



序列化和反序列化
序列化是通过某种算法将存储于内存中的对象转换成可以用于持久化存储或者通信的形式的过程
反序列化是将这种被持久化存储或者通信的数据通过对应解析算法还原成对象的过程,它是序列化的逆向操作
为什么需要序列化
前端请求后端接口数据的时候,后端需要返回 JSON 数据,这就是后端将 Java 堆中的对象序列化为了 JSON 数据传给前端,前端可以根据自身需求直接使用或者将其反序列化为 JS 对象
RPC 远程调用过程中,调用者和被调用者必须约定好序列化和反序列化算法,比如 A 应用将 User 对象序列化为了 JSON 数据传给 B 应用,User 对象数据为 {"id": 1, "name": "long"},到达 B 应用的时候需要将这些数据反序列化为对象,如果此时 B 应用的反序列化算法是 XML 的话那么肯定就解析失败了,所以必须都得约定好他们都采用 JSON 序列化算法,那么基于 JSON 标准就能成功解析出 User 对象
Java 中的序列化
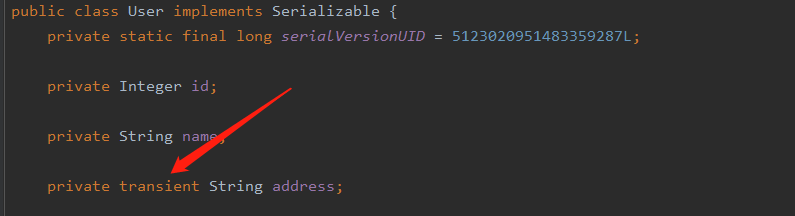
transient
如果某个字段我们不想通过 Java 默认序列化机制输出,我们就可以通过该字段来表明当前字段不需要被序列化
writeObject 和 readObject
我们想通过自定义的方式将 address 数据序列化
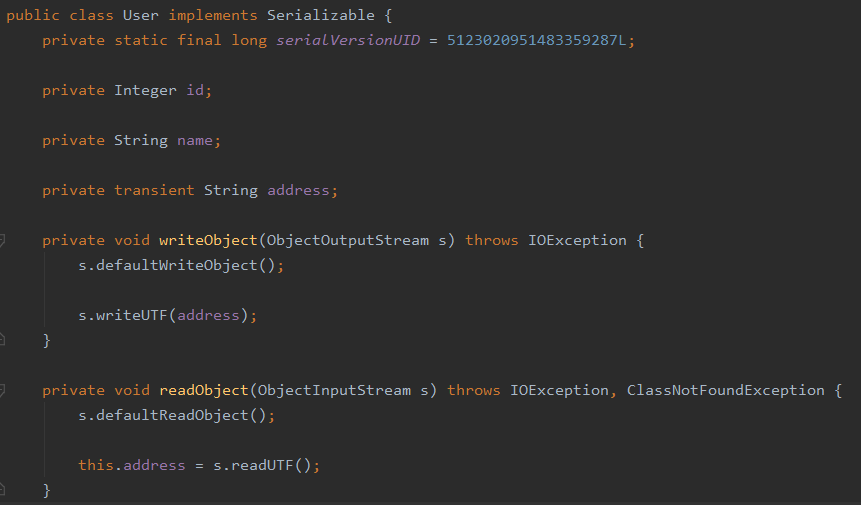
其中的 writeObject 作用于写序列化数据的时候会反射调用该方法,readObject 会在反序列化的时候调用
serialVersionUID 的作用
如果我们没有自定义 serialVersionUID 的话,会根据当前类的信息自动生成,如果当前类没有做修改那么生成的 serialVersionUID 是一致的,如果修改后 serialVersionUID 就会改变导致无法反序列化,所以在日常使用中我们一定要填写该字段
Java 序列化的实现原理
最开始看代码的时候,不要一下就陷入全部细节,我们应该只看我们目前关注的点,当认识逐渐深刻之后再来看一些细节,不然的话容易看的一脸懵逼
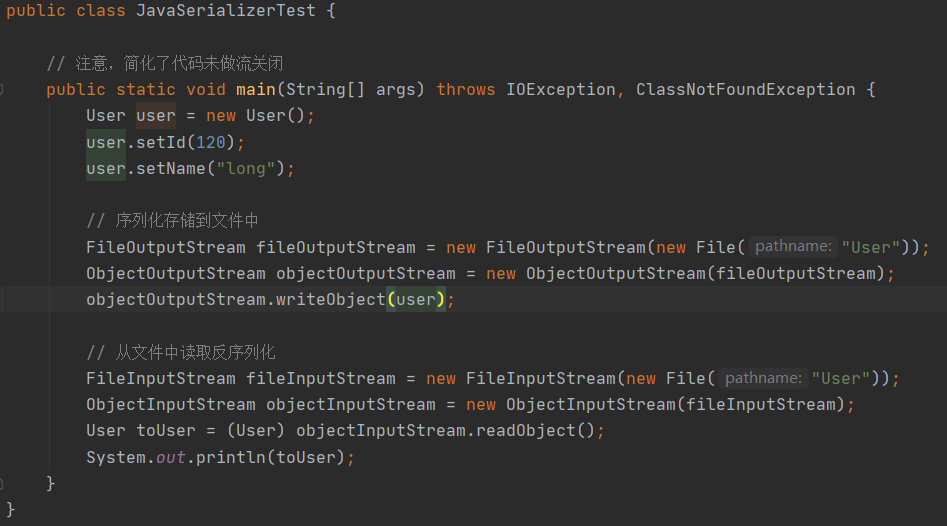
首先调用objectOutputStream.writeObject(user); 然后调用 writeObject0(obj, false); 在这个方法里面有这样一段代码
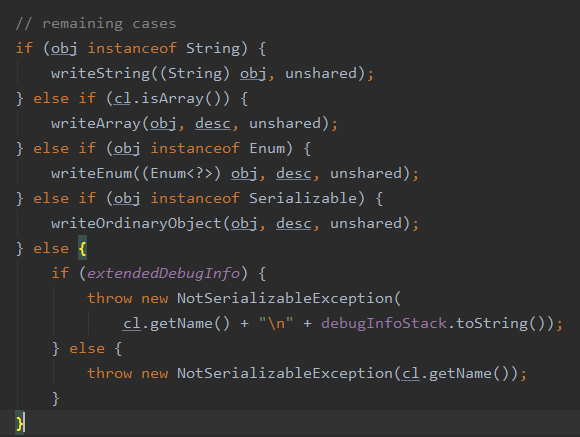
这里可以看到如果我们要序列化的是一个对象并且它没有实现 Serializable 接口的话就会直接抛出 NotSerializableException,由于我们目前传入的是 User 对象它实现了 Serializable 所以会进入到 writeOrdinaryObject 中
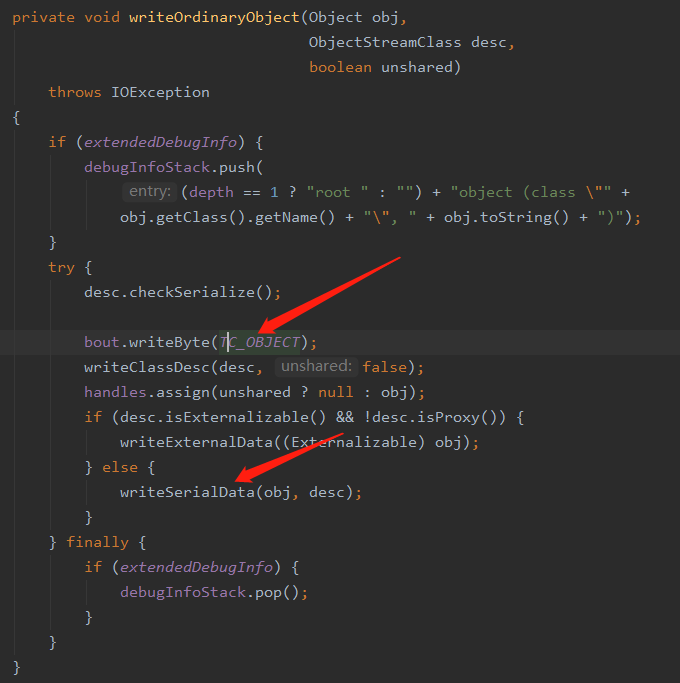
首先将 TC_OBJECT 这一个对象标志位写入到流中,标识着当前开始写一个的数据是一个对象,然后调用 writeSerialData 开始写入具体数据
-
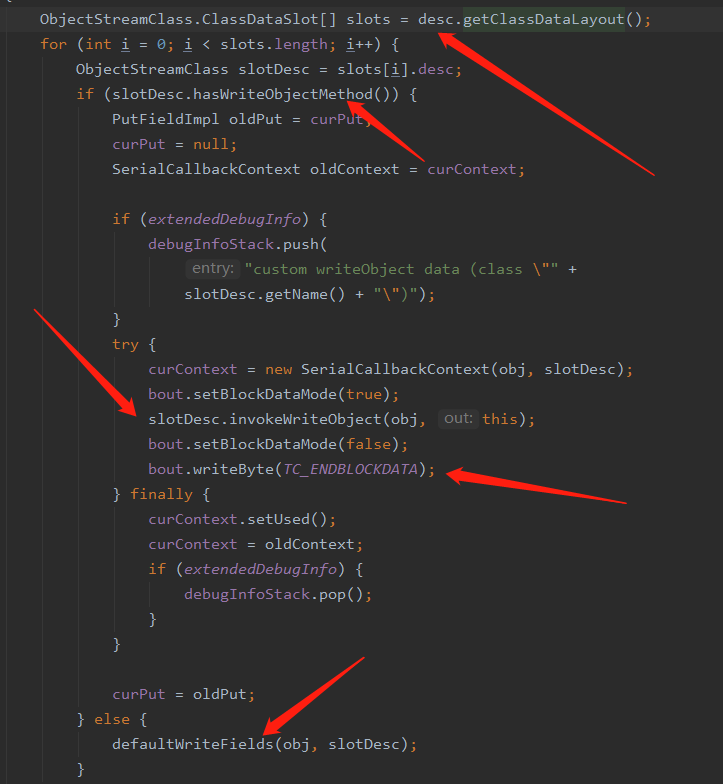
首先会获得 ClassDataSlot 我们可以把它看做是提供了序列化对象的辅助手段
-
在此通过 ClassDataSlot 去检查序列化对象中是否实现了 writeObject 这个方法,那么这个 writeObjectMethod 是在什么时候初始化的呢?马上会讲到

-
如果实现了 writeObject 我们就去反射调用该方法
-
如果当前类没有实现 writeObject 方法就调用默认的 defaultWriteFields 去写数据
如何知道对象是否实现了 writeObject(ObjectOutputStream out) 和 readObject
在上文我们知道是通过 writeObjectMethod 这个来判断的,那么这个字段是在哪里初始化的呢,我们回到 ObjectOutputStream 的 writeObject0 方法,在调用后续的 writeOrderinaryObject 方法之前有这样一段代码
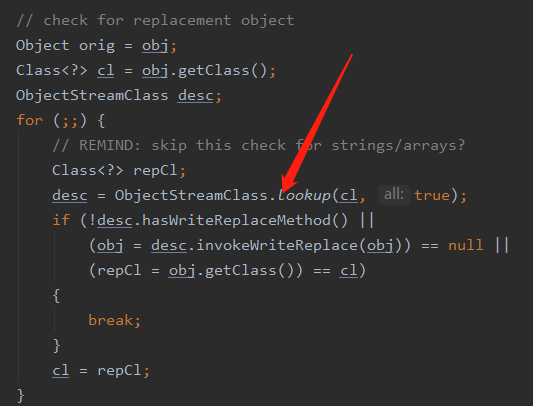
然后会调用到这段代码
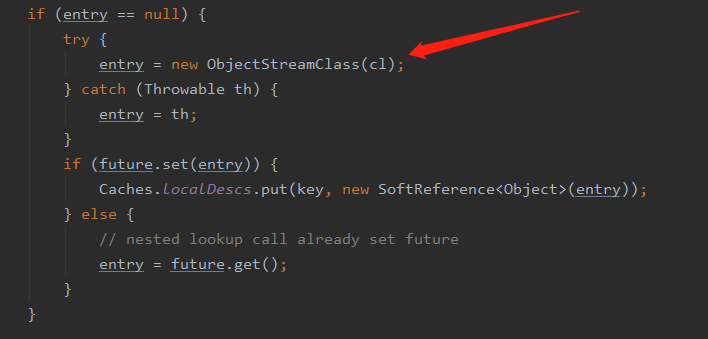
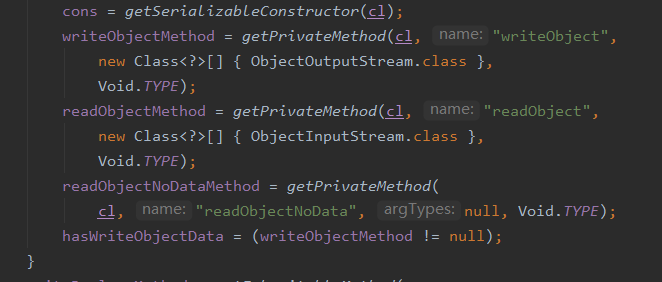
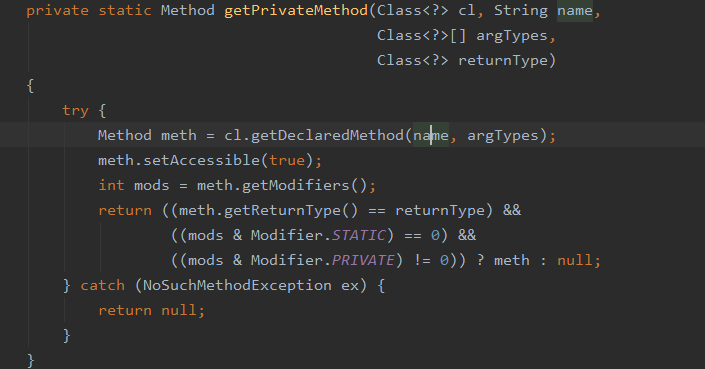
在创建 ObjectStreamClass 对象的过程中会通过反射去拿到当前类的方法,然后根据方法名 writeObject 和参数 ObjectOutputStream 去判断有没有这个方法,有的话就返回没有就返回为 null
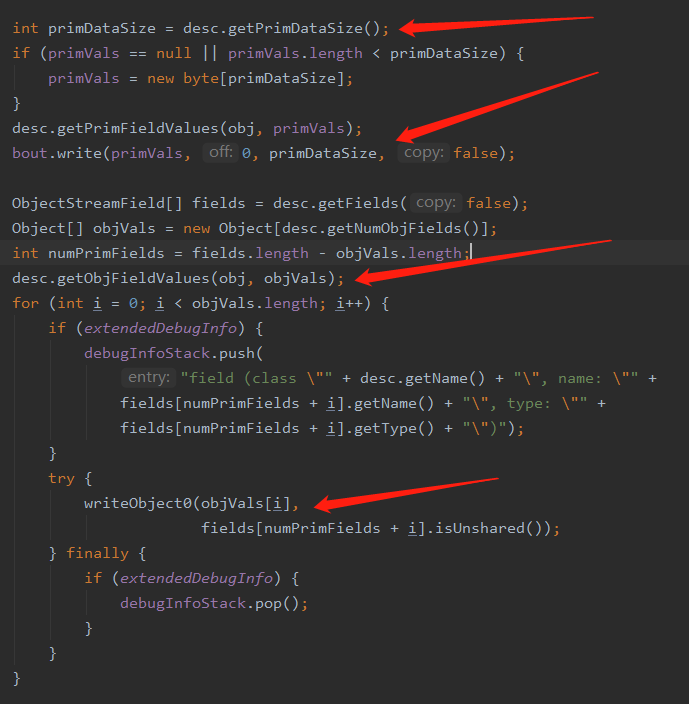
然后我们回到 defaultWriteFields(Object obj, ObjectStreamClass desc) 继续来看
-
拿到当前需要写入数据的具体长度
-
通过反射去获取当前数据的值,ObjectStreamClass desc 这个对象可能是个 Object 可能是基本类型等,此时拿到的是 User 对象,所以取到的值默认为空,因为这里只是写入它的具体字段的数据
-
通过反射拿到当前对象的所有的值
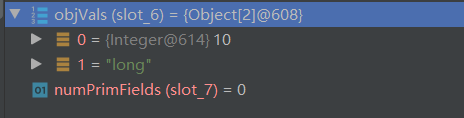
-
挨个调用 writeObject0 写入具体的值,首先调用的是 Integer 由于它是一个包装类,Integer 继承了 Number,Number 类实现了 Serializable 所以会和 User 对象走一样的流程到达次数(可以自己 DEBUG 一下)然后拆包取出值调用
-
随后就进入到了 String 的写入,再次调用 writeObject0,又到达 ObjectOutputStream 的 writeObject0,后续就有所区别了因为这里写入的具体类型是 String
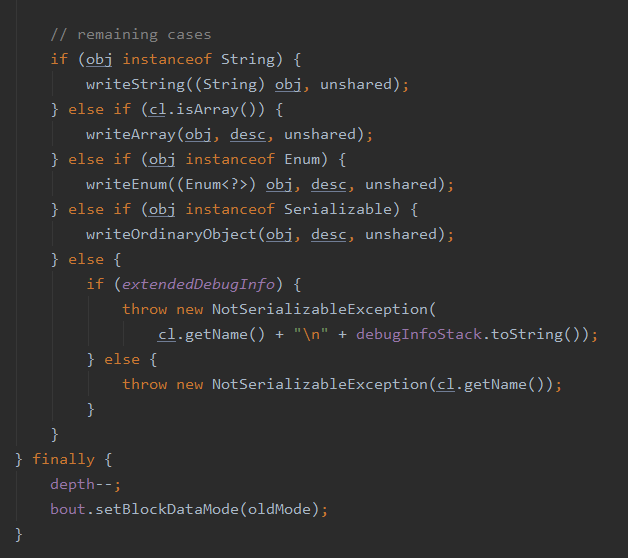
因为 Integer 也实现了 Serializable 并且这里没有针对他坐特殊处理,所以它会走 writeOrdinaryObject,而 String 这里判断了,需要去调用 writeString
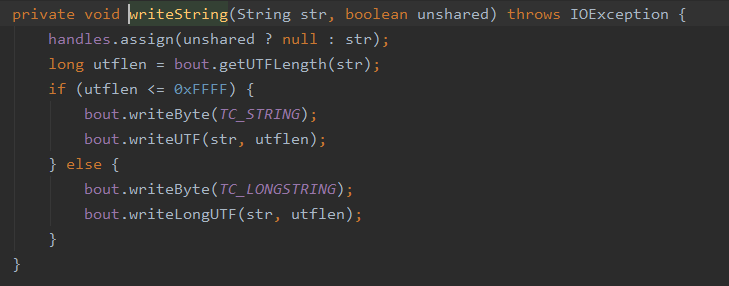
这个方法也比较简单首先写入 String 标志位然后写入具体的数据和长度,其它的类型也是一样会走这里不同的分支,最终将数据写入到流中
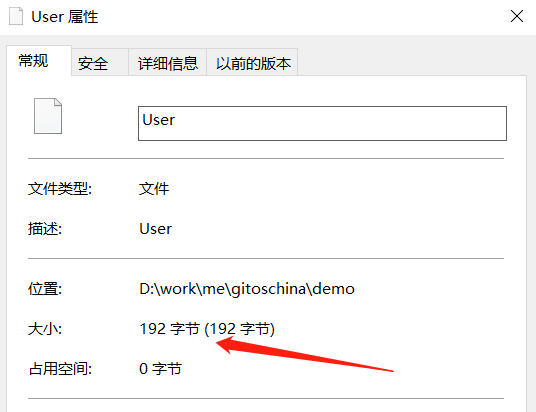
最后来看一下序列化后占用了多少个字节
Java 反序列化的原理
反序列化其实就是序列化的逆向过程,如果你看懂了序列化的关键代码,那么看这个过程就不会很难,下面贴出关键代码做出分析
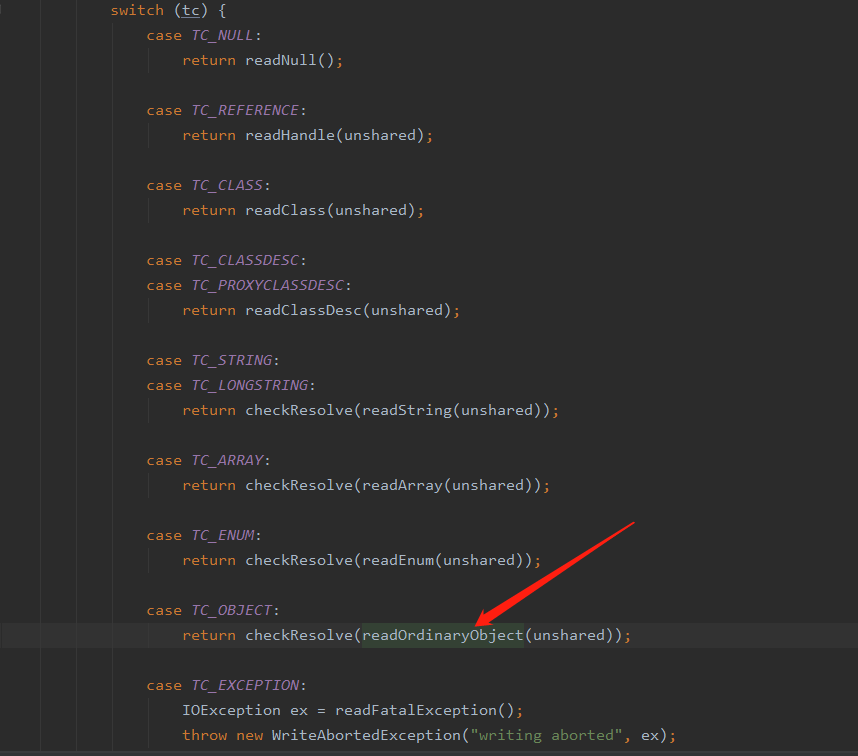
这里能够看到会根据反序列对象的具体类型分别做不同的处理,我们当前的对象是 User 对象所以会进入箭头指向的方法
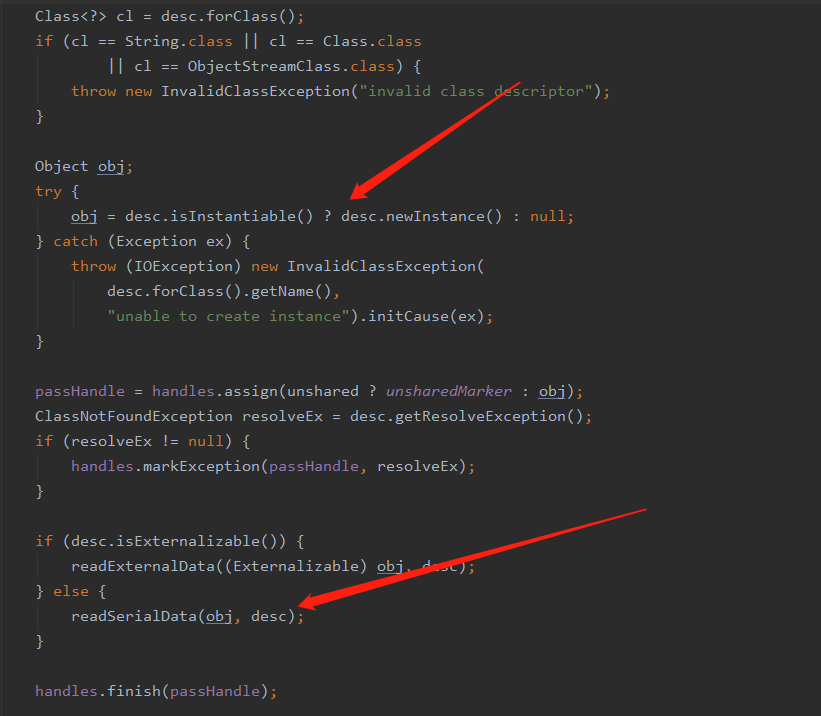
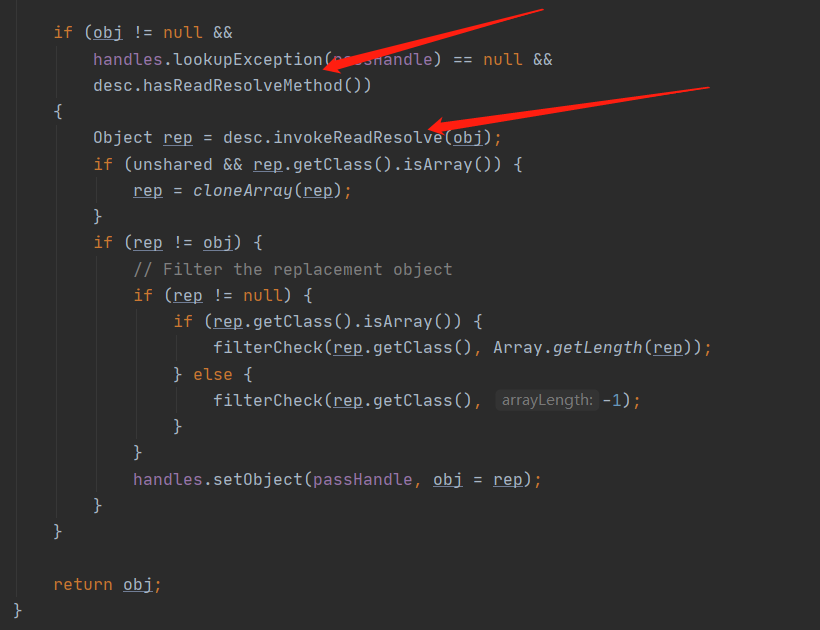
在该方法中会去创建一个实例对象,其中 isInstantiable 这个方法是去判断构造器是否初始化了,同时这里还会将 writeObject 和 readObject 方法设置好,然后会通过 hasReadResolveMethod 方法来确定是否实现了 readObject 方法如果实现了就反射调用 readObject 方法
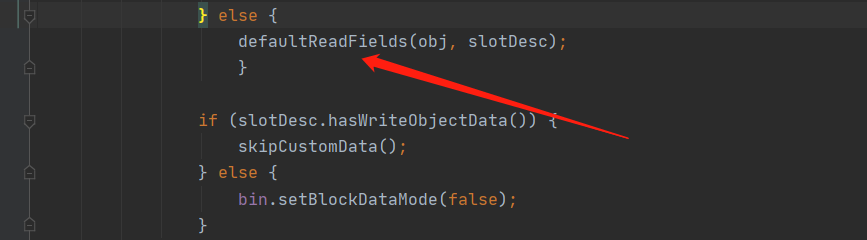
在调用了 readSerialData 方法之后会调用 defaultReadFields 方法来设置字段的值,当前的 Obj 是 User 对象
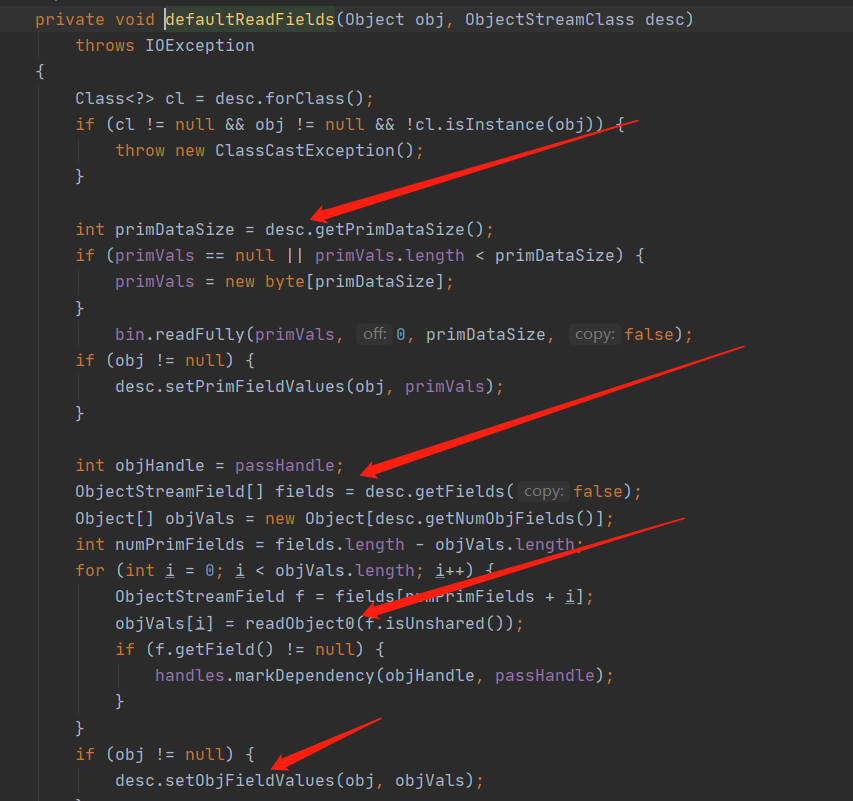
- 获取当前传入对象数据长度由于传入的是 User 空对象,所以此时长度为空
- 反射获取到需要被反序列化的所有字段,并且创建对应的数组来保存对应的值,此时获取到 User 对象有 2 个字段 id 和 name
- 然后开始递归调用 readObject0 处理完所有需要被反序列化的字段,就一当前的 id 和 name 举例
- 和上文序列化一样 id 是 Integer 包装类所以会被识别为 Object 当再次到达这个方法的时候,在第一步 primDataSize 数据长度为 4 因为是 int 类型 4 个字节
- 到第二步,因为是 Integer 没有其它需要被反序列化的字段它只有本身的拆包后的值,所以会到达第四步设置当前 id 的值
- 设置当前基本类型字段的值
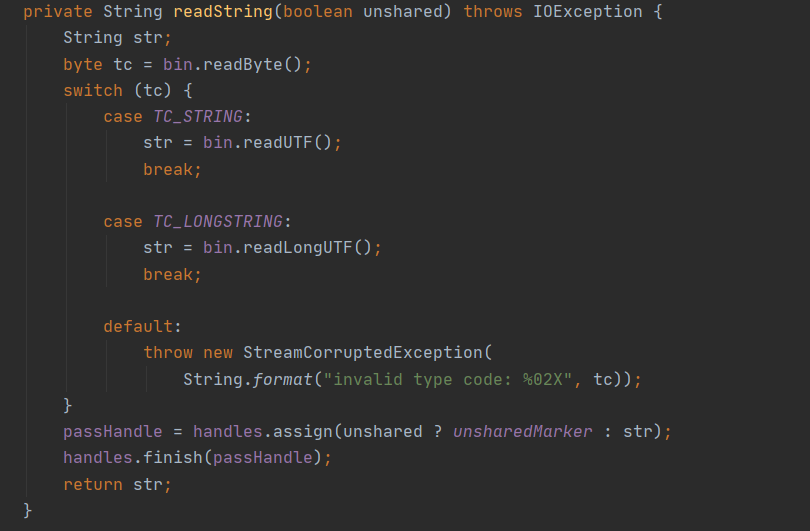
对于 String 类型来说,在反序列化第一张中会调用读取对应的值
其它的序列化方式
一个新的技术的诞生都是有一定的原因和背景的,比如说 Java 原生序列化后数据比较大,传输效率低,同时又又无法跨语言通信,所以很多人选择使用 XML 的来序列化数据,XML 序列化后倒是解决了跨语言通信的问题,但是它序列化后的数据比原生数据还要大,所以就诞生了 JSON 序列化,他支持跨语言,并且序列化后的数据远远小于前 2 者,最后有人想进一步的优化大小就引入了 Protobuf 它具备 压缩的功能,被压缩的数据小于 JSON 序列化后的数据。
其它的序列化方式
- XML
- JSON
- Jackson
- FastJson
- Hessian
- thrift
- protobuf
- …
后面会写一篇文章就会来聊聊其它的序列化方式对比下他们的性能和底层使用原理
很多人上来就说想学习黑客,但是连方向都没搞清楚就开始学习,最终也只是会无疾而终!黑客是一个大的概念,里面包含了许多方向,不同的方向需要学习的内容也不一样。
算上从学校开始学习,已经在网安这条路上走了10年了,无论是以前在学校做安全研究,还是毕业后在百度、360从事内核安全产品和二进制漏洞攻防对抗,我都深知学习方法的重要性。没有一条好的学习路径和好的学习方法,往往只会事倍功半。
网络安全再进一步细分,还可以划分为:网络渗透、逆向分析、漏洞攻击、内核安全、移动安全、破解PWN等众多子方向。今天的这篇,主要针对网络渗透方向,也就是大家所熟知的“黑客”的主要技术,其他方向仅供参考,学习路线并不完全一样,有机会的话我再单独梳理。
学前感言
- 1.这是一条坚持的道路,三分钟的热情可以放弃往下看了
- 2.多练多想,不要离开了教程什么都不会了.最好看完教程自己独立完成技术方面的开发.
- 3.有时多google,baidu,我们往往都遇不到好心的大神,谁会无聊天天给你做解答.
- 4.遇到实在搞不懂的,可以先放放,以后再来解决
网络安全零基础入门学习路线&规划
下面给大家总结了一套适用于网安零基础的学习路线,应届生和转行人员都适用,学完保底6k!就算你底子差,如果能趁着网安良好的发展势头不断学习,日后跳槽大厂、拿到百万年薪也不是不可能!
初级网工
1、网络安全理论知识(2天)
①了解行业相关背景,前景,确定发展方向。
②学习网络安全相关法律法规。
③网络安全运营的概念。
④等保简介、等保规定、流程和规范。(非常重要)
2、渗透测试基础(一周)
①渗透测试的流程、分类、标准
②信息收集技术:主动/被动信息搜集、Nmap工具、Google Hacking
③漏洞扫描、漏洞利用、原理,利用方法、工具(MSF)、绕过IDS和反病毒侦察
④主机攻防演练:MS17-010、MS08-067、MS10-046、MS12-20等
3、操作系统基础(一周)
①Windows系统常见功能和命令
②Kali Linux系统常见功能和命令
③操作系统安全(系统入侵排查/系统加固基础)
4、计算机网络基础(一周)
①计算机网络基础、协议和架构
②网络通信原理、OSI模型、数据转发流程
③常见协议解析(HTTP、TCP/IP、ARP等)
④网络攻击技术与网络安全防御技术
⑤Web漏洞原理与防御:主动/被动攻击、DDOS攻击、CVE漏洞复现
5、数据库基础操作(2天)
①数据库基础
②SQL语言基础
③数据库安全加固
6、Web渗透(1周)
①HTML、CSS和JavaScript简介
②OWASP Top10
③Web漏洞扫描工具
④Web渗透工具:Nmap、BurpSuite、SQLMap、其他(菜刀、漏扫等)

恭喜你,如果学到这里,你基本可以从事一份网络安全相关的工作,比如渗透测试、Web 渗透、安全服务、安全分析等岗位;如果等保模块学的好,还可以从事等保工程师。薪资区间6k-15k
到此为止,大概1个月的时间。你已经成为了一名“脚本小子”。那么你还想往下探索吗?
7、脚本编程(初级/中级/高级)
在网络安全领域。是否具备编程能力是“脚本小子”和真正黑客的本质区别。在实际的渗透测试过程中,面对复杂多变的网络环境,当常用工具不能满足实际需求的时候,往往需要对现有工具进行扩展,或者编写符合我们要求的工具、自动化脚本,这个时候就需要具备一定的编程能力。在分秒必争的CTF竞赛中,想要高效地使用自制的脚本工具来实现各种目的,更是需要拥有编程能力.
零基础入门,建议选择脚本语言Python/PHP/Go/Java中的一种,对常用库进行编程学习; 搭建开发环境和选择IDE,PHP环境推荐Wamp和XAMPP, IDE强烈推荐Sublime; ·Python编程学习,学习内容包含:语法、正则、文件、 网络、多线程等常用库,推荐《Python核心编程》,不要看完; ·用Python编写漏洞的exp,然后写一个简单的网络爬虫; ·PHP基本语法学习并书写一个简单的博客系统; 熟悉MVC架构,并试着学习一个PHP框架或者Python框架 (可选); ·了解Bootstrap的布局或者CSS。
8、超级网工
这部分内容对零基础的同学来说还比较遥远,就不展开细说了,贴一个大概的路线。感兴趣的童鞋可以研究一下,不懂得地方可以【点这里】加我耗油,跟我学习交流一下。

网络安全学习路线&学习资源

扫描下方卡片可获取最新的网络安全资料合集(包括200本电子书、标准题库、CTF赛前资料、常用工具、知识脑图等)助力大家提升进阶!

结语
网络安全产业就像一个江湖,各色人等聚集。相对于欧美国家基础扎实(懂加密、会防护、能挖洞、擅工程)的众多名门正派,我国的人才更多的属于旁门左道(很多白帽子可能会不服气),因此在未来的人才培养和建设上,需要调整结构,鼓励更多的人去做“正向”的、结合“业务”与“数据”、“自动化”的“体系、建设”,才能解人才之渴,真正的为社会全面互联网化提供安全保障。
特别声明:
此教程为纯技术分享!本书的目的决不是为那些怀有不良动机的人提供及技术支持!也不承担因为技术被滥用所产生的连带责任!本书的目的在于最大限度地唤醒大家对网络安全的重视,并采取相应的安全措施,从而减少由网络安全而带来的经济损失!!!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}