



 本文介绍了ElasticSearch的QueryScore功能,用于在原始查询打分后对Top-N文档进行二次打分,提高排序性能。通过设置窗口大小和权重调整原始和二次打分的贡献,以及在Java客户端中的使用示例。
本文介绍了ElasticSearch的QueryScore功能,用于在原始查询打分后对Top-N文档进行二次打分,提高排序性能。通过设置窗口大小和权重调整原始和二次打分的贡献,以及在Java客户端中的使用示例。
二次打分
之前文章写的Script Score的搜索打分是针对整个匹配结果集的,如果一个搜索匹配了几十万个文档,对着文档使用过Function Score或者Script Score查询进行打分是非常耗时的,整个排序性能大打折扣。针对这种情况,ElasticSearch提供了Query Score功能作为折中方案,它支持只针对返回文档的一部分文档进行打分。
1.1 二次打分简介
Query Score工作的阶段是在原始查询打分之后,它支持对打分后Top-N的文档集合执行第二次查询和打分。通过设置window_size参数可以控制在每个分片上进行二次打分查询的文档数量,在默认情况下window_size的值为10。在默认情况下,文档的最终得分等于原查询和rescore查询的分数之和。当然,还可以使用参数对这两部分的权重进行控制。
1.2 使用示例
索引结构和数据如下:
json
复制代码
PUT /hotel_painless { "mappings": { "properties": { "title":{ "type": "text" }, "price":{ "type": "double" }, "create_time":{ "type": "date" }, "full_room":{ "type": "boolean" }, "location":{ "type": "geo_point" }, "doc_weight":{ "type": "integer" }, "tags":{ "type": "keyword" }, "comment_info":{ //定义comment_info字段类型为object "properties": { "favourable_comment":{ //定义favourable_comment字段类型为integer "type":"integer" }, "negative_comment":{ "type":"integer" } } }, "hotel_vector":{ //定义hotel_vector字段类型为dense_vector "type": "dense_vector", "dims":5 } } } }
bash
复制代码
POST /_bulk {"index":{"_index":"hotel_painless","_id":"001"}} {"title":"文雅假日酒店","price":556.00,"create_time":"20200418120000","full_room":false,"location":{"lat":36.083078,"lon":120.37566},"doc_weight":30,"tags":["wifi","小型电影院"],"comment_info":{"favourable_comment":20,"negative_comment":10},"hotel_vector":[0,3.2,5.8,1.2,0]} {"index":{"_index":"hotel_painless","_id":"002"}} {"title":"金都嘉怡假日酒店","price":337.00,"create_time":"20210315200000","full_room":false,"location":{"lat":39.915153,"lon":116.4030},"doc_weight":10,"tags":["wifi","免费早餐"],"comment_info":{"favourable_comment":20,"negative_comment":10},"hotel_vector":[0.7,9.2,5.3,1.2,12.3]} {"index":{"_index":"hotel_painless","_id":"003"}} {"title":"金都欣欣酒店","price":200.00,"create_time":"20210509160000","full_room":true,"location":{"lat":39.186555,"lon":117.162007},"doc_weight":10,"tags":["会议厅","免费车位"],"comment_info":{"favourable_comment":20,"negative_comment":10},"hotel_vector":[6,3.2,0.4,9.3,0]} {"index":{"_index":"hotel_painless","_id":"004"}} {"title":"金都家至酒店","price":500.00,"create_time":"20210218080000","full_room":true,"location":{"lat":39.915343,"lon":116.422011},"doc_weight":50,"tags":["wifi","免费车位"],"comment_info":{"favourable_comment":20,"negative_comment":10},"hotel_vector":[0.7,3.2,5.1,2.9,0.1]} {"index":{"_index":"hotel_painless","_id":"005"}} {"title":"文雅精选酒店","price":800.00,"create_time":"20210101080000","full_room":true,"location":{"lat":39.918229,"lon":116.422011},"doc_weight":70,"tags":["wifi","充电车位"],"comment_info":{"favourable_comment":20,"negative_comment":10},"hotel_vector":[12.1,5.2,5.1,9.2,4.5]}
现在有一个比较简单的查询:查询价格大于300元的酒店,DSL如下:
bash
复制代码
GET /hotel_painless/_search { "query": { "range": { "price": { "gte": 300 } } } }
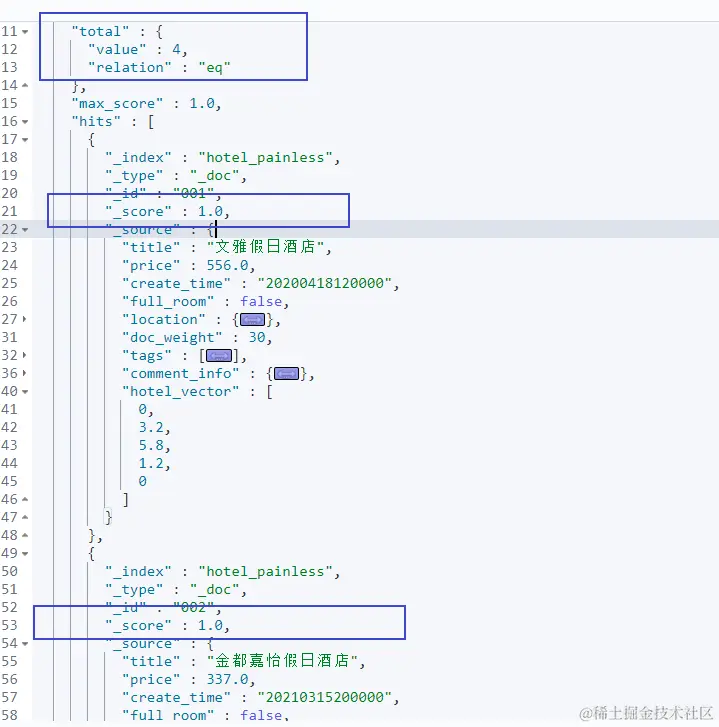
从结果中可看出,索引中有5个文档,匹配的文档书为4。因为使用的是范围查询,所以匹配的文档得分都为1.如果想提升在上述排序中前两个名称包含“金都”的酒店文档排名。而这两个目标酒店的位置分别为2和3,当前的索引主分片数为1,那么应该设置window_size=3,使用二次打分对查询进行扩展的DSL如下:
json
复制代码
GET /hotel_painless/_search { "query": { "range": { "price": { //使用range查询 "gte": 300 } } }, "rescore": { "query": { //对返回的文档进行二次打分 "rescore_query":{ "match":{ "title":"金都" } } }, "window_size": 3 //对每个分片的前3个文档进行二次打分 } }
在上面的DSL中,二次打分使用rescore进行封装,在rescore中可以设置二次打分的查询query和window_size,window_size设置为3意味着对每个分片的前3个文档进行二次打分,执行上述DSL的结果如下:
json
复制代码
{ ... "hits" : { "total" : { "value" : 4, "relation" : "eq" }, "max_score" : 2.1062784, "hits" : [ { "_index" : "hotel_painless", "_type" : "_doc", "_id" : "004", "_score" : 2.1062784, "_source" : { "title" : "金都家至酒店", "price" : 500.0, ... } }, { "_index" : "hotel_painless", "_type" : "_doc", "_id" : "002", "_score" : 1.977973, "_source" : { "title" : "金都嘉怡假日酒店", "price" : 337.0, ... } }, { "_index" : "hotel_painless", "_type" : "_doc", "_id" : "001", "_score" : 1.0, "_source" : { "title" : "文雅假日酒店", "price" : 556.0, } }, { "_index" : "hotel_painless", "_type" : "_doc", "_id" : "005", "_score" : 1.0, "_source" : { "title" : "文雅精选酒店", ... } } ] } }
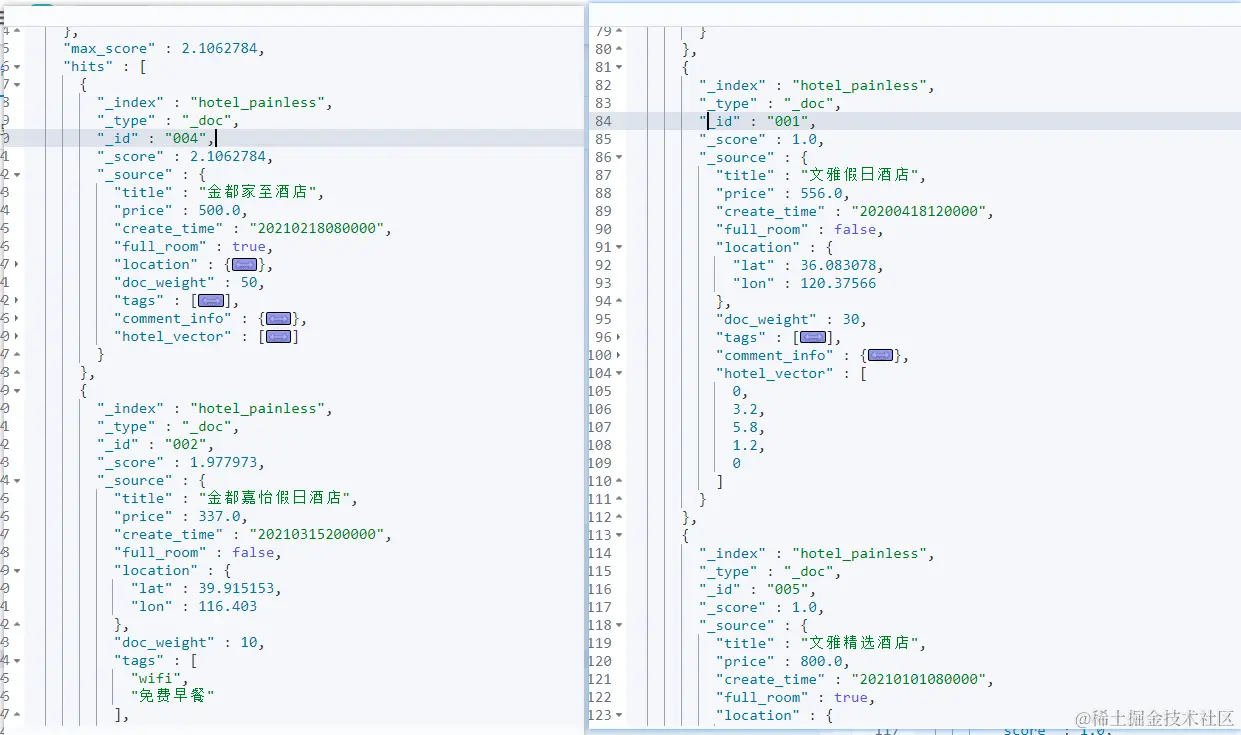
通过对比rescore前后的结果可以看到,原有文档的002和004分别排在第二位和第三位,并且得分都是1。在rescore的查询中对TOP3且标题含有“金都”的文档进行了加分操作,因此文档002和文档004的得分得到了提升。因为文档004的标题更短,所以它的分数相对更高一些,处在第一个位置,文档002处在第二个位置。
在默认情况下,当存在二次打分时,文档得分=原始查询分数+二次打分分数文档得分=原始查询分数+二次打分分数
而用户额可以为这两部分的分数设置权重,所以文档得分=原始查询分数×原始查询权重+二次打分分数×二次打分权重文档得分=原始查询分数×原始查询权重+二次打分分数×二次打分权重
可以分别设置query_weight和rescore_query_weight,为原始查询权重和二次打分权重赋值,例如下面的DSL设置原始查询权重为0.6,二次打分权重为1.7:
bash
复制代码
GET /hotel_painless/_search { "query": { "range": { "price": { "gte": 300 } } }, "rescore": { "query": { "rescore_query": { "match": { "title": "金都" } }, "query_weight": 0.6, "rescore_query_weight": 1.7 }, "window_size": 3 } }
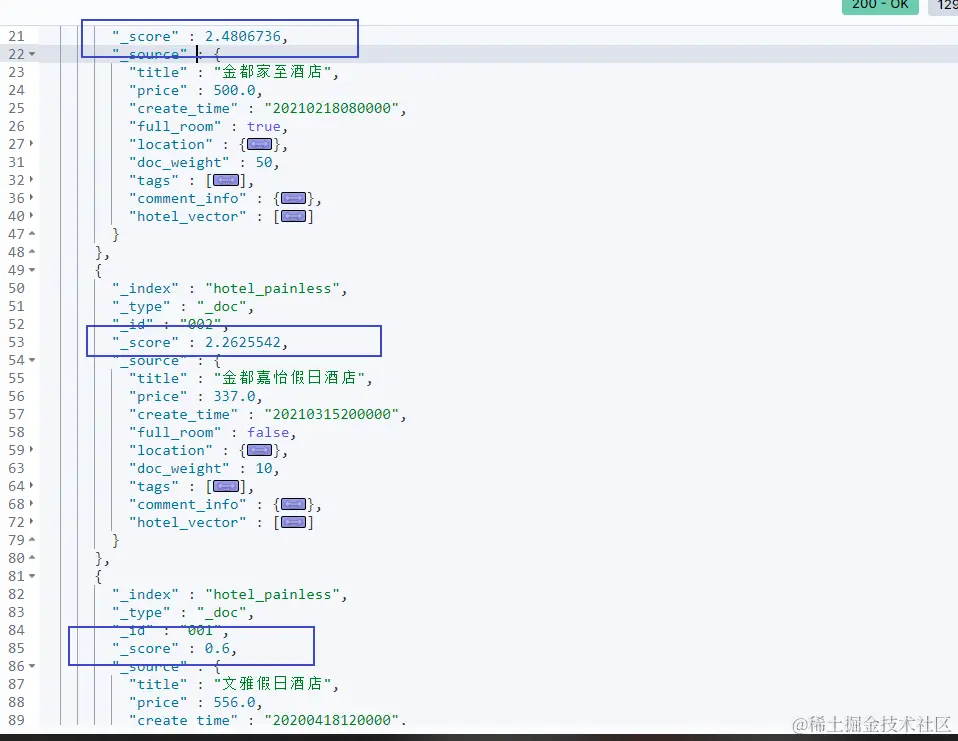
1.3 在Java客户端中使用二次打分
scss
复制代码
@Test public void getRescoreQuery(){ //构建原始的range查询 RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("price") .gte(300); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); searchSourceBuilder.query(rangeQueryBuilder);//添加原始查询Builder //构建二次打分的查询 MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("title", "金都"); //构建二次打分Builder QueryRescorerBuilder queryRescorerBuilder = new QueryRescorerBuilder(matchQueryBuilder); queryRescorerBuilder.setQueryWeight(0.6f); //设置原始打分权重 queryRescorerBuilder.setRescoreQueryWeight(1.7f); //设置二次打分权重 queryRescorerBuilder.windowSize(3); //设置每个分片参加二次打分文档的个数 //添加二次打分Builder searchSourceBuilder.addRescorer(queryRescorerBuilder); //创建搜索请求 SearchRequest searchRequest = new SearchRequest("hotel_painless"); searchRequest.source(searchSourceBuilder);//设置查询请求 printResult(searchRequest); //打印搜索结果 } //打印方法封装,方便查看结果 public void printResult(SearchRequest searchRequest) { try { //执行搜索 SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT); //获取搜索结果集 SearchHits searchHits = searchResponse.getHits(); for (SearchHit searchHit : searchHits) { String index=searchHit.getIndex(); //获取索引名称 String id=searchHit.getId(); //获取文档_id float score = searchHit.getScore(); //获取得分 String source = searchHit.getSourceAsString();//获取文档内容 System.out.println("index="+index+",id="+id+",score="+score+",source="+source); } } catch (IOException e) { throw new RuntimeException(e); } }


















 425
425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









