



本次的Task是了解书生浦语大模型全链路开源开放体系,并形成笔记;
1.书生大模型发展历程如下:经历了一年时间,性能天梯显示InternLM2-Chat-7B与ChatGPT相近,作为国产开源模型是很不容易的;

2. 2.5版本的亮点是:
- 原生推理性能相对2.0版本提升20%;
- 支持100万字上下文;
- 有自主规划和搜索完成复杂任务的能力;
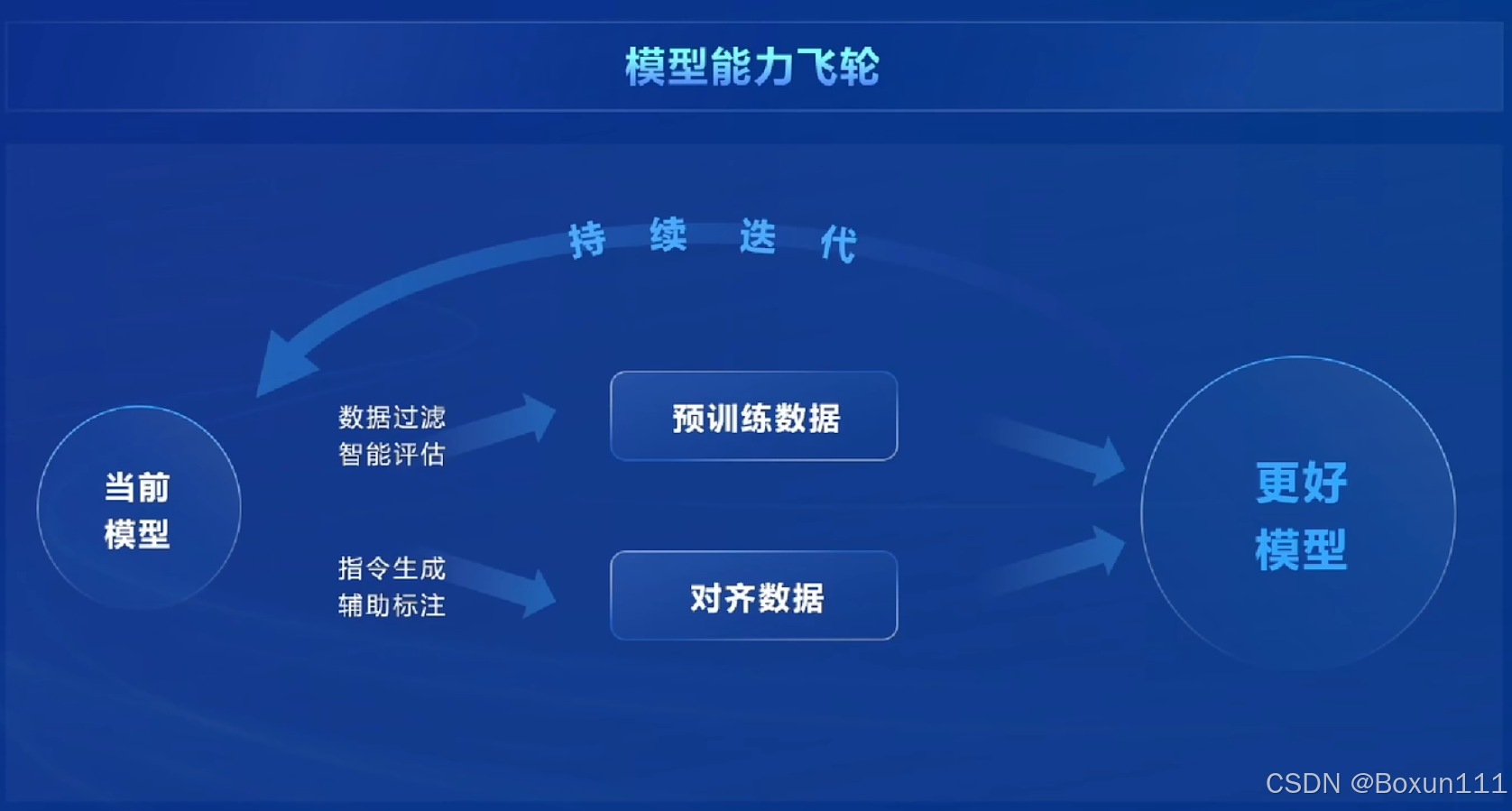
3. 核心研发思路如下:反馈的过程,数据质量驱动的模型迭代更新;预训练数据和对齐数据的操作;如何获得高质量数据?分为三方面:基于规则的数据构造(代码、公式、数学题解);基于模型的数据扩充(现有模型、商业模型);基于人类反馈的强化数据生成(人类对生成结果的满意度排序);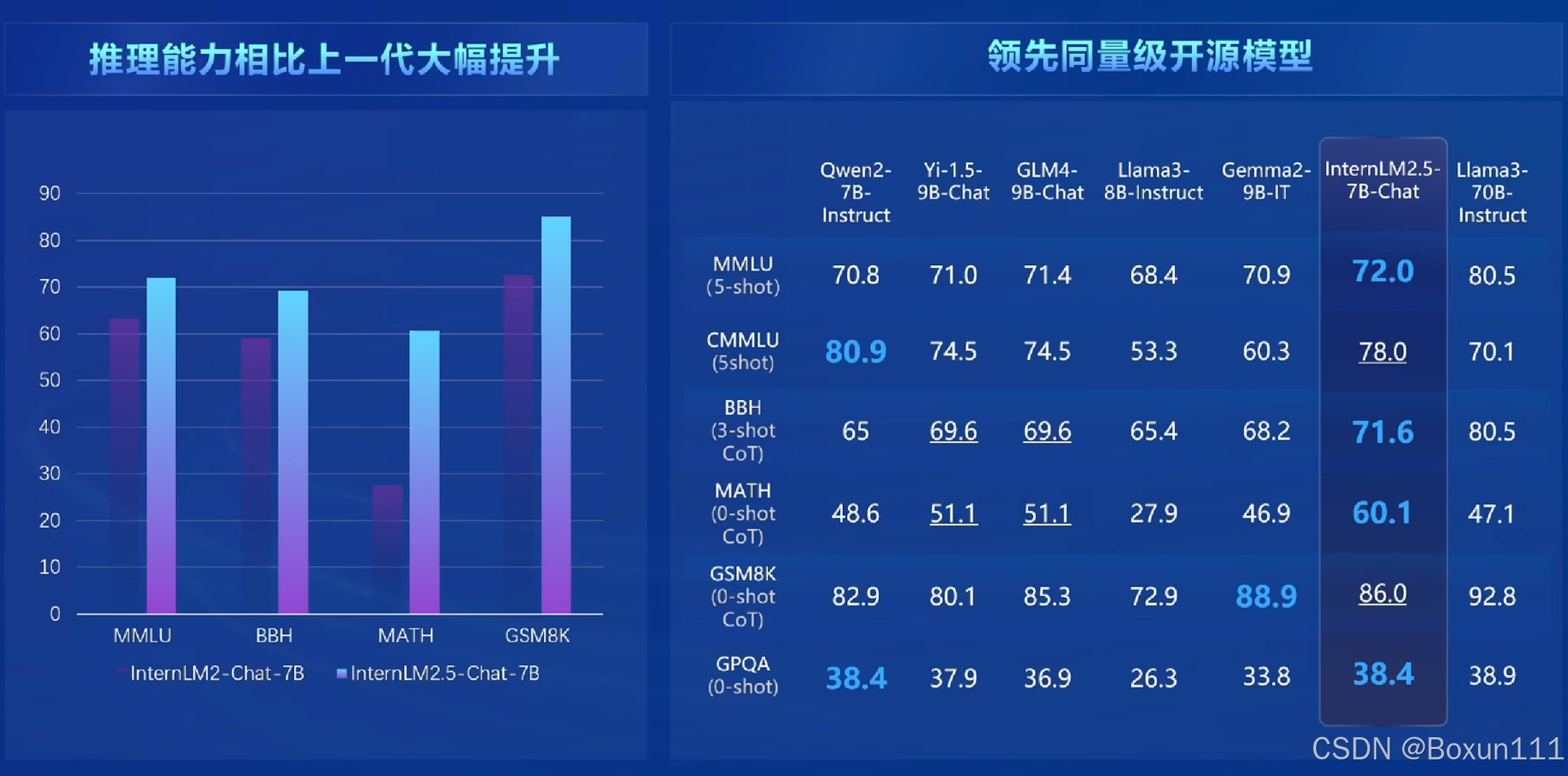
4. 模型的记忆能力非常好,对于给出非常长的参考资料(一本书),定位任何位置背景信息的能力非常好;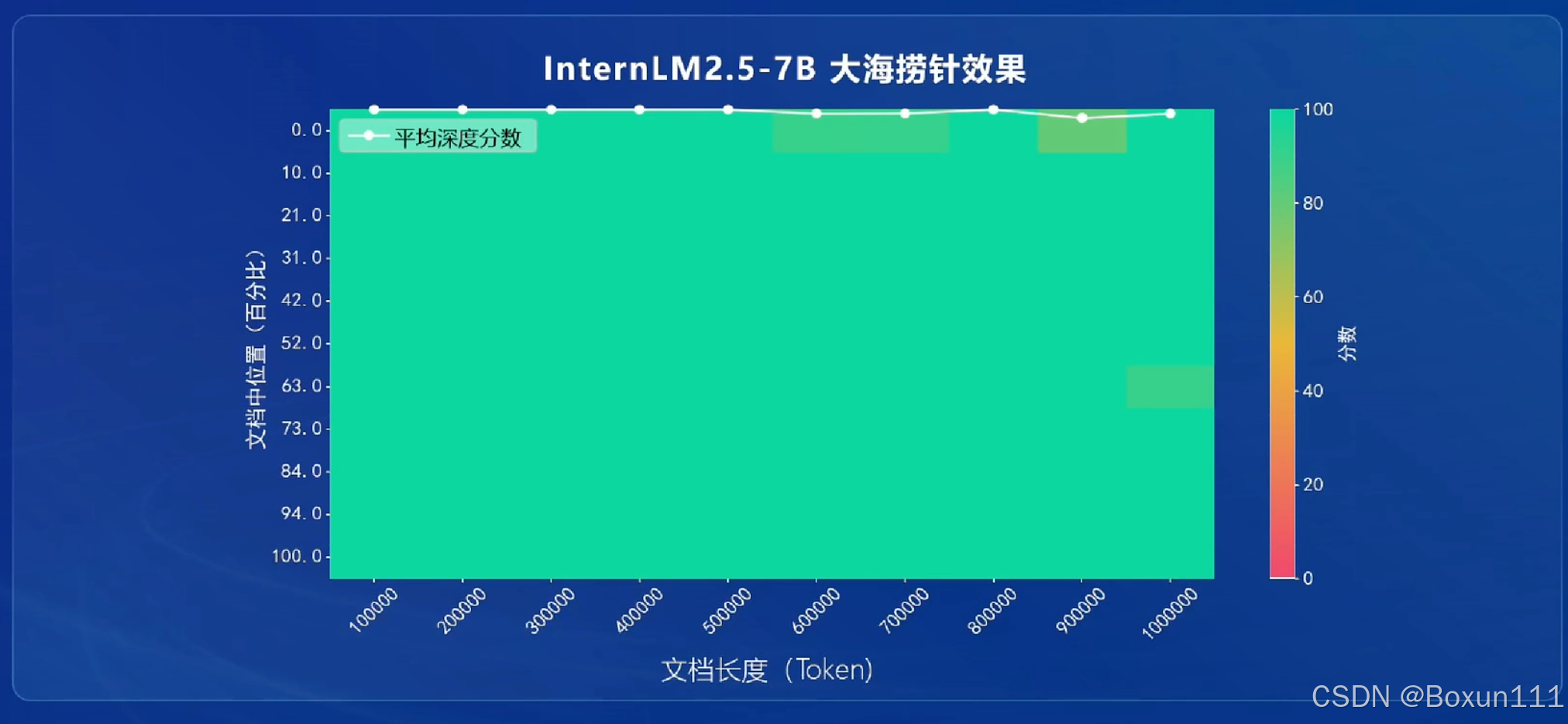
5.MindSearch相关的推理能力,相关结构如图所示:

6. 20B模型出现了涌现现象,适用于实际生产,从模态来分:灵笔(图像文本多模态)、数学、文曲星(高考题目)
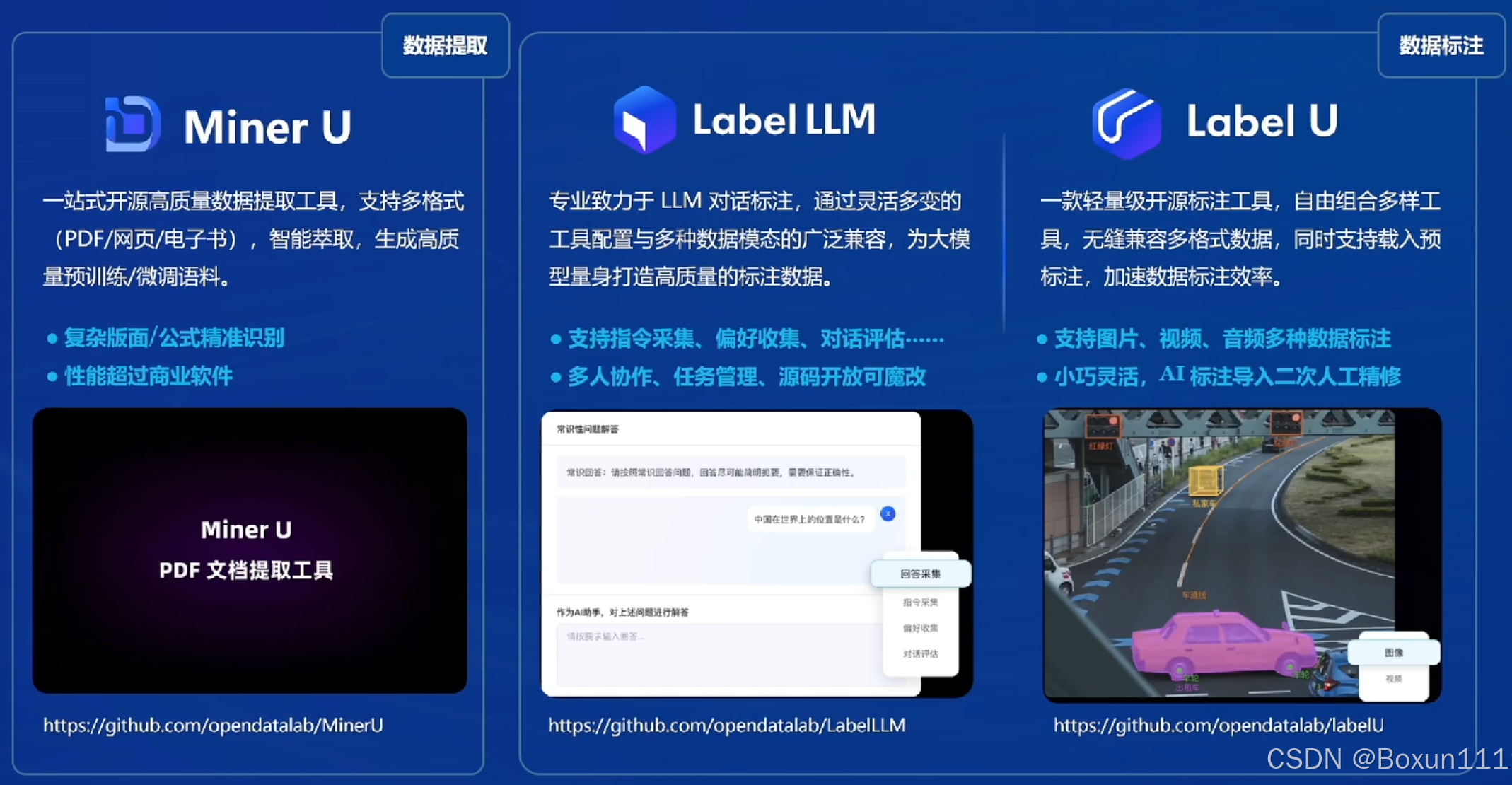
7. 开源体系如下:在数据、预训练、微调、应用、评测、部署都有强大的支撑,我个人比较感兴趣的是看看数据语料库,最重要的是微调、应用(比如使用茴香豆构建自己的专业知识库)和部署方面应用于实际生产应用;

8.对于传统费时费力的数据标注工作,也有专业的工具支持,其中Label U支持多模态,我更感兴趣;
9. 微调的亮点是最低只需8GB显存即可微调7B模型,0显存浪费;
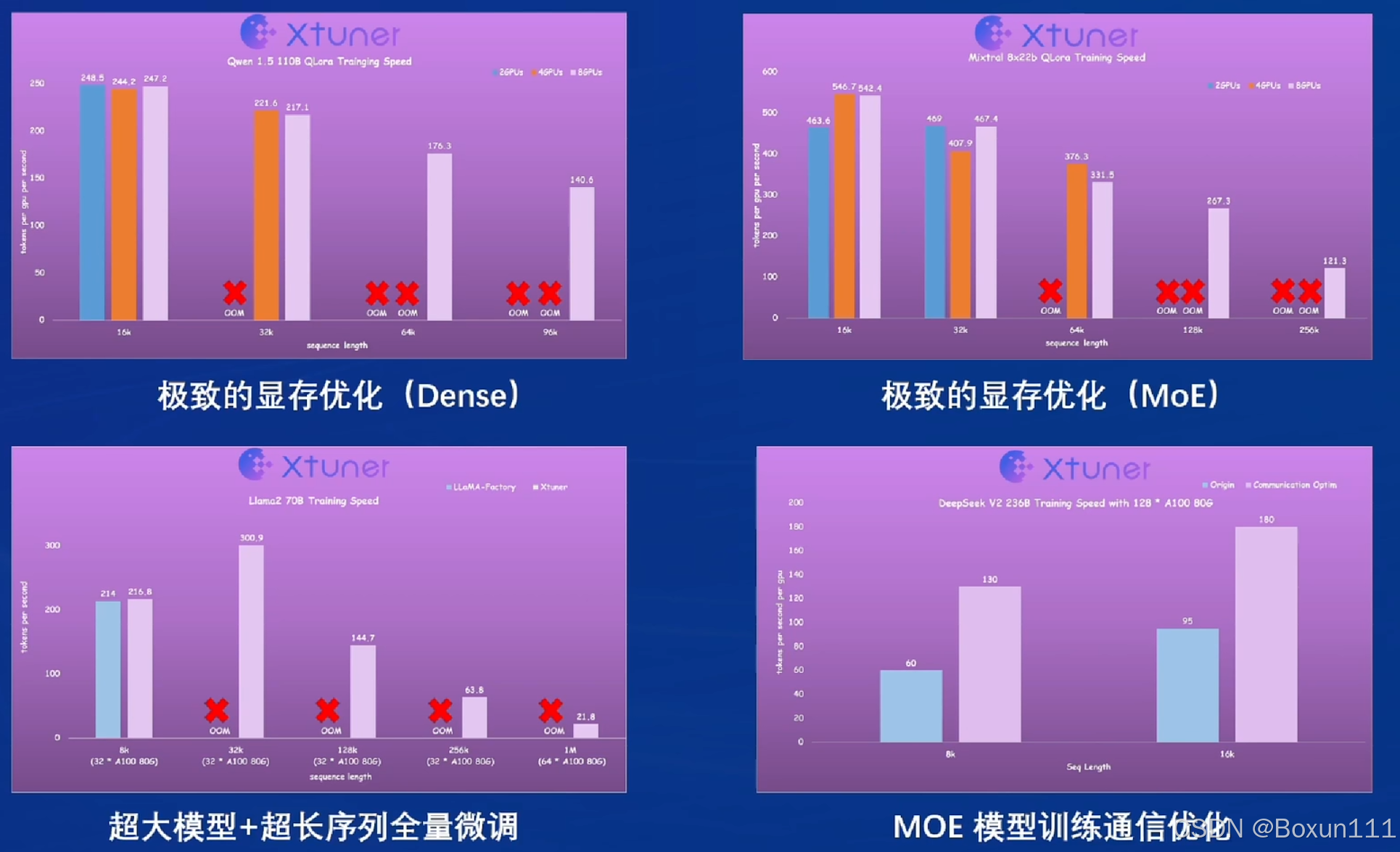
10. 部署支持各种接口,非常好;

11. 对于智能体的构建,提供轻量级Lagent框架(支持多模态)以及MindSearch(模拟人脑的思维路径);

12. 知识库搭建茴香豆工具对于商用非常友好,尤其是其中的实战派和扩展性强功能非常吸引我,期待接下来进一步学习;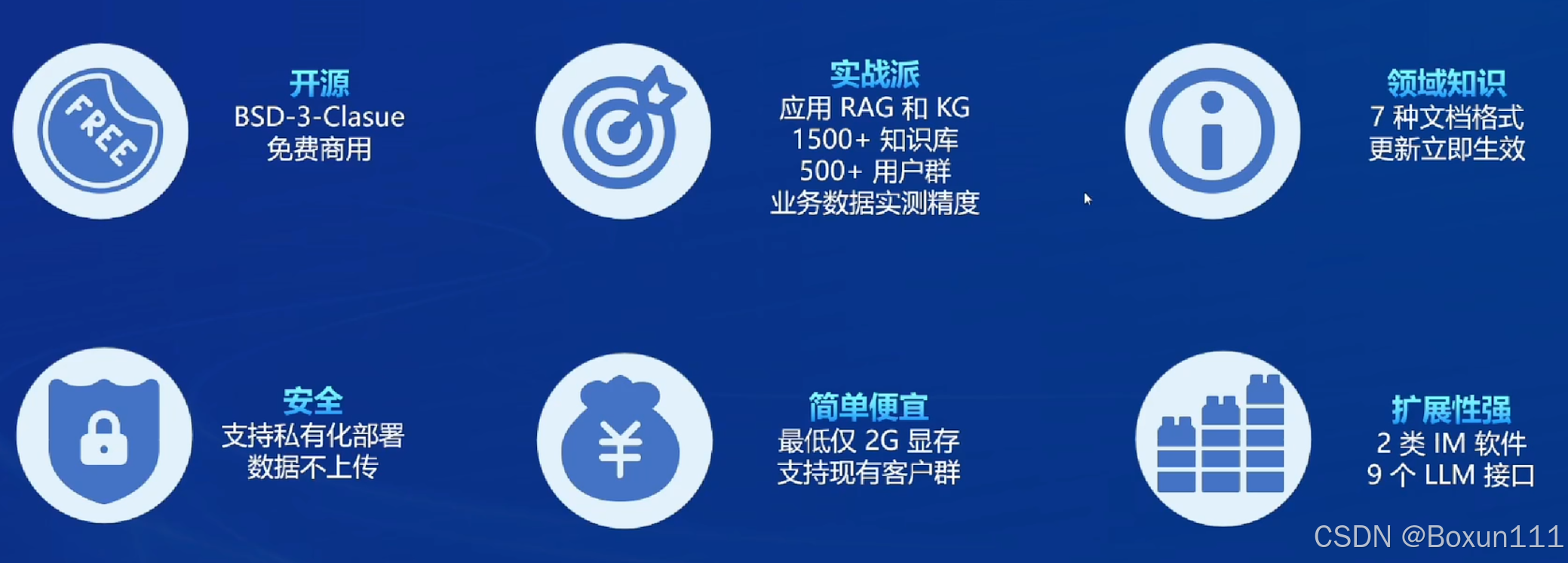

















 1040
1040

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









