearance.
Use exact text for extractions. Do not paraphrase or overlap entities.
Provide meaningful attributes for each entity to add context.""")
examples =[
lx.data.ExampleData(
text="ROMEO. But soft! What light through yonder window breaks? It is the east, and Juliet is the sun.",
extractions=[
lx.data.Extraction(
extraction_class="character",
extraction_text="ROMEO",
attributes={"emotional_state":"wonder"}
),
lx.data.Extraction(
extraction_class="emotion",
extraction_text="But soft!",
attributes={"feeling":"gentle awe"}
),
lx.data.Extraction(
extraction_class="relationship",
extraction_text="Juliet is the sun",
attributes={"type":"metaphor"}
),
]
)
]
# 开始提取
graph_entities =[]
for d in retrieved_docs:
result = lx.extract(
text_or_documents=d.page_content,
prompt_description=prompt,
examples=examples,
model_id="gemini-2.5-flash",
)
graph_entities.append(result)
for r in graph_entities:
print("r:", r)
print('\n\n')
六、应用场景及未来展望
谷歌开源的 LangExtract,堪称大语言模型(LLM)应用领域的一项突破性进展,尤其在信息抽取这一核心任务上表现突出。它巧妙融合了 LLM 强大的文本理解能力,与精准来源追溯、严格结构化输出、海量文档处理优化、直观结果验证等多项工程创新。
依托灵活的多模型适配能力与开放的插件扩展机制,LangExtract 为开发者打造了一款功能强大且具备高扩展性的基础工具。在各类需要从海量文本中提炼核心价值信息的场景中,该工具有望发挥关键作用,成为文本数据挖掘领域的得力助手。
- 医疗信息抽取:高效从临床笔记、病历报告中提取药物名称、用药剂量、诊断结果、病症表现、手术详情等关键信息,为临床决策支持与医学研究分析提供数据支撑(注:实际医疗场景应用需经过严格的合规审查与效果验证)。
- 知识图谱构建:作为强大的文本预处理工具,高效抽取语料中的实体信息与关联关系,为知识图谱的搭建提供坚实的数据基础。
- 内容审核与情报分析:快速识别文本中特定类型的实体、关键事件或隐藏关系,满足内容合规审核与情报挖掘的核心需求。
- 金融、法律等其他垂直领域文档处理:能够深度解析财务报表、商业合同、法律案件等各种各样的专业性的文档,精准提取核心业务指标,分析人物关系,提高处理效率。
版权声明:本文由神州数码云基地团队整理撰写,若转载请注明出处。
公众号搜索神州数码云基地,回复【AI】进入AI社群讨论。


















 4812
4812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









