




 UUID(通用唯一识别码)是分布式系统中确保唯一性的解决方案。它由32位16进制数字组成,有5个版本,其中版本1和4常用于保证唯一性。Java中的UUID实现主要依赖版本4,采用随机数生成,重复概率极低,适用于大量生成唯一ID的场景。
UUID(通用唯一识别码)是分布式系统中确保唯一性的解决方案。它由32位16进制数字组成,有5个版本,其中版本1和4常用于保证唯一性。Java中的UUID实现主要依赖版本4,采用随机数生成,重复概率极低,适用于大量生成唯一ID的场景。
一. 何为UUID
UUID 是指 Universally Unique Identifier,即通用唯一识别码 。
UUID 的目的是让分布式系统中的所有元素都能有唯一的识别信息 。如此一来,每个业务任务都可以创建不与其它任务冲突的 UUID,就不需考虑诸如:数据库创建时的名称重复问题、分布式系统数据信息无法跟踪一条日志信息的问题 。它使用某种规则,而不是某种中心化的自增方式,来 保证这个识别码的全局唯一性。
二. UUID格式及版本
UUID 是由一组32位数的16进制数字所构成,所以 UUID 理论上的总数1632=2128,约等于3.4 x 10123。也就是说若每纳秒产生1百万个 UUID,要花100亿年才会将所有 UUID 用完
UUID的格式:
UUID 的十六个八位字节被表示为 32个十六进制数字,以连字号分隔的五组来显示,形式为 8-4-4-4-12,总共有 36个字符(即三十二个英数字母和四个连字号)。例如:
123e4567-e89b-12d3-a456-426655440000
xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx
数字 M 的四位表示 UUID 版本,当前规范有5个版本,M可选值为1, 2, 3, 4, 5 ;
数字 N 的一至四个最高有效位表示 UUID 变体( variant ),有固定的两位10xx因此只可能取值 8, 9, a, b
UUID版本通过M表示,当前规范有5个版本,M可选值为1, 2, 3, 4, 5。这5个版本使用不同算法,利用不同的信息来产生UUID,各版本有各自优势,适用于不同情景:
- 版本1: 严格按照 UUID 定义的每个字段的意义来实现,使用的变量因子是 时间戳+时钟序列+节点信息(Mac地址)
- 版本2: 基本和版本1一致,但是它主要是和 DCE( IBM 的一套分布式计算环境)。但是这个版本在 IETF 中也没有具体描述,反而在DCE 1.1: Authentication and Security Services这篇文档中说到了具体实现。所以这个版本现在很少使用到,并且很多地方的实现也都忽略了它。
- 版本3: 基于 name 和 namespace 的 hash 实现变量因子,版本3使用的是 md5 进行 hash 算法 。
- 版本4: 使用随机或者伪随机实现变量因子。
- 版本5: 基于 name 和 namespace 的 hash 实现变量因子,版本5使用的是 sha1 进行 hash 算法。
使用较多的是版本1和版本4,其中版本1使用当前时间戳和MAC地址信息。版本4使用(伪)随机数信息,128bit中,除去版本确定的4bit和variant确定的2bit,其它122bit全部由(伪)随机数信息确定。
因为时间戳和随机数的唯一性,版本1和版本4总是生成唯一的标识符。若希望对给定的一个字符串总是能生成相同的 UUID,使用版本3或版本5。
UUID的随机重复率:
Java中 UUID 使用版本4进行实现,所以由java.util.UUID类产生的 UUID,128个比特中,有122个比特是随机产生,4个比特标识版本被使用,还有2个标识变体被使用。利用生日悖论,可计算出两笔 UUID 拥有相同值的机率约为:
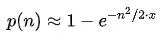
其中x为 UUID 的取值范围,n为 UUID 的个数。
以下是以 x = 2122 计算出n笔 UUID 后产生碰撞的机率:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1601
1601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









