




1、安装ElasticSearch
温馨提示:初学者建议直接安装windows版本的ElasticSearch,安装包解压后就可以直接运行
windows安装ElasticSearch
1)下载ElasticSearch
选择需要的版本:例如7.17.3
# windows 7.17.3下载直接复制下方链接
https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.3-windows-x86_64.zipElasticSearch文件目录结构
| 目录 | 描述 |
| bin | 脚本文件,包括启动elasticsearch,安装插件,运行统计数据等 |
| config | 配置文件目录,如elasticsearch配置、角色配置、jvm配置等。 |
| jdk | 7.x 以后特有,自带的 java 环境,8.x版本自带 jdk 17 |
| data | 默认的数据存放目录,包含节点、分片、索引、文档的所有数据,生产环境需要修改。 |
| lib | elasticsearch依赖的Java类库 |
| logs | 默认的日志文件存储路径,生产环境需要修改。 |
| modules | 包含所有的Elasticsearch模块,如Cluster、Discovery、Indices等。 |
| plugins | 已安装插件目录 |
2)配置JDK环境
- ES比较耗内存,建议虚拟机4G或以上内存,jvm1g以上的内存分配
- 运行Elasticsearch,需安装并配置JDK。各个版本对Java的依赖 Support Matrix | ElasticThe tables below display platform and software configurations that are eligible for support under oursubscription offerings. Learn more about ourSupport Policy and product End of Life poli...
 https://www.elastic.co/support/matrix#matrix_jvm
https://www.elastic.co/support/matrix#matrix_jvm
- Elasticsearch 5需要Java 8以上的版本
- Elasticsearch 从6.5开始支持Java 11
- 7.0开始,内置了Java环境。ES的JDK环境变量生效的优先级配置顺序ES_JAVA_HOME>JAVA_HOME>ES_HOME
- ES_JAVA_HOME:这个环境变量用于指定Elasticsearch使用的Java运行时环境的路径。在启动Elasticsearch时,它会检查ES_JAVA_HOME环境变量并使用其中的Java路径。
- ES_HOME:这个环境变量指定Elasticsearch的安装路径。它用于定位Elasticsearch的配置文件、插件和其他相关资源。设置ES_HOME环境变量可以让您在命令行中更方便地访问Elasticsearch的目录结构和文件。
可以参考es的环境文件elasticsearch-env.bat

windows下,设置ES_JAVA_HOME和ES_HOME的环境变量

3)启动ElasticSearch服务
进入bin目录,直接运行elasticsearch.bat
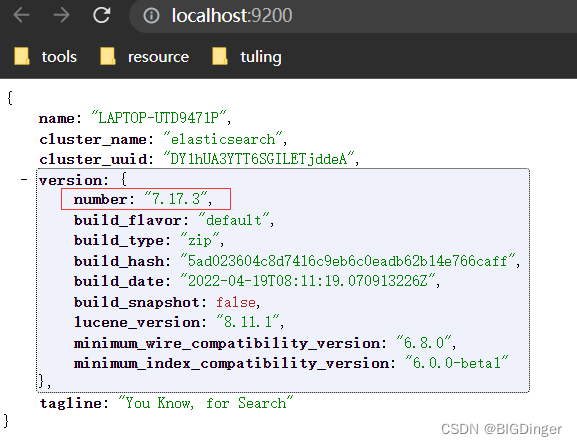
测试,浏览器中访问:http://localhost:9200/
centos7安装ElasticSearch
centos7中ES环境搭建视频:
1)下载ElasticSearch
# centos7 下载直接复制下方链接
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.17.3-linux-x86_64.tar.gz2)配置JDK环境
# linux 进入用户主目录,比如/home/es目录下,设置用户级别的环境变量
vim .bash_profile
#设置ES_JAVA_HOME和ES_HOME的路径
export ES_JAVA_HOME=/home/es/elasticsearch-7.17.3/jdk/
export ES_HOME=/home/es/elasticsearch-7.17.3
#执行以下命令使配置生效
source .bash_profile3) 配置ElasticSearch
修改elasticsearch.yml配置
vim elasticsearch.yml
#开启远程访问
network.host: 0.0.0.0
#单节点模式 初学者建议设置为此模式
discovery.type: single-nodeElasticSearch配置参数
参考: Important Elasticsearch configuration | Elasticsearch Guide [7.17] | Elastic
- cluster.name
当前节点所属集群名称,多个节点如果要组成同一个集群,那么集群名称一定要配置成相同。默认值elasticsearch,生产环境建议根据ES集群的使用目的修改成合适的名字。不要在不同的环境中重用相同的集群名称,否则,节点可能会加入错误的集群。
- node.name
当前节点名称,默认值当前节点部署所在机器的主机名,所以如果一台机器上要起多个ES节点的话,需要通过配置该属性明确指定不同的节点名称。
- path.data
配置数据存储目录,比如索引数据等,默认值 $ES_HOME/data,生产环境下强烈建议部署到另外的安全目录,防止ES升级导致数据被误删除。
- path.logs
配置日志存储目录,比如运行日志和集群健康信息等,默认值 $ES_HOME/logs,生产环境下强烈建议部署到另外的安全目录,防止ES升级导致数据被误删除。
- bootstrap.memory_lock
配置ES启动时是否进行内存锁定检查,默认值true。
ES对于内存的需求比较大,一般生产环境建议配置大内存,如果内存不足,容易导致内存交换到磁盘,严重影响ES的性能。所以默认启动时进行相应大小内存的锁定,如果无法锁定则会启动失败。
非生产环境可能机器内存本身就很小,能够供给ES使用的就更小,如果该参数配置为true的话很可能导致无法锁定内存以致ES无法成功启动,此时可以修改为false。
- network.host
节点对外提供服务的地址以及集群内通信的ip地址,默认值为当前节点所在机器的本机回环地址127.0.0.1 和[::1],这就导致默认情况下只能通过当前节点所在主机访问当前节点。
- http.port
配置当前ES节点对外提供服务的http端口,默认 9200
- transport.port:
节点通信端口号,默认 9300
- discovery.seed_hosts
配置参与集群节点发现过程的主机列表,说白一点就是集群中所有节点所在的主机列表,可以是具体的IP地址,也可以是可解析的域名。
- cluster.initial_master_nodes
配置ES集群初始化时参与master选举的节点名称列表,必须与node.name配置的一致。ES集群首次构建完成后,应该将集群中所有节点的配置文件中的cluster.initial_master_nodes配置项移除,重启集群或者将新节点加入某个已存在的集群时切记不要设置该配置项。
4) 配置JVM参数
修改config/jvm.options配置文件,调整jvm堆内存大小
vim jvm.options
-Xms4g
-Xmx4g配置的建议
- Xms和Xms设置成—样
- Xmx不要超过机器内存的50%
- 不要超过30GB - A Heap of Trouble: Managing Elasticsearch's Managed Heap | Elastic Blog
5)启动ElasticSearch服务
ES不允许使用root账号启动服务,如果你当前账号是root,则需要创建一个专有账户
#非root用户启动
bin/elasticsearch
# -d 后台启动
bin/elasticsearch -d
注意:es默认不能用root用户启动,生产环境建议为elasticsearch创建用户。
# 为elaticsearch创建用户并赋予相应权限
adduser es
passwd es
# 切换成自己的elasticsearch路径
chown -R es:es elasticsearch-7.17.3 6)启动ES服务常见错误解决方案
如果ES服务启动异常,会有提示:

[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
ES因为需要大量的创建索引文件,需要大量的打开系统的文件,所以我们需要解除linux系统当中打开文件最大数目的限制,不然ES启动就会抛错
#切换到root用户
vim /etc/security/limits.conf
末尾添加如下配置(切记*不能省略):
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096[2]: max number of threads [1024] for user [es] is too low, increase to at least [4096]
无法创建本地线程问题,用户最大可创建线程数太小
vim /etc/security/limits.d/20-nproc.conf
改为如下配置:
* soft nproc 4096[3]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
最大虚拟内存太小,调大系统的虚拟内存
vim /etc/sysctl.conf
追加以下内容:
vm.max_map_count=262144
保存退出之后执行如下命令:
sysctl -p[4]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
缺少默认配置,至少需要配置discovery.seed_hosts/discovery.seed_providers/cluster.initial_master_nodes中的一个参数.
- discovery.seed_hosts: 集群主机列表
- discovery.seed_providers: 基于配置文件配置集群主机列表
- cluster.initial_master_nodes: 启动时初始化的参与选主的node,生产环境必填
vim config/elasticsearch.yml
#添加配置
discovery.seed_hosts: ["127.0.0.1"]
cluster.initial_master_nodes: ["node-1"]
#或者指定配置单节点(集群单节点)
discovery.type: single-node2、客户端Kibana安装
Kibana是一个开源分析和可视化平台,旨在与Elasticsearch协同工作。
参考文档:Quick start | Kibana Guide [7.17] | Elastic
1)下载并解压缩Kibana
下载地址:Past Releases of Elastic Stack Software | Elastic
选择版本:7.17.3
#windows
https://artifacts.elastic.co/downloads/kibana/kibana-7.17.3-windows-x86_64.zip
#linux
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.17.3-linux-x86_64.tar.gz2)修改Kibana.yml
vim config/kibana.yml
server.port: 5601 #指定Kibana服务器监听的端口号
server.host: "localhost" #指定Kibana服务器绑定的主机地址
elasticsearch.hosts: ["http://localhost:9200"] #指定Kibana连接到的Elasticsearch实例的访问地址
i18n.locale: "zh-CN" #将 Kibana 的界面语言设置为简体中文3)运行Kibana
windows
直接执行kibana.bat
Linux
注意:kibana也需要非root用户启动
bin/kibana
#后台启动
nohup bin/kibana &
#查询kibana进程
netstat -tunlp | grep 56014)访问Kibana
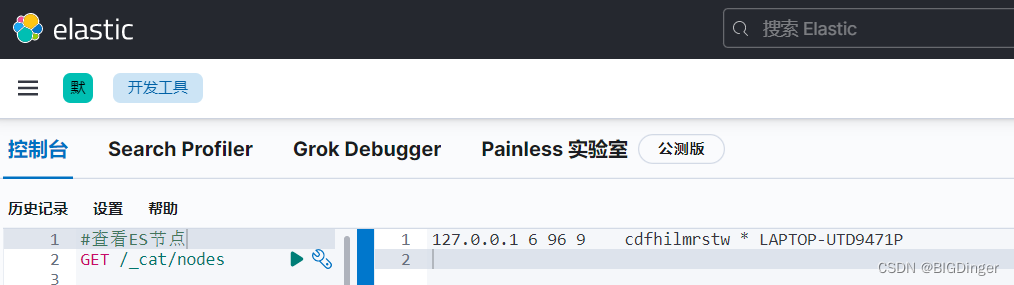
http://localhost:5601/app/dev_tools#/console
cat API
cat API 是 Elasticsearch 提供的一个用于查看和显示集群信息的 RESTful API。它可以用于获取关于索引、节点、分片、健康状态等各种集群相关的信息。
/_cat/allocation #查看单节点的shard分配整体情况
/_cat/shards #查看各shard的详细情况
/_cat/shards/{index} #查看指定分片的详细情况
/_cat/master #查看master节点信息
/_cat/nodes #查看所有节点信息
/_cat/indices #查看集群中所有index的详细信息
/_cat/indices/{index} #查看集群中指定index的详细信息
/_cat/segments #查看各index的segment详细信息,包括segment名, 所属shard, 内存(磁盘)占用大小, 是否刷盘
/_cat/segments/{index}#查看指定index的segment详细信息
/_cat/count #查看当前集群的doc数量
/_cat/count/{index} #查看指定索引的doc数量
/_cat/recovery #查看集群内每个shard的recovery过程.调整replica。
/_cat/recovery/{index}#查看指定索引shard的recovery过程
/_cat/health #查看集群当前状态:红、黄、绿
/_cat/pending_tasks #查看当前集群的pending task
/_cat/aliases #查看集群中所有alias信息,路由配置等
/_cat/aliases/{alias} #查看指定索引的alias信息
/_cat/thread_pool #查看集群各节点内部不同类型的threadpool的统计信息,
/_cat/plugins #查看集群各个节点上的plugin信息
/_cat/fielddata #查看当前集群各个节点的fielddata内存使用情况
/_cat/fielddata/{fields} #查看指定field的内存使用情况,里面传field属性对应的值
/_cat/nodeattrs #查看单节点的自定义属性
/_cat/repositories #输出集群中注册快照存储库
/_cat/templates #输出当前正在存在的模板信息3、Elasticsearch安装分词插件
Elasticsearch提供插件机制对系统进行扩展,以安装分词插件为例:
在线安装analysis-icu分词插件
#查看已安装插件
bin/elasticsearch-plugin list
#安装插件
bin/elasticsearch-plugin install analysis-icu
#删除插件
bin/elasticsearch-plugin remove analysis-icu注意:安装和删除完插件后,需要重启ES服务才能生效。
测试分词效果
# _analyzer API可以用来查看指定分词器的分词结果
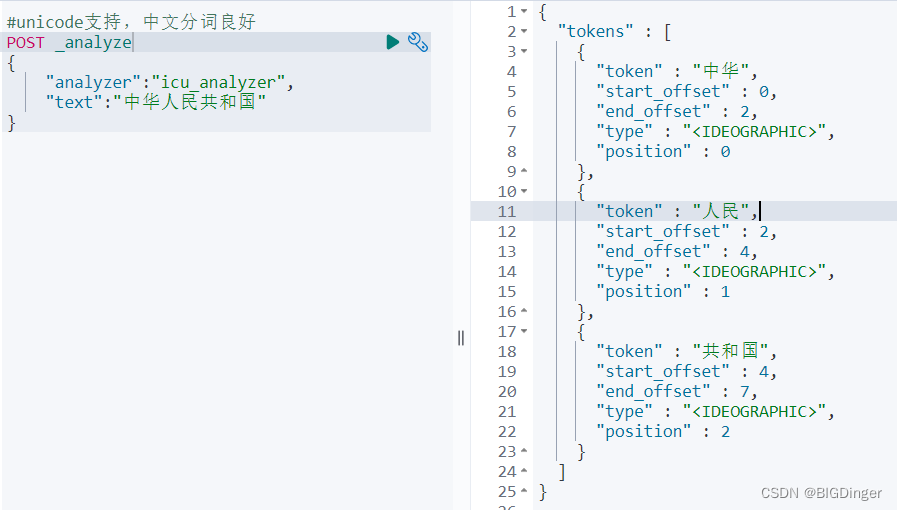
POST _analyze
{
"analyzer":"icu_analyzer",
"text":"中华人民共和国"
}
离线安装ik中文分词插件
本地下载elasticsearch-analysis-ik-7.17.3.zip插件,解压,然后手动上传到elasticsearch的plugins目录,然后重启ES实例就可以了。
测试分词效果
#ES的默认分词设置是standard,会单字拆分
POST _analyze
{
"analyzer":"standard",
"text":"中华人民共和国"
}
#ik_smart:会做最粗粒度的拆
POST _analyze
{
"analyzer": "ik_smart",
"text": "中华人民共和国"
}
#ik_max_word:会将文本做最细粒度的拆分
POST _analyze
{
"analyzer":"ik_max_word",
"text":"中华人民共和国"
}


















 1023
1023

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









