






 AI技术助力古草体文字识别,提升日本历史研究效率。谷歌东京发布会展示KuroNet,一款基于深度学习的OCR工具,能将古日本常用‘古草体’文字转换为现代日语,每页识别仅需2秒,一小时即可翻刻整本书籍。
AI技术助力古草体文字识别,提升日本历史研究效率。谷歌东京发布会展示KuroNet,一款基于深度学习的OCR工具,能将古日本常用‘古草体’文字转换为现代日语,每页识别仅需2秒,一小时即可翻刻整本书籍。

 “古草体”与现代日文
“古草体”与现代日文
数据化处理远远不够,能阅读才是根本

塔琳女士手拿“古草体”文本。本次项目由信息与系统研究机构和数据科学研究(ROIS-DS)、人文开放数据联合使用中心合作完成。
声明:本项AI的开发使用了谷歌技术,可能会让大家误以为是谷歌开发的,实际不然,在此指出并订正。另外,准确地说,项目的操作内容不是“翻译”而是“翻刻”。特此声明。

将明治时代的“古草体”转换为现代日语

东京神保町的二手书店里有数千本古籍在售卖

AI不能解读的地方被做了标记
声明:虽然该项目是“谷歌协作开发”,但是谷歌只是本次活动的主办方,没有协助此次项目开发。特此声明。
利用深度学习和TensorFlow.js,开发名为“KuroNet”的工具
名为KuroNet的“古草体”OCR,以及将它应用于TensorFlow.js进行特征识别
声明:开始时用的是“国立信息学研究所拥有的数据”,但正确的应该是“国家文献研究博物馆所拥有的数据”。特此声明。
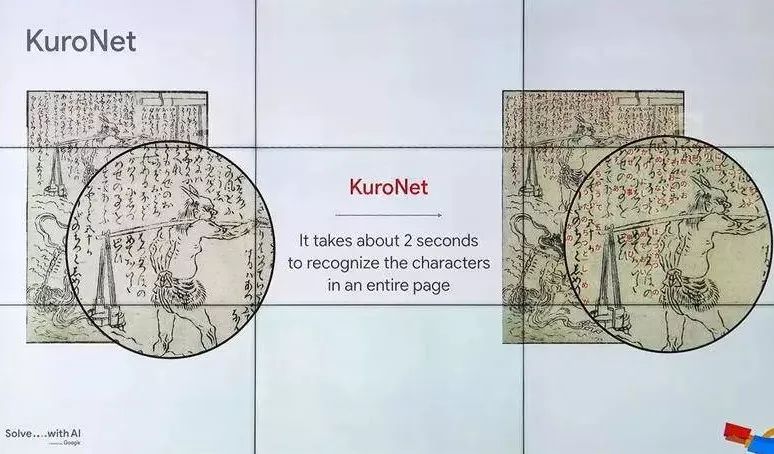
KuroNet2秒就“翻译”完一页

“翻译”一本古文需要一个小时,正确率为85%

TensorFlow.js提供的Web程序

开放源码提供
在Kaggle上举办比赛募集提高OCR识别率的方法
https://www.nii.ac.jp/news/release/2019/0710.html

Kaggle上举行的比赛


















 1690
1690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









