




围绕 MySQL 慢查询治理工作展开,从几方面展开:
- 战略设计:三阶段防控治理,事前召回,事中止损,事后治理
- 典型案例:模糊搜索,延迟关联,减少 IO & 回表次数
- 增益 buff:chatgpt 优化建议工具
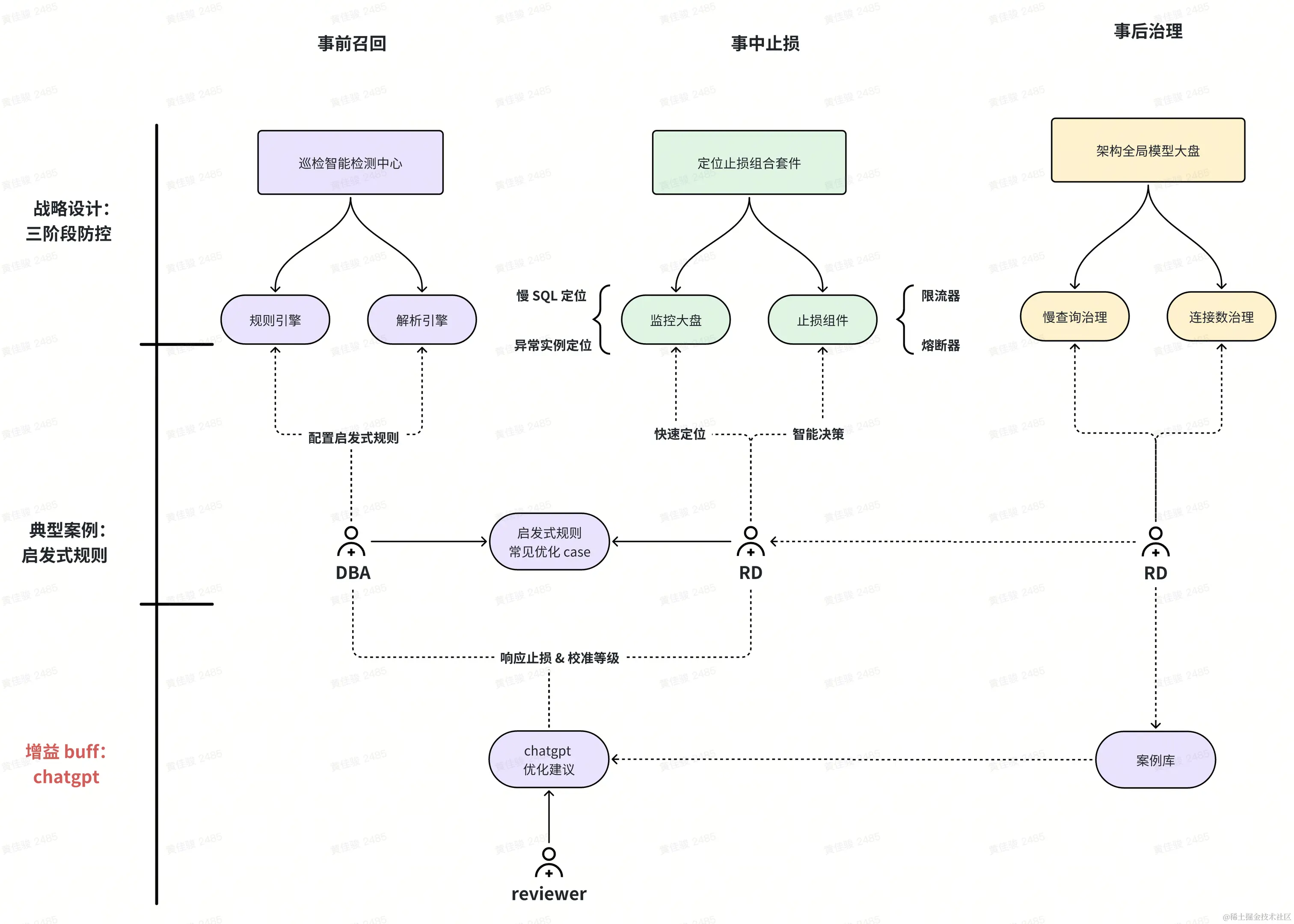
战略设计:三阶段优化治理
首先是战略上,我们分成了三阶段来推进 MySQL 治理,渗透到各个环节,各个角色当中,包括但不限于 RD、QA、SRE、DBA...
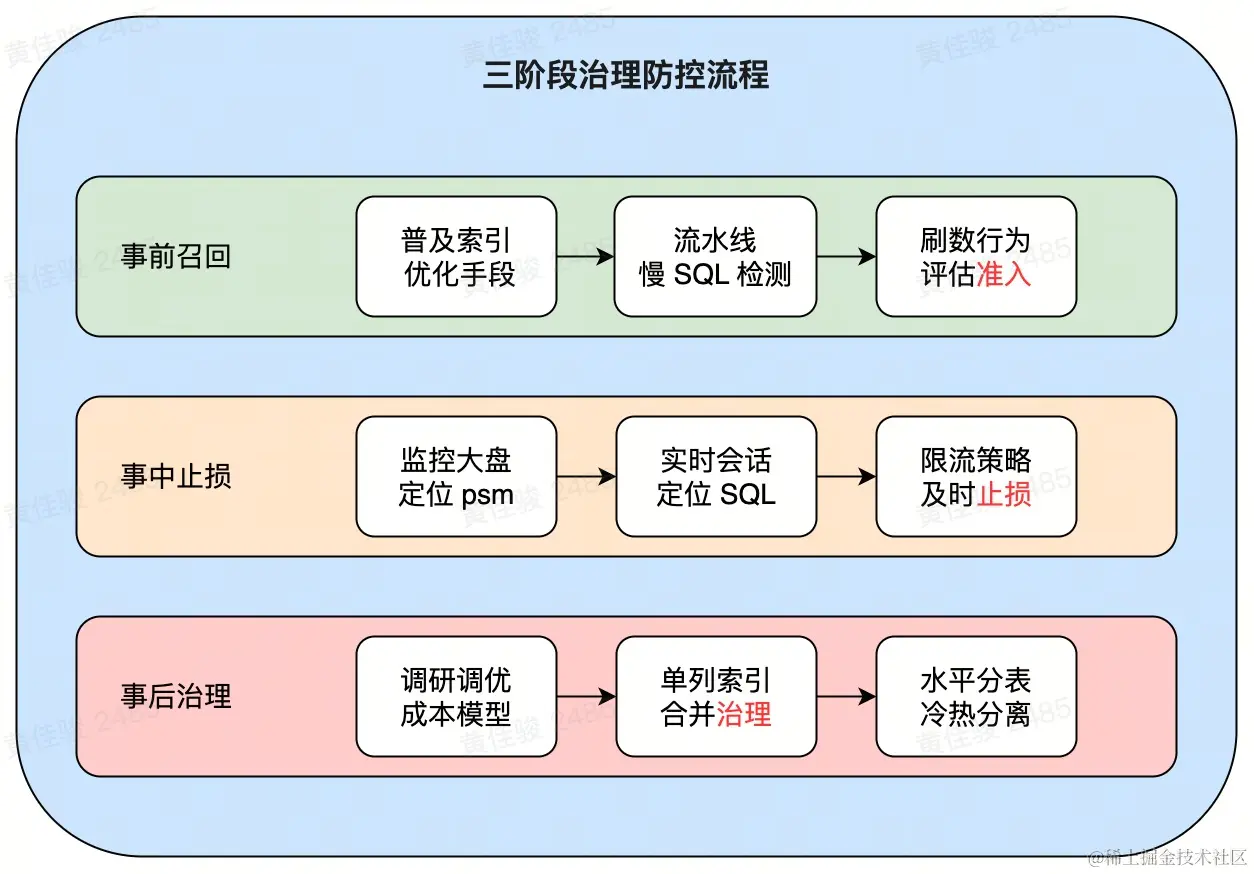
可以明显的看到,每个环节的关键词是不尽相同的,准入->治理->止损,我们是希望前置能发现问题的,而不是陷入「先污染后治理」的怪圈
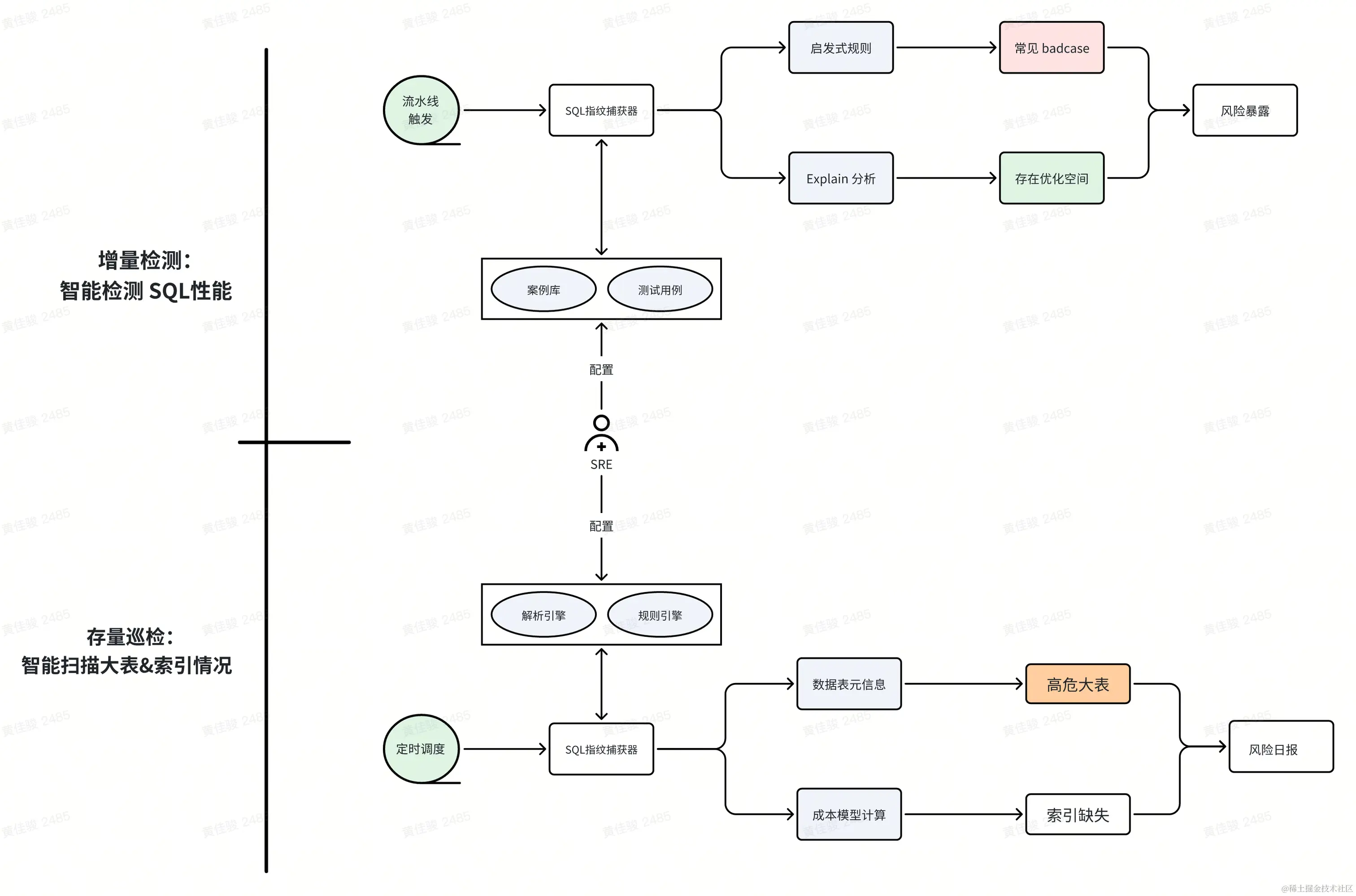
事前召回:巡检智能检测,召回暴露风险
分成了两部分来做,增量检测+存量巡检,抓大放小,先做足覆盖,后续调优巡检阈值 & 支持白名单
- 增量检测:通过启发式规则 & 成本分析引擎,智能检测新增 SQL 性能,并从真实案例库抽调测试「大户人家」
- 存量巡检:扫描历史大表,识别潜在的数据量大 + 缺少索引的隐患,提前暴露风险,防止数据表扩张后没有第一时间建立好索引来应对
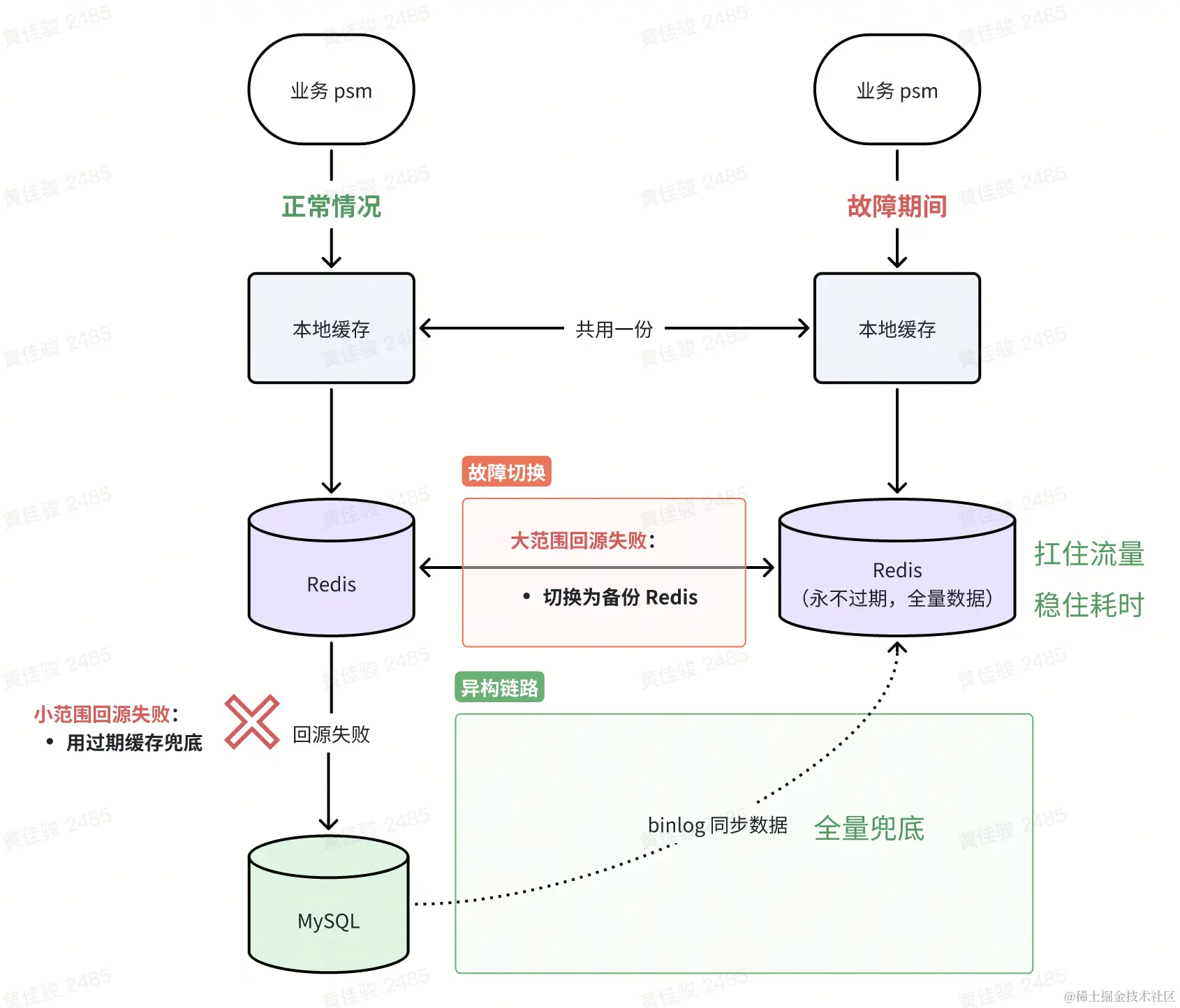
事中止损:实时会话定位,及时限流止损
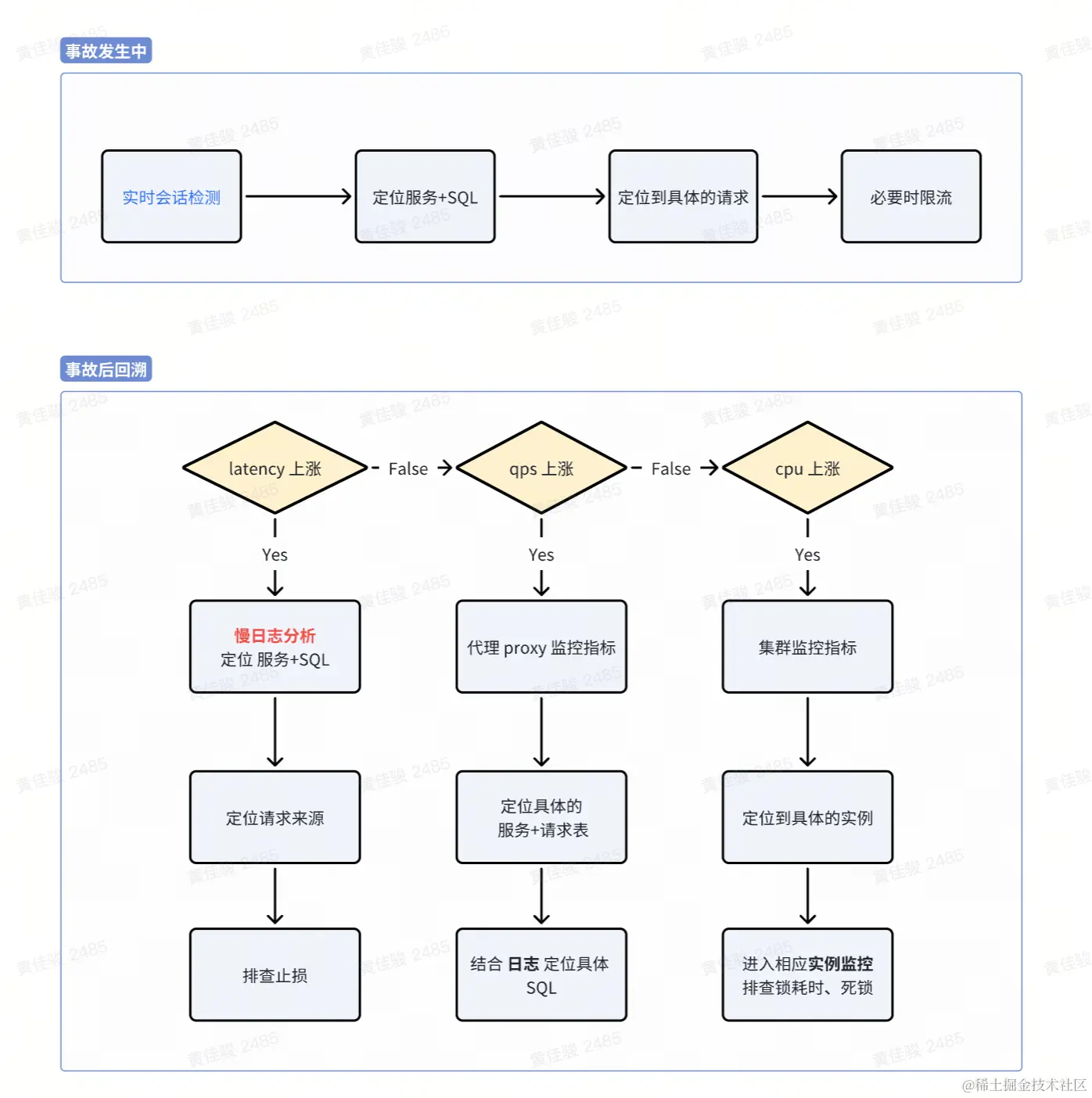
此部分由于不同公司组件,基架不同,便不过多赘述,大差不大的原则:兜底>降级>熔断>限流,一般可以采用异构方式,形成互备容灾
事后治理:成本代价模型调优,索引合并成本误判
问题背景:MySQL explain 有误,通过成本代价模型调优,解决「索引合并成本误判」的问题
具体的索引合并 SQL 这里我只贴出关键的部分,其他 where 条件没有贴出来,耗时达到了 2.5s,时常触发超时 kill
相关 SQL:
sql
复制代码
SELECT count(*) FROM `xxx` WHERE uid = ? -- 取值特别多,选择性很高 AND status = 0; -- 只有2个取值,选择性很低
初步分析:索引合并的执行过程
MySQL 选择的 explain 策略是:uid+status 的索引合并策略
于是我们顺着索引合并的思路和执行过程,挖掘相应的瓶颈所在
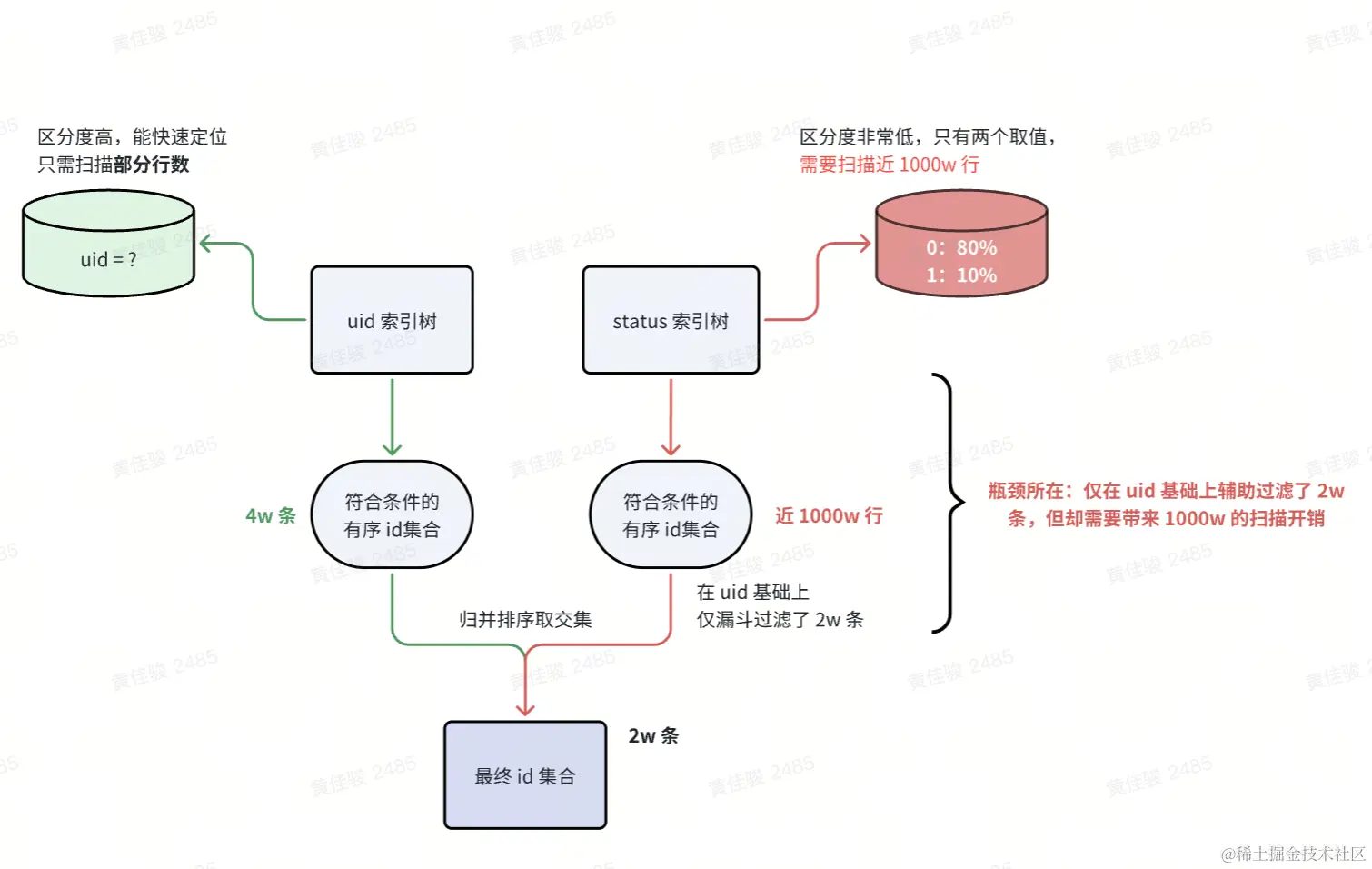
那问题其实挺明朗了,短期的解决方法,直接在 SQL 层面忽略 status 索引,让 MySQL 走 uid 单列索引即可,耗时降低到了 200-400 ms
但从中长期来看,不免这个数据库还有其他 SQL 也有类似问题,考虑到根治,我们还需要在 MySQL 层面,分析为什么成本优化器会计算出错?
恶补知识:成本代价模型的计算方式
一句话总结:通过采样统计分析,得到统计信息/索引基数,进而推断出大致需要扫描的行数,从而计算成本
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









