




 本文详细介绍了MySQL数据库的创建、使用、表操作、数据插入、SQL查询语法中的GROUP BY子句、多表连接查询、子查询以及集合运算等内容。通过实例演示了如何创建数据库、切换数据库、创建表、插入数据,以及如何使用GROUP BY与HAVING子句进行分组统计。同时,文章还讲解了内连接、自连接、外连接的使用,并提供了多个查询示例,帮助读者深入理解多表查询。此外,还介绍了子查询的多种类型,包括基于集合、带比较运算符、带有ANY或ALL、带有EXISTS谓词的子查询,以及如何进行集合运算,如使用UNION关键字合并查询结果。
本文详细介绍了MySQL数据库的创建、使用、表操作、数据插入、SQL查询语法中的GROUP BY子句、多表连接查询、子查询以及集合运算等内容。通过实例演示了如何创建数据库、切换数据库、创建表、插入数据,以及如何使用GROUP BY与HAVING子句进行分组统计。同时,文章还讲解了内连接、自连接、外连接的使用,并提供了多个查询示例,帮助读者深入理解多表查询。此外,还介绍了子查询的多种类型,包括基于集合、带比较运算符、带有ANY或ALL、带有EXISTS谓词的子查询,以及如何进行集合运算,如使用UNION关键字合并查询结果。
创建和使用数据库
目录
创建数据库
CREATE DATABASE menagerie;
![]()
注意:在选择和创建MySQL中的数据库时,Windows系统不区分数据库名字的大小写,而在linux系统中,是区分大小写的,大家以后会用到Linux做开发,一定要注意数据库名称的大小写。
切换数据库
创建了数据库不代表现在就会使用这个数据库,要使用数据库,还需要使用USE关键字来告诉MySQL,现在我们要使用xx数据库,指定menagerie数据库为当前使用的数据库,使用如下命令:
USE menagerie;
![]()
我们可以使用SELECT DATABASE()来查看目前选中的数据库:
SELECT DATABASE();

S注意:我们在与MySQL服务器建立连接的时候,也可以指定我们要使用的数据库,这样就无需再使用USE关键字,命令如下,注意到 menagerie是数据库的名字,不是密码,要输入密码啊的话,-p后面不能加空格,比如-p665544这样,这种输入密码的方式不太推荐,因为会把密码显式得暴露在命令行中:
mysql -h host -u user -p menagerie
创建表
让我们先康康刚刚创建的数据库中是否有数据表:
SHOW TABLES;
![]()
问题来了,我们需要一个什么样的表,每一列分别存放什么类型的数据,这是大家走上工作岗位后,真正需要关心的problem。
假设我们现在想创建一个宠物表(没错,这就是为什么刚才要取menagerie这个奇怪的数据库名),创建一个宠物表的话,我们需要宠物的名字,每个宠物主人是谁,宠物的年龄,性别。根据上述需求,我们创建表的命令如下:
CREATE TABLE pet (name VARCHAR(20), owner VARCHAR(20),
species VARCHAR(20), sex CHAR(1), birth DATE, death DATE);

这样我们就完成了表的创建,现在我们使用SHOW TABABLES命令再来康康,是不是多了个表:

那么这个表里面有哪些字段呢?我们可以使用DESCRIBE关键字来查看表的属性(注意和SELECT区分):
DESCRIBE pet;

插入数据
(考虑到一部分人的系统是win7,该部分会使用cmd命令提示符界面演示)
创建数据库的表结构后,下一步是插入数据。我们目前已经学习过的,插入数据最直观的方法是在workbench中手动插入数据,此处介绍另外两种插入数据的方式,都是以代码的形式导入/插入数据。
方法一:使用INSERT关键字增加/插入数据
如果准备添加一条新数据,可以使用INSERT关键字,代码示例如下:
INSERT INTO pet VALUES ('Puffball','Diane','hamster','f','1999-03-30',NULL);
方法二:从文件中导入数据
从本地文件中导入数据,我们这里准备了一个pet.txt的文本文件,使用LOAD关键字导入文本内容,MySQL会自动识别文本中的数据,将数据存储到数据库对应的表中,命令如下,注意替换文本文件的地址,比如我的地址是“D:\2020年上半学年课程\数据库\第七周\data\pet.txt”:
LOAD DATA LOCAL INFILE '你的文本文件地址' INTO TABLE pet
LINES TERMINATED BY '\r\n';
从外部导入数据时,会报错,原因是MySQL默认拒绝导入本地文件,我们需要手动开启,下面是解决方案:
我们先看一下`local_infile`这个变量:
SHOW GLOBAL VARIABLES LIKE 'local_infile';

我们可以看到'local_infile'这个变量是一个布尔变量,且目前的值是OFF的,我们需要将'local_infile'设置为ON,从而允许本地文件的导入。因此我们先断开与MySQL服务器的连接,再使用如下命令登陆:
--local-infile=1 -u root -p
解决方案和更多内容可以参考如下网址:
————————————解决完毕————————————
重新使用LOAD命令加载数据。
大家在删除表中的数据时,可以使用TRUNCATE关键字删除,如删除pet表中所有数据的命令是:
TRUNCATE TABLE pet;
注意一下, 文本文件中的死亡日期是空值,但是MySQL会将日期默认设置为0000-00-00,是为了统一时间的格式,具体可以参考如下链接:
MySQL :: MySQL 8.0 Reference Manual :: B.3.4.2 Problems Using DATE Columns
SQL查询语法中GROUP BY子句介绍
话接4.4节的SQL查询语句,我们继续查询语句中使用GROUP BY关键字的查询介绍:
GROUP BY可以与WHERE一起使用
带有WHERE子句的分组查询是先执行WHERE子句的选择,再对得到的结果进行分组统计,比如下面这个例子:
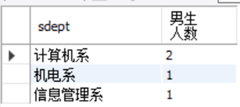
统计每个系男生的人数:
SELECT sdept, COUNT(*) AS 男生人数
FROM student
WHERE ssex='男'
GROUP BY sdept;
GROUP BY于HAVING子句联合使用
GROUP BY还可以与HAVING连接使用,HAVING子句用于对分组后的统计结果再进行筛选,它的功能优点像WHERE子句,但是它是用于单个组而不是记录。要注意的是:HAVING子句中可以使用聚合函数,而在WHERE子句中无法使用聚合函数。
要怎么理解上后面这句话呢?你可能会问?哎为啥都是条件筛选,凭啥HAVING可以使用聚合函数,WHERE就不行,大家回想以下我们之前讲聚合函数的知识时,其实SELECT后是可以接聚合函数的,也就是对WHERE删选出来的结果使用MAX(),MIN()等函数,只不过放在了SELECT子句中。
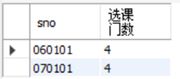
让我们来结合例子理解一下,查询选课门数超过3门的学生的学号和选课门数:
SELECT sno 学号, COUNT(*) AS 选课门数
FROM sc
GROUP BY sno
HAVING COUNT(*) >3;
此语句的处理过程为:先进行GROUP BY对sc表数据按照sno分组,再使用聚合函数COUNT(*)计数,最后筛选出统计结果大于3的组。
条件筛选的查询效率
注意:在实际操作中,对于可以在分组至之前应用的筛选条件,在WHERE子句中指定他们更加有效,这样可以有效减少参与分组的数据行,因为SQL查询语句是先执行WHERE筛选再进行GROUP分组的,我们来看下面这个例子:
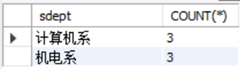
查询“计算机系”和“机电系”每个系的学生人数:方法一 直接使用GROUP BY:
SELECT sdept, COUNT(*)
FROM student
GROUP BY sdept
HAVING sdept IN ('计算机系','机电系')
方法二 先使用WHERE子句筛选再使用GROUP BY进行分组:
SELECT sdept, COUNT(*)
FROM student
WHERE sdept IN ('计算机系','机电系')
GROUP BY sdept
第二种写法比第一种效率更高,因为参与分组的数据少。
多表连接查询
内连接
内连接是一种最常用的连接类型,使用内连接时,如果两个表的相关字段满足连接条件,则从这两个表中国提取数据并组合成新的操作记录。
使用内连接子句时,关键字是:INNER JOIN 和ON,具体的写法如下:
SELECT 属性
FROM 表1 [INNER] JOIN 表2
ON <连接条件>
注意:连接条件中用于比较的属性必须是可比的, 必须是语义相同的列。
让我们看一个具体的例子,查询每个学生及其选课的详情:
SELECT *
FROM student
INNER JOIN sc
ON student.sno=sc.sno;
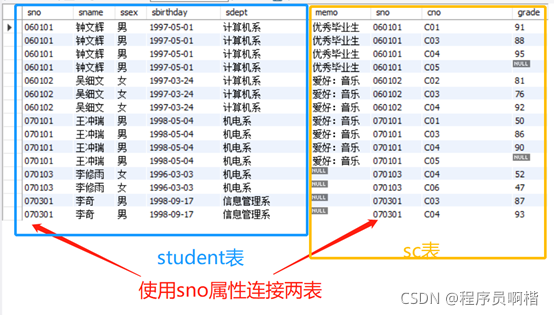
查询结果图
两个表的连接包含了两个表的全部列,sno属性出现了两次,因为我们使用的是 “SELECT *” 来查询全部内容,在实际操作中,建议选取需要的列作为查询结果。
Q1:请实现查询每个学生及其选课信息,要求去掉重复列(student表和sc表连接,指明属性)
进行多表查询时,如果表的名称过长,我们像给属性取别名一样,可以给表取别名,别名跟在表名后面。此外,多表连接可以对两个甚至更多个表进行连接,为了进一步理解这两个知识点,我们来看下面这个例子,查询“计算机系”选修了“数据库原理”课程学生的成绩单,要求包含姓名、课程名称和成绩信息:
SELECT sname, cname, grade
FROM student S INNER JOIN SC
ON S.sno=sc.sno
JOIN course C ON sc.cno=c.cno
WHERE sdept='计算机系' AND cname='数据库原理';
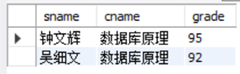
查询结果图
我们进一步分析一下上面的语句结构:此例中student和course两个表本身没有关联,但sc表中有sno和cno,可以作为连接student和course表的“桥梁”。此外我们在连接后对连接的内容使用WHERE子句筛选,大家可以试一试不加WHERE子句的结果,加深理解JOIN的用法
Q2:查询选修了“数据库原理”课程的学生姓名和所在系(提示:也是通过sc表连接student和course表,再添加WHERE子句筛选指定系)
在多表查询中亦可以进行分组统计(使用GROUP BY子句),例如统计每个系的学生的平均成绩:
我们缕一缕思路:看到“统计”、“平均”这两个词,大家应该会想到我们该使用聚合函数了,而且是AVG()这个聚合函数,在看看“每个系”,说明我们要按照系别分组,因此需要GROUP BY对系别分组,同样的,我们需要代码如下“
SELECT sdept, AVG(grade)
FROM student s INNER JOIN sc
ON s.sno=sc.sno
GROUP BY sdept;
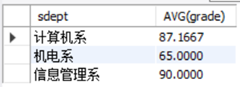
查询结果图
Q3:统计“计算机系”学生中每门课程的选课人数、平均分、最高分和最低分。(提示:在此查询中,需要使用到的查询知识有:多表连接(INNER JOIN)、行选择(WHERE)、分组统计(GROUP BY))
自连接
自连接是一种特殊的内连接,它是指相互连接的表是同一张表,但在逻辑上将其看成两张表。要让同一张表在逻辑上成为两张表,必须通过为表取别名的方法,例如查询课程为“数据库原理”的先修课名称:
SELECT c1.cname 课程名, c2.cname 先修课程名
FROM course c1 INNER JOIN course c2
ON c1.precno=c2.cno
WHERE c1.cname="数据库原理";

查询结果图
Q4:同样地,我们可以去掉WHERE子句,康康查询语句是什么结果,它说明了什么意义?
外连接(LEFT JOIN/RIGHT JOIN)
在内连接操作中,只有满足条件的元组才能作为结果输出,我们以查询计算机系全体学生的选课情况(学号、姓名、所在系、课程编号)为例:
SELECT s.sno, sname, sdept, sc,cno
FROM student S LEFT JOIN sc
ON s.sno=sc.sno
WHERE sdept='计算机系';
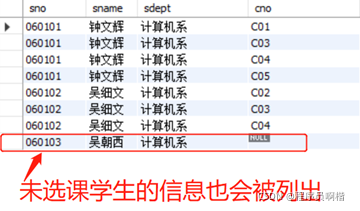
查询结果图
注意我们这边使用的是LEFT JOIN,LEFT JOIN表明左边表“为大”,不必满足连接条件。换句话说:吴朝西同学可以不选课,但是已经选课的同学必定在student表中出现。另外一个RIGHT JOIN语句含义则相反。
让我们再看一个例子, 查询没有人选的课程的课程名:
SELECT cname, sc.sno
FROM course c LEFT JOIN sc
ON c.cno=sc.cno
WHERE sc.cno IS NULL;
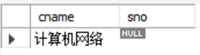
查询结果图
同样,我们可以先去掉WHERE子句看看结果,理解一下LEFT JOIN的作用是什么。
总结
本部分讲述了多表查询的方式——使用JOIN子句来连接多个表,涉及多表连接的情况,往往需要先分析需求,再敲代码。其实我们不断得给查询语句增加关键字和新的子句,目的都是为了实现某个功能,如统计使用聚合函数,分组使用GROUP BY子句,多表连接使用JOIN...ON子句,大家或许会陌生,不过8这都是大佬们制定好的规则,大家多多熟悉提高练度吧~
悄悄话:在实际操作当中内连接用的很频繁(比较重要),自连接和外连接用的比较少,对于内连接大家需要好好掌握,外连接要清楚他的使用方式和场景。
子查询(解决一个查询语句查询不了的问题)
介绍子查询之前,首先介绍一下嵌套查询:即在一次查询中使用多个查询语句,换句话说,嵌套查询用于对查询的结果进一步查询。
子查询的定义:如果一个查询语句嵌套在另一个查询语句中,我们就把这个查询“在里层”的查询叫做子查询。
主查询的定义:包含子查询的语句,叫做主查询。
基于集合的子查询
让我们先来看一个简单的例子更形象地理解一下,查询与钟文辉在一个系学生的学号、姓名、性别、所在系:
思路:先查到钟文辉在哪个系(第一个查询语句),再找到该系的所有学生(第二个查询语句):
SELECT sno, sname, ssex, sdept
FROM student
WHERE sdept IN(
SELECT sdept
FROM student
WHERE sname="钟文辉")
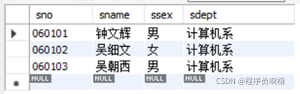
可以发现,在WHERE条件里面跟了一个查询子句,注意整个查询的逻辑是:先查询括号里面(子句)的内容,再执行外层查询。
让我们再来补充一些知识点:
- 子查询语句和普通查询语句一样,必须包含“SELECT FROM”结构,其他的WHERE,ORDER BY,GROUP BY等根据需要使用。
- 基于集合的子查询形式如:WHERE <列名> [NOT] IN (子查询)
带比较运算符的子查询
对比基于集合的子查询,是把IN换成比较运算符(>, <, =...),看个例子理解一下,查询选了"C04"号课程,且课程高于此课程平均成绩的学生的学号和该门课的成绩:
思路:是不是很绕?绕就对了,冷静冷静让我们来分析一下,C04号课程和学生学号、成绩都在sc表中,我们应当先求的是c04课程的平均成绩,再查询选修了c04号课程且课程成绩大于平均成绩的学生学号、成绩。
SELECT sno, grade
FROM sc
WHERE cno='c04' and grade>
(SELECT AVG(grade)
FROM sc
WHERE cno='C04')
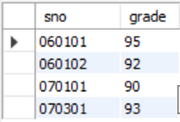
注意到WHERE的条件前一部分是规定课程号,后一部分是子查询的结果,带有比较运算符的嵌套查询中,子查询一般是一个结果,因此子查询一般是一个带有聚合函数的查询语句。
总结:从实用性角度考虑,虽然子查询不是很好理解,但是可以更加精细得筛选查询的内容,是非常实用的。
带有ANY或者ALL的子查询
当子查询的结果有多个值时,可使用ANY或者ALL来修饰子查询的结果,看个例子:查询比'C03'课程成绩都高的同学选了'C04'课程的学生学号和成绩。
思路:先查询出所有选修了'C03'课程学生的成绩,再使用ALL修饰子查询
SELECT sno, grade
FROM sc
WHERE cno='c04' AND grade > ALL
(SELECT grade
FROM sc
WHERE cno='c03')
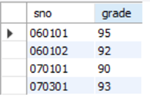
注意ALL关键字的位置,是"grade>ALL(子查询)"
(*) 带有EXISTS谓词的子查询
EXISTS代表存在,使用带EXISTS为此的子查询可以进行存在性测试,其基本使用形式为:
WHERE [NOT] EXISTS
更多关于子查询的例子和讲解请参考,可以帮助大家理解这些关键字的用法:
子查询一(WHERE中的子查询) - TonySoprano - 博客园
查询的集合运算(合并查询结果)
查询的集合运算从操作上可以称为“合并查询结果”,就是将多个SELECT语句的查询结果合并到一起。合并查询结果使用UNION、INTERSECT和EXCEPT(SQL Server2012里面的,MySQL只有UNION)。
使用UNION关键字
查询“计算机系”和“机电系”的所有学生信息。
思考:此查询也可通过之前学到的在WHERE语句中使用IN('计算机系','机电系')这样的方法实现,此处我们可以尝试使用并运算实现:
(SELECT sno, sname, ssex, sdept
FROM student
WHERE sdept='计算机系')
UNION
(SELECT sno, sname, ssex,sdept
FROM student
WHERE sdept='机电系')
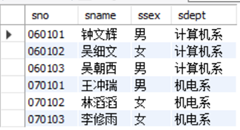
带有排序和LIMIT关键字的集合运算
合并查询可以和排序以及限定查询结果个数的LIMIT使用。此处补充一个知识点:LIMIT关键字,LIMIT是用来筛选最后查询结果可显示个数的,经常与ORDER BY一起使用,用法是加在查询语句的最后面,格式为
LIMIT 查询个数,
看一个例子:查询选修了'C03'和'C04'学生的考试成绩,每个课程只取前三名学生的信息(注意括号的使用)。
分析:
(SELECT sno, cno, grade
FROM sc
WHERE cno='c03'
ORDER BY grade DESC
LIMIT 3)
UNION
(SELECT sno, cno, grade
FROM sc
WHERE cno='c04'
ORDER BY grade DESC
LIMIT 3)
UNION ALL关键字
使用UNION ALL关键字的方法与UNION关键字类似,也是将多个结果合并到一起,但是UNION ALL不会去除相同记录,注意我们目前使用的MySQL是8.0版本,UNION ALL的用法等于UNION,也就是说UNION ALL会自动去除相同记录,但是在MySQL5.7版本的UNION ALL是不会去除相同记录的。
TIP:
1. 注意合并查询的两个子句需要加括号。
2. 合并查询结果的操作,大家可以形象得把他理解为两个表格竖着叠起来。对比查询操作(SELECT FROM),查询操作是把查询的列“横着”拼起来


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











