




 本文深入解析了MapReduce计算框架的执行步骤,包括从原始数据到最终输出的全过程。介绍了MapTask如何读取数据并映射为KV模型,ReduceTask如何进行数据加工,以及Shuffler如何连接Map与Reduce任务,实现数据的排序和汇聚。
本文深入解析了MapReduce计算框架的执行步骤,包括从原始数据到最终输出的全过程。介绍了MapTask如何读取数据并映射为KV模型,ReduceTask如何进行数据加工,以及Shuffler如何连接Map与Reduce任务,实现数据的排序和汇聚。
MapReduce:MapTask & ReduceTask
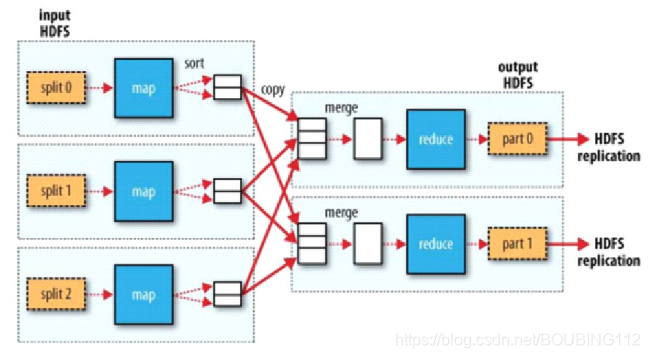
•MR的执行步骤
–原数据 ----> split -----> (input)<k1, v1> ----->map<k2, v2> ------>shuffler-----> <k2, v2>----->reduce<k3, v3>------>(output)
Hadoop 3 Mapreduce离线计算理论
•计算框架MR
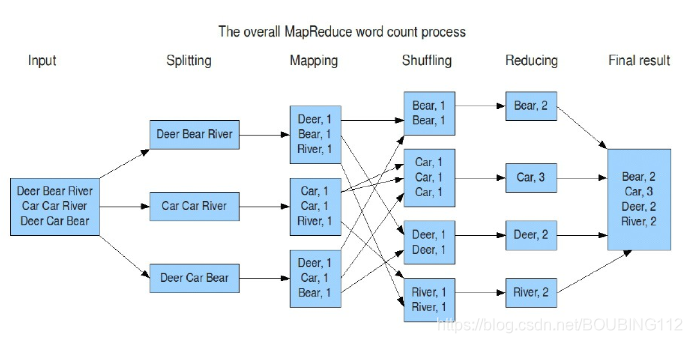
理解:
–Map:
•读懂数据
•映射为KV模型
•并行分布式
•计算向数据移动
–Reduce:
•数据全量/分量加工
•Reduce中可以包含不同的key
•相同的Key汇聚到一个Reduce中
•相同的Key调用一次reduce方法
–排序实现key的汇聚
•K,V使用自定义数据类型
–作为参数传递,节省开发成本,提高程序自由度
–Writable
序列化:使能分布式程序数据交互
–Comparable
比较器:实现具体排序(字典序,数值序等)
•Shuffler<洗牌>:框架内部实现机制
•分布式计算节点数据流转:连接MapTask与ReduceTask

















 1071
1071

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









