



 博客介绍了搭建数据仓库过程,重点讲述MapReduce应用,如wordCount等,其编程模型基于Java,分Map和Reduce阶段,数据按键值对传输,运行在Yarn容器中。还提及大数据组件,包括Hadoop生态、Storm、Spark、Flink的运行机制、实现原理及解决方案。
博客介绍了搭建数据仓库过程,重点讲述MapReduce应用,如wordCount等,其编程模型基于Java,分Map和Reduce阶段,数据按键值对传输,运行在Yarn容器中。还提及大数据组件,包括Hadoop生态、Storm、Spark、Flink的运行机制、实现原理及解决方案。
搭建数据仓库过程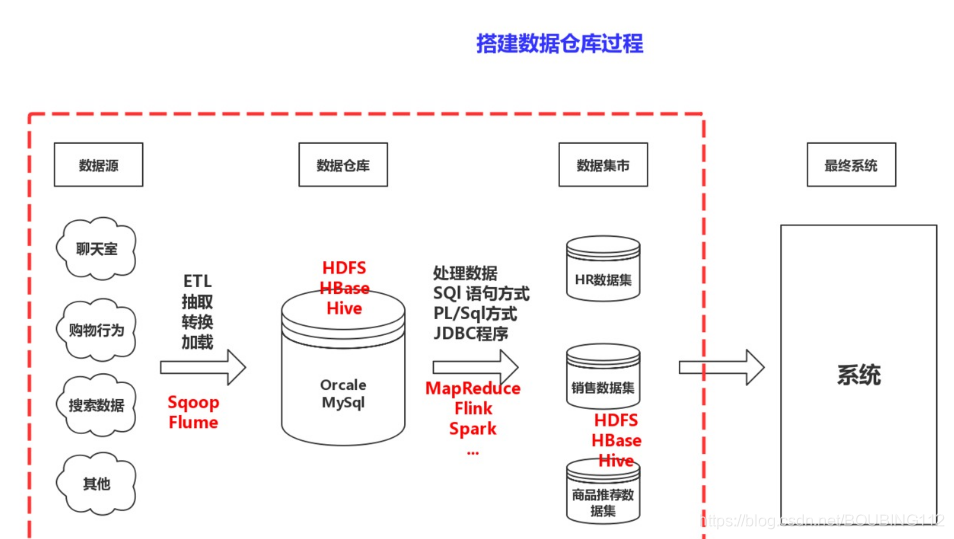
Yarn调度MR任务
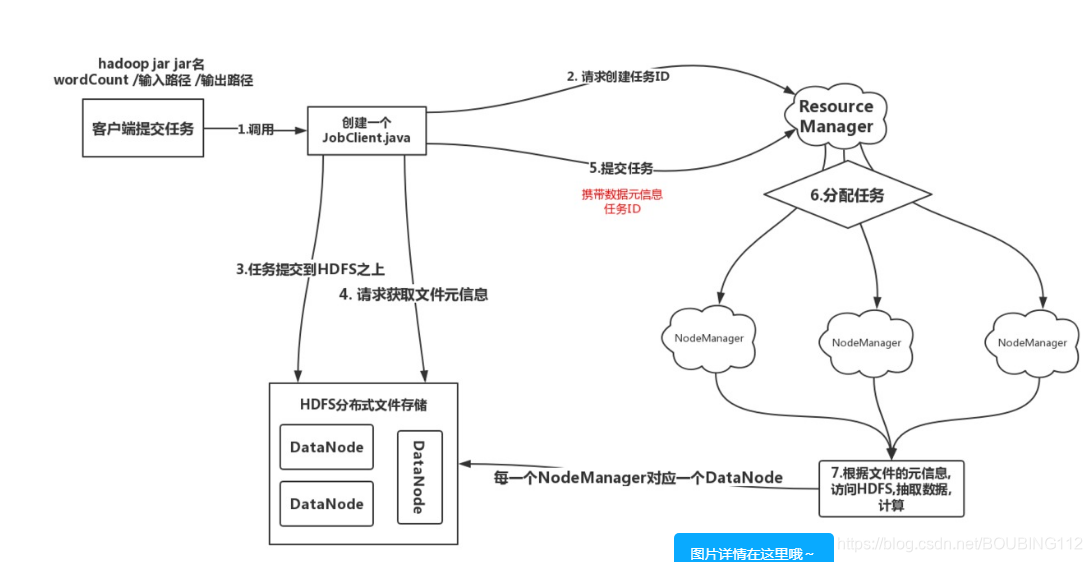
MapReduce 应用:wordCount、倒排索引、网站排名、推荐共同好友等
MapReduce 编程模型底层基于Java开发
MapReduce分为Map阶段拆分,Reduce阶段合并。
1.任务:主任务(job)=Map(拆分)+Reduce(合并)
2.处理数据来源来自于HDFS(分布式文件存储系统),结果同样存储在HDFS中
3.相对于MapReduce有两个输入和两个输出
4.MapReduce 数据按照键值对方式传输
5.相同的key会被同一个Reduce处理计算
6.数据类型都是Hadoop数据类型 String-----Test int intwritable
7.Hadoop 2.x以后MapReduce 运行在Yarn容器中
8.Map阶段的输出等于Reduce阶段的输入
大数据组件:运行机制 实现原理 实际解决方案
Hadoop生态 离线数据处理 基于Java
Storm 实时/流式处理 基于Java
Spark 离线/实时 基于批处理模拟流处理 Scala语言 基于JVM
Flink 新一代计算引擎-----实时/离线 基于流模拟批处理 Java语言

















 402
402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









