




视频介绍
通过网盘分享的文件:项目源码.docx 链接: https://pan.baidu.com/s/1FU69VfNKpEY4PB4zQ1i0Ig?pwd=am7s 提取码: am7s
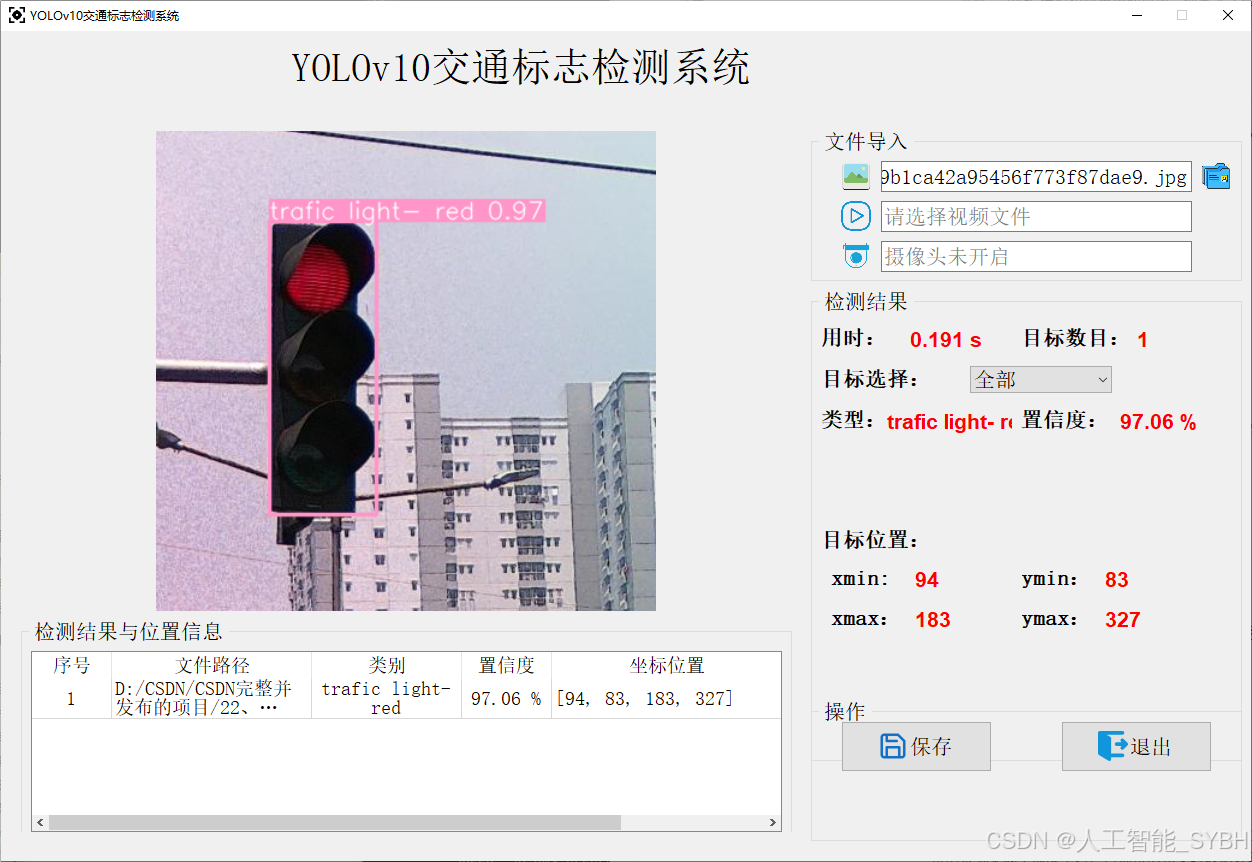
图片检测
视频检测

结果

摄像头实时检测
结果保存

项目包含:
- 确保项目可以运行(图片识别、视频识别、摄像头实时识别和结果保存)。
- 训练好的pt模型文件
- 完整的ui界面
- 完整代码
- 环境配置教程
- 训练结果分析图
软件主要功能
1. 支持图片、视频及摄像头进行检测,同时支持图片的批量检测;
2. 界面可实时显示目标位置、目标总数、置信度、用时等信息;
3. 支持图片或者视频的检测结果保存;
目录
摘要
随着自动驾驶技术的快速发展,交通标志检测和识别系统在智能交通管理中起着至关重要的作用。交通标志检测不仅需要精确识别多种类标志,还要在复杂场景下快速响应。YOLO(You Only Look Once)作为一种快速、精确的目标检测算法,在交通标志检测中备受关注。今天,我们将探讨YOLOv10在交通标志检测中的应用及其优势。本文设计并实现了一个交通标志的实时检测系统,该系统包括了交通标志检测数据集、YOLOv10模型、用户界面(UI)和完整的可运行环境。
本文基于YOLOv10深度学习框架,通过14276张图片,训练了一个交通标志的目标检测模型。并基于此模型开发了一款带UI界面的交通标志检测系统,可用于实时检测场景中的交通标志,更方便进行功能的展示。该系统是基于python与PyQT5开发的,支持图片、视频以及摄像头进行实时目标检测,并保存检测结果。
系统的主要流程包括以下几个模块:
1) 数据集准备:收集并标注了大量交通标志的样本数据,涵盖多种场景和环境。
2) 模型训练与优化:基于YOLOv10进行交通标志检测模型的训练,通过数据增强与超参数调优提升模型的检测精度与响应速度。
3) 实时检测与UI展示:利用摄像头实时捕捉图像输入系统,经过YOLOv10模型处理后快速识别交通标志区域,同时在用户界面上同步显示检测结果和警报信息。
4) 系统集成与部署:该系统实现了从数据采集、模型加载到检测结果输出的全自动流程,支持不同设备平台上的应用部署,确保检测系统能够24小时稳定运行。
前言
在现代智能交通系统中,交通标志检测和识别是一项至关重要的技术,尤其是随着自动驾驶、智能辅助驾驶等技术的飞速发展,车辆对交通标志的准确识别和实时响应直接关系到驾驶安全和效率。YOLO(You Only Look Once)系列模型在计算机视觉领域表现优异,尤其适合实时物体检测任务。随着YOLO版本的不断更新,YOLOv10的发布进一步提升了目标检测的精度和速度,为交通标志检测带来了更强的技术支持。
本文将介绍一个基于YOLOv10的交通标志检测系统,旨在实现对各类交通标志的高效检测和识别。我们将展示该系统的构建过程、数据集准备、模型训练和优化,并以丰富的实验结果来验证其实际效果。在实验中,我们使用了种类繁多的交通标志,包括儿童、限速、行人、铁路平交道口、停车等78类交通标志,涵盖了常见的标志类别。希望通过这篇文章,读者能够深入了解如何借助YOLOv10技术构建一个可靠的交通标志检测系统。
YOLOv10是YOLO系列的最新版本,在架构和性能上进一步优化。相比前代模型,它在精度和速度上做了平衡优化,通过引入自适应特征融合(Adaptive Feature Fusion)、基于Transformer的Attention机制等新技术,进一步提升了目标检测的效率。
YOLOv10的主要特性
- 高效的卷积模块:采用轻量级卷积模块,降低计算复杂度,使得检测过程更快。
- 强大的Attention机制:YOLOv10引入了基于Transformer的注意力模块,使模型更善于关注目标区域,提高小物体检测的精度。
- 自适应特征融合:通过特征融合增强特定检测任务(如交通标志检测)所需的特征提取能力。
数据标注的图像

识别后的结果

YOLOv10的优点
过去几年中,由于YOLO在计算成本和检测性能之间的有效平衡,它已经成为实时目标检测领域的主要范式。研究人员探索了YOLO的架构设计、优化目标、数据增强策略等方面,取得了显著进展。然而,YOLO依赖于非极大值抑制(NMS)进行后处理,这阻碍了YOLO的端到端部署,并对推理延迟产生了不利影响。此外,YOLO的各种组件设计缺乏全面深入的检查,导致明显的计算冗余,限制了模型的能力。这导致了效率不佳,同时也有很大的性能提升潜力。在这项工作中,我们旨在从后处理和模型架构两方面进一步提升YOLO的性能-效率边界。为此,我们首先提出了一致的双重分配策略,用于YOLO的NMS-free训练,这同时带来了竞争力的性能和低推理延迟。此外,我们引入了整体效率-精度驱动的模型设计策略。我们从效率和精度的角度全面优化了YOLO的各个组件,大大减少了计算开销并增强了能力。我们的努力成果是一个新的YOLO系列,用于实时端到端目标检测,称为YOLOv10。大量实验表明,YOLOv10在各种模型规模上都达到了最先进的性能和效率。例如,在COCO数据集上,YOLOv10-S在相似AP的情况下比RT-DETR-R18快1.8倍,同时参数和FLOPs减少了2.8倍。与YOLOv9-C相比,YOLOv10-B在相同性能下的延迟减少了46%,参数减少了25%。

我们的YOLOv10在各种模型规模上实现了最先进的性能和端到端延迟。我们首先将YOLOv10与我们的基线模型YOLOv8进行比较。在N / S / M / L / X五种变体上,YOLOv10分别实现了1.2% / 1.4% / 0.5% / 0.3% / 0.5%的AP提升,同时参数减少了28% / 36% / 41% / 44% / 57%,计算量减少了23% / 24% / 25% / 27% / 38%,延迟降低了70% / 65% / 50% / 41% / 37%。
与其他YOLO模型相比,YOLOv10在准确性和计算成本之间也表现出更优的权衡。具体来说,对于轻量级和小型模型,YOLOv10-N / S比YOLOv6-3.0-N / S分别高出1.5 AP和2.0 AP。
表1中列出了与最先进方法的比较。延迟是使用官方预训练模型测量的。Latencyf表示模型在没有后处理时前向过程的延迟。†表示YOLOv10使用原始一对多训练并采用NMS的结果。为了公平比较,所有结果均未使用诸如知识蒸馏或PGI等额外的高级训练技术。

相比于AP,YOLOv10在参数量和计算量上分别减少了51% / 61%。对于中等规模的模型,YOLOv10-B / M相较于YOLOv9-C / YOLO-MS,在相同或更好的性能下分别减少了46% / 62%的延迟。对于大型模型,相较于Gold-YOLO-L,我们的YOLOv10-L减少了68%的参数量和32%的延迟,同时显著提升了1.4%的AP。此外,与RT-DETR相比,YOLOv10在性能和延迟上均有显著提升。值得注意的是,YOLOv10-S / X在类似性能下推理速度分别比RT-DETR-R18 / R101快1.8倍和1.3倍。这些结果充分证明了YOLOv10作为实时端到端检测器的优越性。
1. 数据集介绍-14276张图像
在构建用于交通标志检测的深度学习模型时,一个全面和精确标注的数据集是至关重要的。我们的数据集共包含14276张图像,其中包括12356张训练图像,1266张验证图像,以及654张测试图像。这样的划分旨在确保模型能在充足的数据上进行训练,同时留出足够的样本来验证和测试模型的性能。



在数据预处理阶段,我们采取了几项关键步骤以确保数据集的质量。首先,所有图像都经过了自动方向校正,并剥离了EXIF方向信息,这是为了消除因摄影设备的不同拍摄角度而带来的方向差异。接着,所有图像都被统一调整至640x640像素,通过拉伸的方式来适配这一分辨率。虽然这可能导致一些图像的比例失真,但这样做能确保所有图像都适合模型的输入需求,并且可以在不牺牲处理速度的情况下保持图像特征的辨识度。
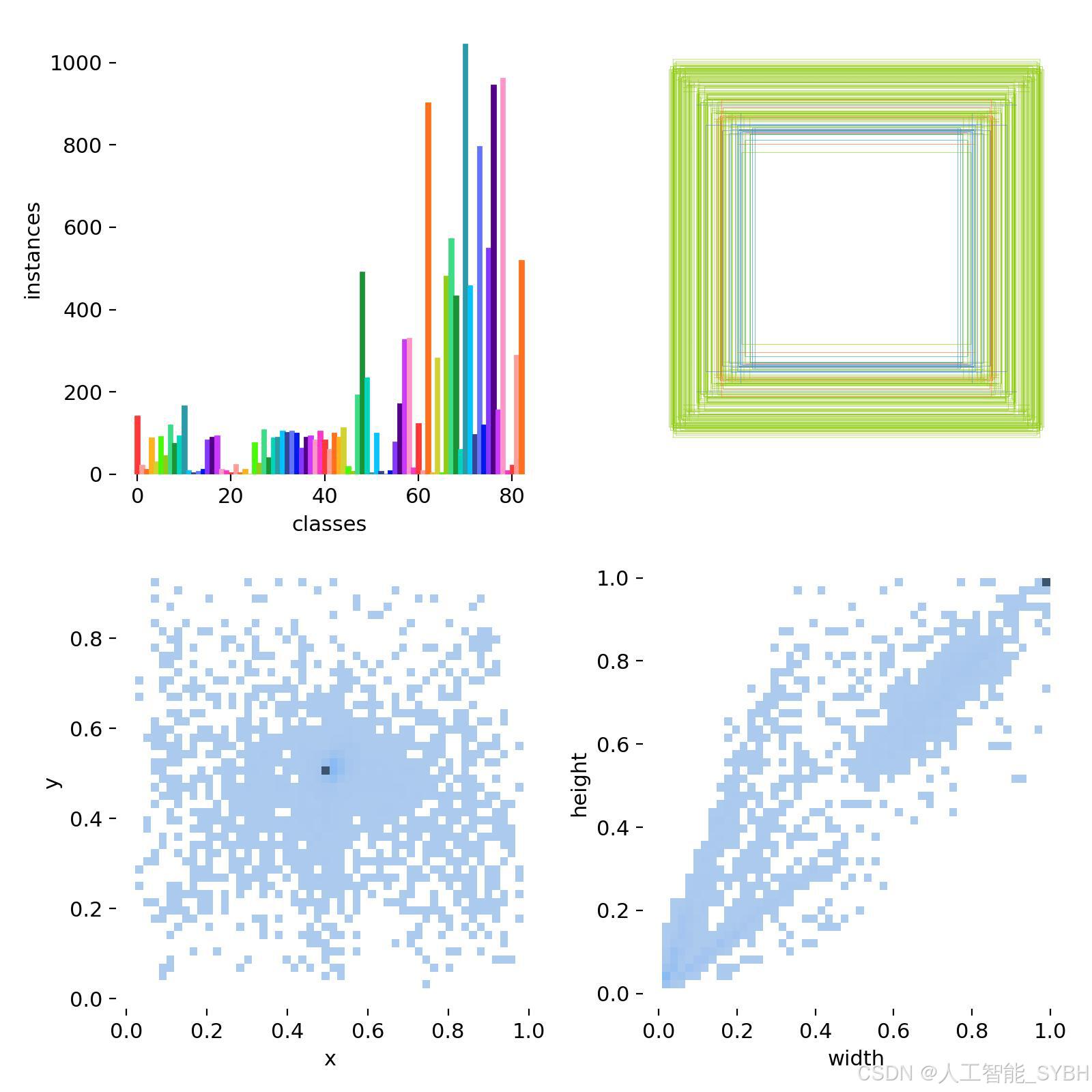
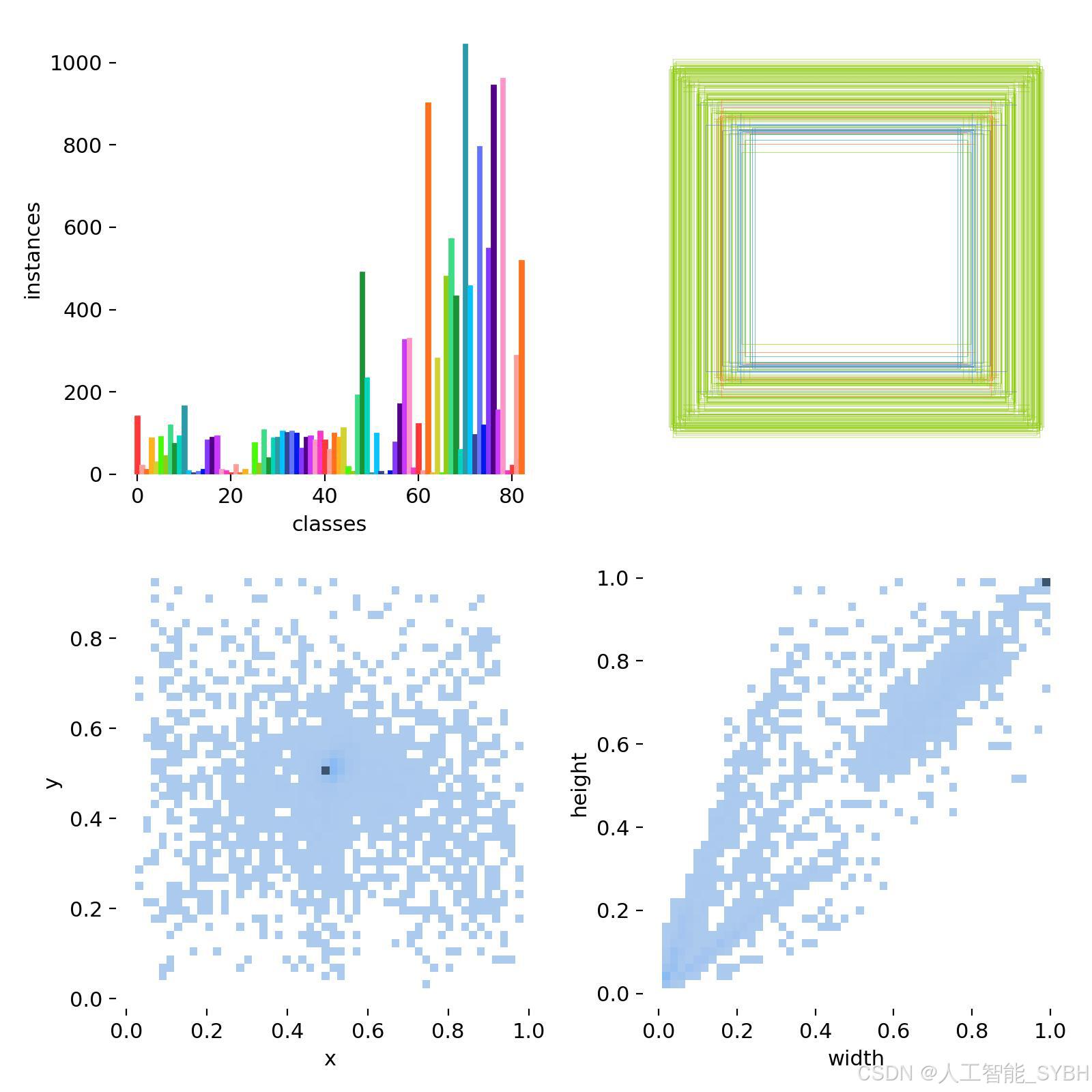
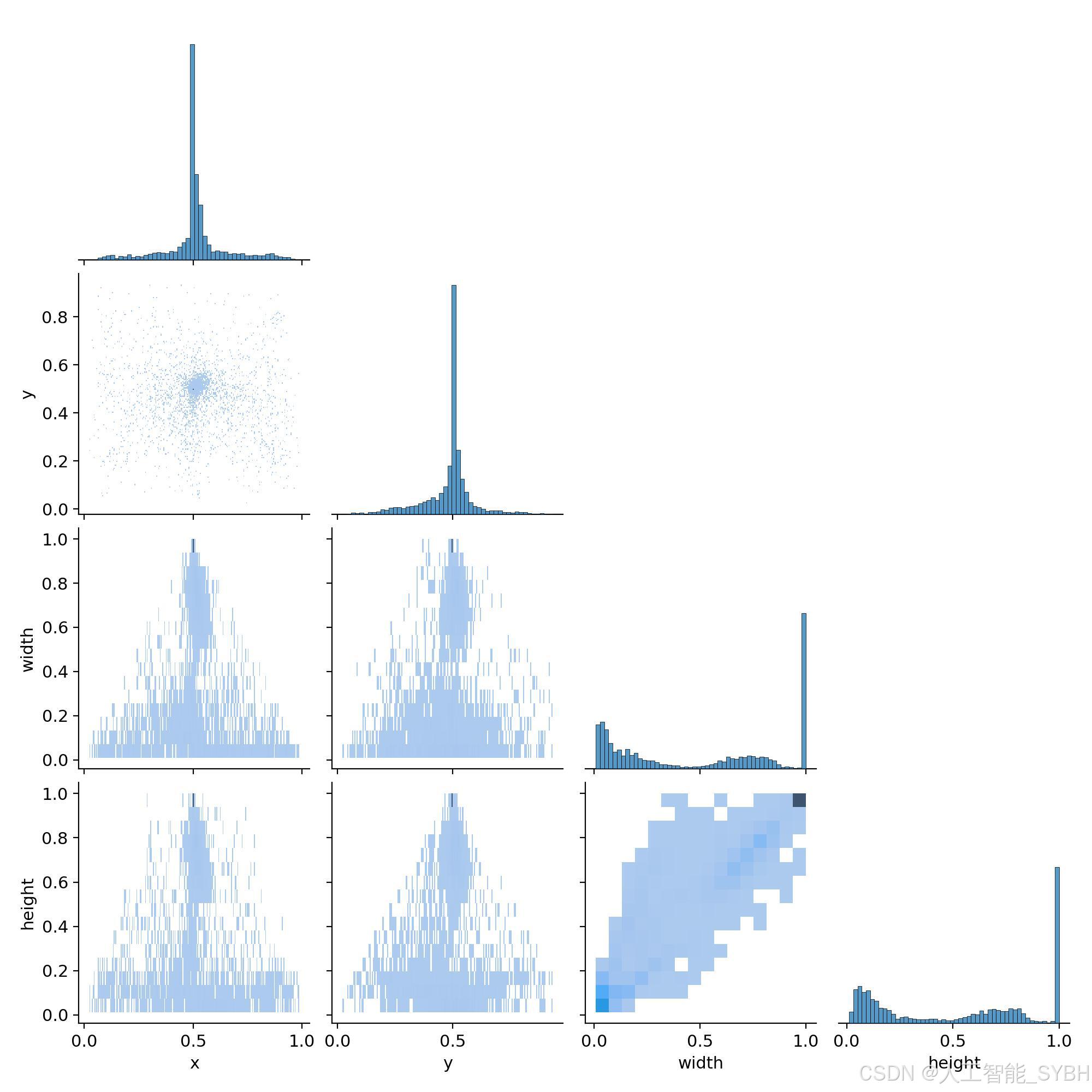
通过分析数据集的标注分布图,我们发现大部分标注框集中在图像的中心区域。这表明数据采集过程中存在一个偏向性:交通标志大多出现在画面中央。虽然这种分布有助于模型更好地学习识别中心区域的目标,但也可能导致模型在检测图像边缘的交通标志时表现欠佳。为此,我们采用了多种数据增强方法,包括随机旋转、缩放、裁剪以及颜色变化等,以模拟不同的视角和环境条件,从而提升模型在各种情况下对烟雾的检测能力。
此外,标注框的大小分布表明交通标志在图像中的尺寸具有较大差异。为了使模型能够识别各种大小的交通标志,我们在数据集的宽度和高度分布中充分考虑了这一点。
总体而言,本数据集经过精心准备和处理,旨在为研究人员和从业者提供坚实的基础,以支持深度学习模型的训练和评估。借助本数据集的使用,我们可以深入研究 YOLOv10 等先进目标检测算法在烟雾检测任务中的应用潜力,并期望在实际应用中实现更高的检测准确性和效率。
数据集配置文件data.yaml
train: ..\yolov10交通标志检测\datasets\images\train
val: ..\yolov10交通标志检测\\datasets\images\val
test: # test images (optional)
nc: 83
names: ['Children', 'Entering city', 'Exiting city', 'Falling rocks', 'Fog', 'Give way', 'Ice or snow', 'Intersection with priority', 'Intersection without priority', 'Level crossing -multiple tracks-', 'Level crossing 160m', 'Level crossing 240m', 'Level crossing 80m', 'Level crossing with barriers ahead', 'Level crossing without barriers ahead', 'Level crossing', 'Loose surface material', 'Low-flying aircraft', 'No heavy goods vehicles', 'No left turn', 'No overtaking by heavy goods vehicles', 'No right turn', 'No vehicles carrying dangerous goods', 'No vehicles', 'One-way street', 'Opening bridge', 'Parking zone', 'Pedestrian crossing', 'Pedestrians', 'Priority over oncoming traffic', 'Right curve', 'Road narrows', 'Roadworks', 'Series of curves', 'Slippery surface', 'Soft verges', 'Steep ascent', 'Steep descent', 'Traffic queues', 'Traffic signals', 'Trams', 'Tunnel', 'Two-way traffic', 'Unprotected quayside or riverbank', 'Wild animals', 'ahead only', 'ahead or right', 'bumpy road', 'crosswalk', 'do_not_enter', 'end ofSpeed limit 70', 'general caution', 'keep right', 'left curve', 'no admittance', 'no overtakes', 'no stopping', 'no_parking', 'priority road', 'road work', 'roundabout', 'slippery road', 'speed limit -100-', 'speed limit -110-', 'speed limit -120-', 'speed limit -130-', 'speed limit -20-', 'speed limit -30-', 'speed limit -40-', 'speed limit -5-', 'speed limit -50-', 'speed limit -60-', 'speed limit -70-', 'speed limit -80-', 'speed limit -90-', 'stop', 'traffic light- green', 'traffic light- red', 'trafic light- red', 'turn left orright only', 'turn right only', 'yellow', 'yield']
2、模型训练、评估和推理
2.1 模型训练(train.py)
from ultralytics import YOLOv10
model_path = 'yolov10s.pt'
data_path = 'datasets/data.yaml'
if __name__ == '__main__':
model = YOLOv10(model_path)
results = model.train(data=data_path,
epochs=500,
batch=64,
device='0',
workers=0,
project='runs/detect',
name='exp',
)1. 模型选择
代码注释列出了YOLOv10模型的不同版本,分别适用于不同需求的任务:
- yolov10n.yaml (nano):最轻量化的模型,适合嵌入式设备,速度较快,但精度可能稍低。
- yolov10s.yaml (small):小型模型,适合需要一定精度的实时任务。
- yolov10m.yaml (medium):中等大小的模型,平衡了速度和精度。
- yolov10b.yaml (base):基本版模型,适合大多数应用。
- yolov10l.yaml (large):大型模型,适合高精度需求的任务。
在代码中,model_path指定了使用的模型权重文件yolov10s.pt,即小型模型(small),适合实时任务。
2. 训练过程
主程序块中,YOLOv10模型被实例化,并调用了.train()方法以启动训练,关键参数包括:
- data: 指定数据集配置文件路径。
- epochs: 训练轮数,这里设定为500轮。
- batch: 每批次数据量,设定为64。
- device: 指定训练设备为GPU('0'表示使用第一个GPU)。
- workers: 数据加载时的子进程数,这里设定为0,适合简单测试或资源有限的设备。
- project: 训练结果存储的主目录。
- name: 实验名称,每次训练的结果会保存在以该名称为子目录的文件夹中。
2.2 训练结果
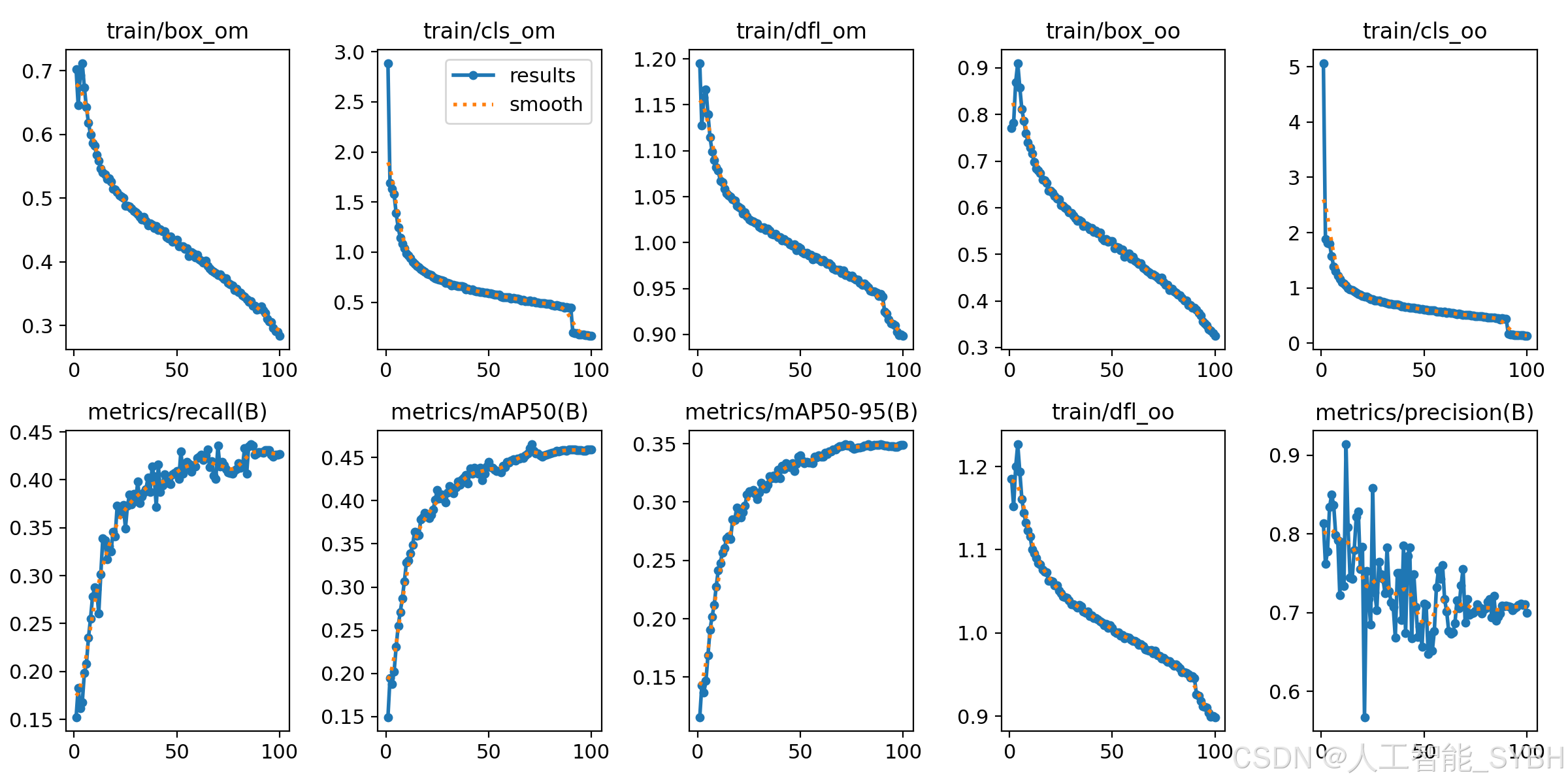
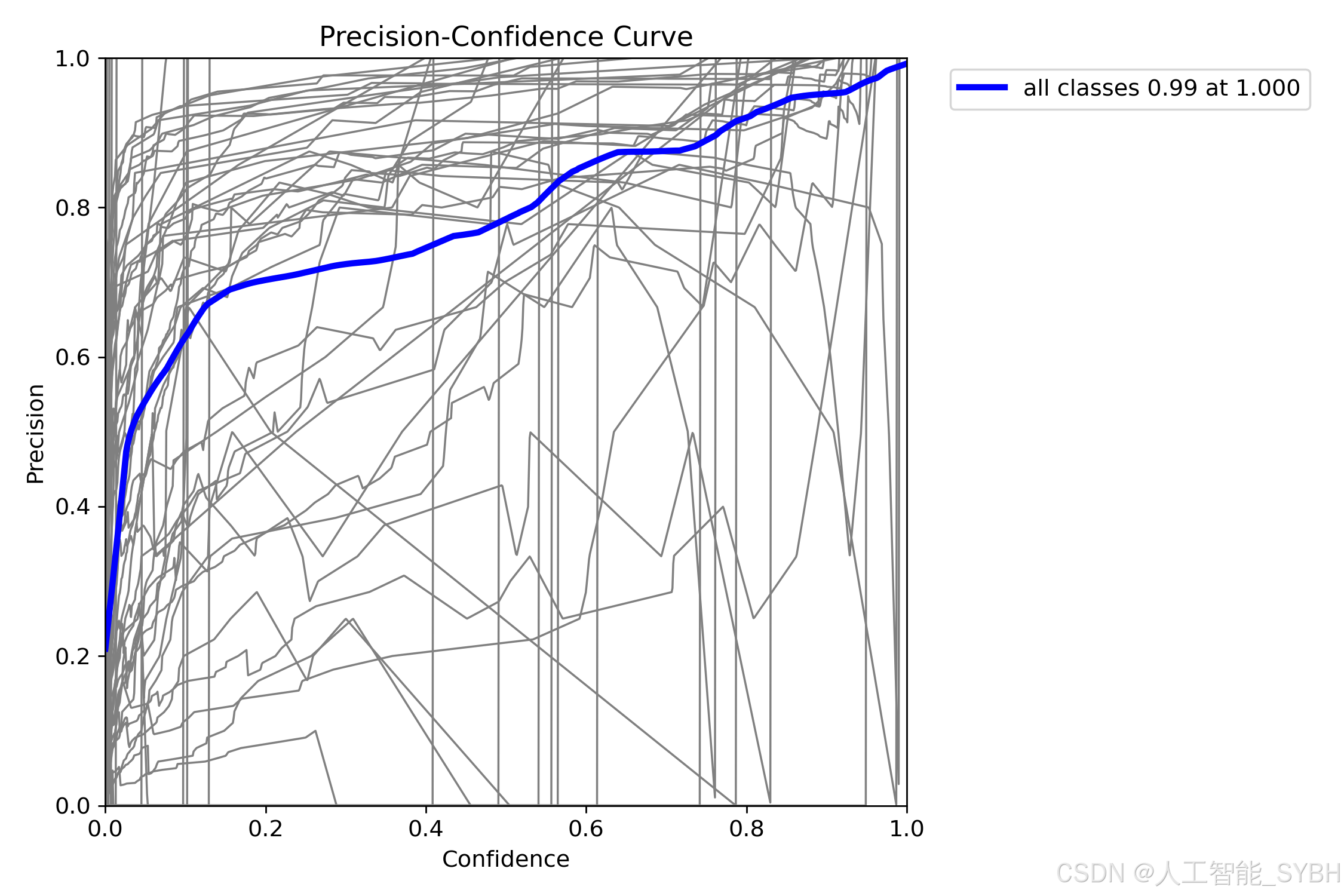
在性能指标方面,图表中的metrics/precision、metrics/recall、metrics/mAP50和metrics/mAP50-95展示了模型性能的逐步提升。随着训练迭代的增加,准确率(Precision)和召回率(Recall)不断提高,这表明模型在识别正样本时变得更加精确,且能捕捉到更多的正样本。mAP(mean Average Precision)是目标检测领域中重要的评估指标之一,其中metrics/mAP50和metrics/mAP50-95的提升说明模型在不同IoU阈值下的检测性能均在提高。具体而言,mAP50表示IoU为0.5时的平均精度,而mAP50-95则涵盖了IoU从0.5到0.95不同阈值下的平均精度,这更加全面地反映了模型在各种重叠程度下的表现。这些指标的稳步上升表明模型在整个训练过程中不断优化,性能逐渐增强。
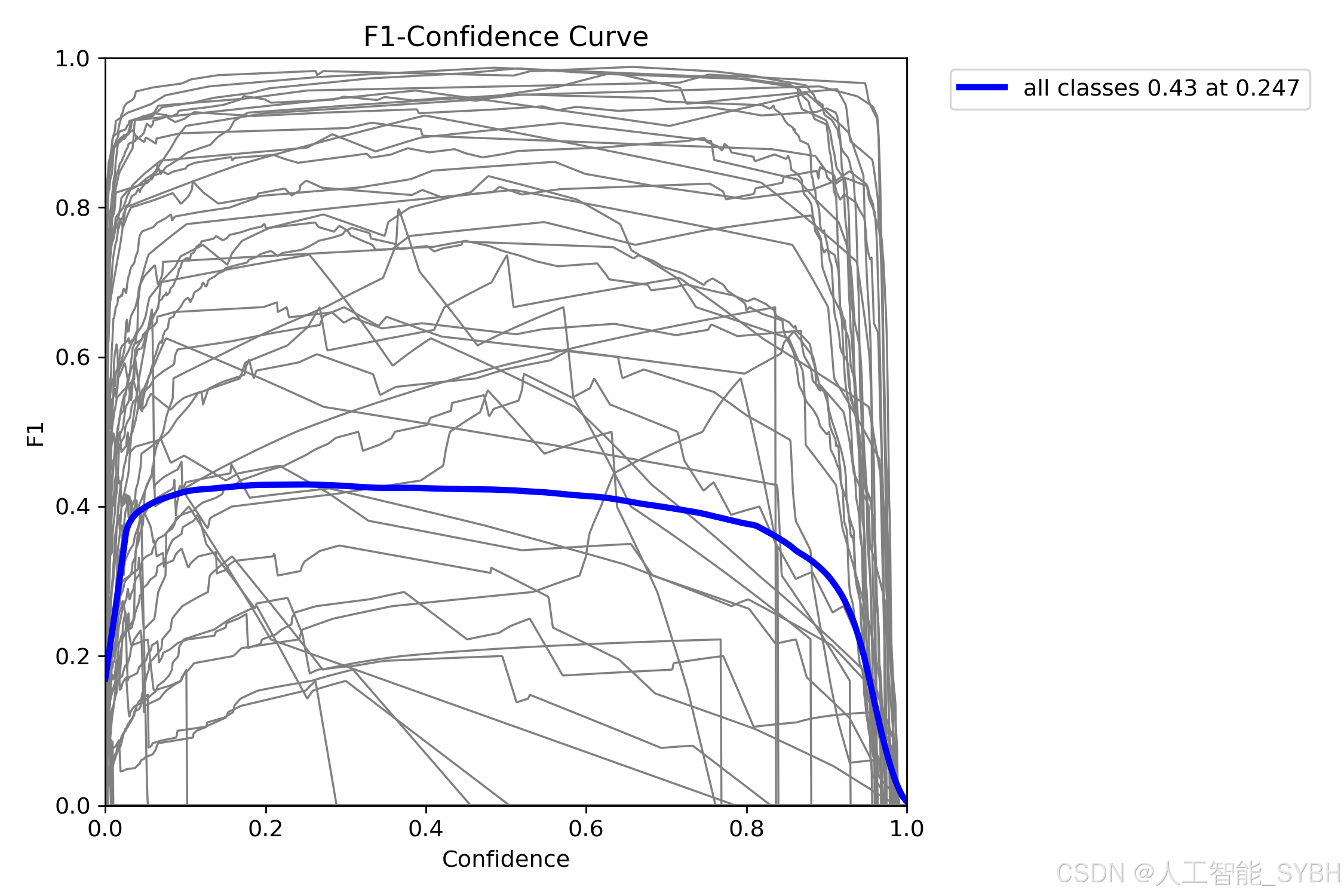
在机器学习中,F1分数也是一个非常重要的性能指标,结合了模型的准确率和召回率,提供了对分类性能的全面视角。尤其在正负样本分布不均的情况下,F1分数有助于评估模型在区分困难类别时的表现,从而更好地理解其实际应用效果。
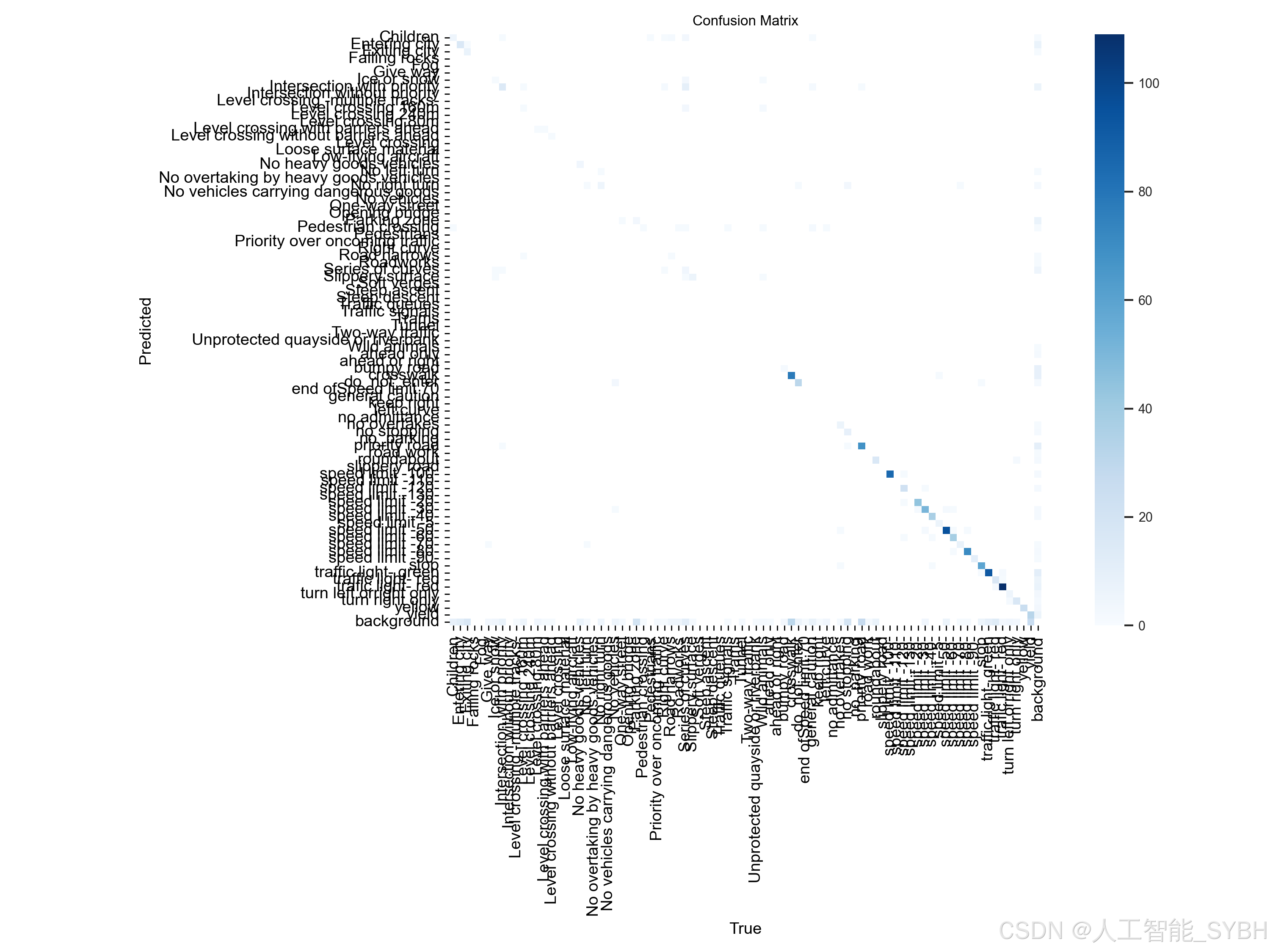
3、 系统界面效果
3.1图片检测
3.2视频检测
结果
3.3摄像头实时检测
3.4结果保存
4、项目源码
data.yaml
train: ..\yolov10交通标志检测\datasets\images\train
val: ..\yolov10交通标志检测\\datasets\images\val
test: # test images (optional)
nc: 83
names: ['Children', 'Entering city', 'Exiting city', 'Falling rocks', 'Fog', 'Give way', 'Ice or snow', 'Intersection with priority', 'Intersection without priority', 'Level crossing -multiple tracks-', 'Level crossing 160m', 'Level crossing 240m', 'Level crossing 80m', 'Level crossing with barriers ahead', 'Level crossing without barriers ahead', 'Level crossing', 'Loose surface material', 'Low-flying aircraft', 'No heavy goods vehicles', 'No left turn', 'No overtaking by heavy goods vehicles', 'No right turn', 'No vehicles carrying dangerous goods', 'No vehicles', 'One-way street', 'Opening bridge', 'Parking zone', 'Pedestrian crossing', 'Pedestrians', 'Priority over oncoming traffic', 'Right curve', 'Road narrows', 'Roadworks', 'Series of curves', 'Slippery surface', 'Soft verges', 'Steep ascent', 'Steep descent', 'Traffic queues', 'Traffic signals', 'Trams', 'Tunnel', 'Two-way traffic', 'Unprotected quayside or riverbank', 'Wild animals', 'ahead only', 'ahead or right', 'bumpy road', 'crosswalk', 'do_not_enter', 'end ofSpeed limit 70', 'general caution', 'keep right', 'left curve', 'no admittance', 'no overtakes', 'no stopping', 'no_parking', 'priority road', 'road work', 'roundabout', 'slippery road', 'speed limit -100-', 'speed limit -110-', 'speed limit -120-', 'speed limit -130-', 'speed limit -20-', 'speed limit -30-', 'speed limit -40-', 'speed limit -5-', 'speed limit -50-', 'speed limit -60-', 'speed limit -70-', 'speed limit -80-', 'speed limit -90-', 'stop', 'traffic light- green', 'traffic light- red', 'trafic light- red', 'turn left orright only', 'turn right only', 'yellow', 'yield']
train.py
#coding:utf-8
#根据实际情况更换模型
# yolov10n.yaml (nano):轻量化模型,适合嵌入式设备,速度快但精度略低。
# yolov10s.yaml (small):小模型,适合实时任务。
# yolov10m.yaml (medium):中等大小模型,兼顾速度和精度。
# yolov10b.yaml (base):基本版模型,适合大部分应用场景。
# yolov10l.yaml (large):大型模型,适合对精度要求高的任务。
from ultralytics import YOLOv10
model_path = 'yolov10s.pt'
data_path = 'datasets/data.yaml'
if __name__ == '__main__':
model = YOLOv10(model_path)
results = model.train(data=data_path,
epochs=500,
batch=64,
device='0',
workers=0,
project='runs/detect',
name='exp',
)main.py
# -*- coding: utf-8 -*-
import time
from PyQt5.QtWidgets import QApplication , QMainWindow, QFileDialog,QMessageBox,QWidget,QHeaderView,QTableWidgetItem, QAbstractItemView
import sys
import os
from PIL import ImageFont
from ultralytics import YOLOv10
sys.path.append('UIProgram')
from UIProgram.UiMain import Ui_MainWindow
import sys
from PyQt5.QtCore import QTimer, Qt, QThread, pyqtSignal,QCoreApplication
import detect_tools as tools
import cv2
import Config
from UIProgram.QssLoader import QSSLoader
from UIProgram.precess_bar import ProgressBar
import numpy as np
# import torch
class MainWindow(QMainWindow):
def __init__(self, parent=None):
super(QMainWindow, self).__init__(parent)
self.ui = Ui_MainWindow()
self.ui.setupUi(self)
self.initMain()
self.signalconnect()
# 加载css渲染效果
style_file = 'UIProgram/style.css'
qssStyleSheet = QSSLoader.read_qss_file(style_file)
self.setStyleSheet(qssStyleSheet)
def signalconnect(self):
self.ui.PicBtn.clicked.connect(self.open_img)
self.ui.comboBox.activated.connect(self.combox_change)
self.ui.VideoBtn.clicked.connect(self.vedio_show)
self.ui.CapBtn.clicked.connect(self.camera_show)
self.ui.SaveBtn.clicked.connect(self.save_detect_video)
self.ui.ExitBtn.clicked.connect(QCoreApplication.quit)
self.ui.FilesBtn.clicked.connect(self.detact_batch_imgs)
def initMain(self):
self.show_width = 700
self.show_height = 500
self.org_path = None
self.is_camera_open = False
self.cap = None
# self.device = 0 if torch.cuda.is_available() else 'cpu'
# 加载检测模型
self.model = YOLOv10('runs/detect/exp/weights/best.pt', task='detect')
self.model(np.zeros((48, 48, 3))) #预先加载推理模型
self.fontC = ImageFont.truetype("Font/platech.ttf", 25, 0)
self.colors = tools.Colors()
self.timer_camera = QTimer()
# 更新检测信息表格
# self.timer_info = QTimer()
# 保存视频
self.timer_save_video = QTimer()
# 表格
self.ui.tableWidget.verticalHeader().setSectionResizeMode(QHeaderView.Fixed)
self.ui.tableWidget.verticalHeader().setDefaultSectionSize(40)
self.ui.tableWidget.setColumnWidth(0, 80) # 设置列宽
self.ui.tableWidget.setColumnWidth(1, 200)
self.ui.tableWidget.setColumnWidth(2, 150)
self.ui.tableWidget.setColumnWidth(3, 90)
self.ui.tableWidget.setColumnWidth(4, 230)
self.ui.tableWidget.setSelectionBehavior(QAbstractItemView.SelectRows) # 设置表格整行选中
self.ui.tableWidget.verticalHeader().setVisible(False) # 隐藏列标题
self.ui.tableWidget.setAlternatingRowColors(True) # 表格背景交替
def open_img(self):
if self.cap:
# 打开图片前关闭摄像头
self.video_stop()
self.is_camera_open = False
self.ui.CaplineEdit.setText('摄像头未开启')
self.cap = None
file_path, _ = QFileDialog.getOpenFileName(None, '打开图片', './', "Image files (*.jpg *.jepg *.png)")
if not file_path:
return
self.ui.comboBox.setDisabled(False)
self.org_path = file_path
self.org_img = tools.img_cvread(self.org_path)
# 目标检测
t1 = time.time()
self.results = self.model(self.org_path)[0]
t2 = time.time()
take_time_str = '{:.3f} s'.format(t2 - t1)
self.ui.time_lb.setText(take_time_str)
location_list = self.results.boxes.xyxy.tolist()
self.location_list = [list(map(int, e)) for e in location_list]
cls_list = self.results.boxes.cls.tolist()
self.cls_list = [int(i) for i in cls_list]
self.conf_list = self.results.boxes.conf.tolist()
self.conf_list = ['%.2f %%' % (each*100) for each in self.conf_list]
total_nums = len(location_list)
cls_percents = []
for i in range(2):
res = self.cls_list.count(i) / total_nums
cls_percents.append(res)
self.set_percent(cls_percents)
now_img = self.results.plot()
self.draw_img = now_img
# 获取缩放后的图片尺寸
self.img_width, self.img_height = self.get_resize_size(now_img)
resize_cvimg = cv2.resize(now_img,(self.img_width, self.img_height))
pix_img = tools.cvimg_to_qpiximg(resize_cvimg)
self.ui.label_show.setPixmap(pix_img)
self.ui.label_show.setAlignment(Qt.AlignCenter)
# 设置路径显示
self.ui.PiclineEdit.setText(self.org_path)
# 目标数目
target_nums = len(self.cls_list)
self.ui.label_nums.setText(str(target_nums))
# 设置目标选择下拉框
choose_list = ['全部']
target_names = [Config.names[id]+ '_'+ str(index) for index,id in enumerate(self.cls_list)]
choose_list = choose_list + target_names
self.ui.comboBox.clear()
self.ui.comboBox.addItems(choose_list)
if target_nums >= 1:
self.ui.type_lb.setText(Config.CH_names[self.cls_list[0]])
self.ui.label_conf.setText(str(self.conf_list[0]))
self.ui.label_xmin.setText(str(self.location_list[0][0]))
self.ui.label_ymin.setText(str(self.location_list[0][1]))
self.ui.label_xmax.setText(str(self.location_list[0][2]))
self.ui.label_ymax.setText(str(self.location_list[0][3]))
else:
self.ui.type_lb.setText('')
self.ui.label_conf.setText('')
self.ui.label_xmin.setText('')
self.ui.label_ymin.setText('')
self.ui.label_xmax.setText('')
self.ui.label_ymax.setText('')
# # 删除表格所有行
self.ui.tableWidget.setRowCount(0)
self.ui.tableWidget.clearContents()
self.tabel_info_show(self.location_list, self.cls_list, self.conf_list,path=self.org_path)
def detact_batch_imgs(self):
if self.cap:
# 打开图片前关闭摄像头
self.video_stop()
self.is_camera_open = False
self.ui.CaplineEdit.setText('摄像头未开启')
self.cap = None
directory = QFileDialog.getExistingDirectory(self,
"选取文件夹",
"./") # 起始路径
if not directory:
return
self.org_path = directory
img_suffix = ['jpg','png','jpeg','bmp']
for file_name in os.listdir(directory):
full_path = os.path.join(directory,file_name)
if os.path.isfile(full_path) and file_name.split('.')[-1].lower() in img_suffix:
# self.ui.comboBox.setDisabled(False)
img_path = full_path
self.org_img = tools.img_cvread(img_path)
# 目标检测
t1 = time.time()
self.results = self.model(img_path)[0]
t2 = time.time()
take_time_str = '{:.3f} s'.format(t2 - t1)
self.ui.time_lb.setText(take_time_str)
location_list = self.results.boxes.xyxy.tolist()
self.location_list = [list(map(int, e)) for e in location_list]
cls_list = self.results.boxes.cls.tolist()
self.cls_list = [int(i) for i in cls_list]
self.conf_list = self.results.boxes.conf.tolist()
self.conf_list = ['%.2f %%' % (each * 100) for each in self.conf_list]
total_nums = len(location_list)
cls_percents = []
for i in range(2):
res = self.cls_list.count(i) / total_nums
cls_percents.append(res)
self.set_percent(cls_percents)
now_img = self.results.plot()
self.draw_img = now_img
# 获取缩放后的图片尺寸
self.img_width, self.img_height = self.get_resize_size(now_img)
resize_cvimg = cv2.resize(now_img, (self.img_width, self.img_height))
pix_img = tools.cvimg_to_qpiximg(resize_cvimg)
self.ui.label_show.setPixmap(pix_img)
self.ui.label_show.setAlignment(Qt.AlignCenter)
# 设置路径显示
self.ui.PiclineEdit.setText(img_path)
# 目标数目
target_nums = len(self.cls_list)
self.ui.label_nums.setText(str(target_nums))
# 设置目标选择下拉框
choose_list = ['全部']
target_names = [Config.names[id] + '_' + str(index) for index, id in enumerate(self.cls_list)]
choose_list = choose_list + target_names
self.ui.comboBox.clear()
self.ui.comboBox.addItems(choose_list)
if target_nums >= 1:
self.ui.type_lb.setText(Config.CH_names[self.cls_list[0]])
self.ui.label_conf.setText(str(self.conf_list[0]))
self.ui.label_xmin.setText(str(self.location_list[0][0]))
self.ui.label_ymin.setText(str(self.location_list[0][1]))
self.ui.label_xmax.setText(str(self.location_list[0][2]))
self.ui.label_ymax.setText(str(self.location_list[0][3]))
else:
self.ui.type_lb.setText('')
self.ui.label_conf.setText('')
self.ui.label_xmin.setText('')
self.ui.label_ymin.setText('')
self.ui.label_xmax.setText('')
self.ui.label_ymax.setText('')
# # 删除表格所有行
self.tabel_info_show(self.location_list, self.cls_list, self.conf_list, path=img_path)
self.ui.tableWidget.scrollToBottom()
QApplication.processEvents() #刷新页面
def draw_rect_and_tabel(self, results, img):
now_img = img.copy()
location_list = results.boxes.xyxy.tolist()
self.location_list = [list(map(int, e)) for e in location_list]
cls_list = results.boxes.cls.tolist()
self.cls_list = [int(i) for i in cls_list]
self.conf_list = results.boxes.conf.tolist()
self.conf_list = ['%.2f %%' % (each * 100) for each in self.conf_list]
for loacation, type_id, conf in zip(self.location_list, self.cls_list, self.conf_list):
type_id = int(type_id)
color = self.colors(int(type_id), True)
# cv2.rectangle(now_img, (int(x1), int(y1)), (int(x2), int(y2)), colors(int(type_id), True), 3)
now_img = tools.drawRectBox(now_img, loacation, Config.CH_names[type_id], self.fontC, color)
# 获取缩放后的图片尺寸
self.img_width, self.img_height = self.get_resize_size(now_img)
resize_cvimg = cv2.resize(now_img, (self.img_width, self.img_height))
pix_img = tools.cvimg_to_qpiximg(resize_cvimg)
self.ui.label_show.setPixmap(pix_img)
self.ui.label_show.setAlignment(Qt.AlignCenter)
# 设置路径显示
self.ui.PiclineEdit.setText(self.org_path)
# 目标数目
target_nums = len(self.cls_list)
self.ui.label_nums.setText(str(target_nums))
if target_nums >= 1:
self.ui.type_lb.setText(Config.CH_names[self.cls_list[0]])
self.ui.label_conf.setText(str(self.conf_list[0]))
self.ui.label_xmin.setText(str(self.location_list[0][0]))
self.ui.label_ymin.setText(str(self.location_list[0][1]))
self.ui.label_xmax.setText(str(self.location_list[0][2]))
self.ui.label_ymax.setText(str(self.location_list[0][3]))
else:
self.ui.type_lb.setText('')
self.ui.label_conf.setText('')
self.ui.label_xmin.setText('')
self.ui.label_ymin.setText('')
self.ui.label_xmax.setText('')
self.ui.label_ymax.setText('')
# 删除表格所有行
self.ui.tableWidget.setRowCount(0)
self.ui.tableWidget.clearContents()
self.tabel_info_show(self.location_list, self.cls_list, self.conf_list, path=self.org_path)
return now_img
def combox_change(self):
com_text = self.ui.comboBox.currentText()
if com_text == '全部':
cur_box = self.location_list
cur_img = self.results.plot()
self.ui.type_lb.setText(Config.CH_names[self.cls_list[0]])
self.ui.label_conf.setText(str(self.conf_list[0]))
else:
index = int(com_text.split('_')[-1])
cur_box = [self.location_list[index]]
cur_img = self.results[index].plot()
self.ui.type_lb.setText(Config.CH_names[self.cls_list[index]])
self.ui.label_conf.setText(str(self.conf_list[index]))
# 设置坐标位置值
self.ui.label_xmin.setText(str(cur_box[0][0]))
self.ui.label_ymin.setText(str(cur_box[0][1]))
self.ui.label_xmax.setText(str(cur_box[0][2]))
self.ui.label_ymax.setText(str(cur_box[0][3]))
resize_cvimg = cv2.resize(cur_img, (self.img_width, self.img_height))
pix_img = tools.cvimg_to_qpiximg(resize_cvimg)
self.ui.label_show.clear()
self.ui.label_show.setPixmap(pix_img)
self.ui.label_show.setAlignment(Qt.AlignCenter)
def get_video_path(self):
file_path, _ = QFileDialog.getOpenFileName(None, '打开视频', './', "Image files (*.avi *.mp4 *.jepg *.png)")
if not file_path:
return None
self.org_path = file_path
self.ui.VideolineEdit.setText(file_path)
return file_path
def video_start(self):
# 删除表格所有行
self.ui.tableWidget.setRowCount(0)
self.ui.tableWidget.clearContents()
# 清空下拉框
self.ui.comboBox.clear()
# 定时器开启,每隔一段时间,读取一帧
self.timer_camera.start(1)
self.timer_camera.timeout.connect(self.open_frame)
def tabel_info_show(self, locations, clses, confs, path=None):
path = path
for location, cls, conf in zip(locations, clses, confs):
row_count = self.ui.tableWidget.rowCount() # 返回当前行数(尾部)
self.ui.tableWidget.insertRow(row_count) # 尾部插入一行
item_id = QTableWidgetItem(str(row_count+1)) # 序号
item_id.setTextAlignment(Qt.AlignHCenter | Qt.AlignVCenter) # 设置文本居中
item_path = QTableWidgetItem(str(path)) # 路径
# item_path.setTextAlignment(Qt.AlignHCenter | Qt.AlignVCenter)
item_cls = QTableWidgetItem(str(Config.CH_names[cls]))
item_cls.setTextAlignment(Qt.AlignHCenter | Qt.AlignVCenter) # 设置文本居中
item_conf = QTableWidgetItem(str(conf))
item_conf.setTextAlignment(Qt.AlignHCenter | Qt.AlignVCenter) # 设置文本居中
item_location = QTableWidgetItem(str(location)) # 目标框位置
# item_location.setTextAlignment(Qt.AlignHCenter | Qt.AlignVCenter) # 设置文本居中
self.ui.tableWidget.setItem(row_count, 0, item_id)
self.ui.tableWidget.setItem(row_count, 1, item_path)
self.ui.tableWidget.setItem(row_count, 2, item_cls)
self.ui.tableWidget.setItem(row_count, 3, item_conf)
self.ui.tableWidget.setItem(row_count, 4, item_location)
self.ui.tableWidget.scrollToBottom()
def video_stop(self):
self.cap.release()
self.timer_camera.stop()
# self.timer_info.stop()
def open_frame(self):
ret, now_img = self.cap.read()
if ret:
# 目标检测
t1 = time.time()
results = self.model(now_img)[0]
t2 = time.time()
take_time_str = '{:.3f} s'.format(t2 - t1)
self.ui.time_lb.setText(take_time_str)
location_list = results.boxes.xyxy.tolist()
self.location_list = [list(map(int, e)) for e in location_list]
cls_list = results.boxes.cls.tolist()
self.cls_list = [int(i) for i in cls_list]
self.conf_list = results.boxes.conf.tolist()
self.conf_list = ['%.2f %%' % (each * 100) for each in self.conf_list]
total_nums = len(location_list)
cls_percents = []
for i in range(2):
if total_nums!= 0 :
res = self.cls_list.count(i) / total_nums
else :
res=0
cls_percents.append(res)
self.set_percent(cls_percents)
now_img = results.plot()
# 获取缩放后的图片尺寸
self.img_width, self.img_height = self.get_resize_size(now_img)
resize_cvimg = cv2.resize(now_img, (self.img_width, self.img_height))
pix_img = tools.cvimg_to_qpiximg(resize_cvimg)
self.ui.label_show.setPixmap(pix_img)
self.ui.label_show.setAlignment(Qt.AlignCenter)
# 目标数目
target_nums = len(self.cls_list)
self.ui.label_nums.setText(str(target_nums))
# 设置目标选择下拉框
choose_list = ['全部']
target_names = [Config.names[id] + '_' + str(index) for index, id in enumerate(self.cls_list)]
choose_list = choose_list + target_names
self.ui.comboBox.clear()
self.ui.comboBox.addItems(choose_list)
if target_nums >= 1:
self.ui.type_lb.setText(Config.CH_names[self.cls_list[0]])
self.ui.label_conf.setText(str(self.conf_list[0]))
self.ui.label_xmin.setText(str(self.location_list[0][0]))
self.ui.label_ymin.setText(str(self.location_list[0][1]))
self.ui.label_xmax.setText(str(self.location_list[0][2]))
self.ui.label_ymax.setText(str(self.location_list[0][3]))
else:
self.ui.type_lb.setText('')
self.ui.label_conf.setText('')
self.ui.label_xmin.setText('')
self.ui.label_ymin.setText('')
self.ui.label_xmax.setText('')
self.ui.label_ymax.setText('')
self.tabel_info_show(self.location_list, self.cls_list, self.conf_list, path=self.org_path)
else:
self.cap.release()
self.timer_camera.stop()
def vedio_show(self):
if self.is_camera_open:
self.is_camera_open = False
self.ui.CaplineEdit.setText('摄像头未开启')
video_path = self.get_video_path()
if not video_path:
return None
self.cap = cv2.VideoCapture(video_path)
self.video_start()
self.ui.comboBox.setDisabled(True)
def camera_show(self):
self.is_camera_open = not self.is_camera_open
if self.is_camera_open:
self.ui.CaplineEdit.setText('摄像头开启')
self.cap = cv2.VideoCapture(0)
self.video_start()
self.ui.comboBox.setDisabled(True)
else:
self.ui.CaplineEdit.setText('摄像头未开启')
self.ui.label_show.setText('')
if self.cap:
self.cap.release()
cv2.destroyAllWindows()
self.ui.label_show.clear()
def get_resize_size(self, img):
_img = img.copy()
img_height, img_width , depth= _img.shape
ratio = img_width / img_height
if ratio >= self.show_width / self.show_height:
self.img_width = self.show_width
self.img_height = int(self.img_width / ratio)
else:
self.img_height = self.show_height
self.img_width = int(self.img_height * ratio)
return self.img_width, self.img_height
def save_detect_video(self):
if self.cap is None and not self.org_path:
QMessageBox.about(self, '提示', '当前没有可保存信息,请先打开图片或视频!')
return
if self.is_camera_open:
QMessageBox.about(self, '提示', '摄像头视频无法保存!')
return
if self.cap:
res = QMessageBox.information(self, '提示', '保存视频检测结果可能需要较长时间,请确认是否继续保存?',QMessageBox.Yes | QMessageBox.No , QMessageBox.Yes)
if res == QMessageBox.Yes:
self.video_stop()
com_text = self.ui.comboBox.currentText()
self.btn2Thread_object = btn2Thread(self.org_path, self.model, com_text)
self.btn2Thread_object.start()
self.btn2Thread_object.update_ui_signal.connect(self.update_process_bar)
else:
return
else:
if os.path.isfile(self.org_path):
fileName = os.path.basename(self.org_path)
name , end_name= fileName.rsplit(".",1)
save_name = name + '_detect_result.' + end_name
save_img_path = os.path.join(Config.save_path, save_name)
# 保存图片
cv2.imwrite(save_img_path, self.draw_img)
QMessageBox.about(self, '提示', '图片保存成功!\n文件路径:{}'.format(save_img_path))
else:
img_suffix = ['jpg', 'png', 'jpeg', 'bmp']
for file_name in os.listdir(self.org_path):
full_path = os.path.join(self.org_path, file_name)
if os.path.isfile(full_path) and file_name.split('.')[-1].lower() in img_suffix:
name, end_name = file_name.rsplit(".",1)
save_name = name + '_detect_result.' + end_name
save_img_path = os.path.join(Config.save_path, save_name)
results = self.model(full_path)[0]
now_img = results.plot()
# 保存图片
cv2.imwrite(save_img_path, now_img)
QMessageBox.about(self, '提示', '图片保存成功!\n文件路径:{}'.format(Config.save_path))
def update_process_bar(self,cur_num, total):
if cur_num == 1:
self.progress_bar = ProgressBar(self)
self.progress_bar.show()
if cur_num >= total:
self.progress_bar.close()
QMessageBox.about(self, '提示', '视频保存成功!\n文件在{}目录下'.format(Config.save_path))
return
if self.progress_bar.isVisible() is False:
# 点击取消保存时,终止进程
self.btn2Thread_object.stop()
return
value = int(cur_num / total *100)
self.progress_bar.setValue(cur_num, total, value)
QApplication.processEvents()
def set_percent(self, probs):
# 显示各表情概率值
items = [self.ui.progressBar, self.ui.progressBar_2]
labels = [self.ui.label_20, self.ui.label_21]
prob_values = [round(each * 100) for each in probs]
label_values = ['{:.1f}%'.format(each * 100) for each in probs]
for i in range(len(probs)):
items[i].setValue(prob_values[i])
labels[i].setText(label_values[i])
class btn2Thread(QThread):
update_ui_signal = pyqtSignal(int,int)
def __init__(self, path, model, com_text):
super(btn2Thread, self).__init__()
self.org_path = path
self.model = model
self.com_text = com_text
# 用于绘制不同颜色矩形框
self.colors = tools.Colors()
self.is_running = True # 标志位,表示线程是否正在运行
def run(self):
# VideoCapture方法是cv2库提供的读取视频方法
cap = cv2.VideoCapture(self.org_path)
# 设置需要保存视频的格式“xvid”
# 该参数是MPEG-4编码类型,文件名后缀为.avi
fourcc = cv2.VideoWriter_fourcc(*'XVID')
# 设置视频帧频
fps = cap.get(cv2.CAP_PROP_FPS)
# 设置视频大小
size = (int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)), int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)))
# VideoWriter方法是cv2库提供的保存视频方法
# 按照设置的格式来out输出
fileName = os.path.basename(self.org_path)
name, end_name = fileName.split('.')
save_name = name + '_detect_result.avi'
save_video_path = os.path.join(Config.save_path, save_name)
out = cv2.VideoWriter(save_video_path, fourcc, fps, size)
prop = cv2.CAP_PROP_FRAME_COUNT
total = int(cap.get(prop))
print("[INFO] 视频总帧数:{}".format(total))
cur_num = 0
# 确定视频打开并循环读取
while (cap.isOpened() and self.is_running):
cur_num += 1
print('当前第{}帧,总帧数{}'.format(cur_num, total))
ret, frame = cap.read()
if ret == True:
# 检测
results = self.model(frame)[0]
frame = results.plot()
out.write(frame)
self.update_ui_signal.emit(cur_num, total)
else:
break
# 释放资源
cap.release()
out.release()
def stop(self):
self.is_running = False
if __name__ == "__main__":
app = QApplication(sys.argv)
win = MainWindow()
win.show()
sys.exit(app.exec_())


















 626
626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









