




 本文探讨了端到端学习与传统机器学习在流程、特征提取及数据标注方面的区别。端到端学习简化了特征设计过程,减少了人工干预,使模型能够直接从原始数据学习到最终结果。
本文探讨了端到端学习与传统机器学习在流程、特征提取及数据标注方面的区别。端到端学习简化了特征设计过程,减少了人工干预,使模型能够直接从原始数据学习到最终结果。
相对于深度学习,传统机器学习的流程往往由多个独立的模块组成,比如在一个典型的自然语言处理(Natural Language Processing)问题中,包括分词、词性标注、句法分析、语义分析等多个独立步骤,每个步骤是一个独立的任务,其结果的好坏会影响到下一步骤,从而影响整个训练的结果,这是非端到端的。
而深度学习模型在训练过程中,从输入端(输入数据)到输出端会得到一个预测结果,与真实结果相比较会得到一个误差,这个误差会在模型中的每一层传递(反向传播),每一层的表示都会根据这个误差来做调整,直到模型收敛或达到预期的效果才结束,这是端到端的。
两者相比,端到端的学习省去了在每一个独立学习任务执行之前所做的数据标注,为样本做标注的代价是昂贵的、易出错的。
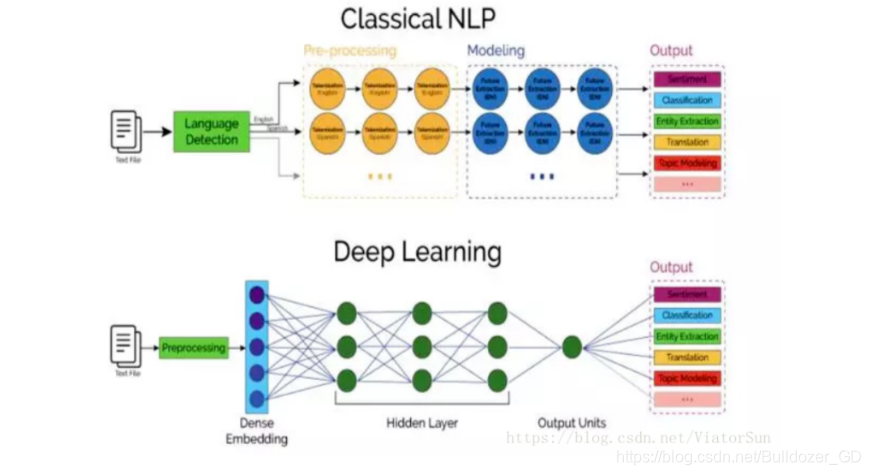
端到端指的是输入是原始数据,输出是最后的结果,原来输入端不是直接的原始数据,而是在原始数据中提取的特征,这一点在图像问题上尤为突出,因为图像像素数太多,数据维度高,会产生维度灾难,所以原来一个思路是手工提取图像的一些关键特征,这实际就是就一个降维的过程。
那么问题来了,特征怎么提?
特征提取的好坏异常关键,甚至比学习算法还重要,举个例子,对一系列人的数据分类,分类结果是性别,如果你提取的特征是头发的颜色,无论分类算法如何,分类效果都不会好,如果你提取的特征是头发的长短,这个特征就会好很多,但是还是会有错误,如果你提取了一个超强特征,比如染色体的数据,那你的分类基本就不会错了。
这就意味着,特征需要足够的经验去设计,这在数据量越来越大的情况下也越来越困难。于是就出现了端到端网络,特征可以自己去学习,所以特征提取这一步也就融入到算法当中,不需要人来干预了。
但是也不是不需要数据标注,,而是不需要中间环节的数据标注,但是起始环节的输入还是需要数据标注的,端到端模型就好比黑箱操作,只需要将数据和对应标签输入到模型当中就可以了,通过模型的学习之后,直接输出结果,而中间的学习过程并不需要我们人为干涉,我们只需要关注输入端和输出端即可,这就是「输入」端到「输出」端的含义。
参考链接:https://www.jianshu.com/p/f8ed2744be97




















 1244
1244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











