




 本文介绍使用Keras实现LeNet-5卷积神经网络的过程,该模型由Yann LeCun设计,用于手写数字识别。文章详细展示了LeNet-5的结构,并在MNIST数据集上进行训练,通过可视化训练过程,发现模型在第4个epoch达到最佳状态。
本文介绍使用Keras实现LeNet-5卷积神经网络的过程,该模型由Yann LeCun设计,用于手写数字识别。文章详细展示了LeNet-5的结构,并在MNIST数据集上进行训练,通过可视化训练过程,发现模型在第4个epoch达到最佳状态。
LenNet5-keras实现(MNIST数据集)
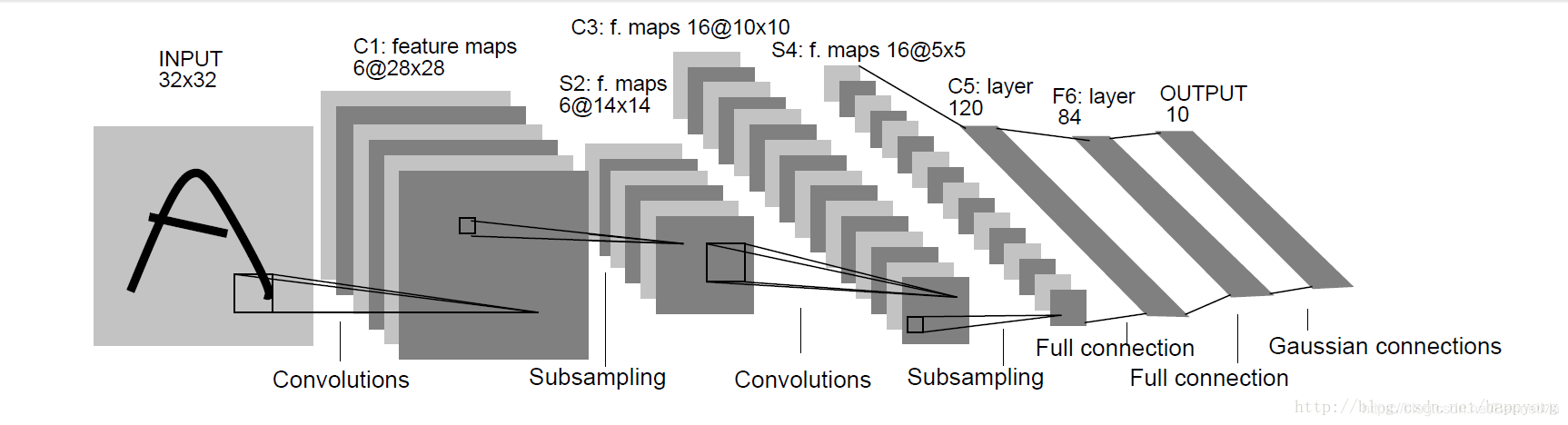
LeNet-5卷积神经网络模型
LeNet-5:是Yann LeCun在1998年设计的用于手写数字识别的卷积神经网络,它是早期卷积神经网络中最有代表性的模型。
LenNet-5共有7层(不包括输入层)
LeNet-5中主要有2个卷积层、2个下抽样层(池化层)、3个全连接层
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(6,(5,5),activation='relu',input_shape=(28,28,1)))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(16,(5,5),activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Flatten())
model.add(layers.Dense(128,activation='relu'))
model.add(layers.Dense(84,activation='relu'))
model.add(layers.Dense(10,activation='softmax'))
Using TensorFlow backend.
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 24, 24, 6) 156
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 12, 12, 6) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 8, 8, 16) 2416
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 4, 4, 16) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 256) 0
_________________________________________________________________
dense_1 (Dense) (None, 128) 32896
_________________________________________________________________
dense_2 (Dense) (None, 84) 10836
_________________________________________________________________
dense_3 (Dense) (None, 10) 850
=================================================================
Total params: 47,154
Trainable params: 47,154
Non-trainable params: 0
_________________________________________________________________
在MNIST数据集上训练卷积神经网络
from keras.datasets import mnist
from keras.utils import to_categorical
(train_images,train_labels),(test_images,test_labels)=mnist.load_data()
train_images = train_images.reshape((60000,28,28,1))
train_images = train_images.astype('float32')/255
test_images = test_images.reshape((10000,28,28,1))
test_images = test_images.astype('float32')/255
train_labels = to_categorical(train_labels)#将类别向量转换为二进制(只有0和1)的矩阵类型
test_labels = to_categorical(test_labels)
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',#交叉熵损失函数
metrics=['accuracy']) #监控的指标
history = model.fit(train_images,train_labels,epochs=10,batch_size=128,validation_split=0.2)
Train on 48000 samples, validate on 12000 samples
Epoch 1/10
48000/48000 [==============================] - 14s 295us/step - loss: 0.3384 - acc: 0.8974 - val_loss: 0.1072 - val_acc: 0.9678
Epoch 2/10
48000/48000 [==============================] - 14s 292us/step - loss: 0.1000 - acc: 0.9691 - val_loss: 0.0753 - val_acc: 0.9773
Epoch 3/10
48000/48000 [==============================] - 14s 293us/step - loss: 0.0682 - acc: 0.9783 - val_loss: 0.0582 - val_acc: 0.9824
Epoch 4/10
48000/48000 [==============================] - 14s 292us/step - loss: 0.0520 - acc: 0.9844 - val_loss: 0.0527 - val_acc: 0.9846
Epoch 5/10
48000/48000 [==============================] - 14s 291us/step - loss: 0.0419 - acc: 0.9875 - val_loss: 0.0533 - val_acc: 0.9847
Epoch 6/10
48000/48000 [==============================] - 14s 292us/step - loss: 0.0351 - acc: 0.9890 - val_loss: 0.0545 - val_acc: 0.9833
Epoch 7/10
48000/48000 [==============================] - 14s 292us/step - loss: 0.0298 - acc: 0.9910 - val_loss: 0.0514 - val_acc: 0.9856
Epoch 8/10
48000/48000 [==============================] - 14s 292us/step - loss: 0.0253 - acc: 0.9920 - val_loss: 0.0453 - val_acc: 0.9871
Epoch 9/10
48000/48000 [==============================] - 14s 292us/step - loss: 0.0215 - acc: 0.9929 - val_loss: 0.0512 - val_acc: 0.9860
Epoch 10/10
48000/48000 [==============================] - 14s 292us/step - loss: 0.0185 - acc: 0.9939 - val_loss: 0.0475 - val_acc: 0.9874
import matplotlib.pyplot as plt
%matplotlib inline
loss_values = history.history['loss']
val_loss_values = history.history['val_loss']
epochs = range(1,len(loss_values)+1)
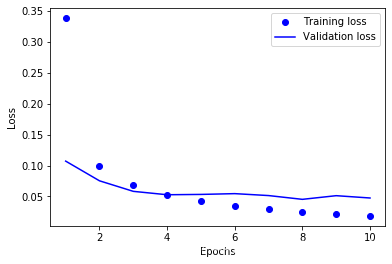
plt.plot(epochs,loss_values,'bo',label = 'Training loss')
plt.plot(epochs,val_loss_values,'b',label = 'Validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()#显示标签
plt.show()
plt.clf()#清空图像
acc = history.history['acc']
val_acc = history.history['val_acc']
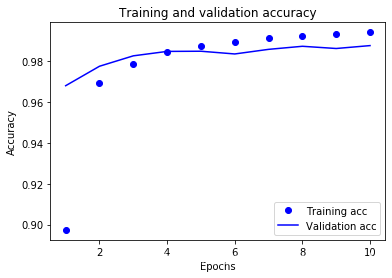
plt.plot(epochs,acc,'bo',label = 'Training acc')
plt.plot(epochs,val_acc,'b',label = 'Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()#显示标签
plt.show()
test_loss,test_acc = model.evaluate(test_images,test_labels)
10000/10000 [==============================] - 2s 164us/step
test_loss
0.035076891154548505
test_acc
0.9895
由图可知当训练到第4个epoch时,刚刚好,既不过拟合,也不欠拟合


















 1590
1590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











