



与传统机器学习不同,深度学习既提供特征提取功能,也可以完成分类的功能。这一TASK主要演示了如何利用深度学习来完成文本表示。
本章主要使用FastText来完成深度学习词向量的表示。FastText通过Embedding层将单词映射到稠密空间,然后将句子中的所有单词在Embedding层空间进行平均,进而完成分类工作。所以FastText层是一个三层的神经网络:输入层、隐含层和输出层。
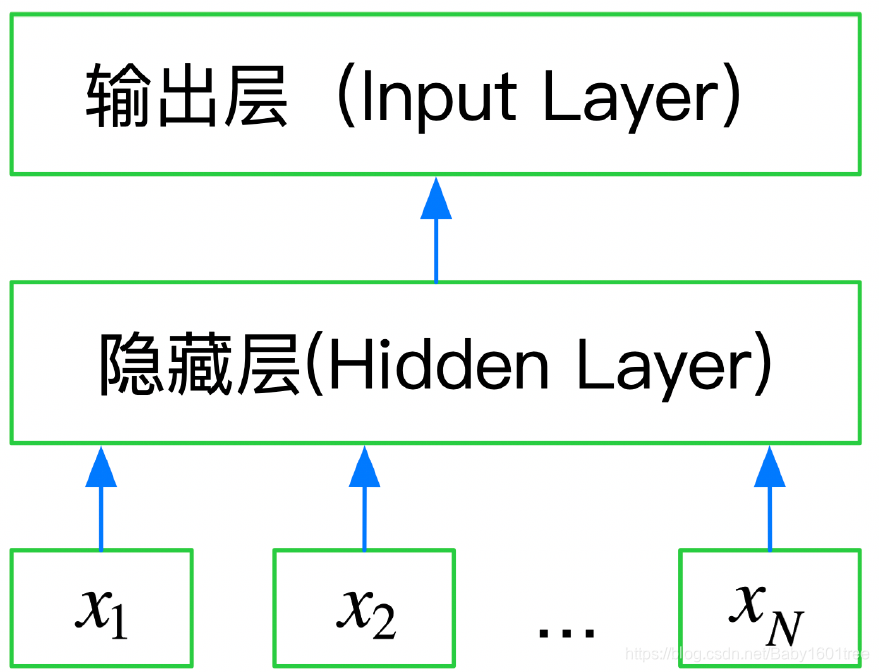
下图是使用Keras实现的FastText网络结构
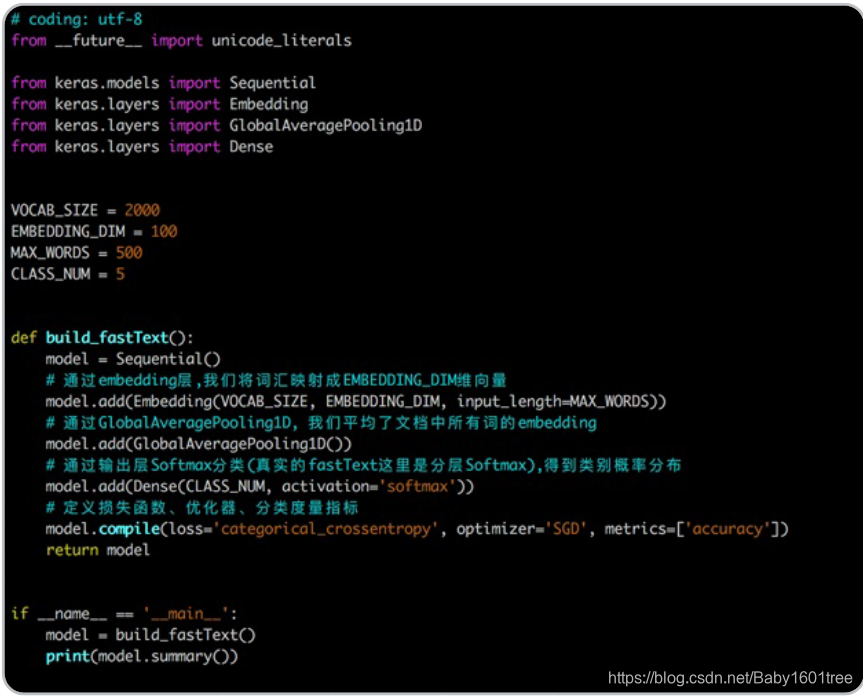
以下是通过FastText完成词文本分类的代码和释义,通过代码复现来完成FastText的学习
导入第三方模块
import pandas as pd
from sklearn.metrics import f1_score
from sklearn.model_selection import StratifiedKFold # 这可以保证每一折分布一致
import fasttext
这里使用‘pip install fasttext’报错
解决方案是先下载了fasttext的第三方安装包,然后指定本地路径安装的
网址导航:https://www.lfd.uci.edu/~gohlke/pythonlibs/#fasttext
安装命令:pip install fasttext-0.9.2-cp38-cp38-win_amd64.whl(需要把安装文件放到当前环境的路径下)
分类模型
为了减小机器的压力,还是导入15000条训练样本数据
train_df = pd.read_csv(r'D:\Users\Felixteng\Documents\Pycharm Files\Nlp\data\train_set.csv',
sep='\t', nrows=15000)
转换为FastText需要的格式,默认情况下,我们假设标签是以字符串__label__为前缀的词
train_df['label_ft'] = '__label__' + train_df['label'].astype(str)
取前10000个训练样本的text和新label,创建一个适合FastText格式的新训练集
train_df[['text', 'label_ft']].iloc[:-5000].to_csv('train.csv', index=None, header=None, sep='\t')
训练数据,学习率设为1,n-gram个数为2,为每个epoch输出一行记录,词频阈值为1,次数为25,损失函数选择分层softmax
model = fasttext.train_supervised('train.csv', lr=1.0, wordNgrams=2, verbose=2,
minCount=1, epoch=25, loss='hs')
'''
fasttext.train_supervised() - 训练一个监督模型,返回一个模型对象
参数详解:
input - 训练数据文件路径
lr - 学习率
dim - 向量维度
ws - cbow模型时使用
epoch - 次数
minCount - 词频阈值,小于该值在初始化时会被过滤
minCountLabel - 类别阈值,类别小于改值初始化时会被过滤
minn - 构造subword时最小char个数
maxn - 构造subword时最大char个数
neg - 负采样
wordNgrams - n-gram个数,组成词语的长度
loss - 损失函数类型,softmax, ns:负采样, hs:分层softmax
bucket - 词扩充大小,[A, B]:A语料中包含的词向量,B不在语料中的词向量
thread - 线程个数,每个线程处理输入数据的一段,0号线程负责loss输出
lrUpdateRate - 学习率更新
t - 负采样阈值
label - 类别前缀
pretrainedVectors - 预训练的词向量文件路径,如果word出现在文件夹中初始化不再随机
verbose - 日志显示
verbose = 0 为不在标准输出流输出日志信息
verbose = 1 为输出进度条记录
verbose = 2 为每个epoch输出一行记录
'''
预测验证集数据并计算精度
val_pred_fasttext = [model.predict(x)[0][0].split('__')[-1] for x in train_df.iloc[-5000:]['text']]
'''
由于FastText单个预测值返回的是一个元组,元组包括标签列表和概率列表,如:
(('__label__4',), array([0.99362451]))
所以我们在提取预测类别值的时候提前加上切片操作,将词标签的值取出;
然后按照'__'对词标签进行分割,从而获取实际预测到的类别值
模型单例预测函数代码:
def model.predict(self, text, k=1, threshold=0.0):
"""
模型预测,给定文本预测分类
@param text: 字符串, 需要utf-8
@param k: 返回标签的个数
@param threshold 概率阈值, 大于该值才返回
@return 标签列表, 概率列表
"""
pass
'''
print(f1_score(train_df['label'].values[-5000:].astype(str), val_pred_fasttext, average='macro'))
f1_score为0.82左右。
尝试增加训练样本的数量以提升其精度
train_df_big = pd.read_csv(r'D:\Users\Felixteng\Documents\Pycharm Files\Nlp\data\train_set.csv',
sep='\t', nrows=75000)
train_df_big['label_ft'] = '__label__' + train_df_big['label'].astype(str)
train_df_big[['text', 'label_ft']].iloc[:50000].to_csv('train_big.csv', index=None, header=None, sep='\t')
model_big = fasttext.train_supervised('train_big.csv', lr=1.0, wordNgrams=2, verbose=2,
minCount=1, epoch=25, loss='hs')
val_pred_fasttext_big = [model_big.predict(x)[0][0].split('__')[-1] for x in train_df_big.iloc[-50000:]['text']]
print(f1_score(train_df_big['label'].values[-50000:].astype(str), val_pred_fasttext_big, average='macro'))
分数达到了0.944。
10折交叉验证
每折使用9/10的数据进行训练,1/10作为验证;
每折的划分必须保证标签的分布与整个数据集的分布一致;
尝试使用StratifiedKFold将训练集分为10折,且分别保存不同折作为验证集时的训练集和验证集
train_df = pd.read_csv(r'D:\Users\Felixteng\Documents\Pycharm Files\Nlp\data\train_set.csv', sep='\t')
skf = StratifiedKFold(n_splits=10) # 确保分出的折与原始集分布相同
for n_fold, (train_index, val_index) in enumerate(skf.split(train_df['text'], train_df['label'])):
# enumerate()函数用于将一个可遍历的数据对象组合为一个索引序列,同时列出数据和数据下标,一般用在for循环当中
print(f'the {n_fold} data split...')
train_X, train_y, val_X, val_y = train_df['text'].iloc[train_index], train_df['label'][train_index], \
train_df['text'].iloc[val_index], train_df['label'][val_index]
# 把标签转化成FastText能训练的形式
train_y = '__label__' + train_y.astype(str)
train_data = pd.DataFrame(list(zip(train_X.values, train_y.values)))
train_data.to_csv(f'data/fasttext_skf10_datasplit/train_split{n_fold}.csv',
index=None, header=['text', 'label_ft'], sep='\t')
test_data = pd.DataFrame(list(zip(val_X.values, val_y.values)))
test_data.to_csv(f'data/fasttext_skf10_datasplit/test_split{n_fold}.csv',
index=None, header=['text', 'label'], sep='\t')
利用10折交叉验证调参
print('starting K10 cross-validation training:')
# val_f1用于存放10次验证集的f1_score
val_f1 = []
for n_fold in range(10):
model = fasttext.train_supervised(f'data/fasttext_skf10_datasplit/train_split{n_fold}.csv',
lr=1.0, wordNgrams=2, verbose=2, minCount=1, epoch=25, loss='softmax')
val_df = pd.read_csv(f'data/fasttext_skf10_datasplit/test_split{n_fold}.csv', sep='\t')
val_pred = [model.predict(x)[0][0].split('__')[-1] for x in val_df['text']]
val_f1.append(f1_score(val_df['label'].values.astype(str), val_pred, average='macro'))
print(f'the f1_score of {n_fold}training is:', val_f1[n_fold])
print('The average f1_score is:', sum(val_f1) / len(val_f1))
经过漫长的训练和等待…

十次训练的得分为0.93分,还不错。
线上验证
test_data = pd.read_csv(r'D:\Users\Felixteng\Documents\Pycharm Files\Nlp\data\test_a.csv', sep='\t')
test_pred = [model.predict(x)[0][0].split('__')[-1] for x in test_data['text']]
sub = pd.DataFrame(test_pred, columns=['label'])
sub.to_csv('sub.csv', index=False)
线上预测结果分数为0.9304,线上线下差别不大,分数还不错,不过参数都没大动,还有提高空间。
前后尝试手动调了几次参,分数并没有变得更高
val_0 = pd.read_csv(f'data/fasttext_skf10_datasplit/test_split0.csv', sep='\t')
model_0 = fasttext.train_supervised(f'data/fasttext_skf10_datasplit/train_split0.csv',
lr=1.0, wordNgrams=3, verbose=2, minCount=1, epoch=25, loss='softmax')
val_pred_0 = [model_0.predict(x)[0][0].split('__')[-1] for x in val_0['text']]
print(f1_score(val_0['label'].values.astype(str), val_pred_0, average='macro'))
test_pred_0 = [model_0.predict(x)[0][0].split('__')[-1] for x in test_data['text']]
sub_0 = pd.DataFrame(test_pred_0, columns=['label'])
sub_0.to_csv('sub_0.csv', index=False)
val_1 = pd.read_csv(f'data/fasttext_skf10_datasplit/test_split1.csv', sep='\t')
model_1 = fasttext.train_supervised(f'data/fasttext_skf10_datasplit/train_split1.csv',
lr=1.5, wordNgrams=3, verbose=2, minCount=1, epoch=25, loss='softmax')
val_pred_1 = [model_1.predict(x)[0][0].split('__')[-1] for x in val_1['text']]
print(f1_score(val_1['label'].values.astype(str), val_pred_1, average='macro'))
'''
0.9344292030486819
'''
val_2 = pd.read_csv(f'data/fasttext_skf10_datasplit/test_split2.csv', sep='\t')
model_2 = fasttext.train_supervised(f'data/fasttext_skf10_datasplit/train_split2.csv',
lr=2, wordNgrams=3, verbose=2, minCount=1, epoch=25, loss='softmax')
val_pred_2 = [model_2.predict(x)[0][0].split('__')[-1] for x in val_2['text']]
print(f1_score(val_2['label'].values.astype(str), val_pred_2, average='macro'))
'''
0.934281492108054
'''
val_3 = pd.read_csv(f'data/fasttext_skf10_datasplit/test_split3.csv', sep='\t')
model_3 = fasttext.train_supervised(f'data/fasttext_skf10_datasplit/train_split3.csv',
lr=1.5, wordNgrams=4, verbose=2, minCount=1, epoch=25, loss='softmax')
val_pred_3 = [model_3.predict(x)[0][0].split('__')[-1] for x in val_3['text']]
print(f1_score(val_3['label'].values.astype(str), val_pred_3, average='macro'))
'''
0.9383561689755379
'''
val_4 = pd.read_csv(f'data/fasttext_skf10_datasplit/test_split4.csv', sep='\t')
model_4 = fasttext.train_supervised(f'data/fasttext_skf10_datasplit/train_split4.csv',
lr=2.5, wordNgrams=3, verbose=2, minCount=1, epoch=25, loss='softmax')
val_pred_4 = [model_4.predict(x)[0][0].split('__')[-1] for x in val_4['text']]
print(f1_score(val_4['label'].values.astype(str), val_pred_4, average='macro'))
'''
0.9353875257235135
'''
val_5 = pd.read_csv(f'data/fasttext_skf10_datasplit/test_split5.csv', sep='\t')
model_5 = fasttext.train_supervised(f'data/fasttext_skf10_datasplit/train_split5.csv',
lr=2, wordNgrams=4, verbose=2, minCount=1, epoch=30, loss='softmax')
val_pred_5 = [model_5.predict(x)[0][0].split('__')[-1] for x in val_5['text']]
print(f1_score(val_5['label'].values.astype(str), val_pred_5, average='macro'))
'''
0.9354738839095721
'''
test_pred_3 = [model_3.predict(x)[0][0].split('__')[-1] for x in test_data['text']]
sub_3 = pd.DataFrame(test_pred_3, columns=['label'])
sub_3.to_csv('sub_3.csv', index=False)
分数都在0.935上下徘徊,除了写一个自动调参的脚本,可能需要精度更高的模型加以训练了。
下一章节会就深度学习的其他模型,继续尝试文本分类任务。

















 1164
1164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









