




 本文深入解析生成式对抗网络(GAN)的工作原理,探讨其在博弈理论基础上的生成式模型与判别式模型如何交互学习,以及如何通过训练达到稳定状态,生成高度模仿训练样本的数据。
本文深入解析生成式对抗网络(GAN)的工作原理,探讨其在博弈理论基础上的生成式模型与判别式模型如何交互学习,以及如何通过训练达到稳定状态,生成高度模仿训练样本的数据。
看了几篇博文,简单记录一下GAN网络(generative adversarial nets 生成式对抗网络)
定义
GAN网络起源于博弈理论,博弈的双方分别是生成式模型(G)和判别式模型(D)
生成式模型的输入是一组服从某一分布的噪声,生成一个类似真实训练数据的样本;
判别式模型的输入就是生成式模型的输出,判别式模型的目的是判断这个生成的样本是不是来自于训练数据(概率);
有点类似于G是用纸生成假钞,力求仿的像;而D是鉴别假钞,力求鉴别的准确
也就是:
随机输入,G生成样本;D判断是不是足够像训练样本;G根据D的判断进行学习;D根据G的输出继续判断……
最终的稳定状态就是G能生成高度模仿训练样本的样本,而D已经不能判断G的输出是否是来自训练样本了
有点类似下图(图片来自知乎https://zhuanlan.zhihu.com/p/33752313 ):
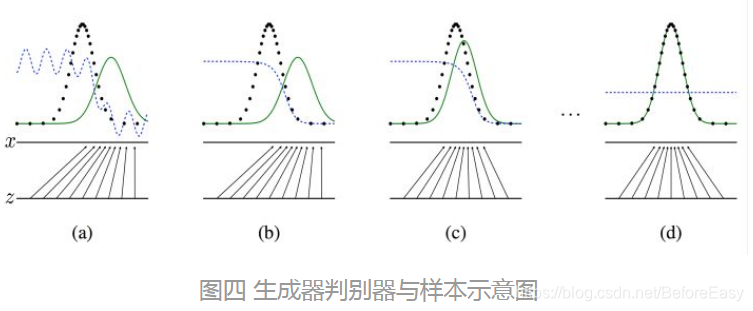
上图中黑色虚线表示真实的样本分布,绿色实线表示真实的样本分布,蓝色虚线表示判别器判别概率的分布。可以看到最终的理想情况下为d图的状态,G生成的样本的分布已经和真实的样本分布非常像,以至于D已经无法分辨了(概率为0.5)
训练
向固定G训练D,得到比较好的判别函数;然后再固定D训练G —— 毕竟有了好的判别器,才能更好的教生成器学习
先初始化D和G的参数,选取部分噪声样本。通过生成器获得对应数量的生成样本,训练判别器尽可能好的区分生成的样本和真实样本,尽可能大的区分两者
循环k次更新了D之后,使用较小的学习率再更新G的参数,训练生成器使其尽可能的减小生成样本与训练样本的差距,也即是尽可能的让D判别错误
目标函数
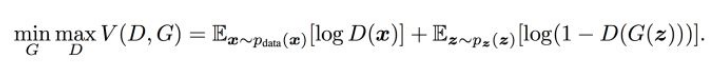
这个还是从基本的交叉熵损失函数演变而来的
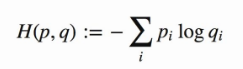 这里pi是真实的样本分布概率,qi是生成的样本分布
这里pi是真实的样本分布概率,qi是生成的样本分布
二分类的问题就可以写成:
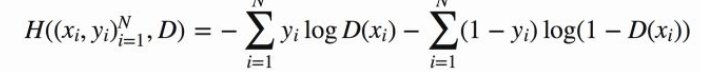
但是GAN中一个概率表示对于真实样本D的输出概率即D(x),另一个则是生成器生成的样本即D(G(z))
对于真实样本,对应的是交叉熵中yi的部分;生成式样本对应的是交叉熵中1-yi的部分
所以有了总的训练目标:
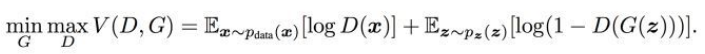
这个就是上面的二分类交叉熵问题的期望表示(期望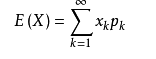 )
)
前面的常数我们并不在乎,重要的是符号
这里的V(D,G)表示生成样本与真实样本之间的差距,D的训练目标是使差距变大更好区分;G的训练目标是使差距变小不易区分
max部分是固定G,训练D,尽可能的让差距变大;
min的部分是固定D的条件下得到生成器G,使得最小化差距
仍然是个博弈的问题

















 721
721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









