




 本文详细介绍了关系型数据库MySQL中的数据索引原理,包括磁盘读取、B+树、聚集与非聚集索引等,并探讨了如何正确使用索引以提升查询效率。此外,还讲解了Pymysql模块的使用和数据库的备份恢复方法,以及慢查询的优化策略。
本文详细介绍了关系型数据库MySQL中的数据索引原理,包括磁盘读取、B+树、聚集与非聚集索引等,并探讨了如何正确使用索引以提升查询效率。此外,还讲解了Pymysql模块的使用和数据库的备份恢复方法,以及慢查询的优化策略。
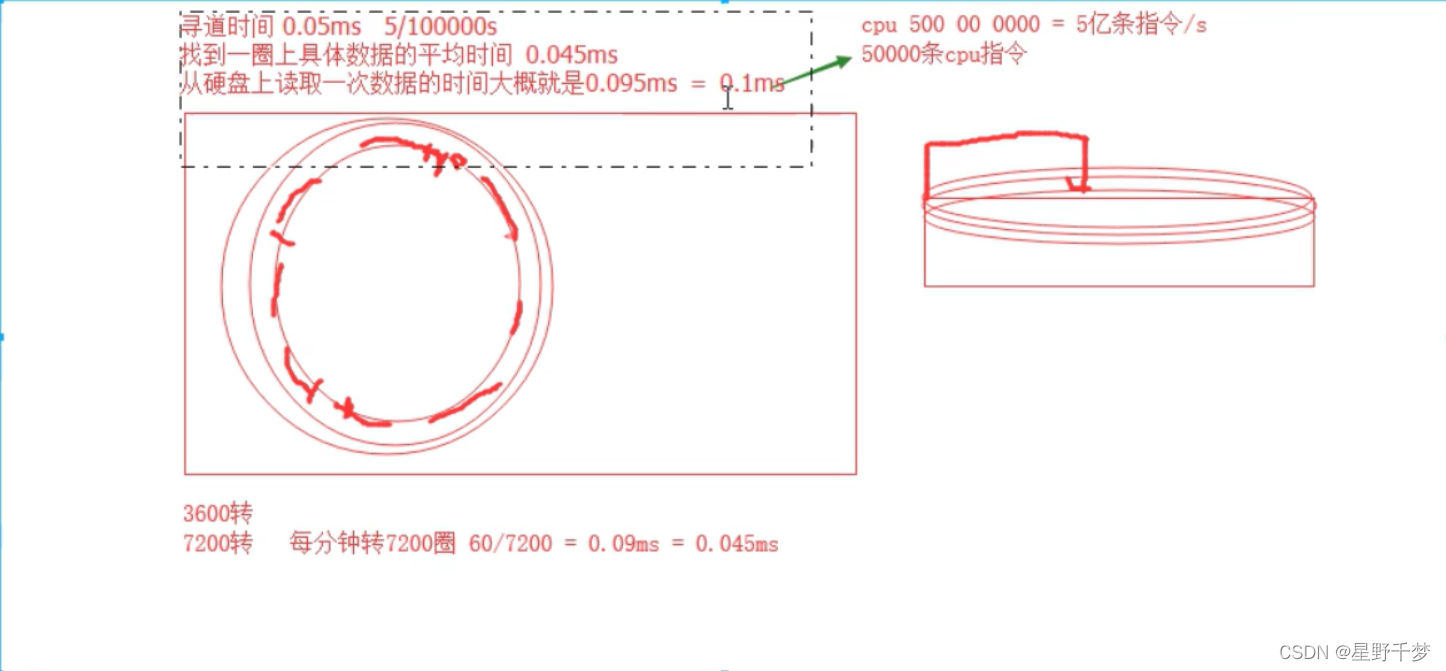
1.磁盘读取和磁盘预读
一块内容也很快就会被用到
每一次读取硬盘的单位不是你要多少就读多少
每一次读取的数据块的大小都是固定的
4096个字节 - block块
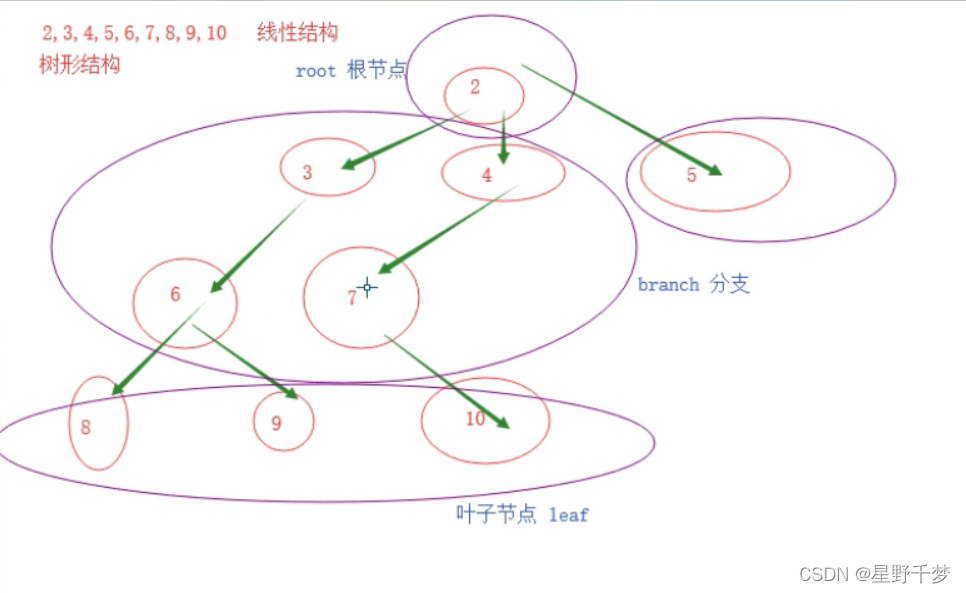
2.树
包括:
root 根节点
branch 分支节点
leaf 叶子节点
1)二叉树(每个父节点有小于等于2个子节点,左边小于父节点,右边大于父节点)
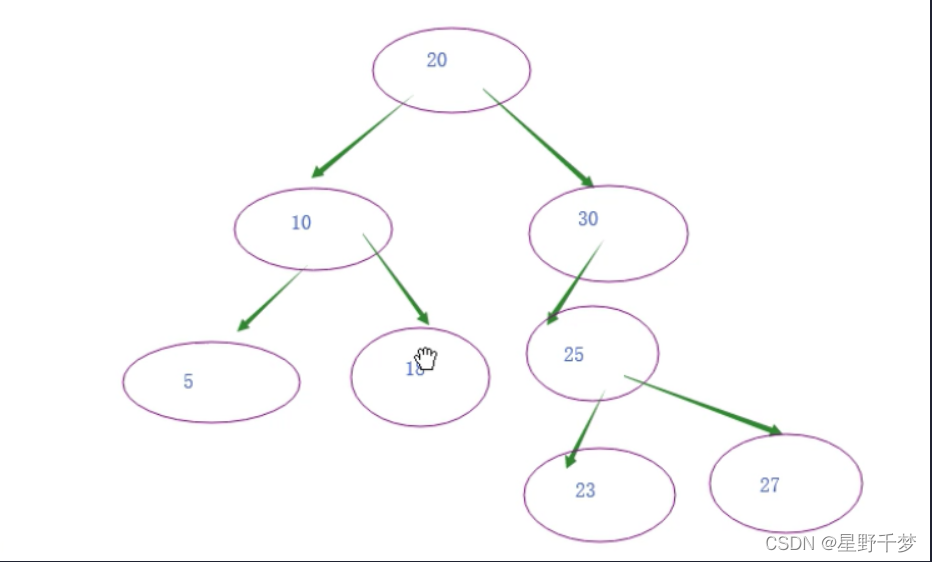
2)b+树(重点)
b是balance 平衡的意思----为了保证每一个数据查找经历的IO次数都相同
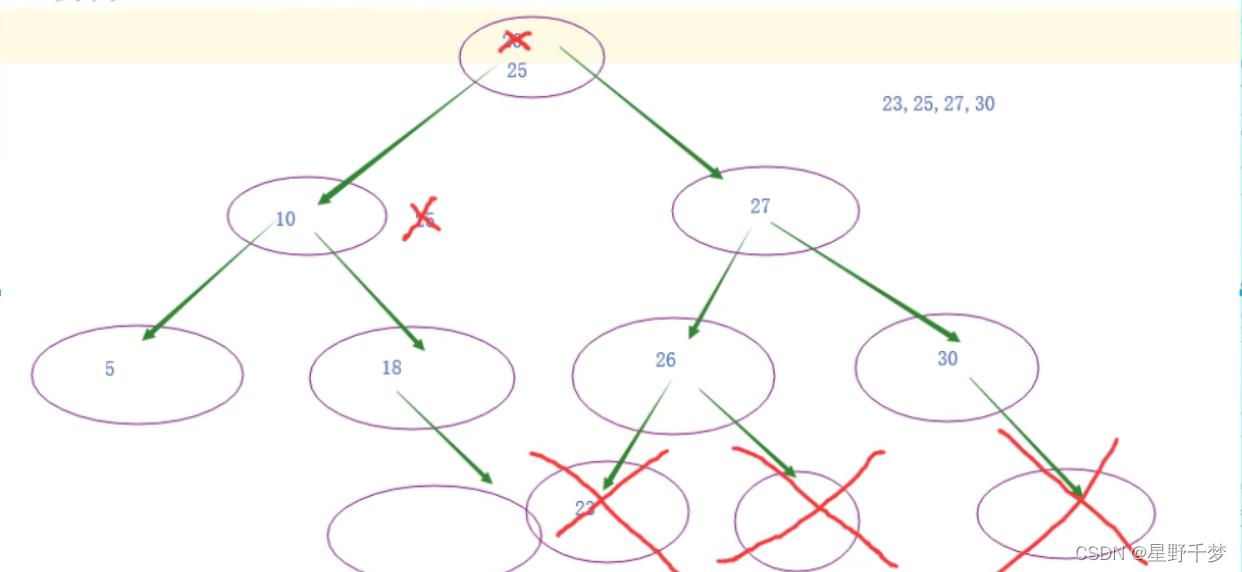
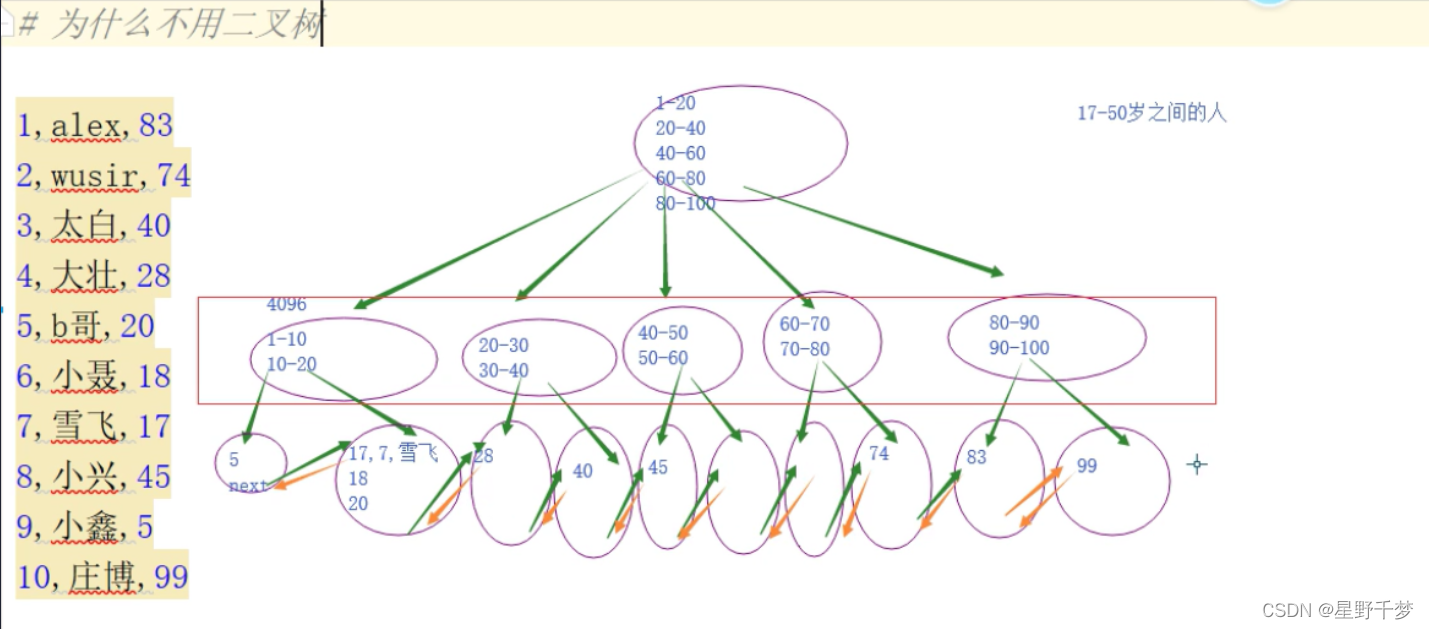
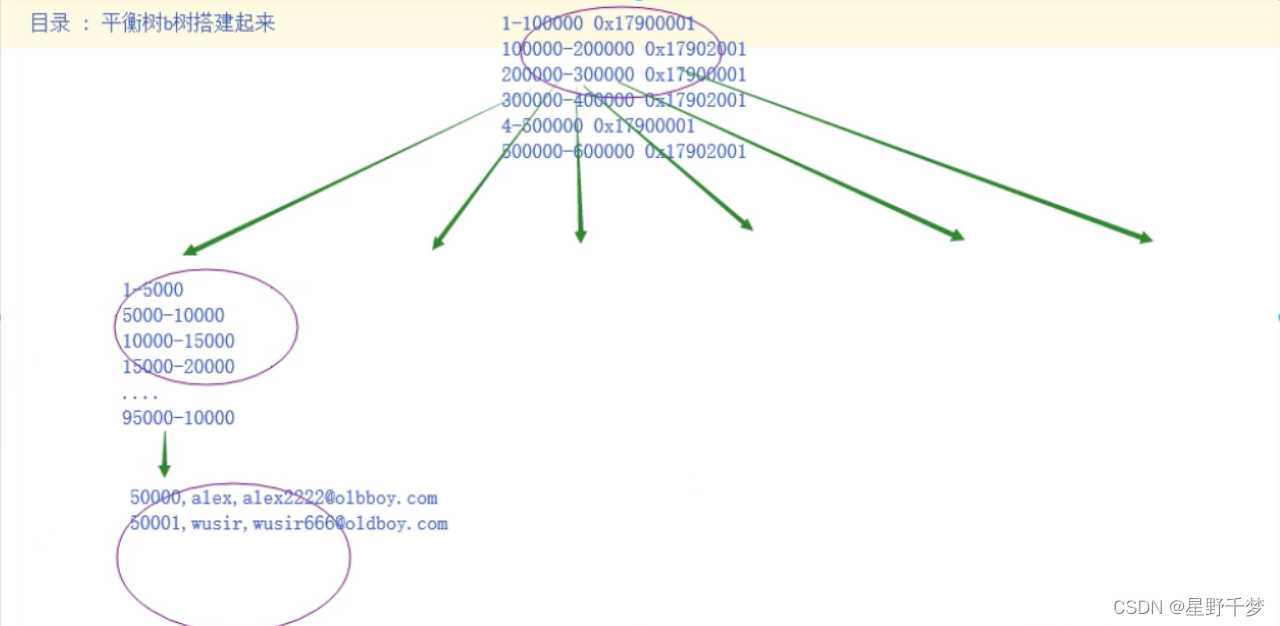
特点:
1.平衡树(btree-balance tree) 能够让查找某一个值经历的查找速度尽量平衡
2.分支节点不存储数据 ,只在叶子节点存储数据,让树的高度尽量矮,让查找一个数据的效率尽量的稳定
3.在所有叶子结点之间加入了双向的地址链接,为了查找范围的时候比较快
3)聚集索引、非聚集(簇)索引
两种索引的差别对照:
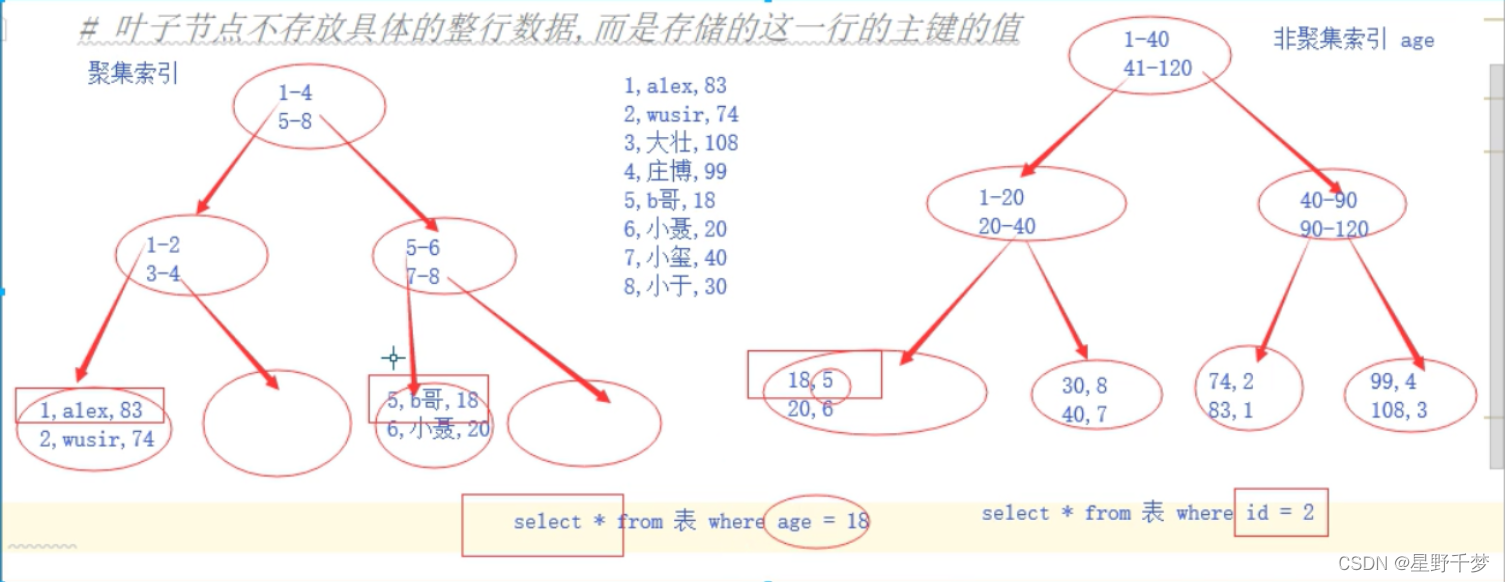
1)聚集(簇)索引(在叶子结点存真实数据)
全表数据都存储在叶子节点上 – Innodb存储引擎中的主键
Innodb必有且仅有一个 :主键
innodb存储引擎中的主键默认就会创建一个聚集索引
2)非聚集(簇)索引 又叫辅助索引(不在叶子结点存真实数据,数据的id指向真实的物理地址)
叶子节点不存放具体的整行数据,而是存储的这一行的主键的值
存在于innodb、myisam
3.正确使用索引
数据库使用的时候有什么注意事项?从搭建数据库的角度上来描述问题
1)从库的角度
1.搭建集群
2.读写分离
3.分库
2)建表的角度上
1.合理安排表关系:该拆的拆,该合的合
2.尽量把固定长度的字段放在前面
3.尽量使用char代替varchar
4.分表: 水平分,垂直分
3)使用sql语句的时候
1.尽量用where来约束数据范围到一个比较小的程度,比如说分页的时候
where a between value1 and value2
2.尽量使用连表查询而不是子查询
3.删除数据或者修改数据的时候尽量要用主键作为条件
4.合理的创建和使
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 649
649

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











