




索引字段设置 "index": false 的作用
在上一篇博客《【Elasticsearch】动手创建一个索引》中,我们了解到可以通过设置 "index": false,让索引字段禁止被搜索。
有小伙伴可能会有疑问,下面的搜索语句,返回的结果中仍然包含 request_body 字段啊,这是怎么一回事?
GET /test-index/_search
{
"size": 5,
"sort": [
{
"timestamp": {
"order": "desc"
}
}
]
}
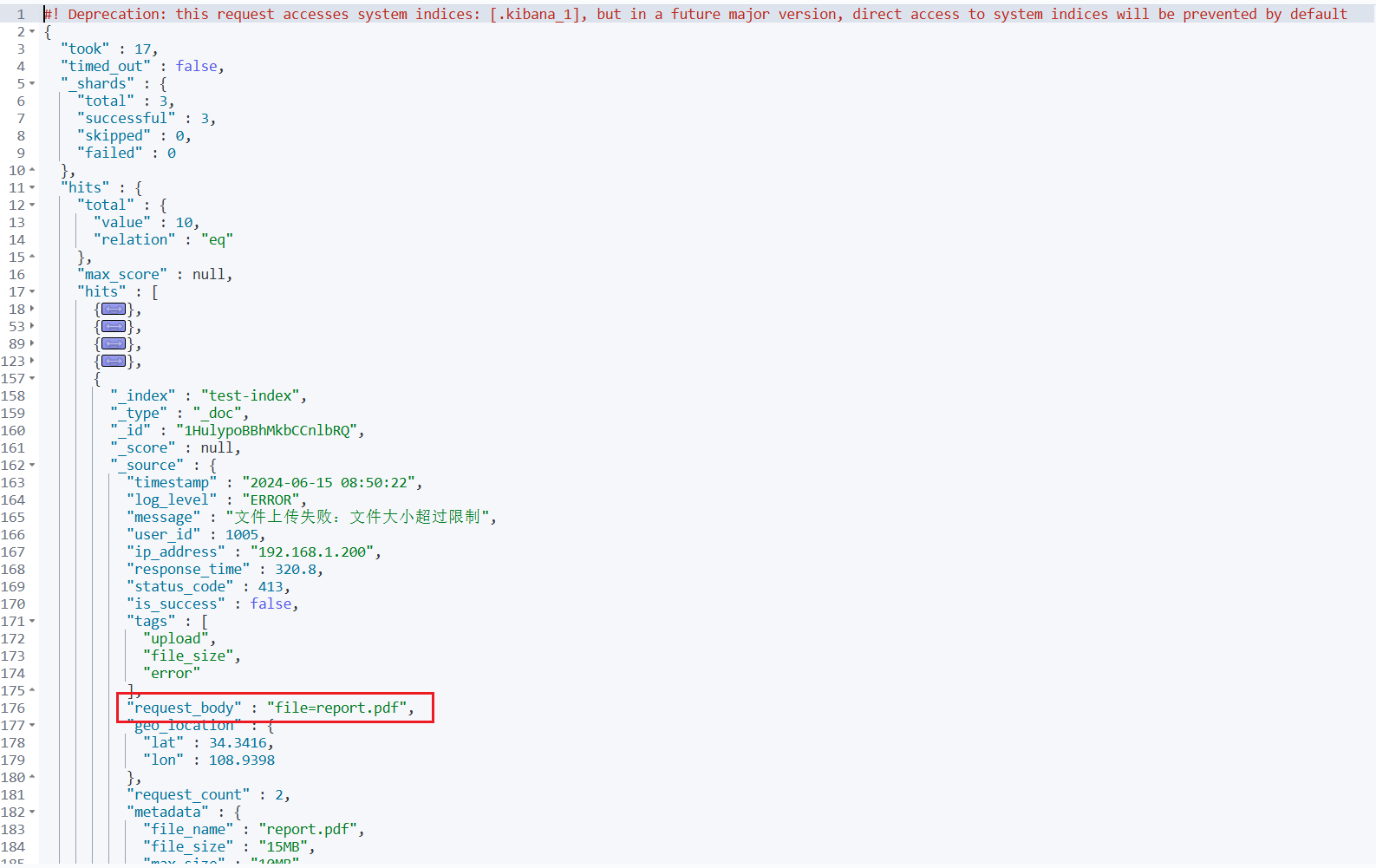
这是一个很好的问题!原因在于:"index": false 只是禁止了字段被搜索,但并没有禁止字段被返回。
1.核心概念澄清
"index": false 的作用:
- ❌ 不能 被搜索(
search) - ❌ 不能 被聚合(
aggregate) - ✅ 可以 在搜索结果中返回(
return in results) - ✅ 可以 通过
_source获取
1.1 验证搜索限制
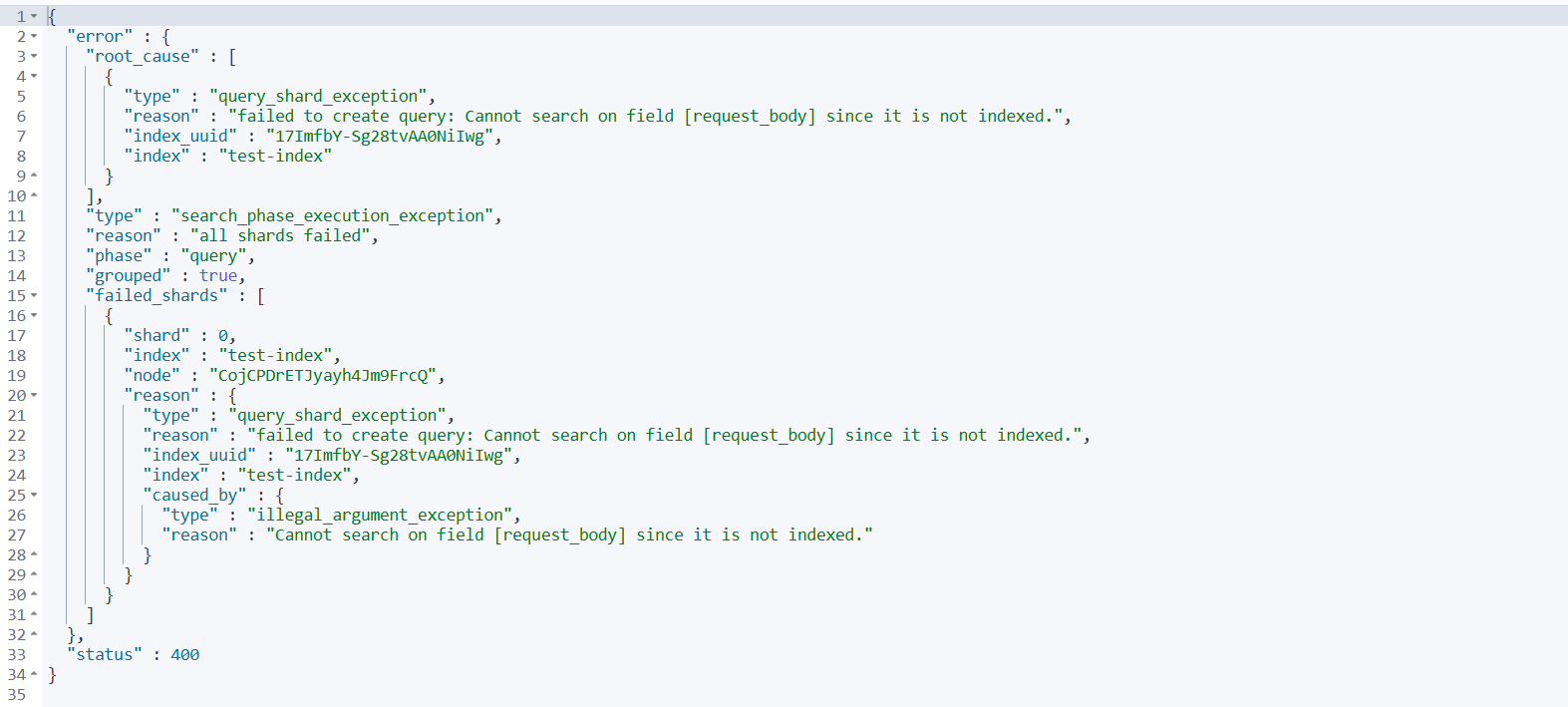
您可以试试这个查询,会发现 request_body 字段确实无法被搜索:
GET /test-index/_search
{
"query": {
"match": {
"request_body": "SELECT" // ← 这会返回空结果,因为该字段不可搜索
}
}
}
1.2 如何控制返回字段
如果希望在搜索结果中 不返回 request_body 字段,有几种方法:
1.2.1 方法 1:使用 _source 排除字段
GET /test-index/_search
{
"_source": {
"excludes": ["request_body"]
},
"size": 5,
"sort": [
{
"timestamp": {
"order": "desc"
}
}
]
}

1.2.2 方法 2:使用 _source 明确指定需要的字段
GET /test-index/_search
{
"_source": ["timestamp", "log_level", "message", "user_id", "ip_address"],
"size": 5,
"sort": [
{
"timestamp": {
"order": "desc"
}
}
]
}
1.2.3 方法 3:完全禁用 _source(不推荐)
PUT /test-index
{
"mappings": {
"_source": {
"enabled": false // ← 这样就不会存储原始文档
},
"properties": {
// ... 其他字段配置
}
}
}
1.3 实际场景举例
1.3.1 场景 A:日志存储但敏感信息不搜索
{
"password": {
"type": "text",
"index": false // 不能被搜索,但事故调查时能查看原始日志
}
}
1.3.2 场景 B:大字段不返回以减少网络传输
{
"full_html_content": {
"type": "text",
"index": true // 可以被搜索
}
}
// 查询时只返回摘要,不返回完整内容
GET /articles/_search
{
"_source": ["title", "summary", "author"],
"query": {
"match": {
"full_html_content": "关键技术" // 仍然可以搜索大字段
}
}
}
1.4 总结
| 控制类型 | 配置方法 | 作用 |
|---|---|---|
| 是否可搜索 | "index": true/false | 控制字段是否能被查询 |
| 是否可返回 | _source.includes/excludes | 控制字段是否在结果中显示 |
| 是否存储原始值 | "_source": {"enabled": false} | 控制是否存储原始文档 |
在上述情况中:
request_body字段:✅ 可返回,❌ 不可搜索- 这是完全正常且符合设计的行为
如果确实不希望 request_body 在搜索结果中显示,使用 _source 排除即可。
2.“不能被搜索” 和 “可以在搜索结果中返回” 有什么不一样
🎯 2.1 核心比喻
把 Elasticsearch 想象成一个 图书馆:
- 图书内容 = 文档的原始数据(
_source) - 索引卡片 = 倒排索引(
index: true) - 查询请求 = 您向管理员询问
📚 2.2 具体场景
场景1:“index”: false 但可以返回
{
"request_body": {
"type": "text",
"index": false // 这本书没有做索引卡片
}
}
在图书馆中的表现:
-
❌ 管理员无法通过卡片找到这本书
// 这个搜索会返回空结果 GET /test-index/_search { "query": { "match": { "request_body": "SELECT" // ← 管理员:我找不到包含"SELECT"的书 } } } -
✅ 但如果您知道书的位置,可以直接拿到书
// 这个查询能返回所有文档,包括request_body字段 GET /test-index/_search { "query": { "match_all": {} // ← 管理员:给您所有书(不涉及搜索) } }
场景2:“index”: true 且可以返回
{
"message": {
"type": "text",
"index": true // 这本书有完整的索引卡片
}
}
在图书馆中的表现:
-
✅ 管理员可以通过卡片找到这本书
// 这个搜索能成功找到结果 GET /test-index/_search { "query": { "match": { "message": "错误" // ← 管理员:我找到了3本提到"错误"的书 } } } -
✅ 找到后把书给您
// 返回结果中包含message字段 { "hits": { "hits": [ { "_source": { "message": "数据库连接错误", // ← 这就是书的内容 "timestamp": "..." } } ] } }
🔍 2.3 实际查询演示
查询 1:搜索 request_body(会失败)
GET /test-index/_search
{
"query": {
"match": {
"request_body": "SELECT" // ← 搜索条件
}
}
}
结果:返回空,因为 request_body 没有倒排索引,无法被搜索。
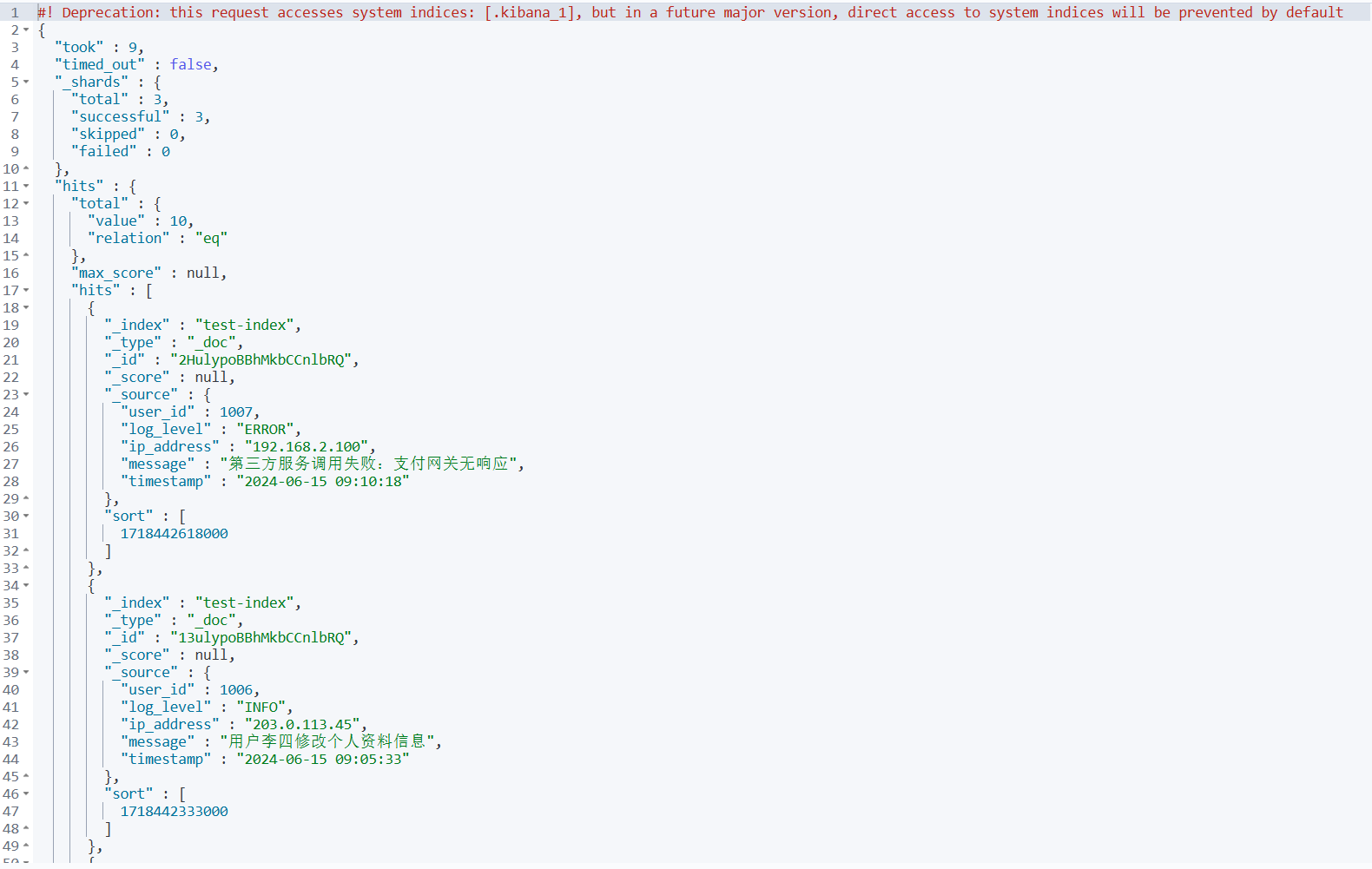
查询 2:获取所有文档(会成功)
GET /test-index/_search
{
"query": {
"match_all": {} // ← 没有搜索条件,只是获取所有文档
}
}
结果:返回所有文档,包括 request_body 字段,因为只是读取存储的原始数据。
💡 2.4 实际应用场景
场景 A:密码字段
{
"password": {
"type": "keyword",
"index": false // 不能被搜索,但登录验证时需要读取
}
}
- ❌ 不能搜索:
WHERE password = '123456' - ✅ 可以读取:用户登录时验证密码
场景 B:原始请求数据
{
"raw_request": {
"type": "text",
"index": false // 数据太大,不建索引,但调试时需要查看
}
}
- ❌ 不能搜索:
WHERE raw_request LIKE '%error%' - ✅ 可以读取:排查问题时查看完整请求
场景 C:计算字段
{
"score": {
"type": "float",
"index": false // 由其他字段计算得出,不需要直接搜索
}
}
- ❌ 不能搜索:
WHERE score > 0.8 - ✅ 可以读取:排序或展示时使用
🎓 2.5 总结
| 操作 | 依赖 index: true | 依赖 _source |
|---|---|---|
搜索"query": {"match": {"field": "value"}} | ✅ 必需 | ❌ 不需要 |
| 返回字段值 在搜索结果中看到字段内容 | ❌ 不需要 | ✅ 必需 |
简单记忆:
- “不能被搜索” = 图书馆里没有这本书的索引卡片
- “可以在搜索结果中返回” = 如果您通过其他方式找到这本书,仍然可以阅读它的内容
现在你应该明白这个重要的区别了!


















 979
979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











