




 本文介绍了一位爬虫初学者如何使用Python和XPath解析网页,爬取动漫图片的过程。通过分析网页结构,利用XPath定位图片链接,解决图片URL的动态变化问题,并通过错误处理确保程序稳定运行。
本文介绍了一位爬虫初学者如何使用Python和XPath解析网页,爬取动漫图片的过程。通过分析网页结构,利用XPath定位图片链接,解决图片URL的动态变化问题,并通过错误处理确保程序稳定运行。
开始
大家好鸭,又是新的一天!
无论做什么事情,都要恪守初心,要知道我们是为了什么才学爬虫的,比如我,就是为了爬取一些好看的图片……
所以,今天带大家一起爬一些好看的,图片~
话不多说,直接高速!
http://www.win4000.com/zt/dongman.html
作为一个老二刺猿,当然是直接找动漫图片~
分析
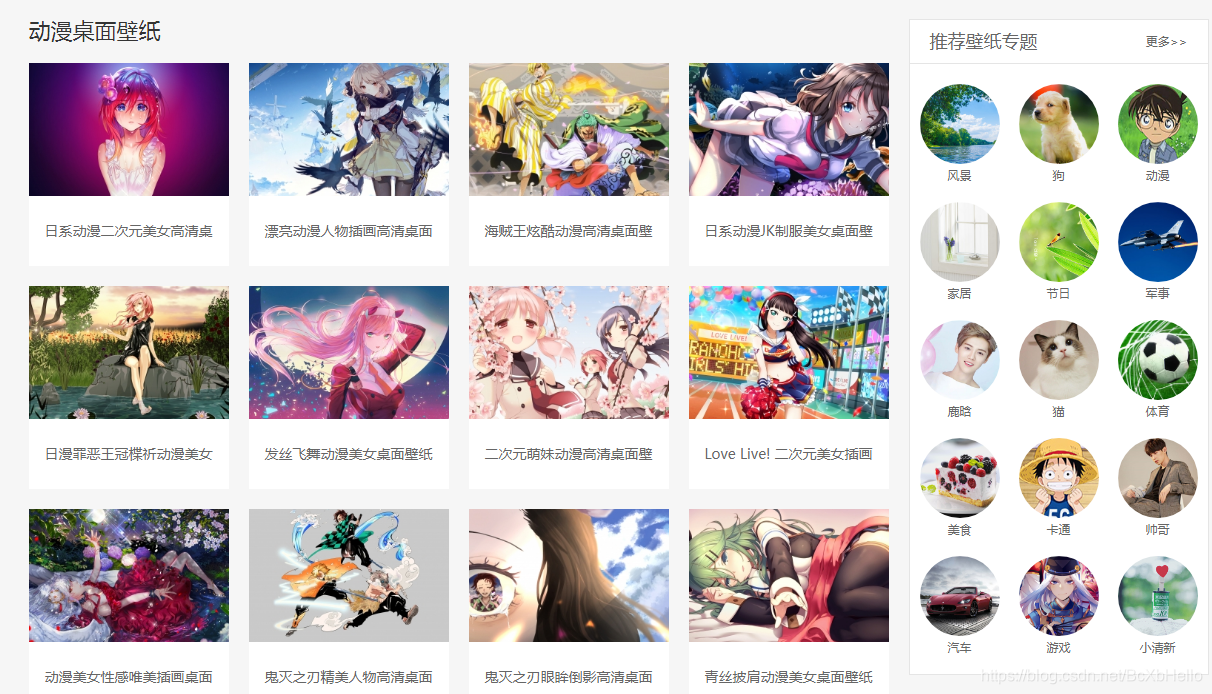
打开页面后往下拉,发现图片是真滴好看……
里面还有我的02老婆~
认真分析,看到这一张张的图片,我们是不是可以认为这些图片是放在一个列表里的,所以一会我们爬取这个列表,然后把每一张图片遍历出来就可以了,对吧!(遍历大意:用循环把列表中每一个元素列出来)
好,打开我们的抓包工具!(审查元素 或 检查)
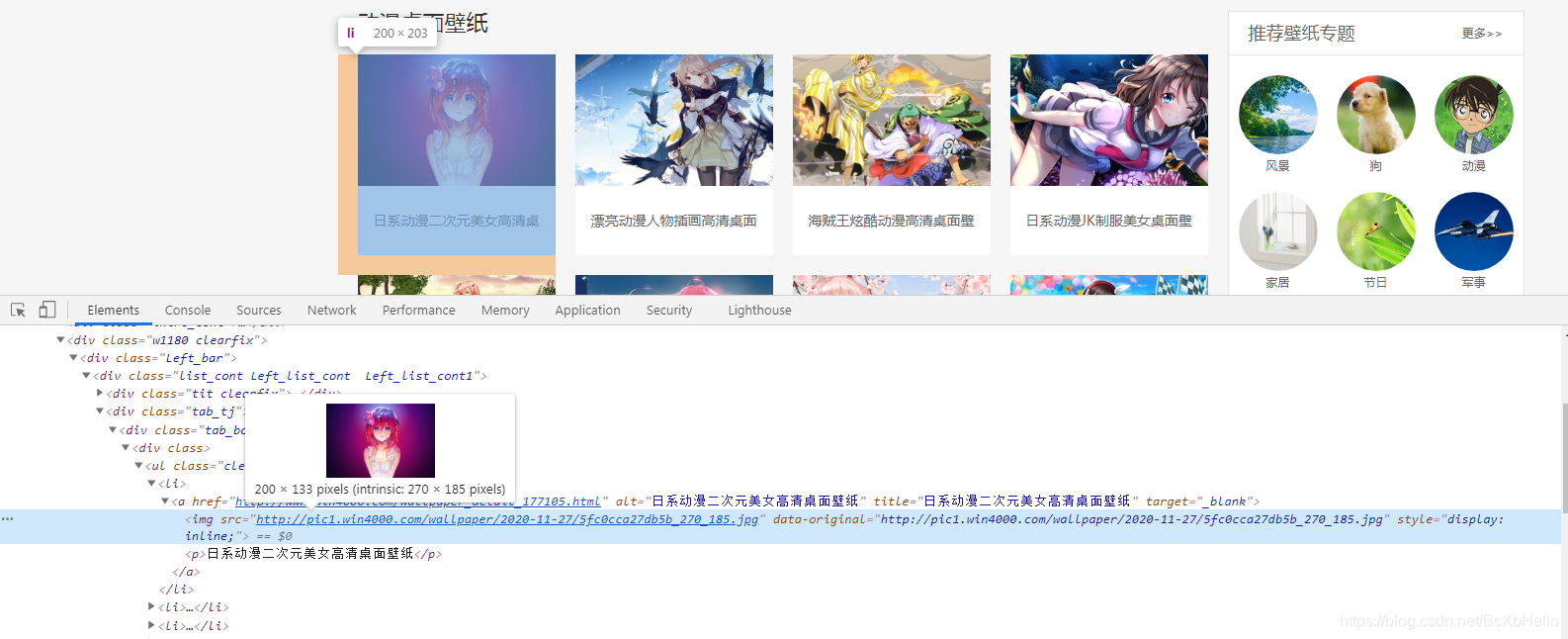
找到图片所对应的位置,发现直接就有图片了,那我们直接爬取整个页面,再把爬取到的数据筛选一下,只要图片的网址然后再单独下载不就好啦~
这个想法是对的,但是打开那个网址会发现……

我们上当了!
这只是一个缩略图,那么真正的图片在哪里呢?学过html的同学应该能直接找到,没学过的呢,就跟着小泽一起往下走。
我们点开某一张图片,会发现跳到了另一个页面。
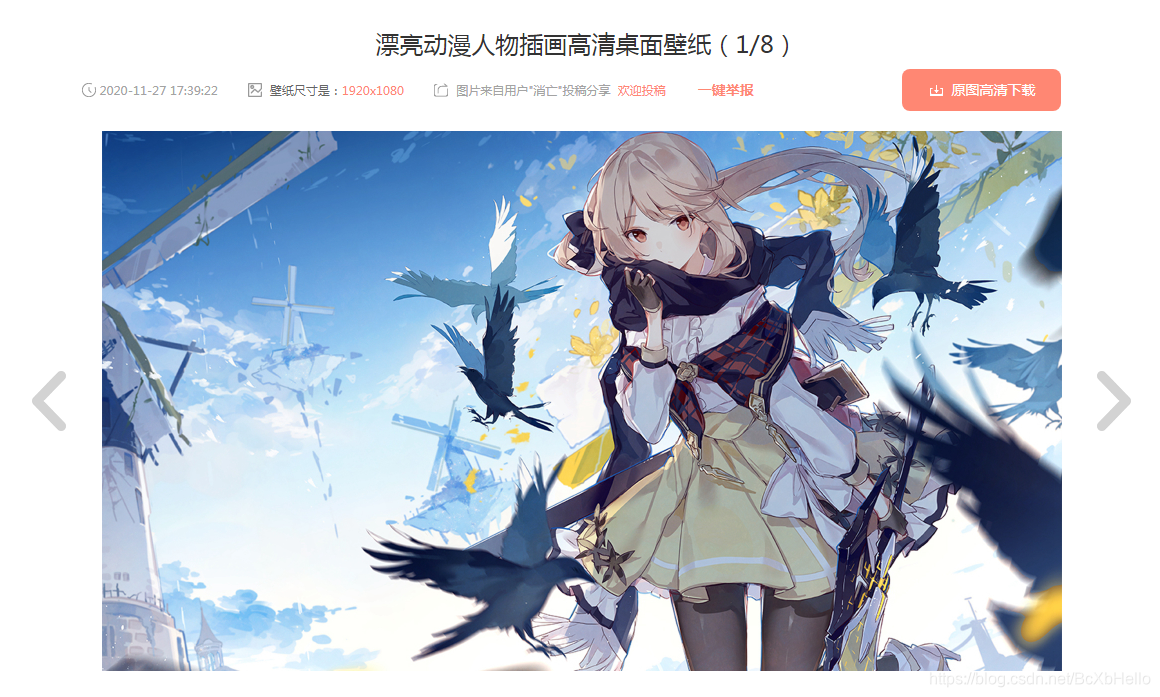
在新的页面,我们会发现有个下载按钮,还有个左右切换的按钮。
先点击一下下载按钮试试……
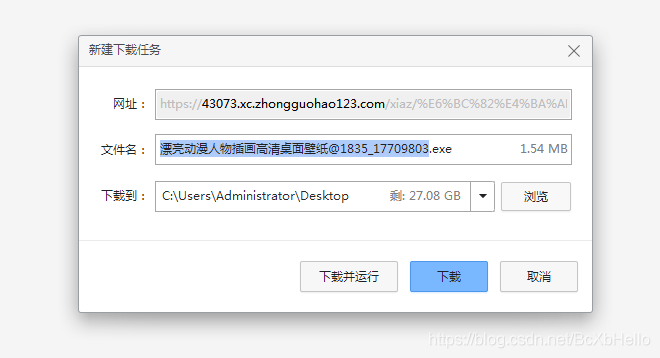
好家伙,直接好家伙。
一看后缀名就知道,我们又上当了!
这个按钮或许会给你一种错觉,跟昨天的翻译按钮一样,会不会返回一个图片,我们只要接收了再保存就好了。
这个想法是没错的,但是奈何这个网站太狡猾,实在是狡猾!
这个时候打开抓包工具看一下我们要的东西还有没有。
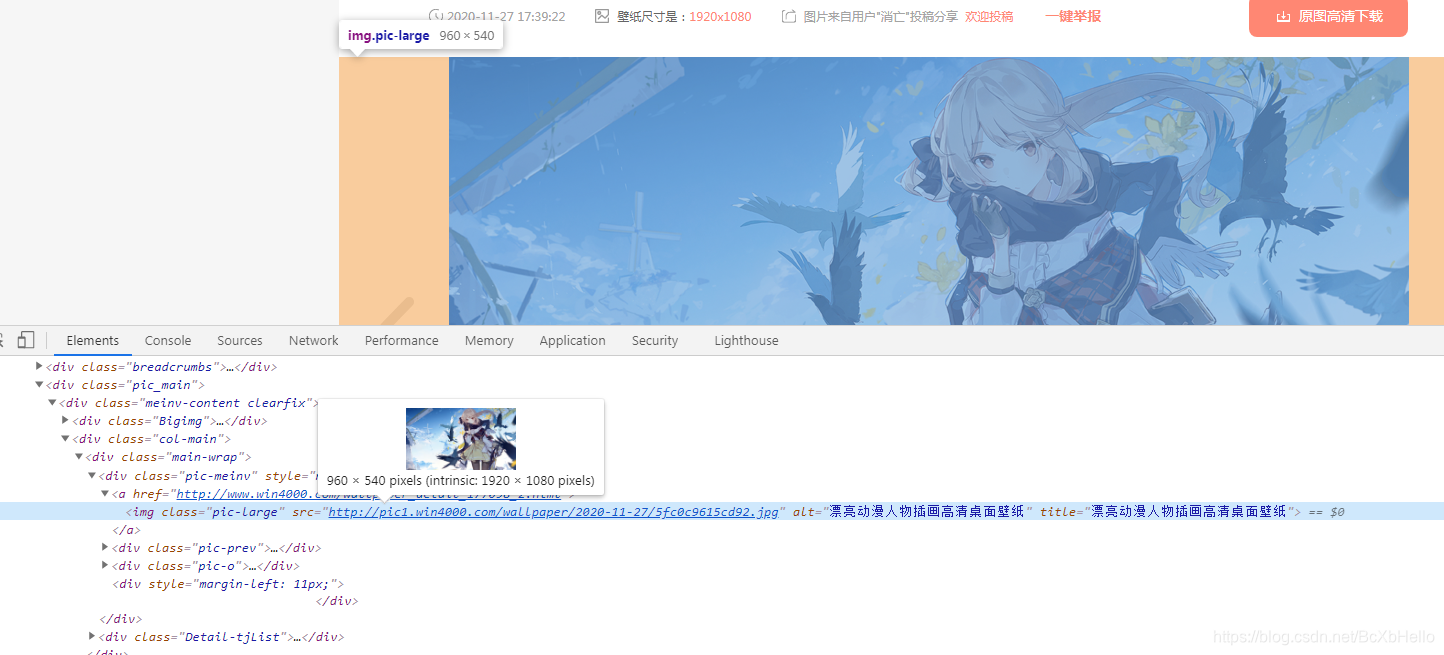
找到你啦,色图 美图!
我们再打开这个链接,看一下是不是真正的大图。

可以了可以了,够大了!
那么我们现在就是找到了真正存放图片的地址,但是还有一个地方不能忽略,来回切换的那个按钮,到底有什么用?
我们点一下,注意观察网址的变化!




发现规律了没,网址每一次都会在177098_后面加1,那么177098_1是不是就是第一张图片呢?大家可以试一下。
试完你就会发现还真的是诶,好神奇!
但是还有个问题,这一组图片是8张,也就是177098_1到177098_8,那么其他的图组是不是呢(一开始还以为是一张一张图片,上当啦,hh)

好的,果然让我们发现一个,那就是说每组图组里面图片的数量是不固定的,只爬第一张怎么会满足呢!
这样想,如果我们上面那个图组出现177098_9会怎么样?
程序不出意外应该会报错,那我们只要建立一个死循环,在报错的时候就终止循环,就可以不用管它有多少张,我全都要的下载下来啦!
思路很明确,但是实现起来…
嗨,先硬着头皮上吧,啃!
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7619
7619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









