




 本文全面解析了HTTP与TCP远程调用的差异、volatile的底层实现与适用场景、线程安全的单例模式、CAS无锁机制、Synchronized与ReentrantLock的区别、AQS架构、负载均衡模式、MySQL复制原理、API网关的优缺点、Redis数据类型及分布式锁、一致性hash的优化场景、ArrayList与LinkedList的区别、hashset与hashmap的差异、ConCurrentHashMap与CopyOnWriteArrayList的对比、数组与链表的性能差异等核心技术。
本文全面解析了HTTP与TCP远程调用的差异、volatile的底层实现与适用场景、线程安全的单例模式、CAS无锁机制、Synchronized与ReentrantLock的区别、AQS架构、负载均衡模式、MySQL复制原理、API网关的优缺点、Redis数据类型及分布式锁、一致性hash的优化场景、ArrayList与LinkedList的区别、hashset与hashmap的差异、ConCurrentHashMap与CopyOnWriteArrayList的对比、数组与链表的性能差异等核心技术。
1.HTTP远程调用和TCP远程调用的区别?
背景:随着项目越来越大,访问量越来越大,为了突破性能瓶颈,需要将项目拆分成多个部分,这样比起传统的项目都是本地内存 调用,分布式的项目之间需要在网络间进行通信
服务之间的远程调用通常有两种方式,即基于TCP的远程调用和基于Http的远程调用
基于TCP的RPC实现
主要是服务提供方定义socket端口和提供的方法名称已经需要的参数结构,服务调用方通过连接服务方的socket端口,进而调用相关方法,并且将需要通信的数据作为参数传递,需要值得注意的是参数在传递的时候需要在服务调用端进行序列化然后在服务提供端进行反序列化,个人理解就行netty之间的通信方式,就是一种基于tcp的远程调用
基于HTTP的RPC实现
对于HTTP的RPC实现,本人觉得与现在的restful风格很类似,主要是在服务调用方通过标识请求,GET,POST然后通过url来定位到服务提供方提供的服务,数据通过xml或者json来传输,省去了TCP的序列化和反序列化
区别
RPC是基于socket通信,在协议层面处于较底层,优点是传输效率高,但是开发难度相对较高,而HTTP处于较高层面,开发难度相对较小,不用维护socket端口和数据序列化相关问题,但是传输效率比起TCP来低了一些
2.volatile的适用场景及底层实现
volatile可以保证顺序性(happen--before原则)和可见性并且可以禁止指令重排序(内存栅栏)
volatile可以适用,多个变量或单个变量当前的值与修改后的值没有约束
volatile变量替代锁的条件:
对变量的写操作不依赖于的当前的值
该变量没有包含在具有其他变量的不变式中
所以此时的volatile变量不能用作线程安全计数器,如果单个线程写入不影响
volatile变量不能用于约束条件中,他包含一个不变式---下届总是小于或等于上届
@NotThreadSafe
public class NumberRange {
private int lower, upper;
public int getLower() { return lower; }
public int getUpper() { return upper; }
public void setLower(int value) {
if (value > upper)
throw new IllegalArgumentException(...);
lower = value;
}
public void setUpper(int value) {
if (value < lower)
throw new IllegalArgumentException(...);
upper = value;
}
}将 lower 和 upper 字段定义为 volatile 类型不能够充分实现类的线程安全;而仍然需要使用同步——使 setLower() 和 setUpper() 操作原子化。
可能会导致此条件的破坏
适用场景:可以用于状态标志,适用只读操作
@ThreadSafe
public class CheesyCounter {
// Employs the cheap read-write lock trick
// All mutative operations MUST be done with the 'this' lock held
@GuardedBy("this") private volatile int value;
//读操作,没有synchronized,提高性能
public int getValue() {
return value;
}
//写操作,必须synchronized。因为x++不是原子操作
public synchronized int increment() {
return value++;
3.线程安全的单例模式
public class Singleton{
private volatile static Singleton instance;
private Singleton(){}
public Singleton getInstance(){
if(instance == null){
synchronized(Singleton.class){
if(instance == null){
instance = new Singleton();
}
}
}
return instance;
}
}4.饿汉式和懒汉式的区别,及其适用场景
饿汉式:
在类加载的时候就完成实例化,没有达到懒加载的效果,如果从始至终从未使用的实例,会造成内存的浪费
public class Singleton{
private static Singleton instance = new Singleton();
private Singleton(){}
public static Singleton getInstance(){
return instance;
}
}饿汉式的效率快
懒汉式的速度慢
5.CAS无锁机制
内存位置V表示,旧的预期值A,新值B,当且仅且内存位置V符合旧的预期值A值时,才用新值B去替换A
可以实现无锁化,但是会出现ABA问题,需要加版本A1BA2;
6.Synchcronized和ReentrantLock区别
Synchronized:
在java中最基本的就是互斥手段就是synchronized关键字,synchronized所修饰的同步块
每个对象都有一个监视器锁(monitor),当monitor被占用时,此时该对象就处于被锁状态。
在synchronized锁所修饰的同步块中前后会形成两个字节码指令,一个monitorenter,一个monitoexit
当线程执行monitorenter时,会判断当前对象的锁计数器是不是0,如果是0时执行该同步区域
,此时锁计数器+1,当执行完成时,当执行monitorexit指令时会锁计数会-1,如果一个对象的锁
计数器为0,就表示该对象是可以执行的
synchronized,锁实例方法时就表示锁住其实是当前的this对象,当锁静态方式时,其实锁住的
当前类的一个class对象。
synchronized对同一条线程来说是可重入的。
可重入:表示当前线程在执行方法是如果中断去执行另一个方法,回来时当前数据不会受到影响
相当于递归调用
ReentrantLock:
默认是非公平的,但是可以设置其要求使用的公平锁
相比于Synchronized,等待可中断,可以实现公平锁,ReentrantLock可以同时绑定多个Condition对象
ReentrantLock底层是AQS:
底层维持了一个双端队列
https://blog.youkuaiyun.com/yanyan19880509/article/details/52345422/
Synchronized相比ReentrantLock的优点:
https://blog.youkuaiyun.com/m0_37897828/rss/list
不需要手动的释放锁,使用起来不如Sychronized方便
在资源竞争不是很激烈的情况下,使用synchronized 的性能更好,但是在资源竞争激烈的情况下,synchronized 的性能会大幅度下降,而ReentreantLock 的性能维持常态。
7.JUC,AQS
AQS架构图:
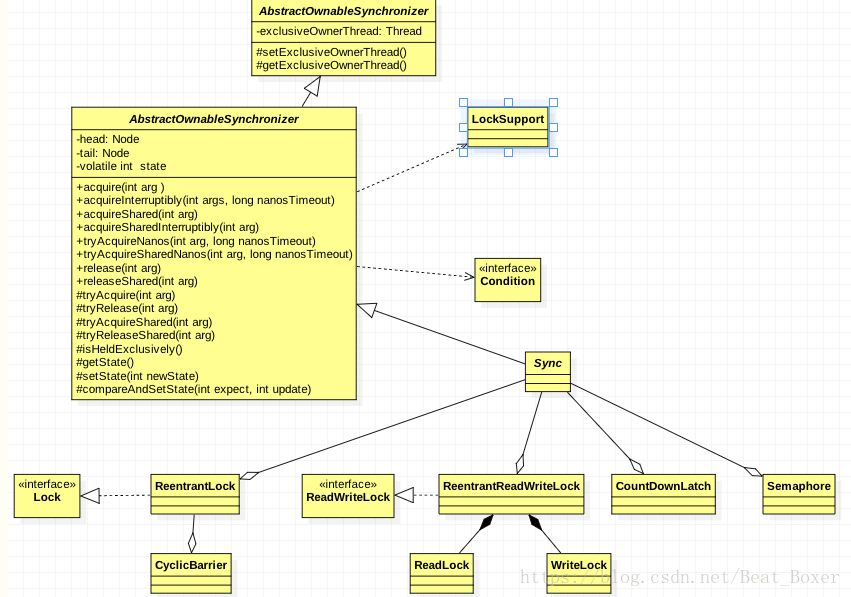
AQS定义两种资源共享方式:Exclusive(独占,只有一个线程能执行,如ReentrantLock)和Share(共享,多个线程可同时执行,如Semaphore/CountDownLatch)。
AQS:公平锁,就是维持一个双端队列,先进先出,可以重入,state会一直增加
非公平的话,A线程访问完成需要切换时B,此时又可能让C线程抢导资源。
同步器内部依赖一个FIFO的双向队列来完成资源获取线程的排队工作。
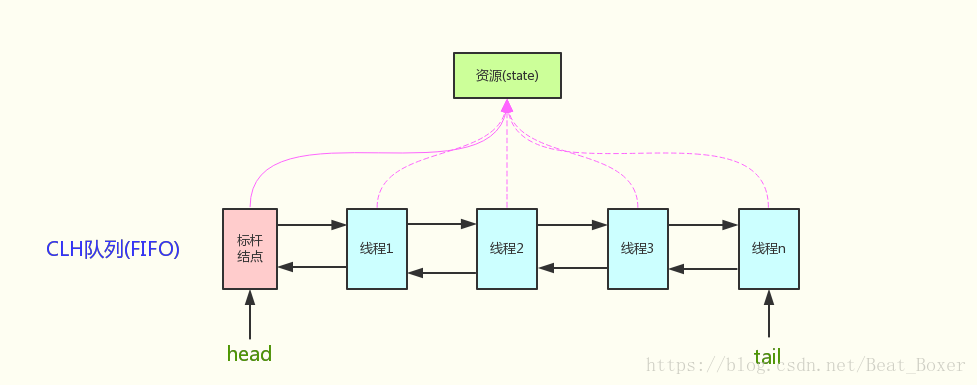
独占锁式的流程图
Condition:
在synchronized锁的东西中通信可以使用Object类中的wait notify notifyAll
而在lock所中,需要Lock对象所以此时会用condition对象
Lock lock = new ReentrantLock();
Condition condition = lock.newCondition();
condition.await(); condition.signal(); condition.signalAll();
CountDownLatch 栅栏:可以让多个线程到达之后,将其释放,所有的线程可以去访问 信号量:可以让多个线程去访问同一个变量
一个线程的运行需要等待其他多个线程完成时,当前线程才会继续执行。
在完成一组操作某些的运算时,只有其他线程运行完成,当前线程才可以执行。
CountDownLatch latch = new CountDownLatch(5);
和线程个数要相同,计算问题,减不到零就需要等待
主线程就需要等待 await();
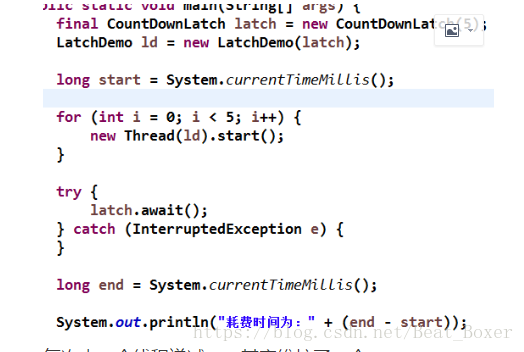
每次来一个线程递减一,其实维护了一个,countdown()
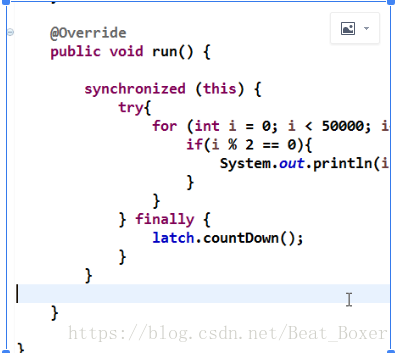
Semaphore:
Semaphore是信号量,用于管理一组资源。其内部是基于AQS的共享模式,AQS的状态表示许可证的数量,在许可证数量不够时,线程将会被挂起;而一旦有一个线程释放一个资源,那么就有可能重新唤醒等待队列中的线程继续执行。
创建了5个跑道对象,并使用一个boolean类型的数组记录每个跑道是否被使用了,初始化了5个许可证的Semaphore,在获取跑道时首先调用acquire(1)获取一个许可证,在归还一个跑道是调用release(1)释放一个许可证。接下来再看启动程序
https://blog.youkuaiyun.com/qq_19431333/article/details/70212663
https://mp.weixin.qq.com/s/gWecABdonaYah4nHr9hDfg
CyclicBarrier:
一个同步辅助类,它允许一组线程互相等待,直到到达某个公共屏障点 (common barrier point)。在涉及一组固定大小的线程的程序中,这些线程必须不时地互相等待,此时 CyclicBarrier 很有用。因为该 barrier 在释放等待线程后可以重用,所以称它为循环 的 barrier。
8.nginx采用的负载均衡模式
1)、轮询 ——1:1 轮流处理请求(默认)
每个请求按时间顺序逐一分配到不同的应用服务器,如果应用服务器down掉,自动剔除,剩下的继续轮询。
2)、权重 ——you can you up,配置权重
通过配置权重,指定轮询几率,权重和访问比率成正比,用于应用服务器性能不均的情况。
3)、ip_哈希算法
每个请求按访问ip的hash结果分配,这样每个访客固定访问一个应用服务器,可以解决session共享的问题。
upstream tomcatserver1 {
server 192.168.72.49:8080 weight=3;
server 192.168.72.49:8081;
}
server {
listen 80;
server_name 8080.max.com;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
proxy_pass http://tomcatserver1;
index index.html index.htm;
}
}1、转发功能:按照一定的算法【权重、轮询】,将客户端请求转发到不同应用服务器上,减轻单个服务器压力,提高系统并发量。
2、故障移除:通过心跳检测的方式,判断应用服务器当前是否可以正常工作,如果服务器期宕掉,自动将请求发送到其他应用服务器。
3、恢复添加:如检测到发生故障的应用服务器恢复工作,自动将其添加到处理用户请求队伍中。
9 、mysql复制原理
1、主库将所有的数据操作记录在二进制日志文件中(Binary log)
2、备库启动一个IO线程,将主库的二进制文件转储(binlog dump)到自己的中继日志中(Relay log)
3、备库读取中继文件中的操作,执行结果放到备份服务器上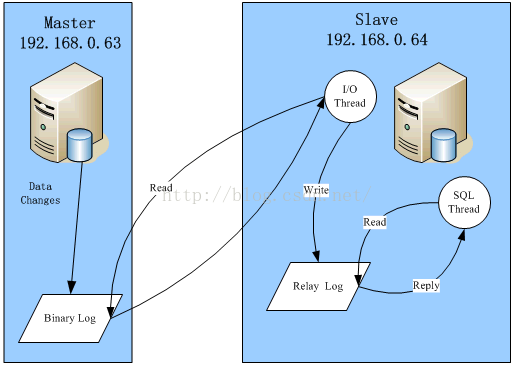
注意:
1、数据一致性延迟问题:
在同一时间,数据的一致性会有延迟,这取决于二进制文件的大小,一些大的语句可能会导致备库产生几秒、几分钟甚至几小时的延迟。
2、mysql复制的版本问题:
由于老版本可能无法解析新版本产生的二进制文件中采用的新特性或语法,所以一般使用同一版本做复制或老版本作为主库,新版本做备库。
10.API网关的优缺点
Kong
Netty+java
zuul + springcloud
11.Redis的数据类型及分布式锁,RDB,AOF,主从复用,Redis滑动窗口
redis数据类型及基本操作:
5种基础数据结构: string list set hash zset
String类似于java中的ArrayList,采用预分配冗余空间的方式来减少内存的频繁分配,如果长度小于1M时,都是对现有的空间加倍,如果超过1M时,只允许其扩1M的空间,最大为512M
string基本操作命令:set get exists del mget (获取多个) mset(设置多个) expire(设置过期时间) setex name 5 haha(等价于set + expire) setnx(如果不存在就创建,存在就不创建) incr (加1) incrbyage age 5(加特定值)
list(列表) 类似于java中的LinkedList,是一个链表结构 ,插入删除比较快,时间复杂度为o(1),但是索引的定位比较慢,时间复杂度为O(n)
list的基本操作指令:
右边进左边出(队列) rpush key v1 v2(右进) llen key (长度) lpop key (左边出)
右边进右边出(栈) rpush key v1 v2(右进) rpop(右出)
lindex key 1(获取key1号位的值) lrange key 0 -1(获取所有元素) llen(获取长度)
其实他不是一个简单的linkedlist,而是称为一个快速链表quicklist的一个结构,首先在元素量少的情况下会使用一块连续的内存存储,这个结构是ziplist,也即是压缩列表,他将元素紧挨着存储;当数据量比较多的时候才会换成quicklist,因为普通链表需要的附加指针空间太大,会比较浪费空间,平切加重碎片化,而list底层就是将多个ziplist通过prev和next。其实是将链表和ziplist结合起来组成了quicklist,这样既满足了快速的插入删除性能,有不会出现太大的空间冗余。
hash(字典)
hash相当于java中的hashmap,数组+链表二维结构。hashmap在字典很大时,rehash是个耗时的操作,需要一次性全部rehash,而redis是采用渐进式rehash策略。相当于CopyOnWriteArrayList是一个原理,old和new
基本指令:
hset key v1 v2 (设置) hgetall key(值) hlen key(长度) hmset(设置多个) hincrby user age 5(增加)
set(集合)
相当于java中的HashSet,不能重复
sadd books python sadd books java php smember books(无序不重复) sismember scard(取长度) spop(弹出一个)
zset(有序列表)
类似于Java中的hashmap和sortedSet
zadd books 9.0 "think in java" zadd books 8.9 "juc" zrange books 0 -1 zcard books zscore books "juc"
zrem books "juc" 删除 其实是用跳表实现的
之前的限流使用的是string
redis滑动窗口的简单限流:(zset)
public boolean xianliu(string key,string do,int period,int maxcount){
String key = key.do;
long nowTs = System.currentTimeMills();
Pipeline pipe = jedis.pipelined();
pipe.multi();
pipe.zadd(key,nowTs," "+nowTs);
pipe.zremRangeByScore(key,0,nowTs-period*1000);
count = pipe.zcard(key);
pipe.expire(key,period+1);
pipe.exec();
pipe.close();
}
CAP:一致性 可用性 分区容错性
redis的主从复制:
- Redis 使用异步复制。 从 Redis 2.8 开始, 从服务器会以每秒一次的频率向主服务器报告复制流(replication stream)的处理进度。
- 一个主服务器可以有多个从服务器。
- 不仅主服务器可以有从服务器, 从服务器也可以有自己的从服务器, 多个从服务器之间可以构成一个图状结构。
- 复制功能不会阻塞主服务器: 即使有一个或多个从服务器正在进行初次同步, 主服务器也可以继续处理命令请求。
- 复制功能也不会阻塞从服务器: 只要在 redis.conf 文件中进行了相应的设置, 即使从服务器正在进行初次同步, 服务器也可以使用旧版本的数据集来处理命令查询。
RDB和AOF
redis的RDB,将内存数据快照写入到磁盘(备份) (读取) 从快照文件读取到内存,可以快速恢复,效率较快
缺点 :保存RDB文件时,需要fork一个子进程俩处理,而父进程不需要关心,所以比较耗时,不能保证租后一次的数据
优点:RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快
使用 AOF 持久化会让 Redis 变得非常耐久(much more durable):你可以设置不同的 fsync 策略,比如无 fsync ,每秒钟一次 fsync ,或者每次执行写入命令时 fsync 。 AOF 的默认策略为每秒钟 fsync 一次,在这种配置下,Redis 仍然可以保持良好的性能,并且就算发生故障停机,也最多只会丢失一秒钟的数据
缺点:相同数据的aof文件占用的内存较多,且回复慢
12.一致性hash的优化场景(数据库满了怎么办或者服务器宕机了如何做到数据同步)
https://www.youkuaiyun.com/article/2014-03-25/2818965
10.ArrayList和LinkedList的区别
11.hashset和hashmap的区别
HashMap的key就是放进HashSet中对象,value是Object类型的。
当调用HashSet的add方法时,实际上是向HashMap中增加了一行(key-value对),该行的key就是向HashSet增加的那个对象,该行的value就是一个Object类型的常量
11.remove方法,和fail-fast的机制
12.为什么要使用迭代器
13.ConCurrentHashMap和CopyOnWriteArrayList
14.数组为什么比链表快
寻址操作次数链表要多一些。数组只需对 [基地址+元素大小*k] 就能找到第k个元素的地址,对其取地址就能获得该元素。链表要获得第k个元素,首先要在其第k-1个元素寻找到其next指针偏移,再将next指针作为地址获得值,这样就要从第一个元素找起,多了多步寻址操作,当数据量大且其它操作较少时,这就有差距了。
12.一致性hash的优化场景(数据库满了怎么办或者服务器宕机了如何做到数据同步)
https://www.youkuaiyun.com/article/2014-03-25/2818965
5.redis的总结及其常用指令,滑动窗口的实现
6.
线程池:
8大排序:
spring三大框架

















 1856
1856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









