







文章内容摘自 https://zhuanlan.zhihu.com/p/43200897b
一、激活还是权重的Norm
1. 激活norm:BatchNorm、LayerNorm、InstanceNorm、GroupNorm
2. 权重norm:Weight Norm(L1、L2正则)
至于深度学习中的Normalization,因为神经网络里主要有两类实体:神经元或者连接神经元的边,所以按照规范化操作涉及对象的不同可以分为两大类,一类是对第L层每个神经元的激活值或者说对于第L+1层网络神经元的输入值进行Normalization操作,比如BatchNorm、LayerNorm、InstanceNorm、GroupNorm等方法都属于这一类;另外一类是对神经网络中连接相邻隐层神经元之间的边上的权重进行规范化操作,比如Weight Norm就属于这一类。
二、norm的位置(激活前和激活后)
第一种是原始BN论文提出的,放在激活函数之前;另外一种是后续研究提出的,放在激活函数之后,不少研究表明将BN放在激活函数之后效果更好。
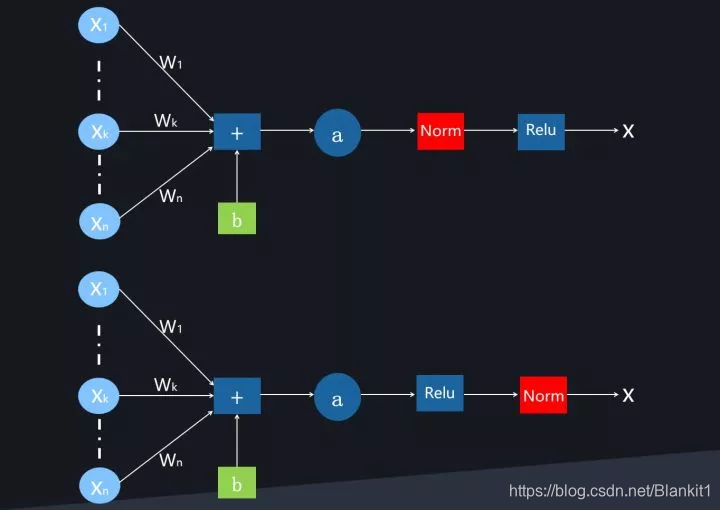
三、Normalization 操作

整个规范化过程可以分解为两步,第一步参考公式(1),是对激活值规整到均值为0,方差为1的正态分布范围内。
第二步参考公式(2),主要目标是让每个神经元在训练过程中学习到对应的两个调节因子,对规范到0均值,1方差的值进行微调。因为经过第一步操作后,Normalization有可能降低神经网络的非线性表达能力,所以会以此方式来补偿Normalization操作后神经网络的表达能力。
集合S:用来计算均值和方差的集合
为什么这些Normalization需要确定一个神经元集合S呢?
原因很简单,前面讲过,这类深度学习的规范化目标是将神经元的激活值 [公式] 限定在均值为0方差为1的正态分布中。而为了能够对网络中某个神经元的激活值 规范到均值为0方差为1的范围,必须有一定的手段求出均值和方差,而均值和方差是个统计指标,要计算这两个指标一定是在一个集合范围内才可行,所以这就要求必须指定一个神经元组成的集合,利用这个集合里每个神经元的激活来统计出所需的均值和方差,这样才能达到预定的规范化目标。
四、几种激活Normalization
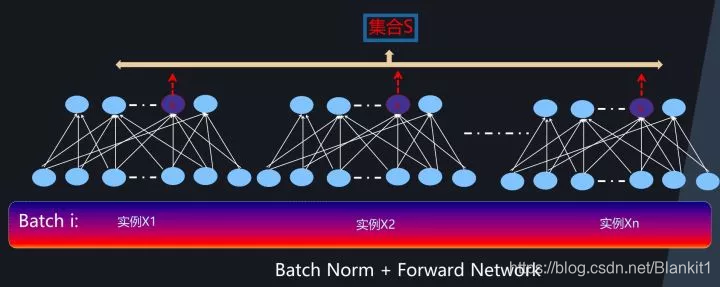
1. Batch Normalization
集合S:同一个batch内的n个实例在第K个神经元处的输出
全连接网络中的Batch Normalization
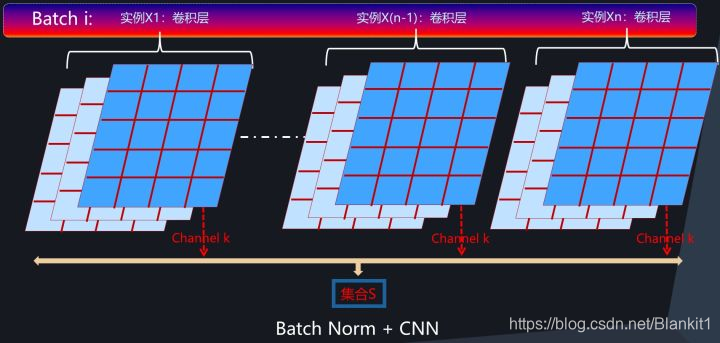
CNN中的Batch Normalization
BatchNorm目前基本已经成为各种网络(RNN除外)的标配,主要是因为效果好,比如可以加快模型收敛速度,不再依赖精细的参数初始化过程,可以调大学习率等各种方便,同时引入的随机噪声能够起到对模型参数进行正则化的作用,有利于增强模型泛化能力。
BatchNorm 的几个局限
局限1:如果Batch Size太小,则BN效果明显下降。
是因为在小的BatchSize意味着数据样本少,因而得不到有效统计量,也就是说噪音太大
局限2:对于有些像素级图片生成任务来说,BN效果不佳;
局限3:RNN等动态网络使用BN效果不佳且使用起来不方便
局限4:训练时和推理时统计量不一致。
因为在线推理或预测的时候,是单实例的,不存在Mini-Batch,所以就无法获得BN计算所需的均值和方差,一般解决方法是采用训练时刻记录的各个Mini-Batch的统计量的数学期望,以此来推算全局的均值和方差,在线推理时采用这样推导出的统计量。虽说实际使用并没大问题,但是确实存在训练和推理时刻统计量计算方法不一致的问题。
如何从根本上解决这些问题?一个自然的想法是:把对Batch的依赖去掉,转换统计集合范围。在统计均值方差的时候,不依赖Batch内数据,只用当前处理的单个训练数据来获得均值方差的统计量,这样因为不再依赖Batch内其它训练数据,那么就不存在因为Batch约束导致的问题。在BN后的几乎所有改进模型都是在这个指导思想下进行的。
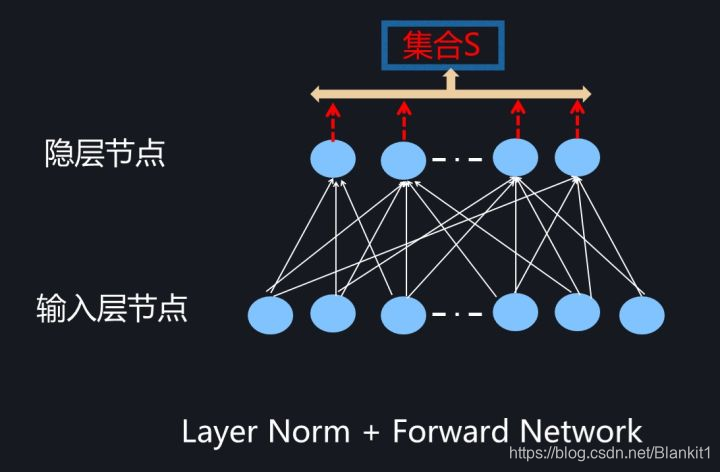
2. Layer Noramalization
集合S:单个实例在某个隐层的所有神经元的输出
前向网络Layer Noramalization
CNN Layer Noramalization
集合S:对于输入实例Xi,某个卷积层的所有特征图
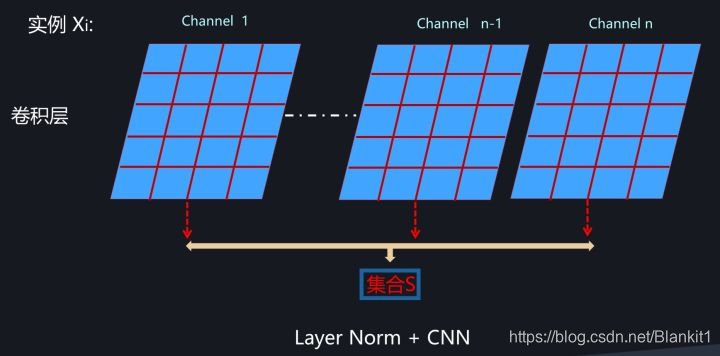
3. Instance Normalization
集合S:对于实例Xi,在某个卷积层的单张特征图
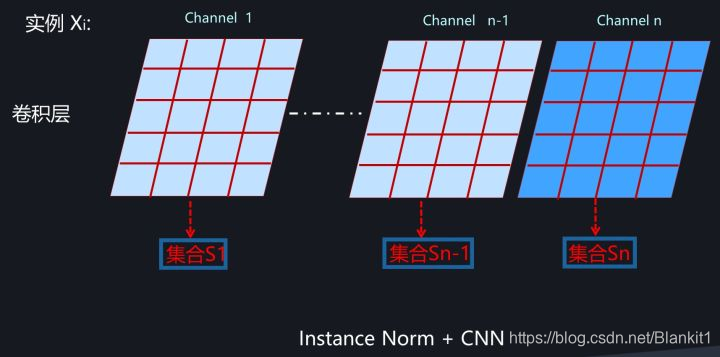
Instance Normalization对于一些图片生成类的任务比如图片风格转换来说效果是明显优于BN的,但在很多其它图像类任务比如分类等场景效果不如BN。
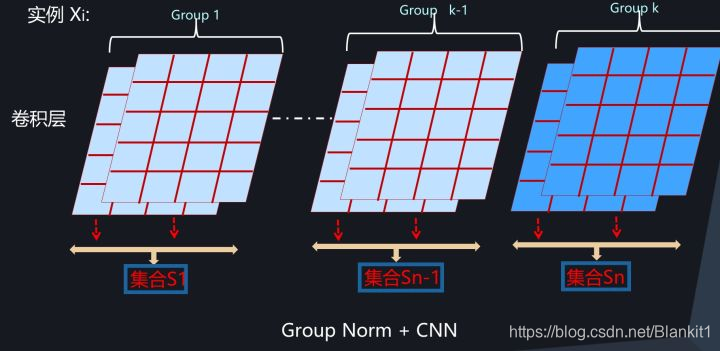
- Group Normalization
集合S:对于实例Xi,某个卷积层的几个特征图。
(介于Layer Normalization和Instance Normalization之间)
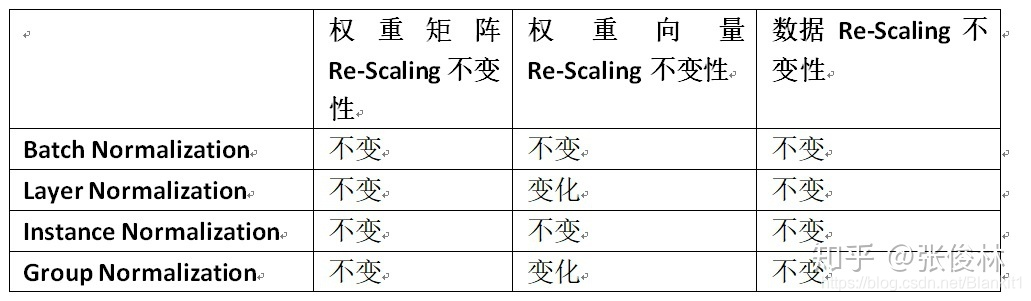
五、Normalization操作的Re-Scaling(放缩)不变性
权重向量(Weight Vector)Re-Scaling,数据Re-Scaling和权重矩阵(Weight Matrix)Re-Scaling。
六.Batch Normalization为何有效
不是因为内部协变化ICS(Internal Covariate Shift)不变性!!!
那是因为什么?
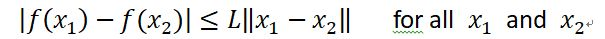
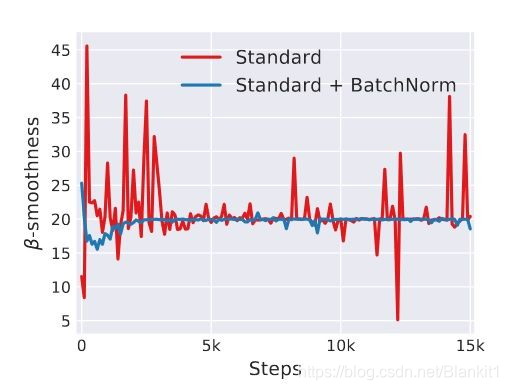
上图展示了用L-Lipschitz函数来衡量采用和不采用BN进行神经网络训练时两者的区别,可以看出未采用BN的训练过程中,L值波动幅度很大,而采用了BN后的训练过程L值相对比较稳定且值也比较小,尤其是在训练的初期,这个差别更明显。这证明了BN通过参数重整确实起到了平滑损失曲面及梯度的作用。
七、总结
不同的Normalization方法在于S集合的划分不同。
BN采用了同一个神经元,但是来自于Mini-Batch中不同训练实例导致的不同激活作为统计范围。而为了克服Mini-Batch带来的弊端,后续改进方法抛弃了Mini-Batch的思路,只用当前训练实例引发的激活来划分集合S的统计范围,概括而言,LayerNorm采用同隐层的所有神经元;InstanceNorm采用CNN中卷积层的单个通道作为统计范围,而GroupNorm则折衷两者,采用卷积层的通道分组,在划分为同一个分组的通道内来作为通道范围。
















 4399
4399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









