



 本文介绍了一个使用未封装Ajax实现的聊天室项目,详细讲解了如何将消息和用户对象存储在Map集合中,并通过jsonObject格式输出。文章还探讨了从前端页面获取这些数据的方法。
本文介绍了一个使用未封装Ajax实现的聊天室项目,详细讲解了如何将消息和用户对象存储在Map集合中,并通过jsonObject格式输出。文章还探讨了从前端页面获取这些数据的方法。
#Ajax
这个聊天室项目是用未封装的ajax拿来练手的,把消息对象集合List<'message>和用户对象List<'user>集合封装在同一个Map集合中
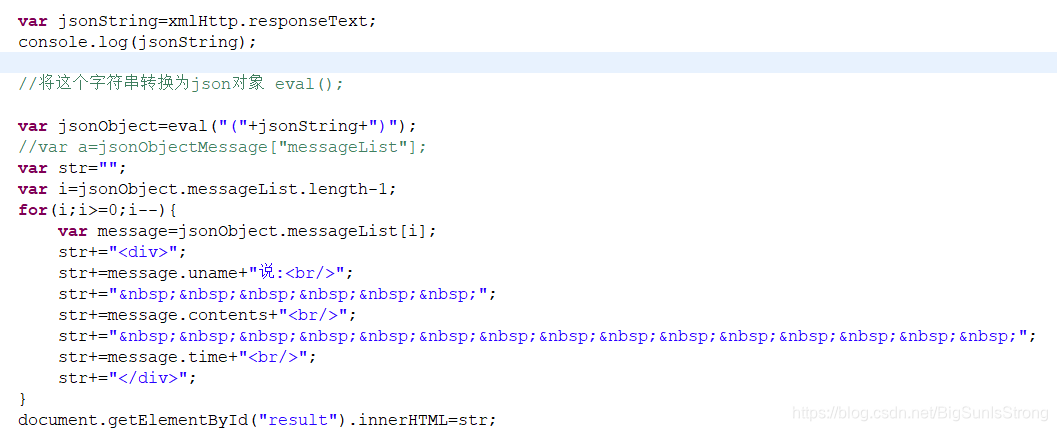
因为jsonObject输出的格式为{“键”:[“键”:值]}
就是存储格式Map{“username”,List<Object};
获取的话需要循环用获取所有值,
语法:jsonObject.键名[i]; //这里的键名是Map的键名。
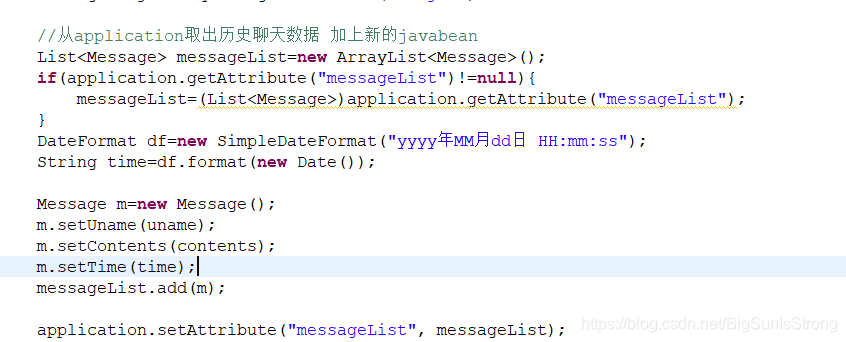
发送消息时存储进消息集合,并且用存进Message对象中 方便后来取 上面的message.uname 就是这样的来的
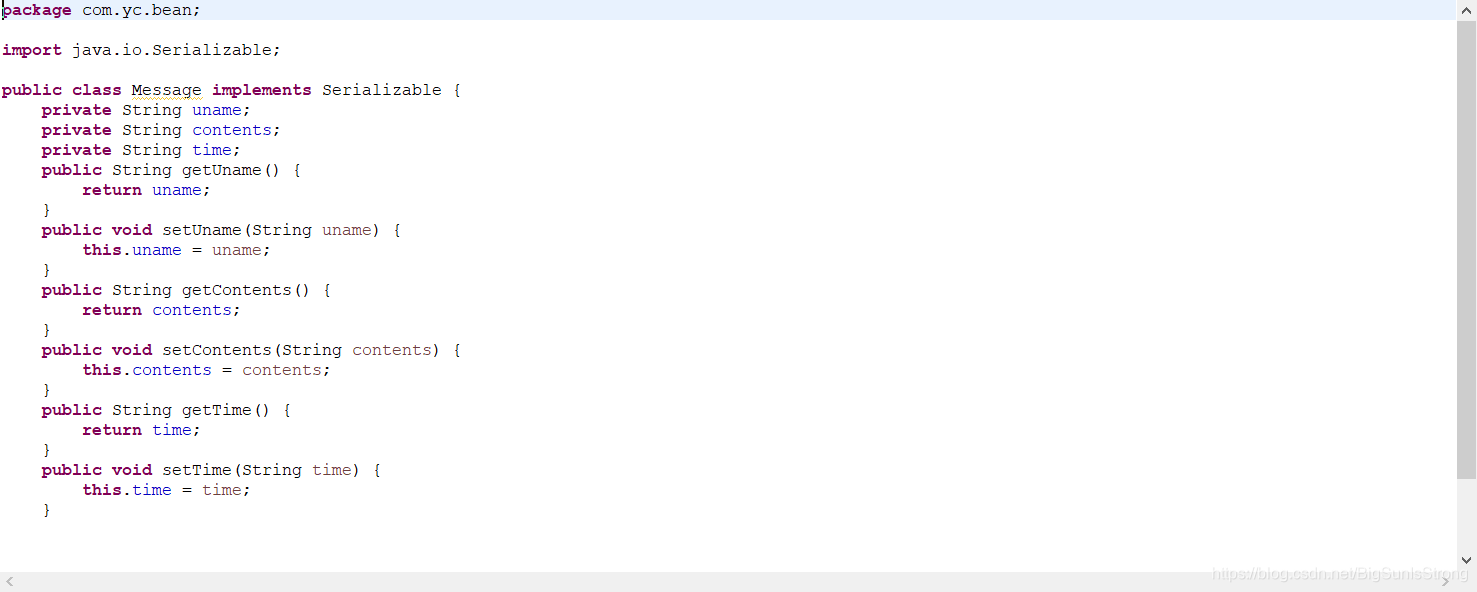
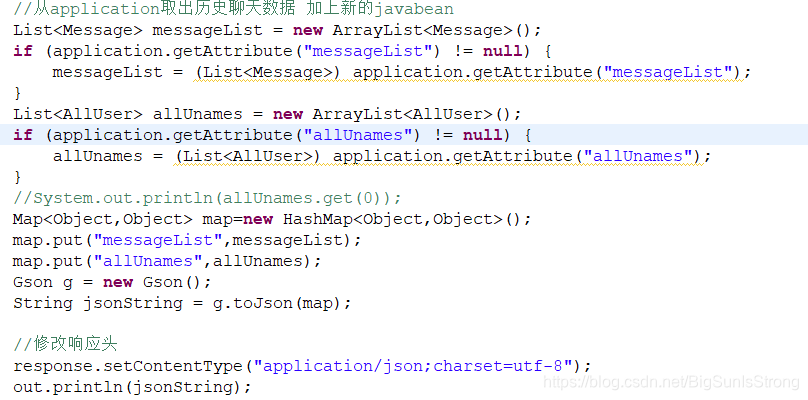
这里是取了历史聊天数据之后再一并存入map集合中 然后json传到前台页面,前台获取就是上面的图片。

















 1168
1168

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









