




 卡内基梅隆大学的研究人员设计了一种新方法,使AI能够为故事创作更多样化和有趣的结局。通过集中注意力于故事的重要词组,该模型在Story-Cloze任务中达到了72%的准确率。
卡内基梅隆大学的研究人员设计了一种新方法,使AI能够为故事创作更多样化和有趣的结局。通过集中注意力于故事的重要词组,该模型在Story-Cloze任务中达到了72%的准确率。

大数据文摘出品
编译:林苗
追小说的时候最怕的是什么?烂尾!比烂尾更可怕的是什么?是作者大大写着写着弃坑了。而现在,有一只能为给定的故事创造多样化结局的AI了。
OpenAI的GPT-2是一个非常高大上的自然语言处理系统,在其他同类型的AI还在“前后是否连贯一致”和“是否足够像人”这两个问题上苦苦挣扎时,它已经能生成一篇高度拟人化的演讲。
一般AI创作的故事结尾都是套用相似的通用模板,而且缺乏内容上的连贯性。为了克服这一明显的短板,卡内基梅隆大学计算机科学学院的科学家们设计出了一种新的方法,这个方法的关键在于将训练模型的注意力集中在故事的重要词组上,促进特定词汇的产生。
相关研究论文链接
“所谓故事的语境,其实就是把特征和事件连接起来的句子序列。这个任务的难点在于对上下文本的特征、事件以及其他对象进行建模,再基于这个模型,产生一个既符合逻辑,又符合常理的结局。其中,对事件、其他实体,以及他们在整个故事中的关系进行语义学的归纳提取,是一个非常艰巨且重要的任务。”合作者指出,“我们的研究表明,两者结合能产生更多样化、更有趣的故事结局。”
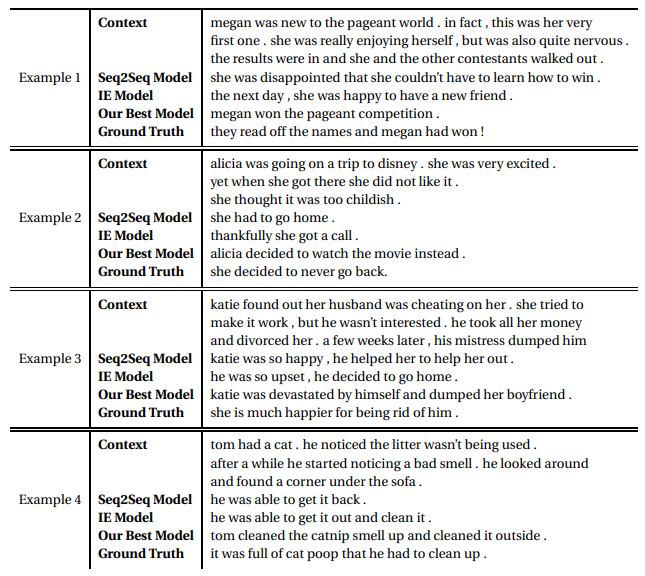 研究所用模型的部分输出结果
研究所用模型的部分输出结果该团队利用seq2seq翻译模型(一种能够学习依赖关系的长短时记忆深度神经网络)去形成目标故事语境中词汇的数学表征,然后对这些词汇的关系进行训练,再将它们重新翻译成人类可读的文本。
为了能整合吸收故事中的关键词组,研究者们使用RAKE算法进行提取,并基于词组中单词的词频和共现率进行打分,再根据相应的分数,对这些词组进行人工分类。只有达到特定阈值的词组,才会被认为是重要的。
为了能产生结局,研究者们在ROCStories语料库上对模型进行训练,该语料库涵盖了50,000多个五句话的微故事。

为了评估训练模型的好坏,研究者们首先采用DIST(distinct)命令来计算所产生的结局中,去重后的一元语法(unigram,给定样本中,n个对象的连续序列)、二元语法(bigram,一对相邻的书面单元如字母、音节或单词)和三元语法(trigram,三个相邻的书面单元)的数量,再把这些数量分别在总的一元语法、二元语法和三元语法中的占比作为衡量指标。
在另一项独立的测试中,研究者们采用开源的Story-Cloze任务(故事型常识阅读理解任务),对谷歌的BERT模型训练,并与基准水平进行比较。该任务要求是,根据给定语境的四句话,在两个候选句子中选出哪一句是可以根据前四句推导出来的。
那么,AI表现如何呢?普利策奖应该是拿不了的。

尽管这个模型在DIST中表现得非常好,并且在Story-Cloze测试中达到了72%的准确率,但它偶尔还是会产生一些不合理的结局,比如“Katie被他自己震惊了,并抛弃了她的男朋友”,或者引用一些与名词词性不符的代词(Katie为女名,与himself矛盾)。
研究者们承认,想要确保输出结果“保持故事语境中的语义学和一定水准”,并且在逻辑上合理一致,还需要更进一步的深入研究。尽管如此,他们也还是坚持认为他们已经从“定量”和“定性”两个角度来表明,他们的模型能够在基线水平上实现“重大的”改进。


















 849
849

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









