 链表与回文判断
链表与回文判断





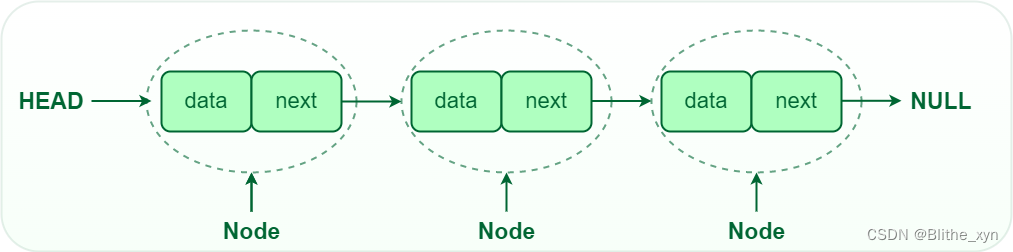
链表概念
单项链表
链表(Linked List)是一系列节点单向连接而成的数据结构,一般的节点有两个属性,分别是数据(data)和下一个节点的引用(next)。一般,链表会给出头部(Head)节点,通过不断的获取下个节点来遍历整个链表。直到下个节点为null时,则对该链表完成了遍历。
其他链表类型
双向链表
双向链表(double-linked list)其实就是在单项链表的基础上,节点存储多一个上一节点对象的引用(prev)。

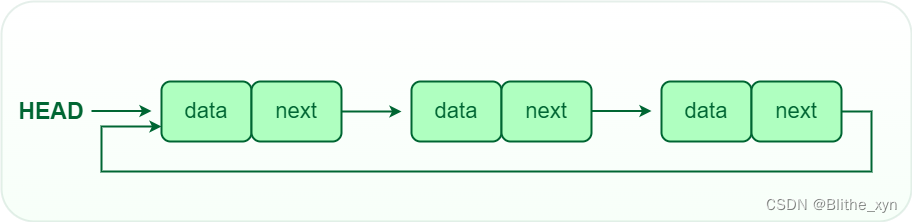
环形链表
环形链表则是在单项链表的基础上最后一个节点的下一个节点从null改为头部节点(head),这样形成一个循环。
链表特性(优缺点)
-
链表插入删除效率非常高,O(1)级别,简单地改变节点中的对象引用则可。
-
链表灵活的数据规模,以node为单位,增删灵活。无需像以数组为基础的数据结构那样维护数组大小,及时扩容防止溢出。
-
无法做到像数组一样下标随机读取。
-
相对于数组来说,除了存储数据之外,还需要额外空间来存储下一个节点的引用(next)。
常与链表结合解决问题的数据结构
哈希表(HashSet)
哈希过程(Hashing)需要3个重要的组件,分别是:Key、Hash Function、Hash Table
Key可以是任意的String/Integer,它作为Hash Function 的输入生成Hash Table的下标(Hash Index),好的Hash function会尽可能将不同的key计算成(散列)不同hash Index。
Hash Table本质上是一个数组,只是以Hash Function散列出来的Hash Index作为下标来获取到数据。但有的时候当不同的值被Hash Function计算出同样的值的时候,这时,在该Hash Index下就不是直接存储数据,而是存储一个数组或者树来继续存下具有相同Hash Index的数据。
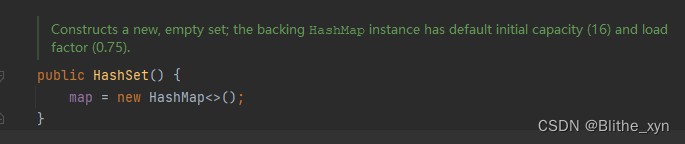
接下来,我们来JDK Hash Set的实现。可以看到,默认情况下,这个HashSet的构造方法会直接新建一个HashMap,所以HashSet本质是一个HashMap!
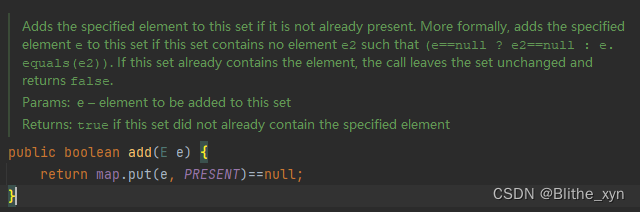
那它是如何存储数据又保证唯一的呢?直接看add方法是如何处理的。很简单,直接调用map的put方法,把要存的数据作为key放进map的key中,而value则是一个固定常量(static final修饰)的Object PRESENT。它的作用只是和key组成一对放到map中。
以上,HashSet是借用了HashMap的put方法实现了value不重复的功能。
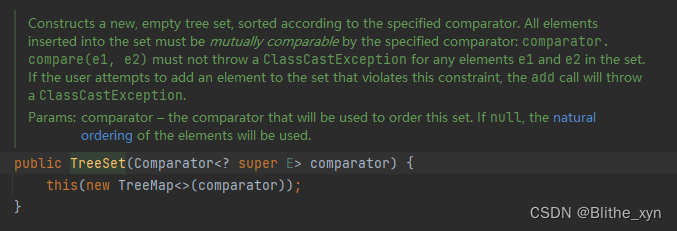
有序表 (TreeSet)
TreeSet的实现思路和HashSet差不多,内部存储数据用了TreeMap。TreeMap的Tree是指key是基于红黑树(Red-Black Tree)排序的。它的key是有序的,而基于TreeMap实现的TreeSet也自然有序了。
有序的定义可以是自然有序,或者是创建TreeSet时往构造方法中加入一个比较器(comparator),而红黑树就会基于比较器的方式来排序。
相关题目
回文问题
链表节点value值为字符,给出一个链表的头部节点,判断该链表所代表的字符串是否回文。
public static class ListNode {
int val;
ListNode next;
public ListNode(int value) {
this.val = value;
}
public ListNode(int value, ListNode next) {
this.val = value;
this.next = next;
}
public ListNode next(int value){
ListNode next = new ListNode(value);
this.next = next;
return next;
}
}
简单实现
两次遍历,第一次先遍历链表将每个节点放到栈中。第二次遍历时,一边遍历一边从栈中拿数据pop节点进行比对。利用栈的特性,FILO,pop的过程相当于从后往前遍历。
private static boolean isPalindrome(ListNode node){
//方法1. 利用栈
Stack<Integer> stack = new Stack<>();
ListNode head = node;
while (node != null){
stack.push(node.val);
node = node.next;
}
while (!stack.empty()){
if (stack.pop() != head.val){
return false;
}
head = head.next;
}
return true;
}
不适用额外空间实现
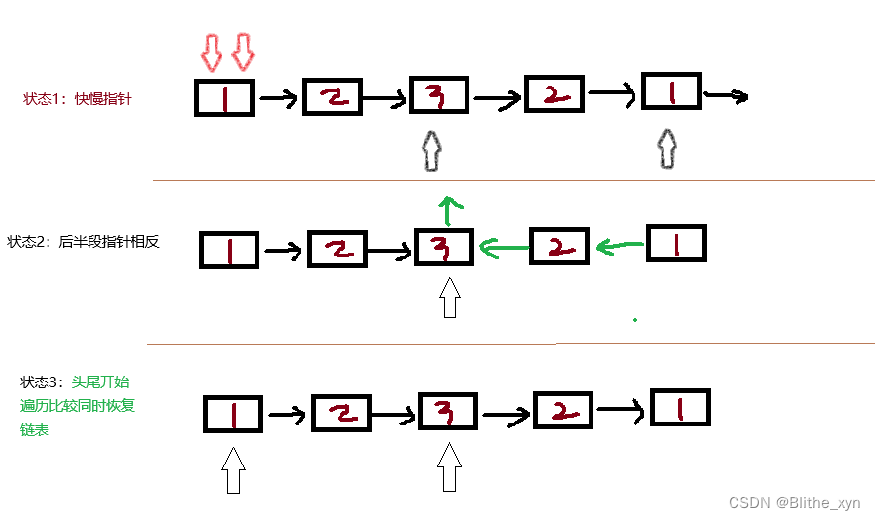
简单画了一个示意图,首先给定一个链表结构为 1 -> 2 -> 3 -> 2 -> 1,单向链表从header节点开始访问:
-
状态1:快慢指针,利用两个指针。开始时都从头部往下遍历。指针1每次走1步,指针2每次走两步。当然,这里需要判定的临界点情况就是指针2的下个节点为空时(已经走到最后了),指针1还继续走吗(偶数节点的情况)?我这里的做法就是不往前走。
ListNode n1 = head, n2 = head;
while (n2.next != null){
n1 = n1.next;
n2 = n2.next;
if (n2.next == null){
break;
}
n2 = n2.next;
}
-
状态2:改变后半段的链表方向。快慢指针的中间节点的next指向null,后续节点指向前一个节点。这里比较考验就是节点与节点之间的关系。我这里用了3个变量完成这个过程。
ListNode n3 = n1;
n1 = n1.next;
n3.next = null;
while (n1 != null){
n2 = n1.next;
n1.next = n3;
n3 = n1;
n1 = n2;
}
-
状态3:前后同时遍历。判断是否回文同时恢复到原始状态(未必需要)。这里比较难的是边界判断。我这里判断的标准是下个节点为null时跳出。
n1 = n3;//mark n1 as last head
while (n1 != null){
n3 = n1.next;
if (n1.val != n2.val){
result = false;
}
n1.next = n4;
n4 = n1;
n1 = n3;
//move n2
n2 = n2.next;
}
return result;
以上是简单的示意图,以下则是可运行示例。
import java.util.Stack;
/**
* 链表 回文问题
*/
public class Palindrome {
public static void main(String[] args) {
//create linked like
//1->2->3->3->2->1
ListNode f = new ListNode(1);
f.next(2).next(3).next(3).next(2).next(1);
//1->2->3->3->2->1
ListNode s = new ListNode(1);
s.next(2).next(3).next(4).next(2).next(1);
//1->2->3->3->2->1
ListNode t = new ListNode(1);
t.next(2).next(3).next(3).next(3).next(1);
//1->2->3->4->3->2->1
ListNode k = new ListNode(1);
k.next(2).next(3).next(4).next(3).next(2).next(1);
System.out.println(k);
print(s);
System.out.println(isPalindrome(f));
System.out.println(isPalindrome(s));
System.out.println(isPalindrome(t));
System.out.println(isPalindrome(k));
System.out.println("====== no extra space solution ========");
System.out.println(isPalindrome2(f));
System.out.println(isPalindrome2(s));
System.out.println(isPalindrome2(t));
System.out.println(isPalindrome2(k));
print(f);
print(s);
print(t);
print(k);
}
private static boolean isPalindrome(ListNode node){
//方法1. 利用栈
Stack<Integer> stack = new Stack<>();
ListNode head = node;
while (node != null){
stack.push(node.val);
node = node.next;
}
while (!stack.empty()){
if (stack.pop() != head.val){
return false;
}
head = head.next;
}
return true;
}
private static boolean isPalindrome2(ListNode head){
ListNode n1 = head, n2 = head;
while (n2.next != null){
n1 = n1.next;
n2 = n2.next;
if (n2.next == null){
break;
}
n2 = n2.next;
}
ListNode n3 = n1;
n1 = n1.next;
n3.next = null;
while (n1 != null){
n2 = n1.next;
n1.next = n3;
n3 = n1;
n1 = n2;
}
//n3 is last head and n1 is null
boolean result = true;
n2 = head;
ListNode n4 = null;
n1 = n3;//mark n1 as last head
while (n1 != null){
n3 = n1.next;
if (n1.val != n2.val){
result = false;
}
n1.next = n4;
n4 = n1;
n1 = n3;
//move n2
n2 = n2.next;
}
return result;
}
public static class ListNode {
int val;
ListNode next;
public ListNode(int value) {
this.val = value;
}
public ListNode(int value, ListNode next) {
this.val = value;
this.next = next;
}
public ListNode next(int value){
ListNode next = new ListNode(value);
this.next = next;
return next;
}
}
public static void print(ListNode node){
while (node != null){
System.out.print(node.val + "->");
node = node.next;
}
System.out.println("null");
}
}
而关于《链表左小右大》,《克隆链表》,《链表成环》等问题会在下篇文章作介绍。
若本文有任何错漏,欢迎各位指出,共勉。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









