







 本文介绍基于Python的静态图片网站爬虫程序设计。利用图片索引页网址规律批量生成索引页,借助Beautifulsoup库分析网页和图片链接,用Requests库访问页面和下载文件。考虑网站反爬虫机制,添加请求头,分批次下载图片,实现自动批量下载。
本文介绍基于Python的静态图片网站爬虫程序设计。利用图片索引页网址规律批量生成索引页,借助Beautifulsoup库分析网页和图片链接,用Requests库访问页面和下载文件。考虑网站反爬虫机制,添加请求头,分批次下载图片,实现自动批量下载。
原论文来自《基于 Python 的图片爬虫程序设计》——仇 明
针对静态图片网站:
本次爬 虫的设计思路 :由于图片的索引页的网址比较有规律,比如本次下载的各索引页的 网址就是最后一部分有所变化,所以可以批量生成所有的索引页即使不能批量生成,也可以网页解析来获得索引页地址),
在索引页中通过使用 Beautifulsoup 库 来获得各个图片的具体展示页面的网 址,继续在具体展示页面中再次使用Beautifulsoup 库获得图片的具体网址,并将所有的图片网址存于 一个列表中,
最后通过Requests库从列表中一一 下载图片,从而实现自动批量下载。
Python 有方便的第三方库进行使用,本次程序的流程就是使用 Beautifulsoup 库来分析网页链接、图片链接,在使用 Requests 库进行页面的访问、文件的下载。在图片的 批量下载中,当然网站会设定一定的反爬虫技术,此 时可以通过添加headers、设置代理服务器等方法来 进行下载。
具体实现
1、导入库

2、构建图片索引页地址

3、构建 Requests 的 headers
现在网络普遍有反爬虫机制,所以必须在 requests 中必须加上请求头。

4、通过 imgpageurl 函数获得索引页中所有图片 的具体展示页面的网址


5、通过 img_down_url 函数在图片的展示页中获 得图片的实际网址

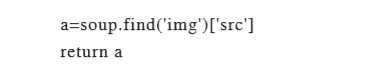
6、 通过loadDataset函数从文件中读取存取的 网址,并生成 list

7、 获得所有图片展示页的网址
由于短时间集中访问会被网站屏蔽IP地址, 为了便于程序的运行,将所有图片的展示页面地址, 存于文本文件中,便于以后的使用,每一行为一个 地址。

8、 得到所有图片文件的实际地址,并存于文本文 件中

9、用requests库对图片批量下载
从txt文件中读取图片的实际地址在实际的操 作中,由于图片数较多,可以设定图片地址范围, 进行分批次下载,最终下载完成图片


















 480
480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









