



接前篇红外小目标实战,加入MicroC3、HDC、ART后,虽说召回率相对于Yolov11 baseline提升了24个点,达到了0.75,但是离0.9的目标还差很远
本次优化思路
红外微小目标很多是不到20个像素的,步长为2的卷积和池化层在处理低分辨率图像和小物体时会导致信息的丢失,有没有一种特征提取在下采样的同时尽可能少的丢失特征呢?
SPDConv好像挺符合需求的!
SPDConv和HDC,一个通过增加通道数来保留更多信息,一个通过增大感受野来获取更丰富的语义信息,何不将二者结合看看效果!
SPDConv解析
SPD-Conv(Space-to-Depth Convolution,空间到深度卷积)是一种针对传统卷积神经网络在处理低分辨率图像和小目标时性能下降问题而提出的创新性下采样模块。它由论文《SPD-Conv: Eliminating the Downsampling Information Bottleneck in Convolutional Neural Networks》(arXiv:2208.03641)提出,核心思想是用无信息损失的空间重排替代传统的步长卷积或池化操作。
传统下采样的缺陷
-
细粒度信息丢失:每次下采样会丢弃 75% 的像素(2×2 → 1 像素),对小目标(如 3×3 像素)可能是致命的。
-
不可逆操作:无法从下采样后的特征图还原原始空间信息。
-
感受野增长以牺牲分辨率为代价:小目标在浅层可能直接被滤掉。
SPDConv创新
-
消除步长卷积和池化层:不使用stride=2卷积核Pooling层
-
空间到深度转换:通过空间到深度操作,将像素的空间块重新排列到深度/通道维度,增加通道数到 4 C ,同时将空间维度缩小2倍
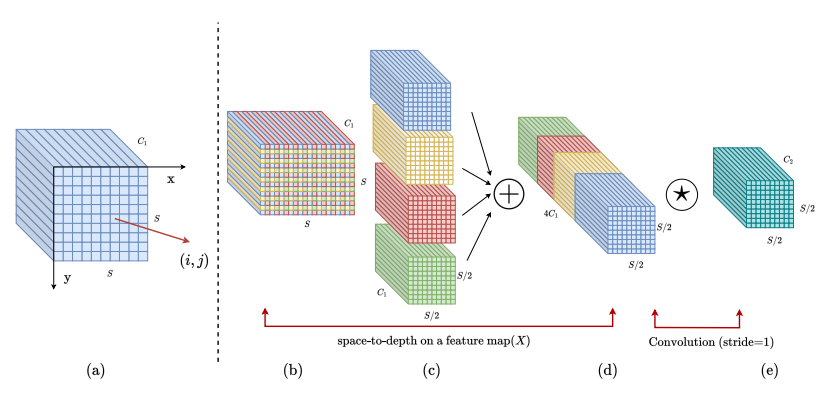
模块代码
class SPDConv(nn.Module): ###
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
c1 = c1 * 4
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
x = torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
x = torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)
return self.act(self.conv(x))
模型结构图
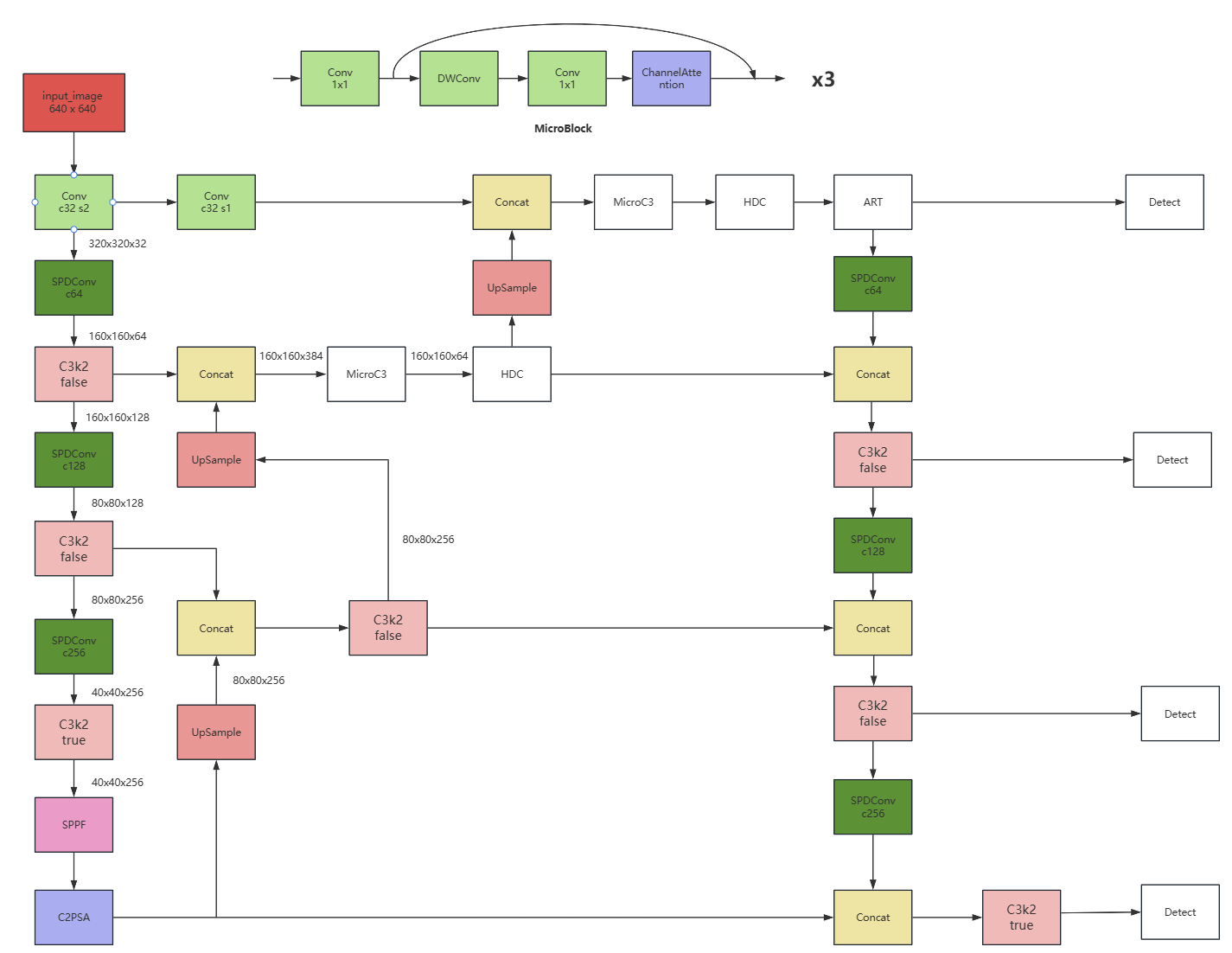
yaml配置
nc: 1 # number of classes (change as needed)
# Backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [32, 3, 2]] #
- [-1, 1, Conv, [32, 3, 1]] # 1 P1
- [ 0, 1, SPDConv, [64]] # 2
- [-1, 1, C3k2, [128, False, 0.25]] # 3 P2
- [-1, 1, SPDConv, [128]] #
- [-1, 1, C3k2, [256, False, 0.25]] # 5 P3
- [-1, 1, SPDConv, [256]] #
- [-1, 1, C3k2, [256, True]] #
- [-1, 1, SPPF, [256, 5]] #
- [-1, 1, C2PSA, [256]] # 9 P4
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 10 upsample P4 to P3
- [[-1, 5], 1, Concat, [1]] # 11 cat P3
- [-1, 1, C3k2, [256, False]] #
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 13 upsample P3 to P2
- [[-1, 3], 1, Concat, [1]] # 14 cat P2
- [-1, 1, MicroC3, [64]]
- [-1, 1, HDC, [64]] # 16
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 17 upsample P2 to P1
- [[-1, 1], 1, Concat, [1]] # 18 cat P1
- [-1, 1, MicroC3, [32]]
- [-1, 1, HDC, [32]]
- [-1, 1, ART, [32]] # 21 P1 head
- [-1, 1, SPDConv, [64]]
- [[-1, 16], 1, Concat, [1]] # 23 downsample p1 to p2
- [-1, 1, C3k2, [64, False]] # 24 P2 head
- [-1, 1, SPDConv, [128]]
- [[-1, 12], 1, Concat, [1]]
- [-1, 1, C3k2, [128, False]] # 27 P3 head
- [-1, 1, SPDConv, [256]]
- [[-1, 9], 1, Concat, [1]]
- [-1, 1, C3k2, [256, True]] # 30 P4 head
- [[21, 24, 27, 30], 1, Detect, [nc]]
实验结果
还是使用我的1000多张微小目标测试集来测试
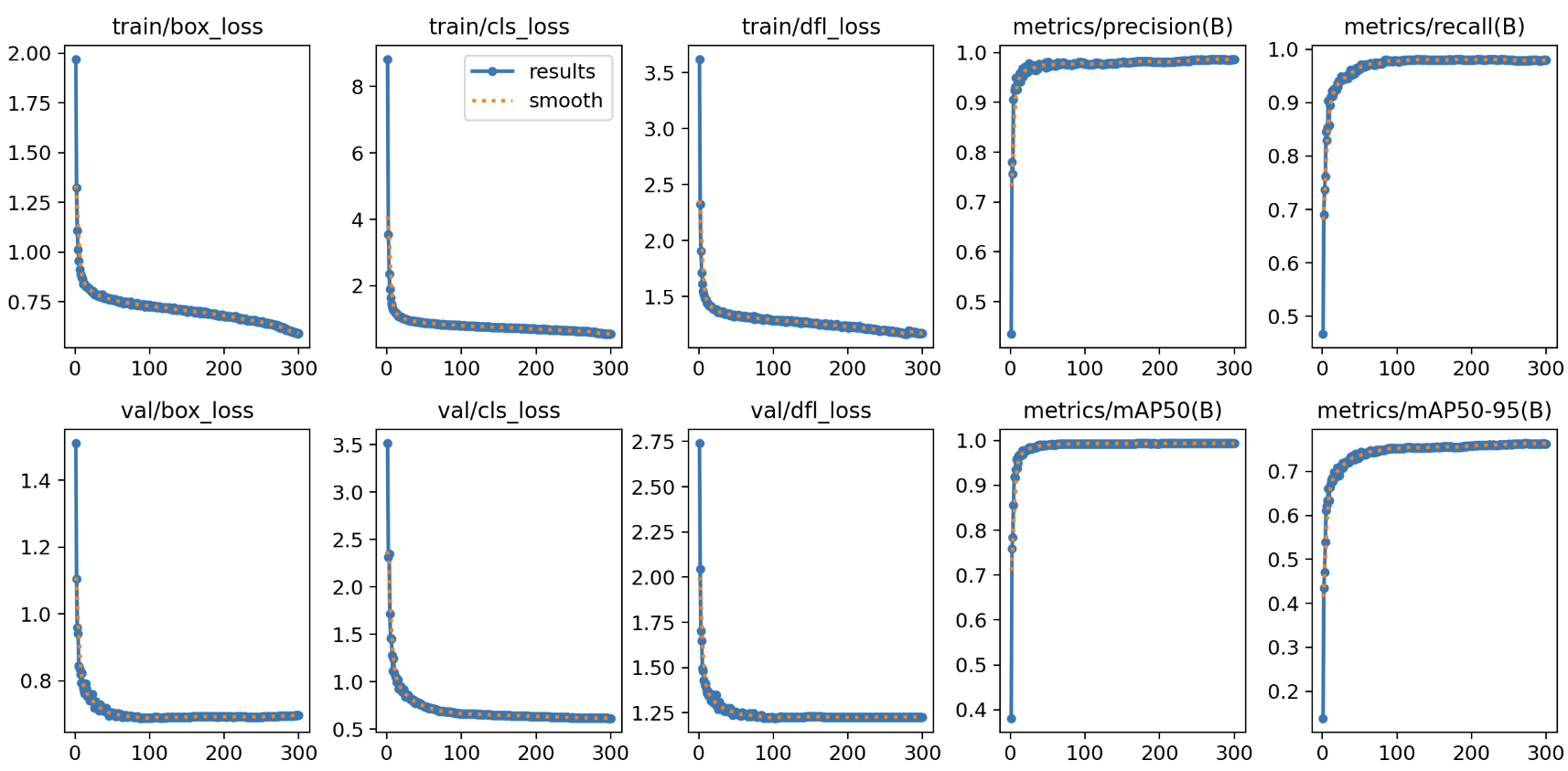
训练过程图
测试集上混淆矩阵
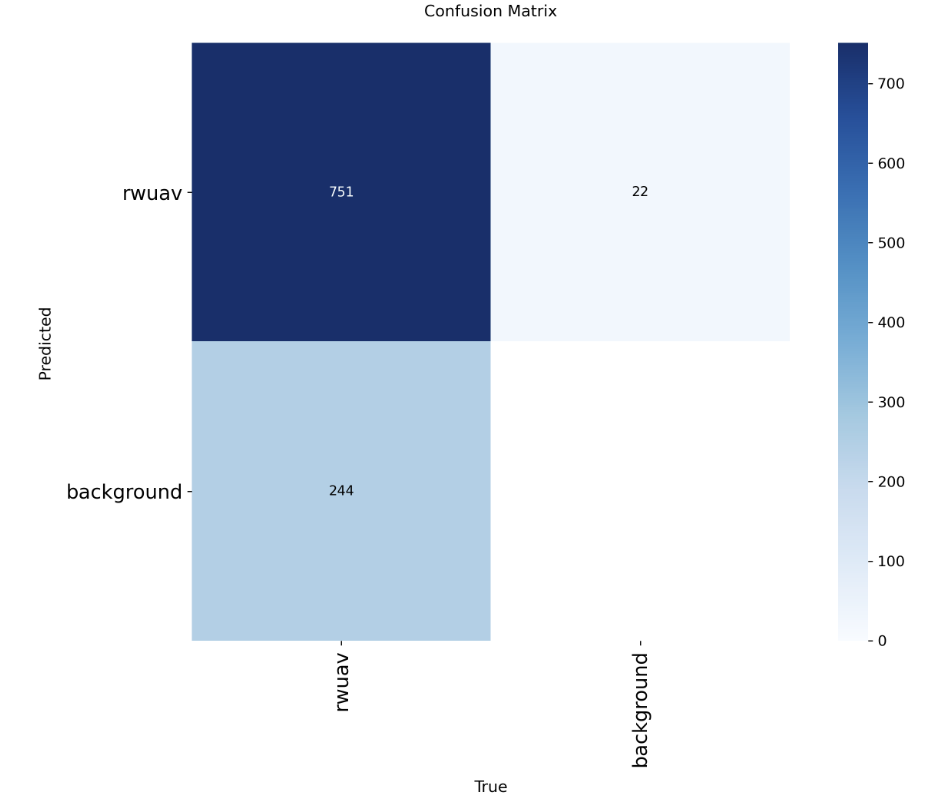
比起不加SPDConv,多检出了3张图片~
说没提升吧,又有点,模型参数量倒是减小了,但是在我的数据集上一点也不明显…
对比数据
| 模型 | 大小 | P | R |
|---|---|---|---|
| 优化前 | 19M | 0.95 | 0.59 |
| 优化后 | 6.9M | 0.97 | 0.75 |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









