



一、部署准备
1.hadoop集群部署 3台机器
青云、阿里云 按量付费
2.机器名称和集群部署的概要
hadoop001: mysql cm-deamon cm-server cm-agent
hadoop002: cm-deamon cm-agent
hadoop003: cm-deamon cm-agent
agent端向server端发送请求
3.CDH架构 主从
cm-server metadata-->mysql
cm-agent 多个
二、CDH部署
1、mysql部署
2、IT环境部署
提醒:集群的每个机器都要操作一次
1 关闭防火墙
执行命令 service iptables stop
验证: service iptables status
2 关闭防火墙的自动运行
执行命令 chkconfig iptables off
验证: chkconfig --list | grep iptables
$>vi /etc/selinux/config
SELINUX=disabled
清空防火墙策略:
iptables -F
3 设置主机名-- linux运维
执行命令 (1)hostname hadoopcm-01
(2)vi /etc/sysconfig/network
NETWORKING=yes
NETWORKING_IPV6=yes
HOSTNAME=hadoopcm-01
4 ip与hostname绑定(关键,每个机器)
执行命令 (1)vi /etc/hosts
[root@hadoopcm-01 ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
按实际的内网ip配置,以下为案例:
172.16.101.54 hadoopcm-01.xxx.com hadoopcm-01
172.16.101.55 hadoopnn-01.xxx.com hadoopnn-01
172.16.101.56 hadoopnn-02.xxx.com hadoopnn-02
172.16.101.58 hadoopdn-01.xxx.com hadoopdn-01
172.16.101.59 hadoopdn-02.xxx.com hadoopdn-02
172.16.101.60 hadoopdn-03.xxx.com hadoopdn-03
验证: ping hadoopcm-01
集群每台机器同步 scp /etc/hosts root@hadoopnn-01:/etc/hosts
5 安装oracle jdk,不要安装
(1)下载,指定目录解压
[root@hadoopcm-01 tmp]# tar -xzvf jdk-7u79-linux-x64.gz -C /usr/java/
(2)vi /etc/profile 增加内容如下:
export JAVA_HOME=/usr/java/jdk1.7.0_79
export PATH=.:$JAVA_HOME/bin:$PATH
(3)source /etc/profile
验证: java -version
which java
6 创建hadoop用户,密码admin (三个文件/etc/passwd, /etc/shadow, /etc/group) (此步可以省略,可以直接用root安装,最后CDH集群环境的各个进程是以各自的用户管理的)
要求: root或者sudo无密码 user
6.1 没LDAP,root-->happy
6.2 刚开始给你机器,root,这时候拿root用户安装,过了一个月机器加上公司LDAP-->安装开心,要一个sudo user
6.3 始终不会加LDAP认证,都有root用户,但是想要用另外一个用户安装管理,必须sudo
6.4 给你的机器,就是有LDAP-->不要怕 ,搞个sudo user
[root@hadoopcm-01 ~]# adduser hadoop
[root@hadoopcm-01 ~]# passwd hadoop
Changing password for user hadoop.
New password:
BAD PASSWORD: it is too short
BAD PASSWORD: is too simple
Retype new password:
passwd: all authentication tokens updated successfully.
[root@hadoopcm-01 etc]# vi /etc/sudoers
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
hadoop ALL=(root) NOPASSWD:ALL
hadoop ALL=(ALL) ALL
jpwu ALL=(root) NOPASSWD:ALL
jpwu ALL=(ALL) NOPASSWD:ALL
###验证sudo权限
[root@hadoopcm-01 etc]# sudo su hadoop
[hadoop@hadoopcm-01 ~]$ sudo ls -l /root
total 4
-rw------- 1 root root 8 Apr 2 09:45 dead.letter
7 检查python:
cdh4.x系列 系统默认python2.6.6 --> 升级2.7.5-->hdfs ha,过不去. (2个月)
cdh5.x系列 python2.6.6 or python2.7
#建议是python2.6.6版本
python --version
centos6.x python2.6.x
centos7.x python2.7.x
但是 假如以后你们集群是2.7.x 跑Python服务需要3.5.1
8 时区+时钟同步 (云主机可以忽略)
https://www.cloudera.com/documentation/enterprise/5-10-x/topics/install_cdh_enable_ntp.html
[root@hadoopcm-01 cdh5.7.0]# grep ZONE /etc/sysconfig/clock
ZONE="Asia/Shanghai"
运维: 时区一致 + 时间同步
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
yum install -y ntpdate
配置集群时间同步服务:通过ntp服务配置
192.168.17.1-100
192.168.17.0
ntp主节点配置:
cp /etc/ntp.conf /etc/ntp.conf.bak
cp /etc/sysconfig/ntpd /etc/sysconfig/ntpd.bak
echo "restrict 172.16.101.0 mask 255.255.255.0 nomodify notrap" >> /etc/ntp.conf
echo "SYNC_HWCLOCK=yes" >> /etc/sysconfig/ntpd
service ntpd restart
ntp客户端节点配置:
然后在所有节点都设置定时任务 crontab –e 添加如下内容:
*/30 * * * * /usr/sbin/ntpdate 172.16.101.54
[root@hadoop002 ~]# /usr/sbin/ntpdate 192.168.1.131
16 Sep 11:44:06 ntpdate[5027]: no server suitable for synchronization found
防火墙没有关闭 清空
9 关闭大页面
echo never > /sys/kernel/mm/transparent_hugepage/defrag
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo 'echo never > /sys/kernel/mm/transparent_hugepage/defrag'>> /etc/rc.local
echo 'echo never > /sys/kernel/mm/transparent_hugepage/enabled'>> /etc/rc.local
10 swap 物理磁盘空间 作为内存
echo 'vm.swappiness = 10' >> /etc/sysctl.conf
sysctl -p(从指定的文件加载系统参数,如不指定即从/etc/sysctl.conf中加载)
swap=0-100
0不代表禁用 而是惰性最高
100表示 使用积极性最高
集群计算对实时性 要求高的 swap=0 允许job挂 迅速的加内存或调大参数 重启job
集群计算对实时性 要求不高的 swap=10/30 不允许job挂 慢慢的运行
4G内存 8Gswap
0: 3.5G--》3.9G 0
30: 3G 2G
3、CDH配置离线数据源
1.安装http 和启动http服务
[root@hadoop-01 ~]# rpm -qa|grep httpd
[root@hadoop-01 ~]# yum install -y httpd
[root@hadoop-01 ~]# chkconfig --list|grep httpd
httpd 0:off 1:off 2:off 3:off 4:off 5:off 6:off
[root@hadoop-01 ~]# chkconfig httpd on
[root@hadoop-01 ~]# chkconfig --list|grep httpd
httpd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
[root@hadoop-01 ~]# service httpd start
[root@hadoop001 ~]# systemctl list-unit-files |grep httpd
httpd.service disabled
[root@hadoop001 ~]#
2.创建 parcels文件
[root@hadoop-01 rpminstall]# cd /var/www/html
[root@hadoop-01 html]# mkdir parcels
[root@hadoop-01 html]# cd parcels
3.在http://archive.cloudera.com/cdh5/parcels/5.7.0/,
将
CDH-5.7.0-1.cdh5.7.0.p0.45-el6.parcel
CDH-5.7.0-1.cdh5.7.0.p0.45-el6.parcel.sha1
manifest.json
这三个文件下载到window桌面上(在网络比较通畅情况下,可以直接wget),
然后通过rz命令上传到 /var/www/html/parcels/目录中,
然后将CDH-5.7.0-1.cdh5.7.0.p0.45-el6.parcel.sha1重命名
(去掉名称结尾"1",不然cdh在装的时候,会一直认为在下载,是未完成的)
[root@hadoop-01 parcels]# wget http://archive.cloudera.com/cdh5/parcels/5.7.0/CDH-5.7.0-1.cdh5.7.0.p0.45-el6.parcel
[root@hadoop-01 parcels]# wget http://archive.cloudera.com/cdh5/parcels/5.7.0/CDH-5.7.0-1.cdh5.7.0.p0.45-el6.parcel.sha1
[root@hadoop-01 parcels]# wget http://archive.cloudera.com/cdh5/parcels/5.7.0/manifest.json
[root@hadoop-01 parcels]# ll
total 1230064
-rw-r--r-- 1 root root 1445356350 Nov 16 21:14 CDH-5.7.0-1.cdh5.7.0.p0.45-el6.parcel
-rw-r--r-- 1 root root 41 Sep 22 04:25 CDH-5.7.0-1.cdh5.7.0.p0.45-el6.parcel.sha1
-rw-r--r-- 1 root root 56892 Sep 22 04:27 manifest.json
[root@hadoop-01 parcels]# mv CDH-5.7.0-1.cdh5.7.0.p0.45-el6.parcel.sha1 CDH-5.7.0-1.cdh5.7.0.p0.45-el6.parcel.sha
校验文件下载未损坏:
[root@sht-sgmhadoopcm-01 parcels]# sha1sum CDH-5.7.0-1.cdh5.7.0.p0.45-el6.parcel
b6d4bafacd1cfad6a9e1c8f951929c616ca02d8f CDH-5.7.0-1.cdh5.7.0.p0.45-el6.parcel
[root@sht-sgmhadoopcm-01 parcels]#
[root@sht-sgmhadoopcm-01 parcels]# cat CDH-5.7.0-1.cdh5.7.0.p0.45-el6.parcel.sha
b6d4bafacd1cfad6a9e1c8f951929c616ca02d8f
[root@sht-sgmhadoopcm-01 parcels]#
4.在http://archive.cloudera.com/cm5/repo-as-tarball/5.7.0/,下载cm5.7.0-centos6.tar.gz包
[root@hadoop-01 ~]$ cd /opt/rpminstall
[root@hadoop-01 rpminstall]$ wget http://archive.cloudera.com/cm5/repo-as-tarball/5.7.0/cm5.7.0-centos6.tar.gz
[root@hadoop-01 rpminstall]$ ll
total 1523552
-rw-r--r-- 1 root root 815597424 Sep 22 02:00 cm5.7.0-centos6.tar.gz
5.解压cm5.7.0-centos6.tar.gz包,必须要和官网的下载包的路径地址一致
[root@hadoop-01 rpminstall]$ tar -zxf cm5.7.0-centos6.tar.gz -C /var/www/html/
[root@hadoop-01 rpminstall]$ cd /var/www/html/
[root@hadoop-01 html]$ ll
total 8
drwxrwxr-x 3 1106 592 4096 Oct 27 10:09 cm
drwxr-xr-x 2 root root 4096 Apr 2 15:55 parcels
6.创建和官网一样的目录路径,然后mv
[root@hadoop-01 html]$ mkdir -p cm5/redhat/6/x86_64/
[root@hadoop-01 html]$ mv cm cm5/redhat/6/x86_64/
[root@hadoop-01 html]$
7.配置本地的yum源,cdh集群在安装时会就从本地down包,不会从官网了
注意:云主机一定要配置80端口映射内网IP

[root@hadoop-01 html]$ vi /etc/yum.repos.d/cloudera-manager.repo
[cloudera-manager]
name = Cloudera Manager, Version 5.7.0
baseurl = http://192.168.0.2/cm5/redhat/6/x86_64/cm/5/
gpgcheck = 0
###提醒: 每个机器都要配置cloudera-manager.repo文件,scp主机的repo文件到其他机器同样的位置。
8.浏览器查看下面两个网址(外网IP)是否出来,假如有,就配置成功
http://139.198.188.104/parcels/
http://139.198.188.104/cm5/redhat/6/x86_64/cm/5/
配置的时候实用内网ip:
http://192.168.0.2/parcels/
http://192.168.0.2/cm5/redhat/6/x86_64/cm/5/
总结就是:浏览器看行不行就输入外网ip看。
内部文件用内网IP来加快速度。
parcel: 后缀为parcel,
是将Apache hadoop zk hbase hue oozie 等等,打包一个文件,
后缀取名为包裹 英文parcel
cm: deamons+server+agent 闭源
重点: 9.在什么时候用这两个地址???
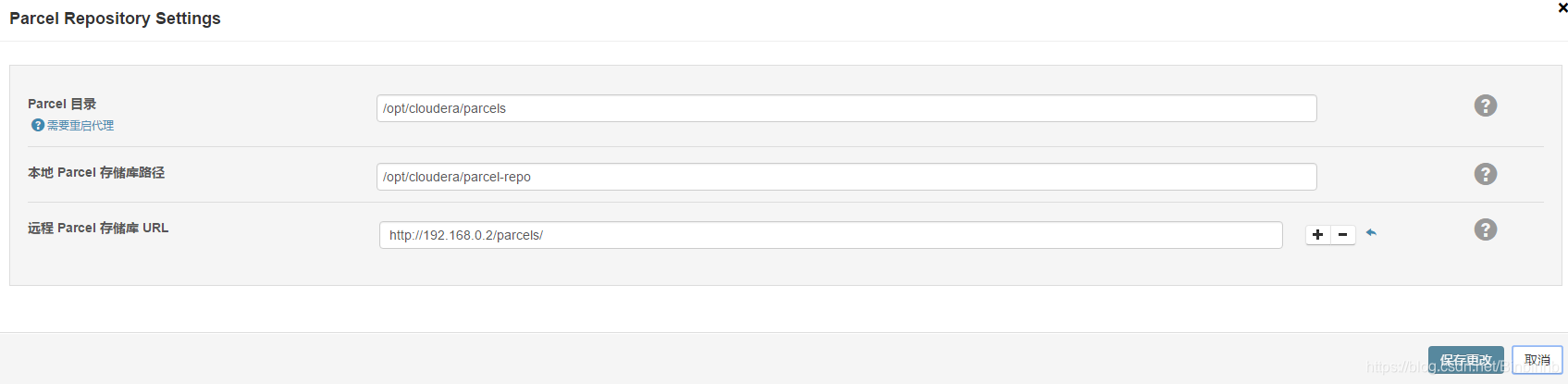
参考CDH5.7.0 Installation.docx 文档的第二.05选择存储库的界面时:
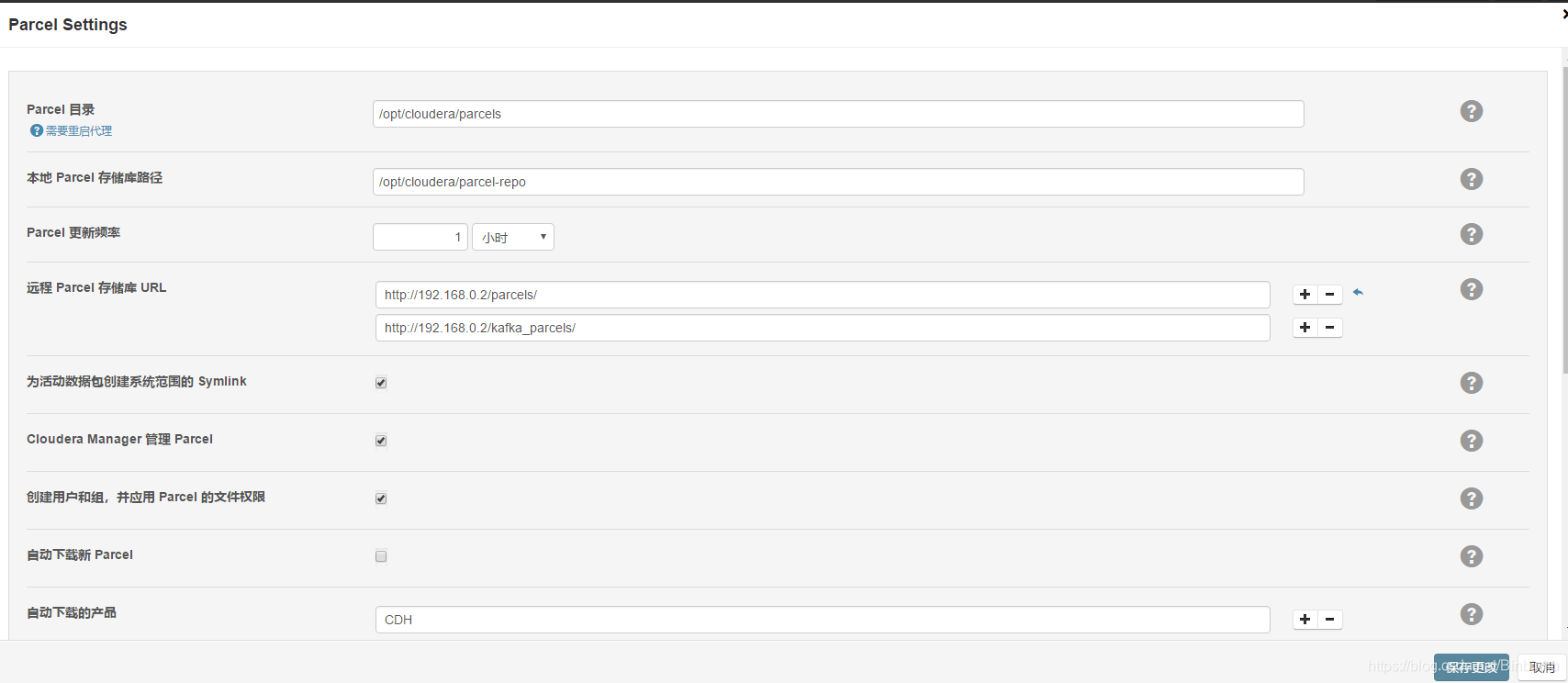
a.单击"更多选项",弹出界面中,在"远程Parcel存储库URL"的右侧地址,
b.删除url,只保留一个,然后替换为 http://172.16.101.54/parcels/
c.然后单击"save changes",稍微等一下,页面会自动刷新一下,
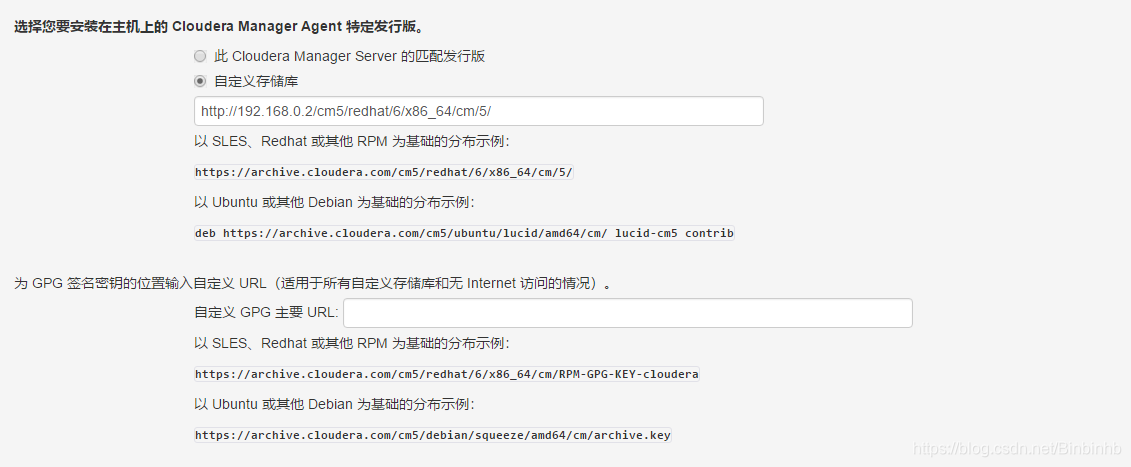
d.然后在"选择CDH的版本",选择cdh
f."其他Parcels",全部选择"无"
g.选择"自定义存储库",将 http://172.16.101.54/cm5/redhat/6/x86_64/cm/5/ 粘贴上去
【官网参考链接】
http://archive.cloudera.com/cdh5/parcels/5.8.2/
http://archive.cloudera.com/cm5/repo-as-tarball/5.8.2/
http://archive.cloudera.com/cm5/redhat/6/x86_64/cm/5.8.2/
4、实用rpm包安装和启动CM Server
1.install server rpm in cm instance
cd /var/www/html/cm5/redhat/6/x86_64/cm/5/RPMS/x86_64
yum install -y cloudera-manager-daemons-5.7.0-1.cm570.p0.76.el6.x86_64.rpm
yum install -y cloudera-manager-server-5.7.0-1.cm570.p0.76.el6.x86_64.rpm
2.configure the jdbc driver of mysql-connector-java.jar
cd /usr/share/java
wget http://cdn.mysql.com//Downloads/Connector-J/mysql-connector-java-5.1.37.zip [invaild]
unzip mysql-connector-java-5.1.37.zip
cd mysql-connector-java-5.1.37
cp mysql-connector-java-5.1.37-bin.jar ../mysql-connector-java.jar
#Must rename to “mysql-connector-java.jar”
3.on the CM machine,install MySQL and configure cmf user and db
create database cmf DEFAULT CHARACTER SET utf8;
grant all on cmf.* TO 'cmf'@'localhost' IDENTIFIED BY 'cmf_password';
grant all on cmf.* TO 'cmf'@'%' IDENTIFIED BY 'cmf_password';
grant all on cmf.* TO 'cmf'@'172.16.101.54' IDENTIFIED BY 'cmf_password';
flush privileges;
grant all privileges on *.* to 'root'@'%' identified by 'root' with grant option;
flush privileges;
删除数据库的时候的操作:
mysql> drop database cmf;
mysql> CREATE DATABASE `cmf` /*!40100 DEFAULT CHARACTER SET utf8 */;
4.modify cloudera-scm-server connect to MySQL
[root@hadoopcm-01 cloudera-scm-server]# cd /etc/cloudera-scm-server/
[root@hadoopcm-01 cloudera-scm-server]# vi db.properties
# Copyright (c) 2012 Cloudera, Inc. All rights reserved.
若泽数据 www.ruozedata.com Page 14
#
# This file describes the database connection.
#
# The database type
# Currently 'mysql', 'postgresql' and 'oracle' are valid databases.
com.cloudera.cmf.db.type=mysql
# The database host
# If a non standard port is needed, use 'hostname:port'
com.cloudera.cmf.db.host=localhost
# The database name
com.cloudera.cmf.db.name=cmf
# The database user
com.cloudera.cmf.db.user=cmf
# The database user's password
com.cloudera.cmf.db.password=cmf_password
注意:> CDH5.9.1/5.10 多加一行 db=init----->db=external
5.start cm server
service cloudera-scm-server start
6.real-time checking server log in cm instance(看日志)
cd /var/log/cloudera-scm-server/
tail -f cloudera-scm-server.log
2017-03-17 21:32:05,253 INFO WebServerImpl:org.mortbay.log: Started SelectChannelConnector@0.0.0.0:7180
2017-03-17 21:32:05,253 INFO WebServerImpl:com.cloudera.server.cmf.WebServerImpl: Started Jetty server.
#mark: configure clouder manager metadata to saved in the cmf db.
7.waiting 1 minute,open http://172.16.101.54:7180
云主机记得打开端口7180
#Log message:
User:admin
Password:admin
安装CM
安装CM-agent
不安装jdk,不启用单用户模式;
集群安装:
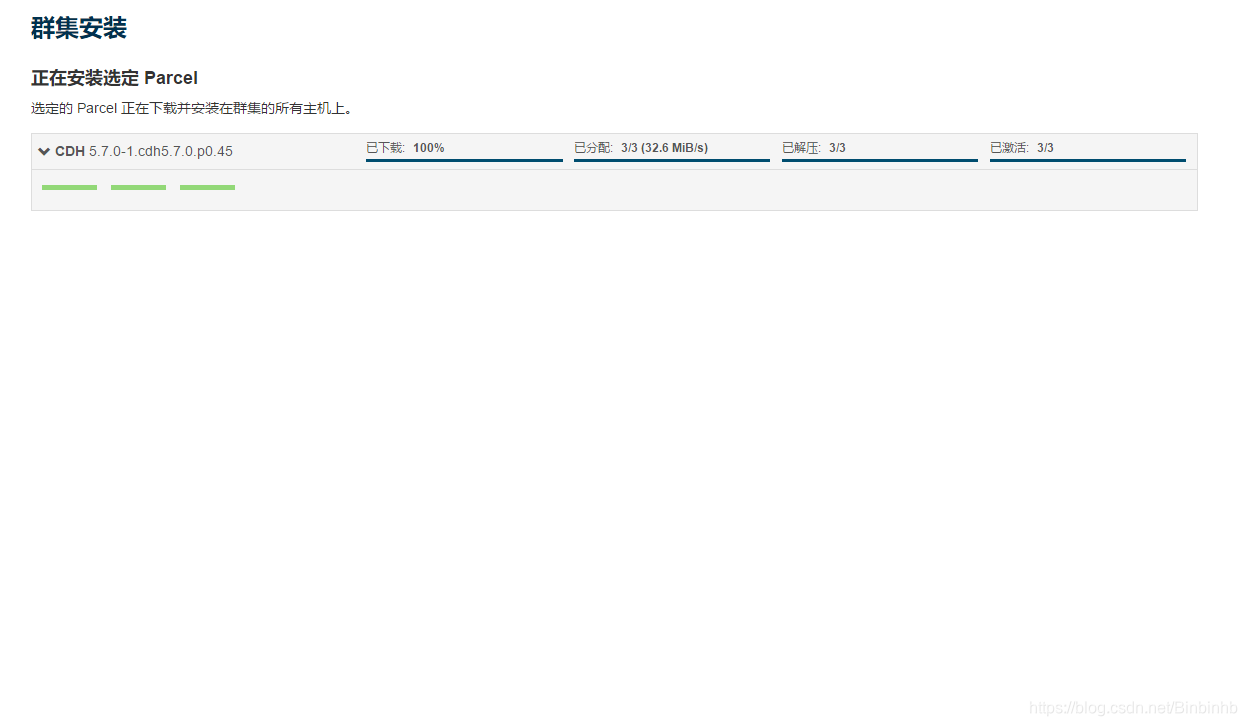
->cm server + agent安装好了
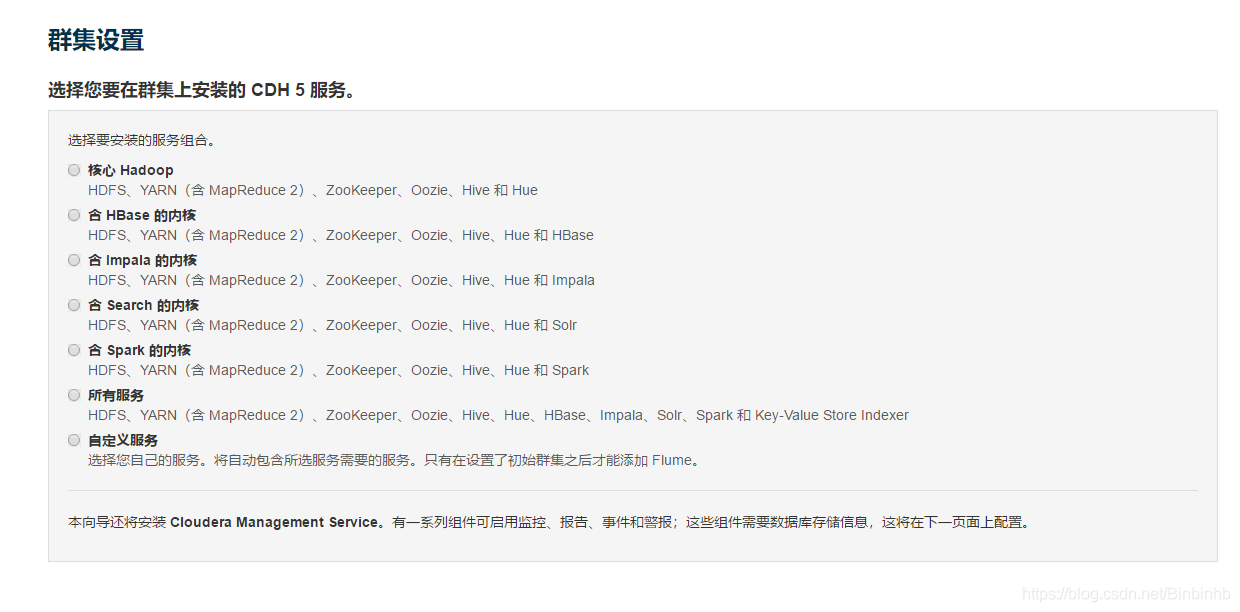
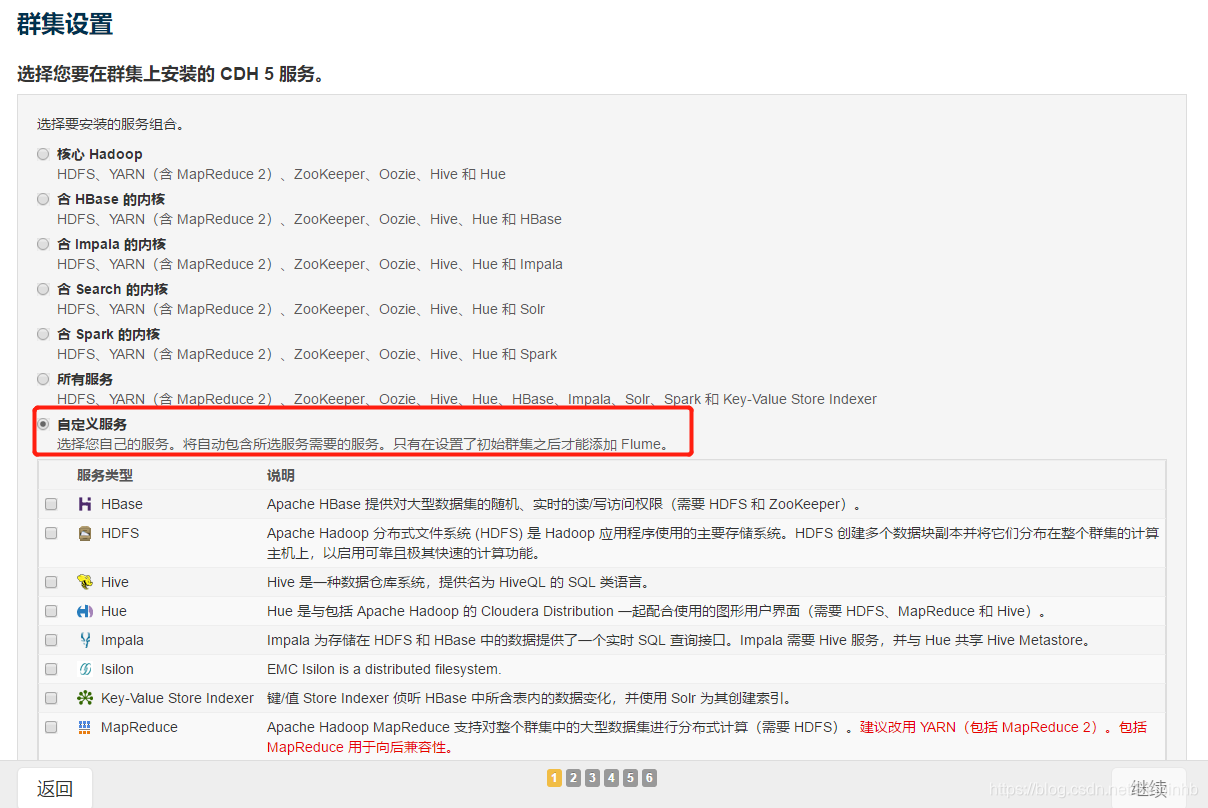
安装组件(自定义)
HDFS,Yarn,ZK
HDFS:
CM:

Yarn:

ZK:

创建AM数据库:
注意:AM放哪个机器,那个机器要有jdbc
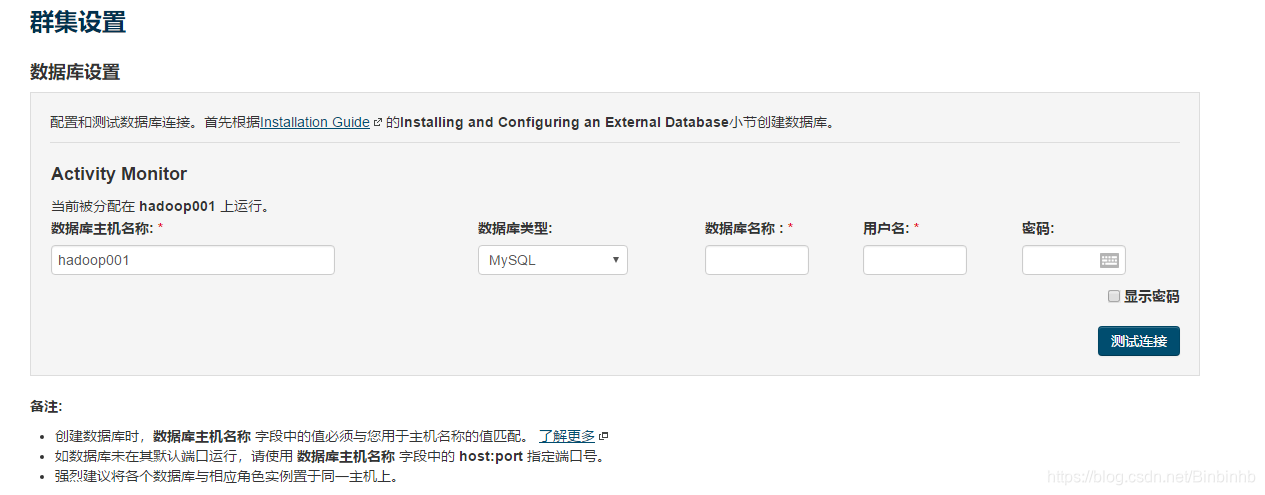
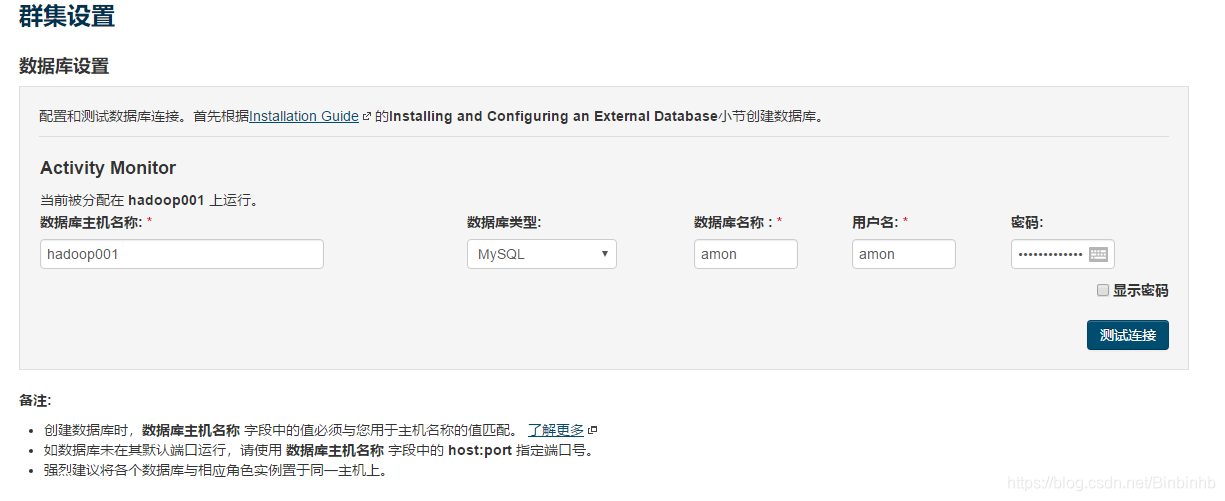
create database amon DEFAULT CHARACTER SET utf8;
grant all on amon.* TO 'amon'@'%' IDENTIFIED BY 'amon_password';
flush privileges;
注意:务必对数据库root,赋予最大权限。
检查目录是否存在,存在就再删除干净。
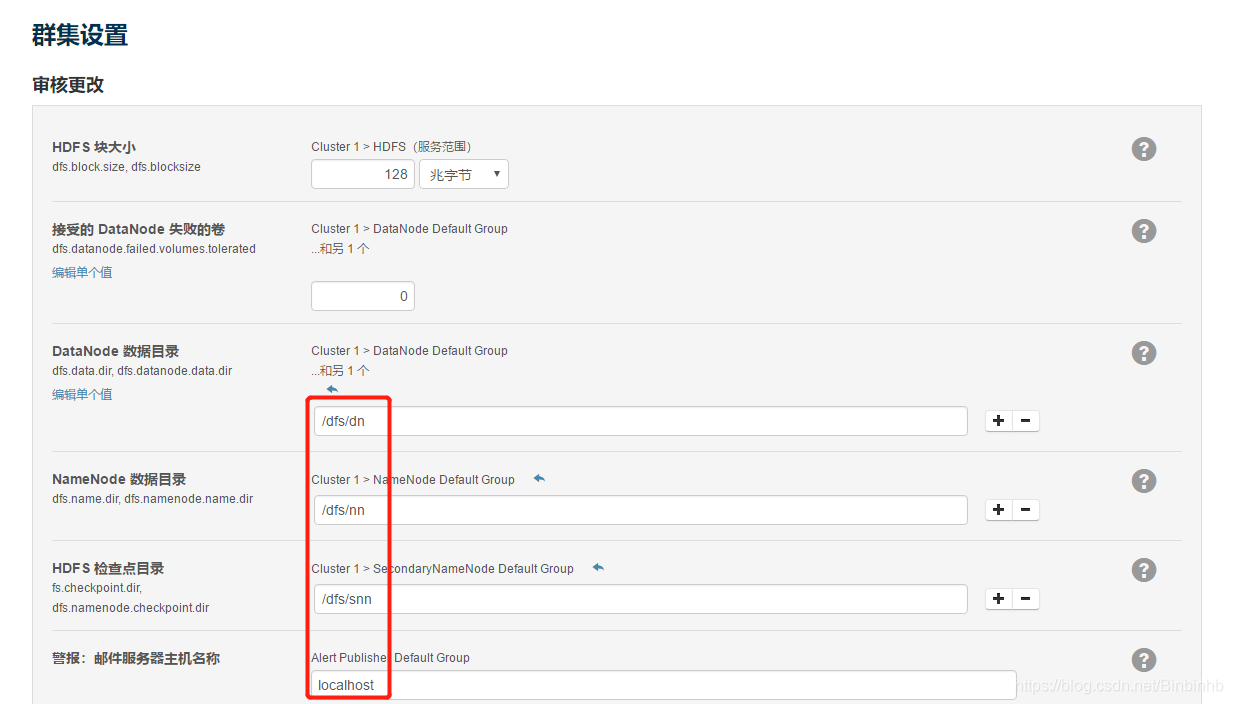
成功!!!
5、cloudera官网学习(https://www.cloudera.com/downloads.html)
以5.12为例:
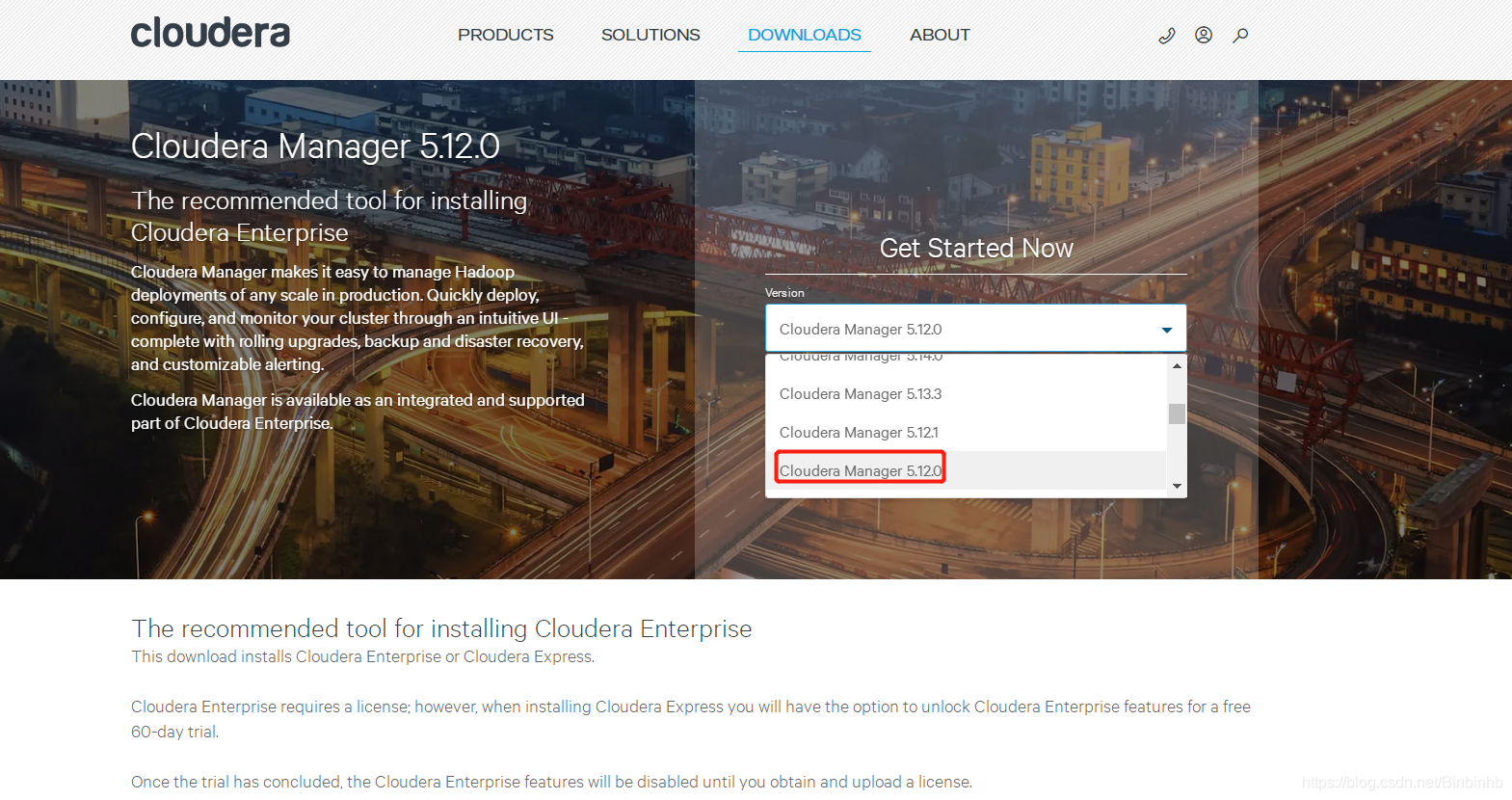
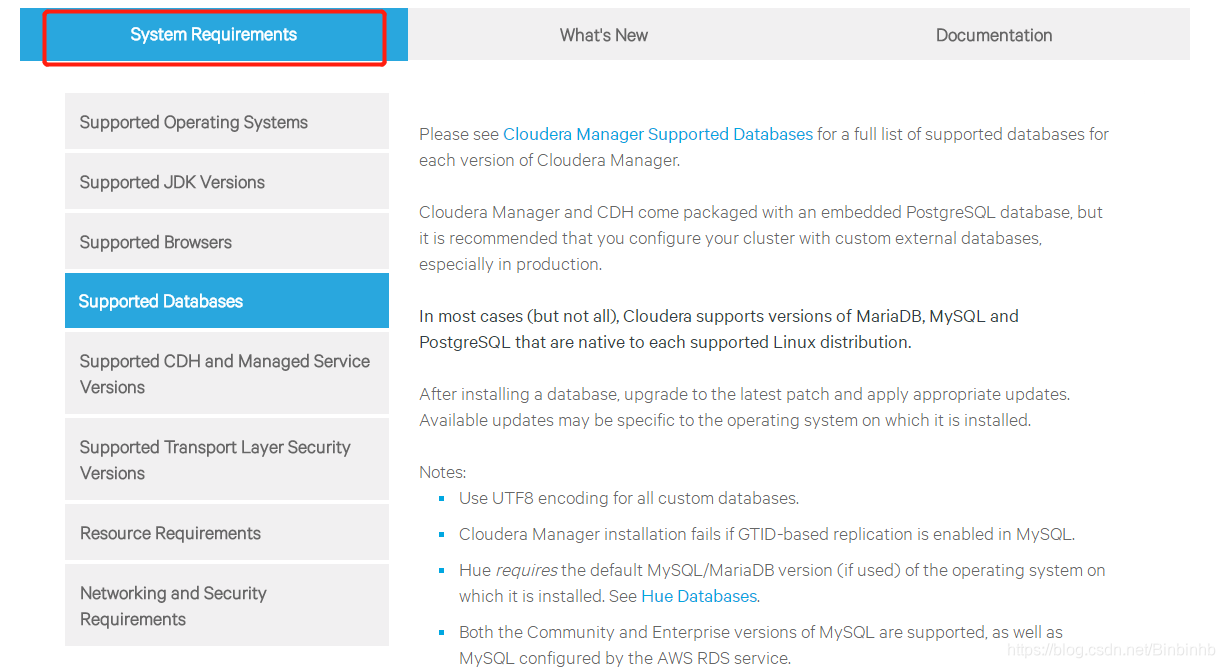
(1)系统配置要求:
(2)更新
(3)重点
6、部署kafka-cloudera
(1)CDH-KAFKA准备步骤
因为CDH不建议系统安装,所以自己安装。
官网最下方的
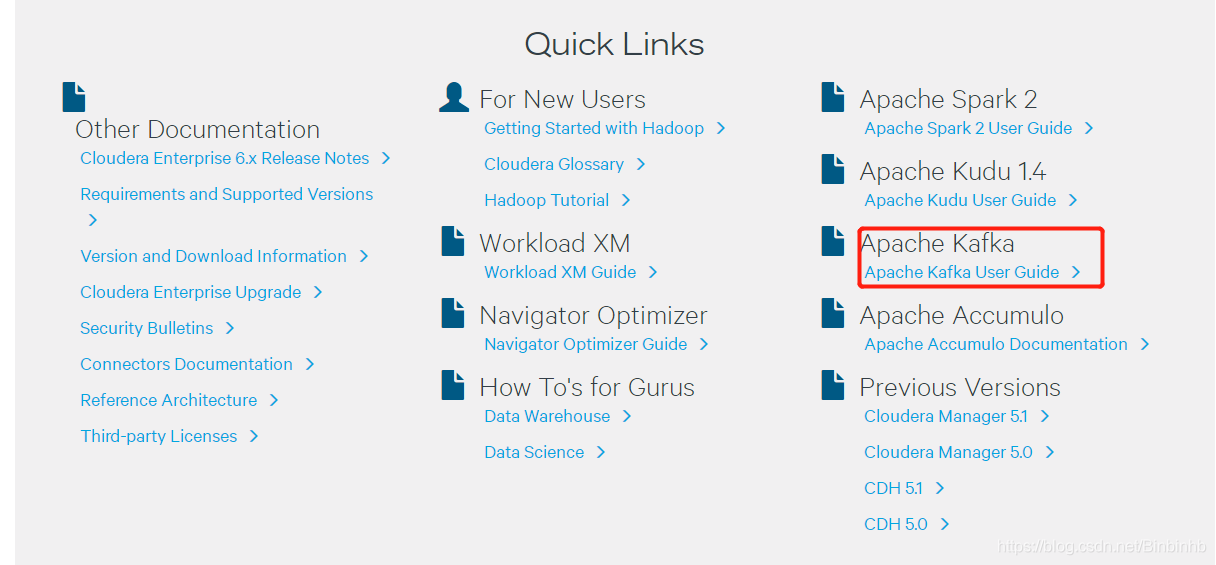
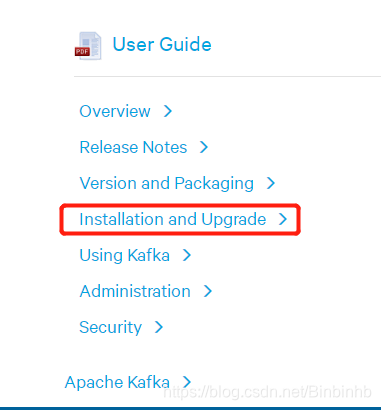
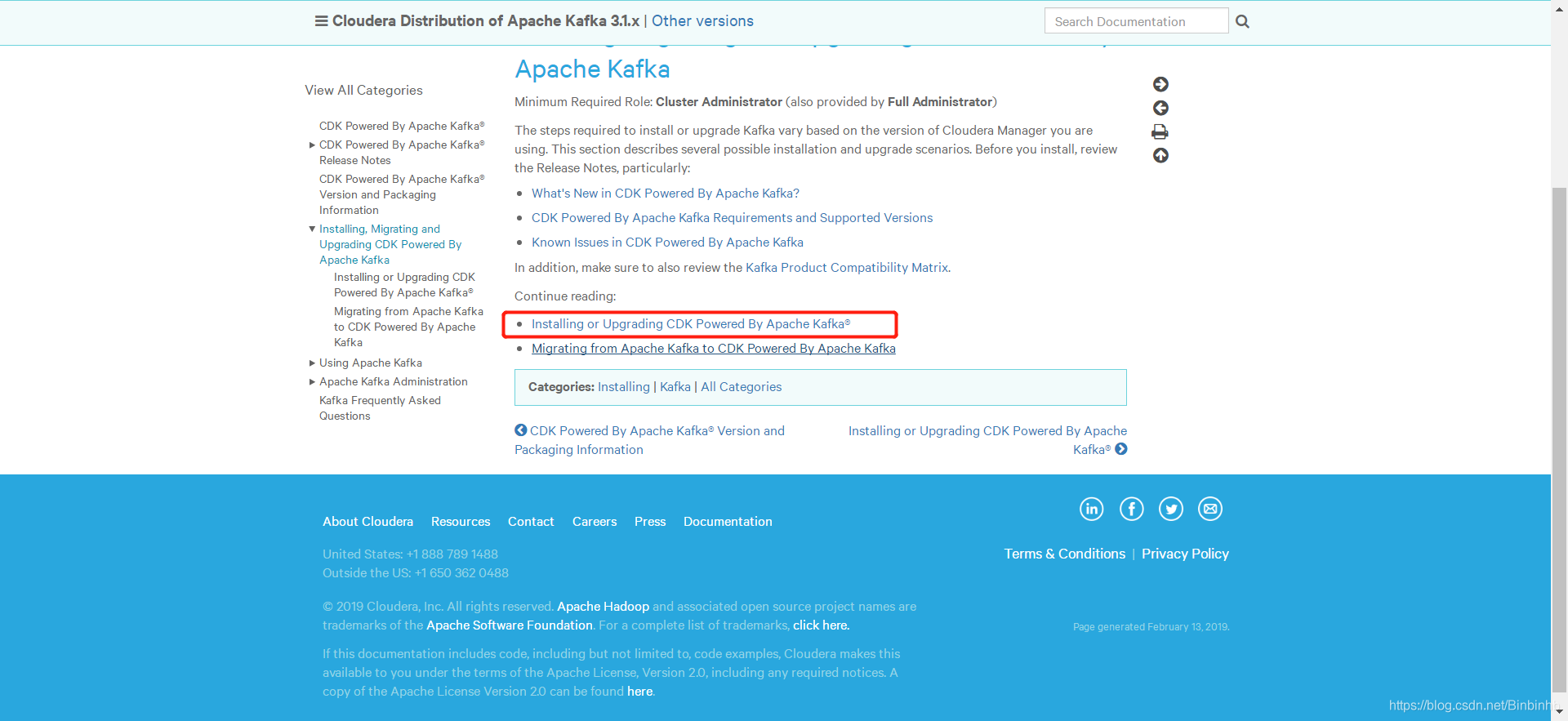
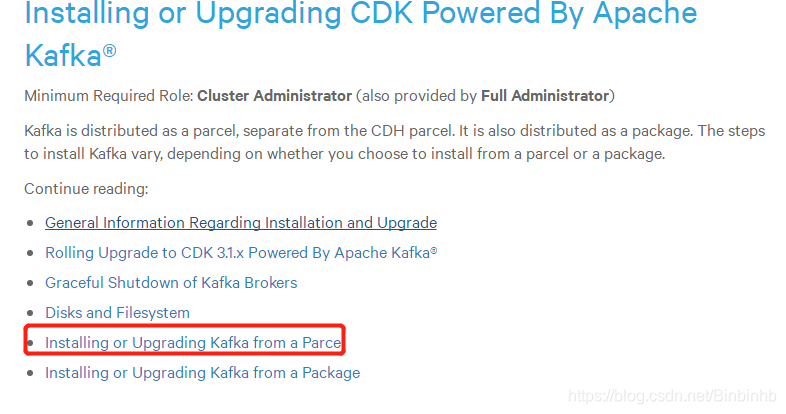
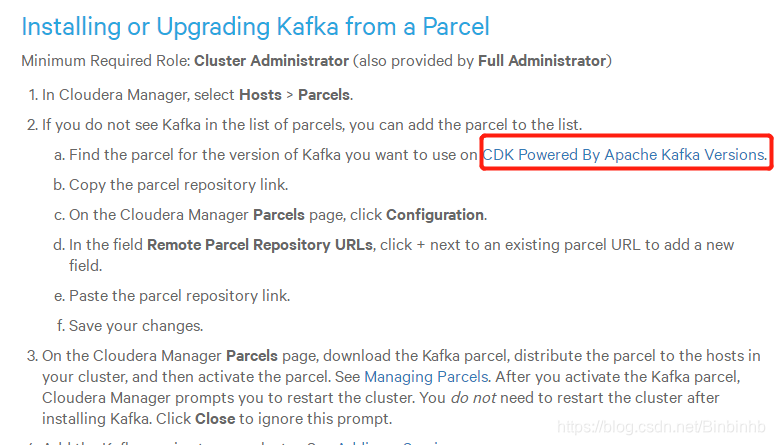
由于我们使用的kafka版本:kafka_2.11-0.10.0.1
因此选择:

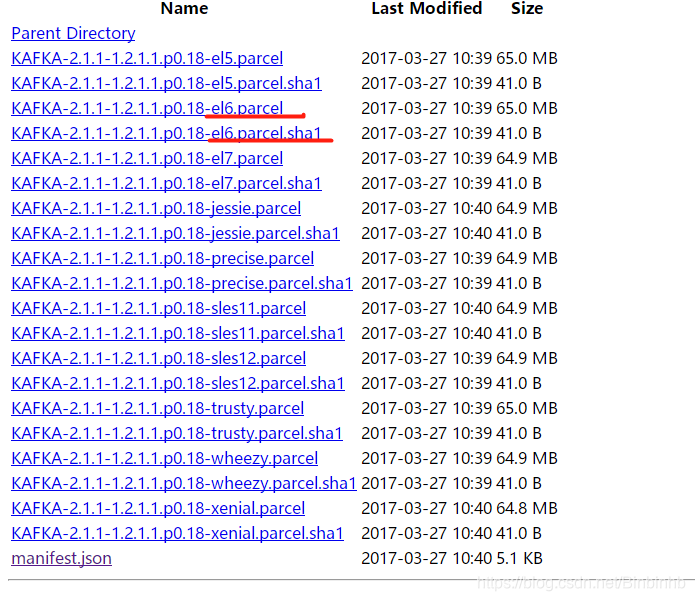
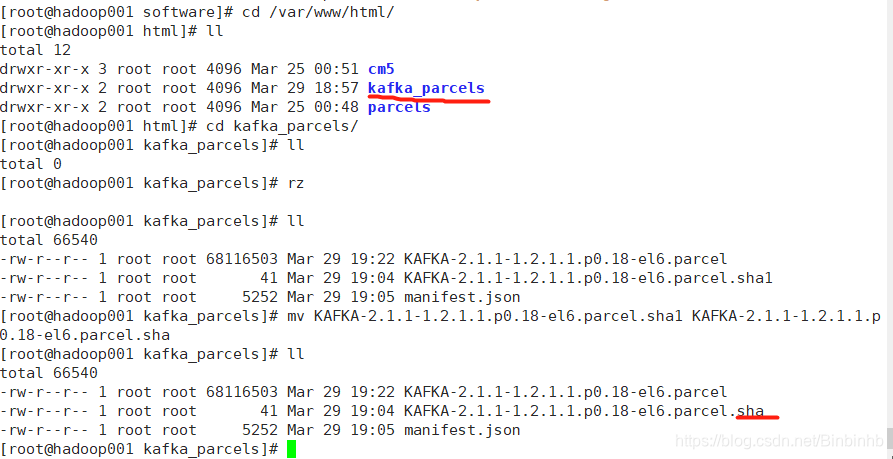
上传并修改.sha1文件为.sha
(2)CDH配置
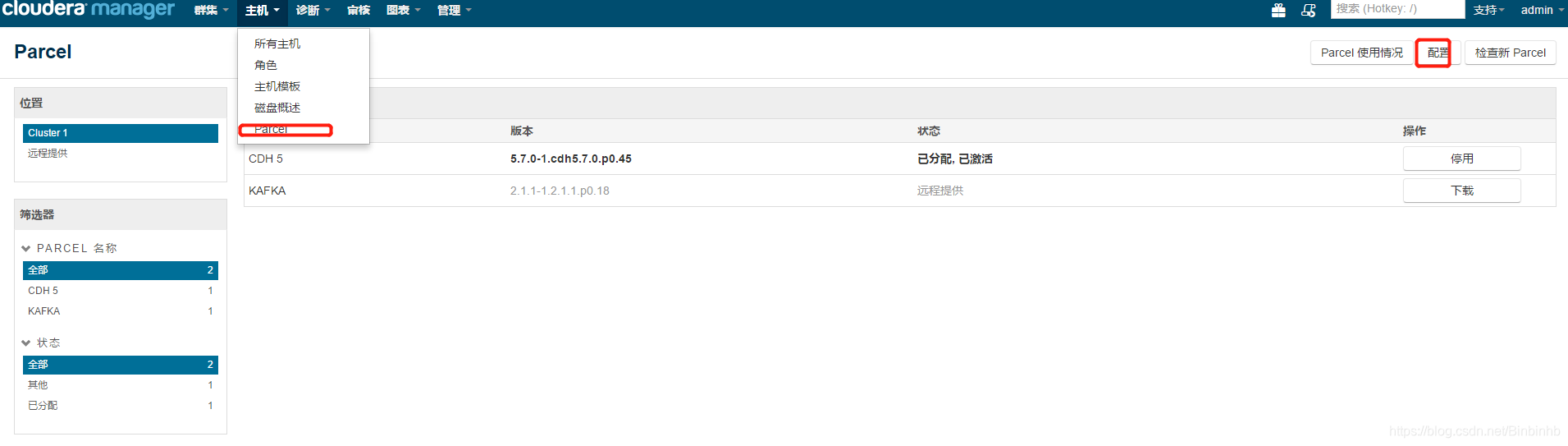
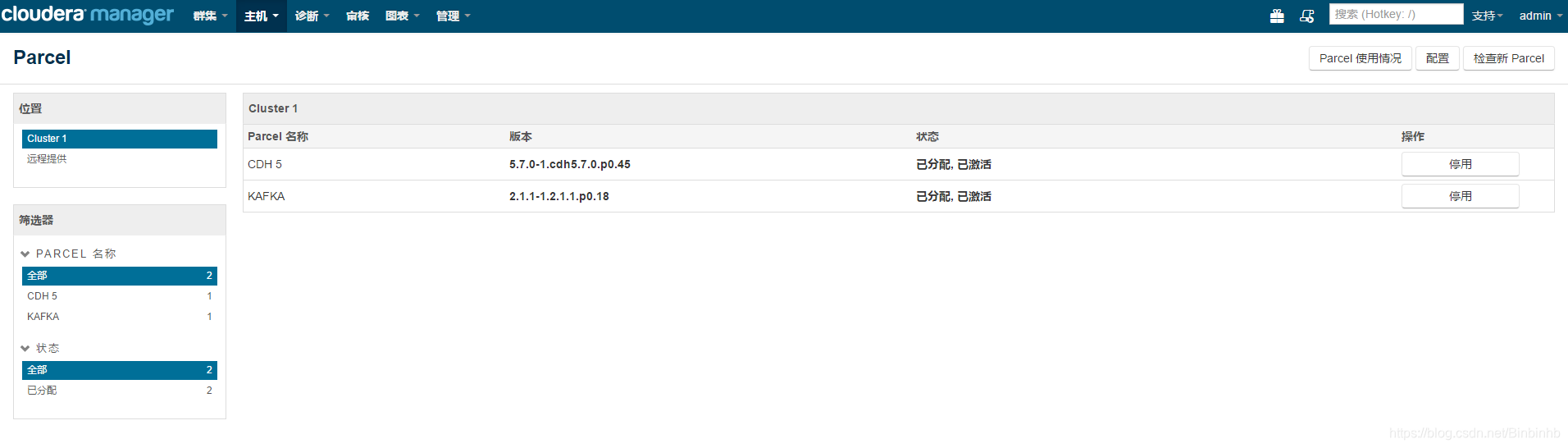
添加服务:
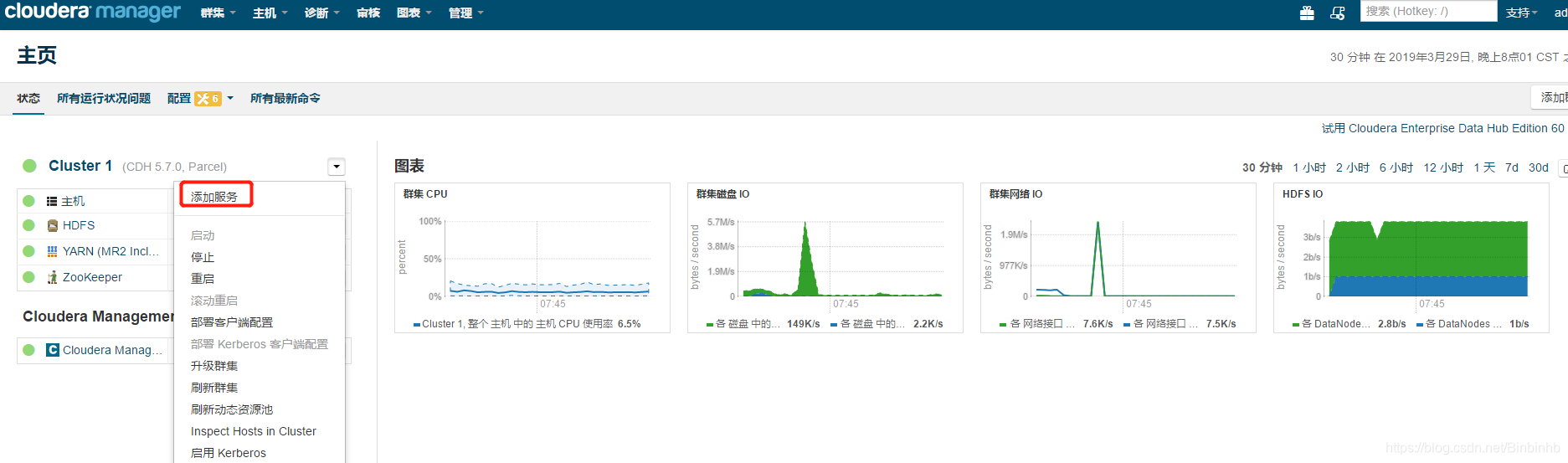
选择kafka,按继续;
brower放在所有机器上;
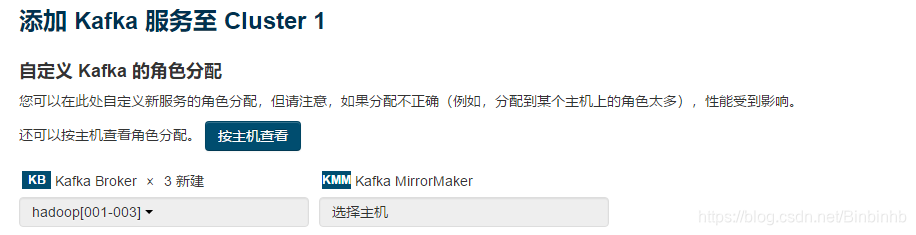
然后:
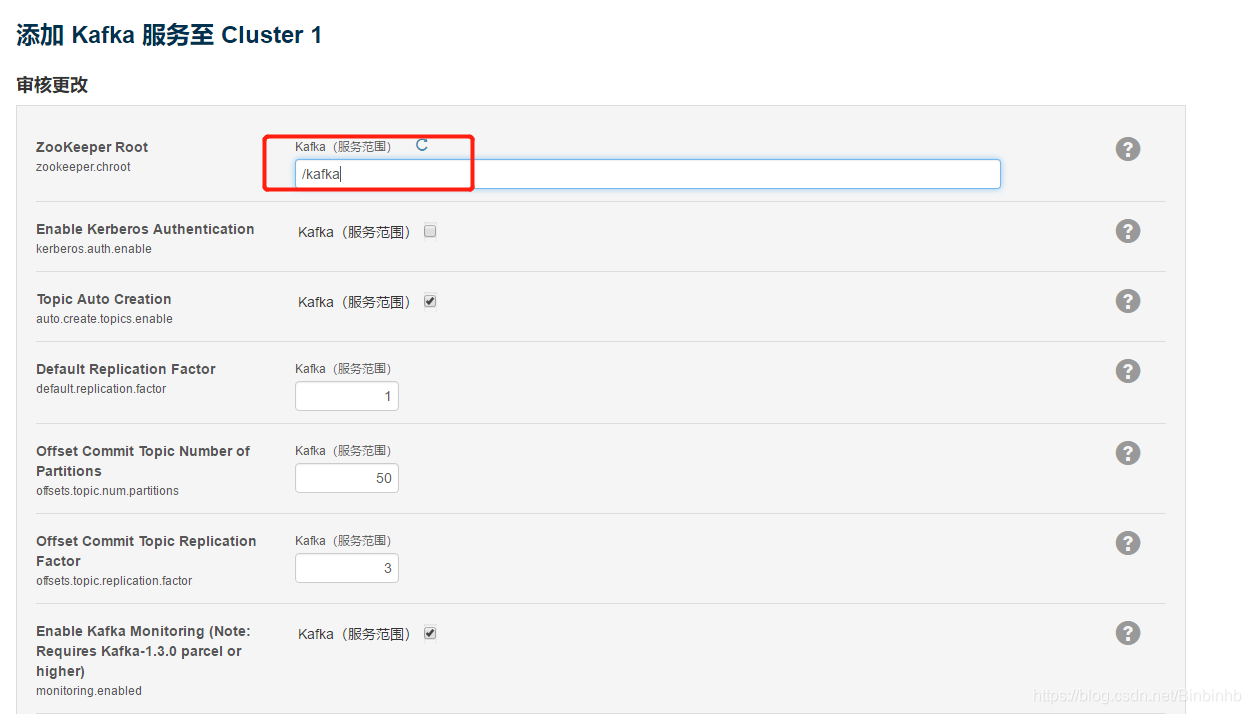
如果安装出问题可以看日志分析:
stdout,stderr,Role Log 三个日志输出
7、部署Spark2(未完待续)
官网链接(https://www.cloudera.com/documentation/spark2/latest/topics/spark2_installing.html)

















 710
710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









