



 本文详细探讨了数组作为数据结构的基础概念,包括其线性与非线性特性,内存寻址机制,以及插入、删除操作的时间复杂度分析。特别强调了数组下标随机访问的高效性,以及在Go语言中的注意事项,如数组越界和优化删除操作的方法。
本文详细探讨了数组作为数据结构的基础概念,包括其线性与非线性特性,内存寻址机制,以及插入、删除操作的时间复杂度分析。特别强调了数组下标随机访问的高效性,以及在Go语言中的注意事项,如数组越界和优化删除操作的方法。
数组
数组数据结构(英语:array data structure),简称数组(英语:Array),是由相同类型的元素(element)的集合所组成的数据结构,分配一块连续的内存来存储。利用元素的索引(index)可以计算出该元素对应的存储地址。
简单归纳下,数组是一种线性数据结构,用一段连续的存储空间,用来存储一类相同数据类型的元素。
线性表
线性表(Linear List)是一种基本的数据结构,它是由n(n≥0)个数据元素构成的有限序列。数据元素之间存在着一种顺序关系,可以理解成这些数据之间连成了一条线。
常见的线性表数据结构有以下这些:数组、链表(单链表、双向链表、循环链表)、栈、队列。
非线性表
和线性表相反,非线性表是一种没有顺序的,准确的说非线性表的结构不局限于一对一的关系,而是可以是一对多、多对一或多对多的关系。即一个数据元素可能有多个直接前驱元素或直接后继元素。
常见的非线性表数据结构有:二叉树、堆、图、hash表等。
连续的内存空间
数组的内存空间是连续的,内存分配后是一段连续的地址。写几行代码验证下。
css
复制代码
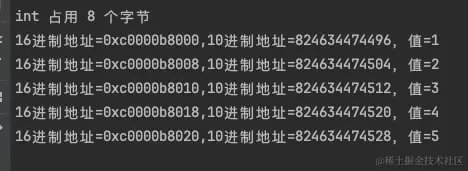
func TestArray(t *testing.T) { var x int size := unsafe.Sizeof(x) fmt.Printf("int 占用 %d 个字节\n", size) tp := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12} for i := 0; i < len(tp); i++ { fmt.Println(fmt.Sprintf("16进制地址=%p,10进制地址=%d,值=%+v", &tp[i], uintptr(unsafe.Pointer(&tp[i])), tp[i])) // 以10和16进制方式打印 } }
int 占 8 个字节
上段代码结果输出如下:
diff
复制代码
=== RUN TestArray int 占用 8 个字节 16进制地址=0xc00011e240,10进制地址=824634892864,值=1 16进制地址=0xc00011e248,10进制地址=824634892872,值=2 16进制地址=0xc00011e250,10进制地址=824634892880,值=3 16进制地址=0xc00011e258,10进制地址=824634892888,值=4 16进制地址=0xc00011e260,10进制地址=824634892896,值=5 16进制地址=0xc00011e268,10进制地址=824634892904,值=6 16进制地址=0xc00011e270,10进制地址=824634892912,值=7 16进制地址=0xc00011e278,10进制地址=824634892920,值=8 16进制地址=0xc00011e280,10进制地址=824634892928,值=9 16进制地址=0xc00011e288,10进制地址=824634892936,值=10 16进制地址=0xc00011e290,10进制地址=824634892944,值=11 16进制地址=0xc00011e298,10进制地址=824634892952,值=12 --- PASS: TestArray (0.00s) PASS
10进制地址可以看出,起始地址是:824634892864,后续的地址依次加 8,就是下一个元素的地址。
数组的最强杀招,“下标随机访问”。直接通过元素的下标来获取数组中的元素,不需遍历整个数组。所以,数组在查找、访问和修改特定元素时具有高效性,时间复杂度为 O(1)。
但是,数组的某些操作也会非常慢,比如:插入、删除、移动,为了保证连续性,会移动大量元素。如果,你的业务不需要保证连续性,那性能也可以非常高的。
数组寻址
上段代码打印了数组的连续内存地址,你看出来数组是怎么寻址的?
举一个简单例子,创建一个长度为5的数组,假设起始地址(基地址)为0xc0000b8000,连续的内存空间0xc0000b8000-0xc0000b8020,这个是16进制看起来不是很方便,可以用 10 进制好算一些。
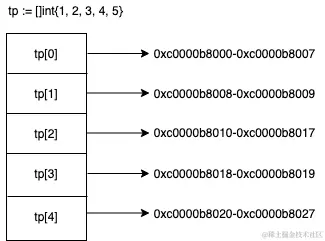
计算机会给每个内存单元分配一个地址,通过地址来访问内存中的数据。当计算机需要通过数组下标访问数组中的某个数据时,需要通过下面的公式计算。(注:你在使用数组过程中基本都是通过下标或者遍历得到了最终值,复杂的寻址过程语言层面已经帮你处理好了。)
css
复制代码
address=基地址+i*type_size
type_size 是数组中每个元素的字节大小,也就是数组中存储的数据类型的大小;
i 是数组中要访问的元素的索引,即下标值;
基地址 是数组的起始内存地址,即数组中第一个元素的地址;
划重点:数组数组结构的特性是支持下标随机访问,根据下标随机访问的时间复杂度为 O(1)。非下标访问的方式如果用二分查找时间复杂度是O(logn),若通过遍历的方式,最好时间复杂度为O(1),最坏时间复杂度为O(n)。
聊聊数元素组插入
假设一个数组长度是 x,我们要在 y 的位置插入一个数据 v,需要把 y~x 位置的数据分别往后挪动1位。我们先分析下时间复杂度。
1. 最好情况时间复杂度:如果在数组的末尾(x-1)进行插入操作,即插入位置是数组的尾部,那么时间复杂度为 O(1)。在这种情况下,不需要移动其他元素,只需将新元素直接放在数组的末尾。
2. 最坏情况时间复杂度:在数组头(0位置)插入,需要把所有移动移动一个位置,不考虑扩容假设内存空间够用。时间复杂度为O(n)。
3. 平均时间复杂度:平均情况下的时间复杂度取决于插入位置的分布情况。如果插入位置随机分布在数组中,那么平均情况下的时间复杂度仍然为 O(n),因为大约一半的情况下会需要移动一半的元素。
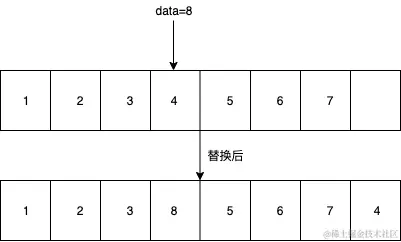
当然,我上面讲过,如果你不在乎替换后数组的连续性,可以按下面这种操作。时间复杂度为O(1)。
聊聊数组元素的删除
数组元素删除和插入都是类似的,当插入元素是,元素可能会后移;删除元素时,因为删除下标空出来了,所以元素会往前移。有人会问了,如果不移元素会怎么样?不移动元素就会出现空洞,内存不连续。下面我们分析下时间复杂度。
1. 最好情况时间复杂度:如果删除操作是针对数组末尾(x-1)的元素进行的,那么时间复杂度为 O(1)。因为在这种情况下,只需要将数组的长度减一即可,不需要移动其他元素。
2. 最坏情况时间复杂度:如果删除操作是针对数组开头的元素进行的,或者是数组中间的元素进行的,那么需要将删除位置之后的所有元素向前移动一个位置,以填补删除元素留下的空缺,时间复杂度为 O(n)。
3. 平均时间复杂度:平均情况下的时间复杂度取决于删除位置的分布情况。如果删除位置随机分布在数组中,那么平均情况下的时间复杂度仍然为 O(n)。
数组的删除操作是需要移动元素的,因此在时间复杂度上并不能提高效率。但,有一种技巧可以提高数组删除操作的效率,即使用“标记删除”而非真正的物理删除。
大概思路是下面这样的:当需要删除一个元素时,并不立即移动其它元素来填补删除位置,而是将该位置的元素标记为已删除状态。在进行元素访问时,忽略已标记为删除状态的元素。当数组中已删除元素的数量达到一定阈值时,再执行一次真正的物理删除并进行数组重排,以释放不必要的内存空间。
数组越界问题
数组越界在 go 中是非常严重的,会导致 Panic,所以在使用过程中一定要注意。看下面这段代码。
go
复制代码
func main() { tp := []int{1, 2, 3, 4, 5} v := tp[6] print(v) }
结果输出如下:
go
复制代码
panic: runtime error: index out of range [6] with length 5
代码实战
go
复制代码
package slice import ( "errors" "fmt" "sync/atomic" ) var ( indexOutOfRange = errors.New("index out of range") arrayIsFull = errors.New("array is full") ) type Slices[T any] struct { data []T // 容器 len atomic.Uint32 // 长度 capacity uint32 // 容量 } // NewSlices 初始化数组 func NewSlices[T any](capacity uint32) *Slices[T] { return &Slices[T]{data: make([]T, capacity), capacity: capacity} } func (a *Slices[T]) Insert(index uint32, v T) error { if a.Len() >= a.capacity { return arrayIsFull } if a.isIndexOutOfRange(index) { return indexOutOfRange } // 元素后移 for i := a.Len(); i > index; i-- { a.data[i] = a.data[i-1] } a.len.Add(1) a.data[index] = v return nil } func (a *Slices[T]) Insert2Head(v T) error { return a.Insert(0, v) } func (a *Slices[T]) Insert2Tail(v T) error { return a.Insert(a.Len(), v) } func (a *Slices[T]) Delete(index uint32) (T, error) { var v T if ok := a.isIndexOutOfRange(index); ok { return v, indexOutOfRange } v = a.data[index] l := a.Len() - 1 // 元素前移 for i := index; i < l; i++ { a.data[i] = a.data[i+1] } // 设置零值 var zero T a.data[l] = zero d := int32(-1) a.len.Add(uint32(d)) return v, nil } // Find 下标随机查询 func (a *Slices[T]) Find(index uint32) (T, error) { var out T if ok := a.isIndexOutOfRange(index); ok { return out, indexOutOfRange } out = a.data[index] return out, nil } func (a *Slices[T]) Len() uint32 { return a.len.Load() } func (a *Slices[T]) Print() { for _, v := range a.data { fmt.Println(v) } } func (a *Slices[T]) isIndexOutOfRange(index uint32) bool { // 长度大于容量说明数组越界了 return index >= a.capacity }
测试用例如下:
go
复制代码
package slice import ( "fmt" "testing" "unsafe" ) func FuzzInsert2Tail(f *testing.F) { testcases := []uint32{0, 1, 2, 3, 4} for _, tc := range testcases { f.Add(tc) } slices := NewSlices[int](11) f.Fuzz(func(t *testing.T, index uint32) { err := slices.Insert(index, int(index)) if err != nil { panic(err) } }) slices.Insert2Tail(20) slices.Print() } func FuzzInsert2Head(f *testing.F) { testcases := []uint32{0, 1, 2, 3, 4} for _, tc := range testcases { f.Add(tc) } slices := NewSlices[int](11) f.Fuzz(func(t *testing.T, index uint32) { err := slices.Insert(index, int(index)) if err != nil { panic(err) } }) slices.Insert2Head(20) slices.Print() } func FuzzFind(f *testing.F) { testcases := []uint32{0, 1, 2, 3, 4, 5, 6, 7, 8, 9} for _, tc := range testcases { f.Add(tc) } slices := NewSlices[int](11) f.Fuzz(func(t *testing.T, index uint32) { err := slices.Insert(index, int(index)) if err != nil { panic(err) } }) f.Log(slices.Find(0)) f.Log(slices.Find(1)) f.Log(slices.Find(2)) f.Log(slices.Find(8)) } func FuzzInsertAndDelete(f *testing.F) { testcases := []uint32{0, 1, 2, 3, 4, 5, 6, 7, 8, 9} for _, tc := range testcases { f.Add(tc) } slices := NewSlices[int](11) f.Fuzz(func(t *testing.T, index uint32) { err := slices.Insert(index, int(index)) if err != nil { panic(err) } }) err := slices.Insert(3, int(20)) if err != nil { panic(err) } r, err := slices.Delete(5) if err != nil { panic(err) } f.Log(r) } func TestArray(t *testing.T) { var x int size := unsafe.Sizeof(x) fmt.Printf("int 占用 %d 个字节\n", size) tp := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12} for i := 0; i < len(tp); i++ { fmt.Println(fmt.Sprintf("16进制地址=%p,10进制地址=%d,值=%+v", &tp[i], uintptr(unsafe.Pointer(&tp[i])), tp[i])) // 以10和16进制方式打印 } }
总结
-
数组一旦初始化就是连续的内存空间,用来存储一类相同数据类型的元素。
-
数组数据结构的特性是支持下标随机访问,最好时间复杂度为O(1),最坏时间复杂度为O(n)。
-
数组的寻址公式是:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









