




古罗马,“乘法”是只有御用数学家才能理解的深奥概念——而当阿拉伯数字出现,孩童亦能于纸上演算。
新工具不仅提升效率,还可为前人所不能。作为活跃开发领域之一,区块链新技术、工具、平台、语言与框架层出不穷,然而面对纷繁复杂的选择,开发者难以面面俱到。《区块链大本营 | 新工具》栏目每周将为开发者介绍最值得关注的新技术与工具。未来,我们还将多角度、系统地为项目选型提供指南。
“这是应对区块链极繁主义的最好手段”
——Parity创始人Gavin Wood如是说,他也是Ethereum创始人和Solidity设计者之一。
上周,Gavin在柏林Web3峰会现场演示了一种新框架——Substrate。他使用一台刚启封的Macbook Pro,从编写第一行代码,到发布区块链,用时不足60分钟。Substrate目的是让发布区块链就像发布智能合约一样容易。

最大自由,最少代价
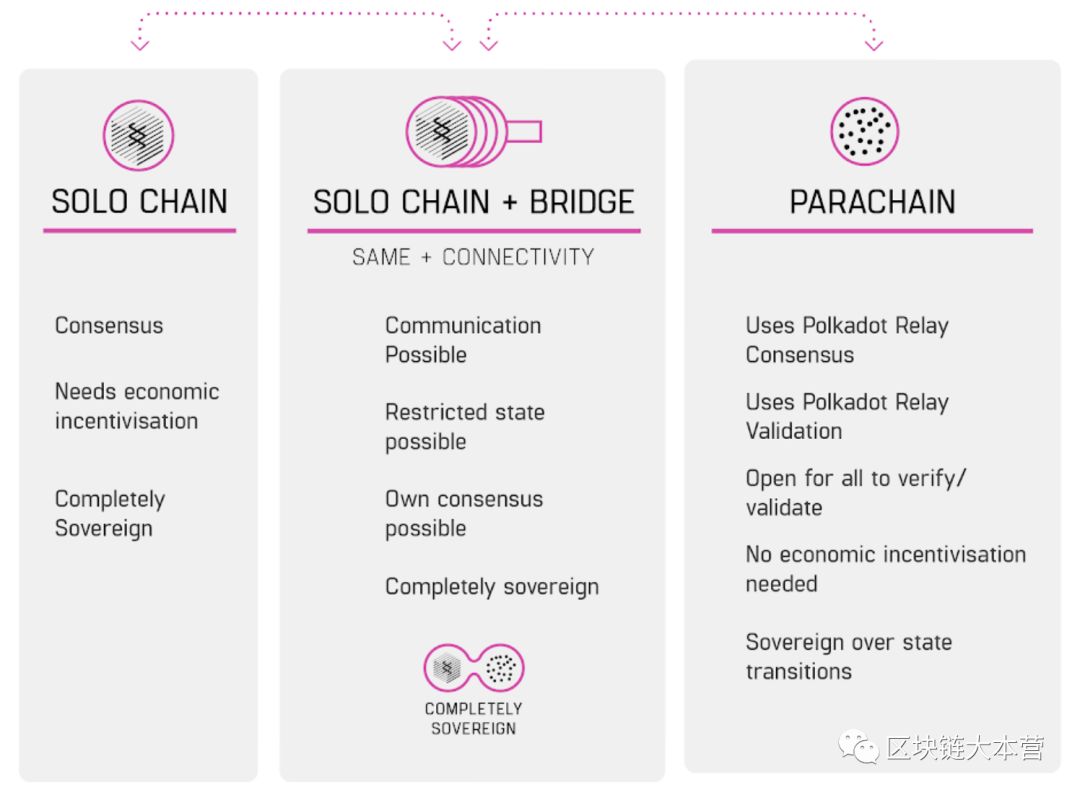
Parity的明星项目Polkadot就是基于Substrate构建的——前者是一种由多条链,异构组成的区块链集合,其目的是成为不同区块链间的媒介。Substrate先前的主要目的是让开发者能在Polkadot上快速启动平行链,不过Substrate框架本身还具备发布独立区块链的能力,这让它成为独立于Polkadot的项目,不依赖后者的开发进度,本月晚些时候,Substrate 1.0-beta将会公开发布。
与Express或其他Web应用框架类比,Substrate是用来构建分布式或去中心化系统的,如加密货币项目或消息总线系统。就如大多数Web应用程序不需要重新实现HTTP一样,Gavin Wood认为,所有人都从头构建网络和共识代码,非常浪费精力。使用Substrate来构建新项目,开发者所要做的,就是在代码调用少量函数,就能获得各种密码学模板,以及定制、搭建和发布新区块链所需要的方方面面,“Substrate为区块链开发者提供最大限度的自由,花费最少的精力”。
高通用技术栈
Substrate在设计时,考虑了支持大多数现有和未来可能出现的区块链应用场景。其技术栈主要由以下几个具备高通用和扩展潜能的部分组成。

1. 对区块链应用架构来说,State Transition Function(STF)代表其核心商业逻辑,STF的功能集合、有何种限制,决定了区块链的应用场景。Substrate运行时采用WebAssembly的一个子集,具有跨平台和轻量的特点。在1.0-beta版本中,开发者可以使用纯Rust、C++和C编写STF;通过WebAssembly支持的其他语言,将在后续引入。
2. 网络部分基于Libp2p,开箱即用。对于需要其他网络消息支持的区块链应用,未来版本的Substrate计划引入一个网络拓扑API。
3. 为了适应快速应用开发,Substrate支持包括Polkadot SHAFT(GRANDPA)在内的多种共识算法。密码学数据库后端及块格式,都可以定制或重写。在1.0-beta版本中,将包含以下几类共识算法,当然开发者还可以通过Substrate API设计自己的共识算法。
Rhododendron
SHAFT/GRANDPA
Aurand
Ouroboros
PoW
Parachain(PoV)
Substrate提供的其他工具还包括:
Polkadot连接
可以热替换和插入的共识机制
可以热升级和插入的STF
Pub/Sub WebSocket JSON-RPC
轻量客户端
交易队列
安全网络
JavaScript实现
Substrate运行时模块库(SRML)
因为具备一系列链上热升级机制,无论修改共识算法还是升级STF,开发者都无需硬分叉。作为例证,今年7月17日,Polkadot的“Krumme Lanke”测试网络进行过公开演示,至今依然正常运行。
创建Substrate运行时模块库(SRML)的目的,是为了帮助开发者更迅速地发布区块链。开发者只需要将一组模块集合,便能实现相应的网络、共识、轻客户端或者其他需要的功能,新功能可以通过创建新模块实现。
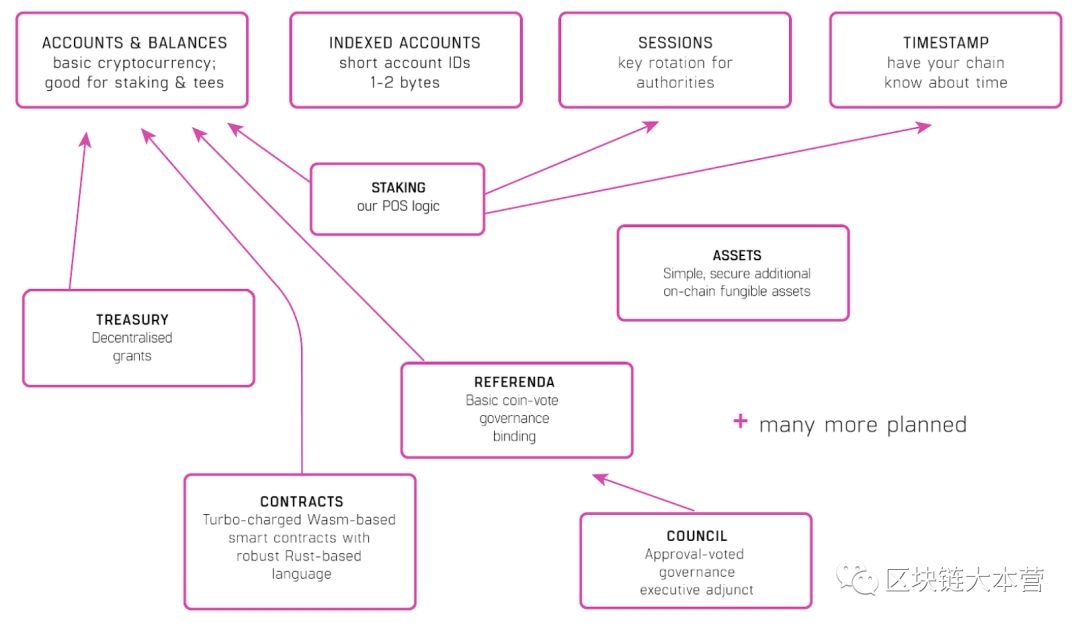
SRML之外,Substrate在设计中还额外引入了两层逻辑:
1. 可通过JSON配置的通用区块链节点,用于执行其运行时;
2. 一个精简的区块链内核引擎,用于处理共识、块生成、网络、数据库等功能。
此外,企业和金融敏感用户关注的高级隐私和权限管理,也能轻松加入并通过Substrate进行控制,而无需与Polkadot产生瓜葛,并通过桥接或成为原生Parachain的方式升级。
注:Substrate项目地址为https://github.com/paritytech/substrate
--【完】--
公众号又又又改版了,为了不错过第一手推送消息,建议你按照图片的提示,将【区块链大本营】设为星标(安卓用户设为“置顶”),标星看大图更爽哟!

推荐阅读

大力戳↑↑↑ 加入区块链大本营读者⑦号群
(内容转载请联系微信:优快云_qkldby)
(商务合作请联系微信:fengyan-1101)
免费公开课|扫码即可报名
想学习超级账本的同学千万不要错过!开课前报名可免费观看直播和回放,课程结束后只有会员才可免费观看回放哦



















 4641
4641

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









